 Bo Tao
Bo Tao Yan Wang
Yan Wang Xinbo Qian2
Xinbo Qian2 Xiliang Tong
Xiliang Tong Weiping Yao
Weiping Yao Bin Chen
Bin Chen- 1Key Laboratory of Metallurgical Equipment and Control Technology, Ministry of Education, Wuhan University of Science and Technology, Wuhan, China
- 2Hubei Key Laboratory of Mechanical Transmission and Manufacturing Engineering, Wuhan University of Science and Technology, Wuhan, China
- 3Precision Manufacturing Institute, Wuhan University of Science and Technology, Wuhan, China
- 4Research Center for Biomimetic Robot and Intelligent Measurement and Control, Wuhan University of Science and Technology, Wuhan, China
- 5Hubei Key Laboratory of Hydroelectric Machinery Design and Maintenance, China Three Gorges University, CTGU, Yichang, China
Recent work has shown that deep convolutional neural network is capable of solving inverse problems in computational imaging, and recovering the stress field of the loaded object from the photoelastic fringe pattern can also be regarded as an inverse problem solving process. However, the formation of the fringe pattern is affected by the geometry of the specimen and experimental configuration. When the loaded object produces complex fringe distribution, the traditional stress analysis methods still face difficulty in unwrapping. In this study, a deep convolutional neural network based on the encoder–decoder structure is proposed, which can accurately decode stress distribution information from complex photoelastic fringe images generated under different experimental configurations. The proposed method is validated on a synthetic dataset, and the quality of stress distribution images generated by the network model is evaluated using mean squared error (MSE), structural similarity index measure (SSIM), peak signal-to-noise ratio (PSNR), and other evaluation indexes. The results show that the proposed stress recovery network can achieve an average performance of more than 0.99 on the SSIM.
1 Introduction
Inspired by the human nervous system, Rosenblatt (1958) proposed the perceptron model, which became the basis of the early artificial neural network (ANN). In recent years, the ANN, especially deep neural network (DNN), has become one of the fastest developing and most widely used artificial intelligence technologies(Sun et al., 2020a; Sun et al., 2020c; Li et al., 2020; Tan et al., 2020; Chen et al., 2021a). Classical research work has proved the excellent performance of DNNs in image classification (He et al., 2016), medical image segmentation (Ronneberger et al., 2015; Xiu Li et al., 2019; Jiang et al., 2021a), image generation (Isola et al., 2017), and depth estimation (Godard et al., 2017; Jiang et al., 2019a). The deep convolutional neural network is widely used in feature extraction of image data (Jiang et al., 2019b; Huang et al., 2020; Hao et al., 2021). As an extremely powerful tool, the deep convolutional neural network can provide a new perspective for the application of digital photoelasticity. That is, the deep convolutional neural network can directly learn the corresponding relationship between isochromatic pattern and principal stress difference pattern.
In digital photoelasticity, the fringe patterns that contain the whole field stress information in terms of the difference of principal stresses (isochromatics) and their orientation (isoclinics) are captured as a digital image, which is processed for quantitative evaluation (Ramesh and Sasikumar, 2020). Frequency-domain and spatial-domain analysis methods, such as Fourier transform (Ramesh et al., 2011), phase-shift (Tao et al., 2022), step-loading method (Ng, 1997; Zhao et al., 2022) and multiwavelength technology (Dong et al., 2018), are usually used to process the data of isochromatics and isoclinics. However, in the actual industrial scene, the traditional pattern demodulation will face challenges, such as the color difference in the color matching method of the calibration table; the complex geometry of the sample, which makes the pattern complex and difficult to demodulate; and the fringes with different experimental configuration need special analysis, all of which make photoelasticity research a complex process extending to industrial applications.
In recent years, deep learning has shown increasing interest in solving traditional mechanics problems (Chen et al., 2021b; Jiang et al., 2021b; Duan et al., 2021; Tao et al., 2021; Zhang et al., 2022), which is due to deep learning’s powerful ability of data feature extraction and representation of complex relationships. In general, deep learning is committed to mining implicit rules of data from a large number of data sets and then using the learned rules to predict the results and hoping that the learned models have good generalization ability (Cheng et al., 2021; Huang et al., 2021; Yang et al., 2021; Chen et al., 2022). Works in optical image processing, such as phase imaging (Gongfa Li et al., 2019; Xin Liu et al., 2021; Sun et al., 2022), phase unwrapping (Wang et al., 2019), and fringe pattern analysis (Feng et al., 2019), have also demonstrated the applicability of deep learning. Recovering the full-field principal stress difference of the loaded object from the photoelastic fringe pattern can be regarded as an inverse problem solving process of deep learning. A large number of datasets are collected and trained to find the complex correspondence between the fringe pattern and stress difference pattern, which is then used to recover the stress field of the real loaded object from a single fringe pattern. When many conditions such as specimen shape, material properties, and the setting of polarized light field need to be considered, it is difficult for traditional mathematical methods to deal with this complicated and changeable situation. However, with sufficient data collected under different experimental conditions, deep learning can directly learn the complex correspondence between the input fringe pattern and output principal stress difference.
In this study, a deep convolutional neural network model is designed for inferring the stress field from the photoelastic fringe pattern. The overall framework of the network is in the form of encoder–decoder structure. The encoder completes the feature extraction process of the input fringe pattern, and the decoder completes the process of feature fusion to stress distribution pattern inference, thus realizing the transformation from the single photoelastic fringe pattern to stress distribution pattern. The main contributions of our study can be summarized as follows:
(1) A simple and efficient stress recovery neural network is designed to realize the process of stress field recovery of the loaded object from a single fringe pattern.
(2) A multiloss function weighted objective optimization function is proposed to accelerate the convergence of neural networks and improve the robustness of model prediction.
(3) The superior performance of the proposed method is verified on a public dataset.
The remainder of this article is structured as follows. Some of the work closely related to this study will be discussed in Section 2. The combination of the photoelastic method and convolutional neural network and the design of the neural network model and objective optimization function is presented in Section 3. In Section 4, the details of the experiment implementation are introduced, the method proposed in this study is compared with that of other studies in detail, and then the experimental results are further analyzed. Finally, the conclusion and limitations of the proposed method are given in Section 5.
2 Related Work
It is a challenging task to recover the stress field of the loaded object from a single photoelastic fringe pattern. Most of the traditional methods are limited by different experimental conditions and calculation methods when dealing with complex fringe patterns. Recently reported methods based on deep learning provide new ideas to solve these shortcomings. Feng et al. (2019) proposed a fringe pattern analysis method based on deep learning. They collected phase-shifted fringe patterns in different scenes to generate training data and then trained neural networks to predict some intermediate results. Finally, combining these intermediate results, the high-precision phase image is recovered by using arc tangent function. The results show that this method can significantly improve the quality of phase recovery. Sergazinov and Kramar (2021) use the CNN to solve the problem of force reconstruction of photoelastic materials. They use the synthetic dataset obtained by theoretical calculation for training and then use the transfer learning to fine-tune a small amount of real experimental data, which shows good force reconstruction results.
For the estimation of the photoelastic stress field under a single experimental condition, a dynamic photoelastic experimental method based on pattern recognition was proposed (Briñez-de León et al., 2020a). The ANN was used to process the color fringe patterns that changed with time so as to classify the stress of different sizes, isotropic points, and inconsistent information. In order to make the deep learning method suitable for a wider range of experimental conditions, Briñez-de León et al. (2020b) reported a powerful synthetic dataset which covered photoelastic fringe patterns and the corresponding stress field distribution patterns under various experimental conditions with highly diversified spatial fringe distribution. At the same time, a neural network structure based on VGG16 (Simonyan and Zisserman, 2014) is proposed to recover the stress field from the isochromatic pattern. However, the prediction results of this network model are somewhat different from the real maximum stress difference, and the prediction results of the stress on the rounded surfaces are not very accurate. In their reports in the other literature (Briñez-de León et al., 2020c), an image translation problem directly related to spatial transformation based on the generative adversarial network (GAN) model was proposed. This method showed good performance in the SSIM, but there is a supersaturation phenomenon of stress recovery in some specimens. In addition, GAN is not an easy training model for the convergence of the network (Sun et al., 2021; Ying Liu et al., 2021; Wu et al., 2022). Recently, they proposed a new neural network model to evaluate the stress field and named it PhotoelastNet (Briñez-de León et al., 2022). Considering the influence of noise and complex stress distribution patterns, the scale of synthetic data was further expanded, and a lighter network structure was designed, which achieved better performance in synthetic images and experimental images. However, there is still a certain gap between the accuracy of stress distribution estimation and ground truth. Our study improves on these methods by proposing a simpler and reasonable network structure and designing more effective loss functions to solve these problems.
3 Photoelasticity and the Neural Network Model
3.1 Photoelasticity
Photoelastic fringes are visualized patterns obtained by a polarized optical system, which display the invisible stress response of each point in the model related to the birefringence effect through the related optical system. In this research, photoelastic fringes are visualized by a circular polariscope. The schematic diagram of the circular polariscope is shown in Figure 1. The circular polariscope comprises a light source, polarizer, quarter wave plate I (QW-I), specimen which is made of photoelastic material, quarter wave plate II (QW-II), and an analyzer.
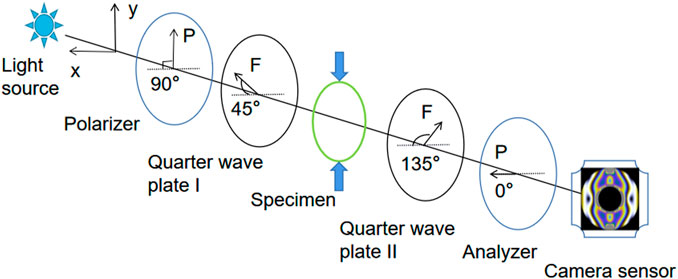
FIGURE 1. Schematic diagram of the orthogonal circularly polarized light field.
In Figure 1, F represents the fast axis of the QW-I and QW-II. The orientations of the fast axis of the QW-I and QW-II are set to 45° and 135°, respectively. The orientation of the polarizer is set to 90°. The orientation of the analyzer is set to 0°. The light carried with the specimen’s stress information is emitted from the analyzer, and the light intensity can be expressed as follows:
where Ib is the background light intensity. I0 is the intensity of the light source. δ is the isochromatic angle of the photoelastic model, which contains the stress field information.
According to the law of stress optics, the principal stress difference in photoelastic models is proportional to the refractive index in the principal stress direction, as shown in Eq. 2. The optical path difference produced when polarized light passes through the photoelastic model can be expressed as Eq. 3.
where σi is the ith principal stress, ni is the refractive index in the direction of σi, C = C1 − C2, Ci is the optical coefficient of the stress of the model material, δ is the phase delay, h is the thickness of the photoelastic model, z is the optical path difference, and λ is the wavelength of the incident light source.
In two-dimensional photoelasticity, the relationship between phase delay caused by principal stress difference and the properties of the optical material is shown in Eq. 4. The main influencing factors of phase delay are light wavelength, optical coefficient of photoelastic material, model thickness, and stress condition.
where fσ = λ/C is the material fringe value.
The photoelastic fringe patterns collected by the camera are interference intensity images of light. These fringe patterns generated by phase delay wrap the stress field information of the stressed object. In general, the stress field can be understood as the mechanical effect caused by the force distributed inside the object (Markides and Kourkoulis, 2012), which can be expressed by the principal stress difference σ1 − σ2.
Briñez-de León et al. (2020b) reported that the intensity of the emitted light is related to the spectral content of the light source, optical elements in the polarized light system, spatial stress distribution, and relative spectral response in the camera sensor. Based on the circular polariscope shown in Figure 1, the relationship between the intensity and phase delay of the emitted light (Ajovalasit et al., 2015) in different color channels is shown in Eq. (5).
where I is the emergent light intensity; RGB is the red, green, and blue color channels; and
According to the causal relationship between the photoelastic fringe pattern and stress field, the process from the stress field to fringe pattern can be regarded as a forward problem, while solving the stress field according to the single fringe pattern is a challenging inverse problem, that is, unwrapping stress information in the fringe pattern. We propose a stress field recovering method based on the CNN to solve this problem.
3.2 Photoelastic Image Dataset
It is expensive to obtain enough photoelastic fringe patterns and corresponding stress field images through the photoelastic experiment, which is due to the complicated experimental environment configuration and tedious post-data processing. Briñez-de León et al. (2020d) propose a hybrid scheme that includes real experimental data and computational simulation. Different types of light sources, the range of loading external forces, rotation angles of optical elements, and various types of camera sensors are fully considered in this method. According to a variety of different experimental conditions, such a rich isochromatic art dataset (Briñez-de León et al., 2020e) was finally synthesized through calculation methods. In this repository, all the experimental cases consider a PMMA material of 10 mm thickness and a stress optical coefficient of about 4.5 e−12 m2/N. There are totally 101,430 photoelastic image pairs in the dataset, and each pair includes the color fringe pattern and the corresponding gray stress map. The images are all 224 × 224 in size, and these images cover various patterns from simple to complex, which can be divided into two types: complete and patch. The fringe pattern and stress pattern are placed in different folders and matched by the same serial number.
3.3 Network Model
We propose a stress field recovery model based on the encoder–decoder structure. The input of the network is a single photoelastic color fringe pattern, and the output is the gray image of the stress field recovered from the fringe pattern. The overall structure of the neural network model is shown in Figure 2.
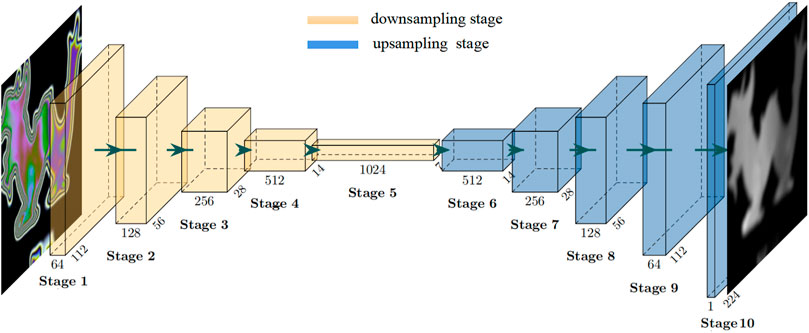
FIGURE 2. Schematic for the neural network architecture of the proposed model in this research. The network consists of an encoder and a decoder. An RGB isochromatic image is taken as the input, and the output is a stress map in gray scale.
The whole network consists of an encoder and a decoder. The encoder receives the input photoelastic fringe pattern and then uses a series of sub-sampling convolution, batch normalization (BN) (Ioffe and Szegedy, 2015), activation, and other operations to complete feature extraction from the input images. The feature information extracted by the encoder will be used as an intermediate representation of the input fringe pattern. Concretely, the whole coding process is divided into five stages by using the structure of the cascaded convolutional neural network (Sun et al., 2020b; Weng et al., 2021), and each stage comprises a different number of RepVGGBlock (Ding et al., 2021), as shown in Figure 3. The number of blocks can be freely adjusted to change the encoder’s representation ability of the input image. Considering the trade-off between the accuracy and speed of the model, we set the number of blocks in each stage as {1,2,4,8,1}, and the image resolution of the first stage is 224 × 224. Experiments show that under the large image size, using only one block is helpful to speed up the training and reasoning of the model. The input and output dimensional parameters of each stage are shown in Table 1.
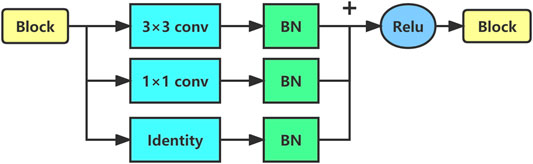
FIGURE 3. Sketch of RepVGGBlock architecture.

TABLE 1. Encoder parameters of each stage. The first parameter of the size indicates the number of channels, and the last two parameters indicate the size of the image during the down-sampling process.
RepVGGBlock is a convolutional block with multibranch topology, including convolution with 3 × 3 kernel branch, convolution with 1 × 1 kernel branch, and identity branch. Each branch performs BN operation, then concatenates them together, and finally outputs after being activated by ReLu. The schematic diagram of RepVGGBlock is shown in Figure 3.
In order to recover the stress field distribution quickly and accurately, we designed a convolutional decoding structure which maps the features extracted by the encoder to the stress distribution map corresponding to the fringe pattern. The feature decoding process is also divided into five stages, each of which is stacked with blocks with the same structure. The number of blocks is also adjustable, and its structure comprises an up-sampling layer, a convolution layer, a BN layer, and an active layer. The schematic diagram is shown in Figure 4. The up-sampling layer uses bicubic interpolation (Huang and Cao, 2020), the convolution layer uses 3 × 3 conv, and the activation layer uses ReLu. Table 2 shows the parameters of each stage of the decoder.
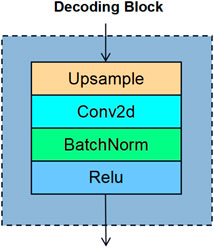
FIGURE 4. Sketch of decoding block architecture.

TABLE 2. Parameters of each stage of the decoder. The input size of the decoder is the output size of the encoder, and the final output size of the model is 1 × 224 × 224.
3.4 Objective Optimization Function
Mean squared error (MSE) (choi et al., 2009; Ma et al., 2020) is the most commonly used loss function in image reconstruction, which has fast convergence speed. But for regression tasks, the MSE is prone to interference by outliers during training. Most importantly, it usually leads to blurred images (Gondal et al., 2018) because minimizing MSE is equivalent to minimizing the cross-entropy of the empirical distribution and Gaussian distribution on the training set. We followed the method proposed by Zhao et al. (2016) and used L1 (Liao et al., 2021), L2, and SSIM (Wang et al., 2004) to construct our stress recovery loss function. First, the L1 loss of the two images is defined as follows:
where p is the index of the pixel; Ir(p) and Ig(p) are the values of the pixels in the recovered stress map and the ground truth, respectively; and N is the number of pixels p in the image I. Similarly, L2 loss is defined as follows:
The SSIM has been widely used as a metric to evaluate image processing algorithms. It is a full reference image quality evaluation index which measures the image similarity from three aspects: brightness, contrast, and structure. The SSIM for pixel p is defined as follows:
where x and y are two image patches extracted from the same spatial position of the two images, respectively; μx and μy are the average brightness of patches x and y, respectively; σx and σy are the standard deviation of x and y, respectively; σxy is the covariance of x and y; and C1 and C2 are very small constants to avoid having a zero denominator.
In order to solve the problem of edge noise in the process of image generation, multiscale SSIM (MS-SSIM) is added to the loss function (Wang et al., 2003), which can effectively improve the impact of edge noise. MS-SSIM is defined as Eq. 7. M scale images were obtained by down-sampling. These images were evaluated by the SSIM, and the MS-SSIM value was obtained by fusion calculation.
where lM and csj are the terms defined in Eq. 8 at scales M and j. According to the convolutional nature of the network, the loss function of MS-SSIM can be written as follows:
where
Finally, the objective optimization function is formulated in Eq. (11):
where Ir and Ig are the recovered stress map and the ground truth, respectively. Through the comparative experiments of different loss functions, we set
4 Experiment and Analysis
By comparing the performance of the proposed network structure with the multiloss function fusion method on a synthetic dataset and comparing with the previous work, it is proved that the proposed method can accurately recover the stress field distribution from the photoelastic fringe pattern.
4.1 Implementation Details
Our network model is implemented by PyTorch. During the training process, 20,000 image pairs are randomly selected from the complete dataset, with 80% as the training set and the remaining 20% as the validation set. The batch size is set to 32, and Adam optimizer is used to train 100 epochs. The initial learning rate is 0.0001. The size of the input and output images is 224 × 224, in which the input is the RGB channel color fringe pattern and the output is the single channel stress gray pattern. We train the stress recovery network from scratch on a single NVIDIA GTX 1080Ti, save several models with low loss values on the verification set, and then select the one with the best performance on the validation set as the final model. Another 20,000 pairs of images are randomly selected as the test set, and these images did not appear in the previous training and validation sets. This test set will be used to evaluate the performance of the final model.
4.2 Comparison With Different Methods
We test the trained models on different number of test sets, and the test images are randomly selected from the data sets that have never participated in the training. The distribution map of the stress field recovered by the network is compared with the real distribution map. MSE, peak signal-to-noise ratio (PSNR) (Gupta et al., 2011), and SSIM are used to measure the quality of the generated stress field images and then compare with the previous work. The PSNR is an image quality reference value for measuring maximum signal and background noise, as shown in Eq. (12).
where MAXI is the maximum possible pixel value of the image, and MSE is the mean square error.
For MSE, the value is close to 0 and the smaller the better. For the PSNR, high values indicate better performance; on the contrary, low values indicate low performance. For the SSIM, the value close to 1 indicates high similarity and the value close to 0 indicates low similarity.
The results of StressNet (Briñez de León et al., 2020b), GAN (Briñez de León et al., 2020c) and our proposed network are compared, as shown in Table 3. The experimental results show that the proposed network model has good feature extraction ability and better image space mapping ability. The large standard deviation of the PSNR and MSE may be due to the noise in randomly selected data, which leads to a certain deviation from the mean value. Generally speaking, the results obtained by our proposed stress recovery network are better than those of the previous work.
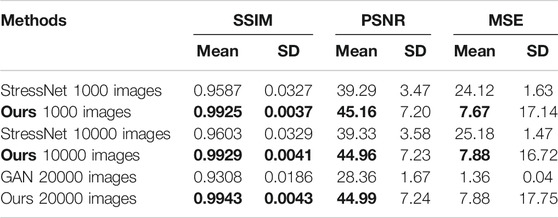
TABLE 3. Quantitative results. Comparison with StressNet (Briñez de León et al., 2020b) and GAN (Briñez de León et al., 2020c) in the SSIM, PSNR, and MSE.
We selected the two examples in StressNet to obtain specific instructions. The results in Figure 5 and Table 4 show that our proposed method has a high structural similarity index, and the bright area in the Figure 5 shows the degree of stress concentration. In order to measure the difference of the maximum stress difference between the recovery stress map and ground truth in the stress concentration area, the ratio of the maximum stress difference (RMSD) was proposed, as shown in Eq. 13. For the RMSD, the value close to 1 represents a small error. According to the RMSD value in Table 4, the stress recovery error of our method is smaller.
where MSDr and MSDg are the maximum stress difference of the recovery stress map and ground truth, respectively.

FIGURE 5. Results of comparison with StressNet (Briñez de León et al., 2020b). (A,E) are photoelastic fringes obtained with fluorescent and incandescent light sources, respectively. (B,F) are the corresponding ground truth. (C,G) are the results in StressNet. (D,H) are the results of our method.
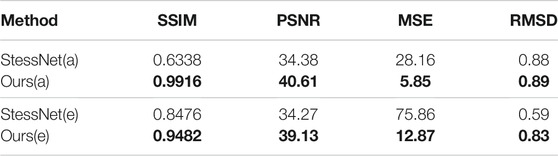
TABLE 4. Quantitative results of comparison with StressNet (Briñez de León et al., 2020b). (a) and (e) represent the results of processing the photoelastic fringes in Figure 5.
Similarly, we also make a further comparison with the methods proposed in GAN (Briñez de León et al., 2020c), as shown in Figure 6. The experimental results show that our method solves the local over-saturation phenomenon in GAN (i.e., the predicted value of the stress concentration area tends to be larger).
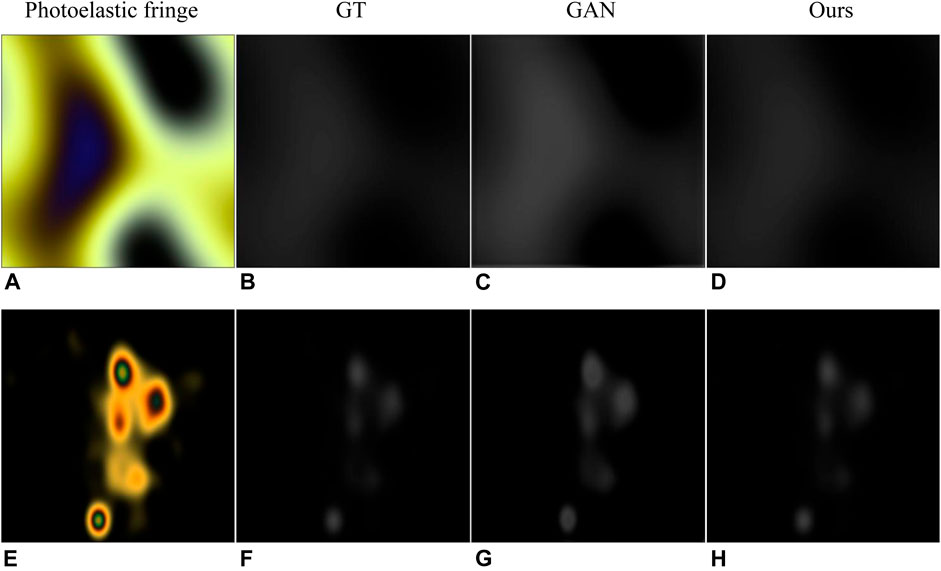
FIGURE 6. Results of comparison with GAN (Briñez de León et al., 2020c). (A,E) are photoelastic fringes obtained with Willard_LED and incandescent light sources, respectively. (B,F) are corresponding ground truth. (C,G) are the results in the GAN. (D,H) are the results of our method.
4.3 Comparison With Different Loss Functions
In order to construct the most effective loss function to accurately recover the stress map, we compare the image recovery effect of the models trained under different loss functions. 20,000 images were used to evaluate each indicator to avoid accidental errors. The experimental conditions were the same except for different loss functions. The experimental results of each evaluation index are shown in Tables 5, 6. The results show that compared with using MSE and MS-SSIM as loss functions alone, the fusion of multiple loss function mix as shown in Eq. 11 can achieve better image recovery quality. Figure 7 shows a concrete example of stress map recovery under different loss functions. When L1, L2, and L1+L2 are used as loss functions, as shown in Figures 7C–E, local details are lost in the stress map recovery, leading to inaccurate results. When MS-SSIM is used as a loss function, as shown in Figure 7F, complete local details are preserved, but the maximum stress difference in the stress concentration area is less than the true value. Using the fusion loss function mix, as shown in Figure 7G, the best effect is achieved in all evaluation indicators, which is almost consistent with the ground truth.
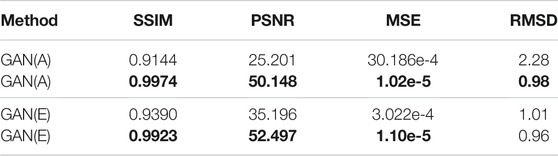
TABLE 5. Quantitative results of comparison with GAN (Briñez de León et al., 2020c). (a) and (e) represent the results of processing the photoelastic fringes in Figure 6. MSE is calculated after image normalization.

TABLE 6. Comparison of results of different loss functions. All the results are tested on 20000 images, and then the average and standard deviation are obtained. MSE is calculated after image normalization.
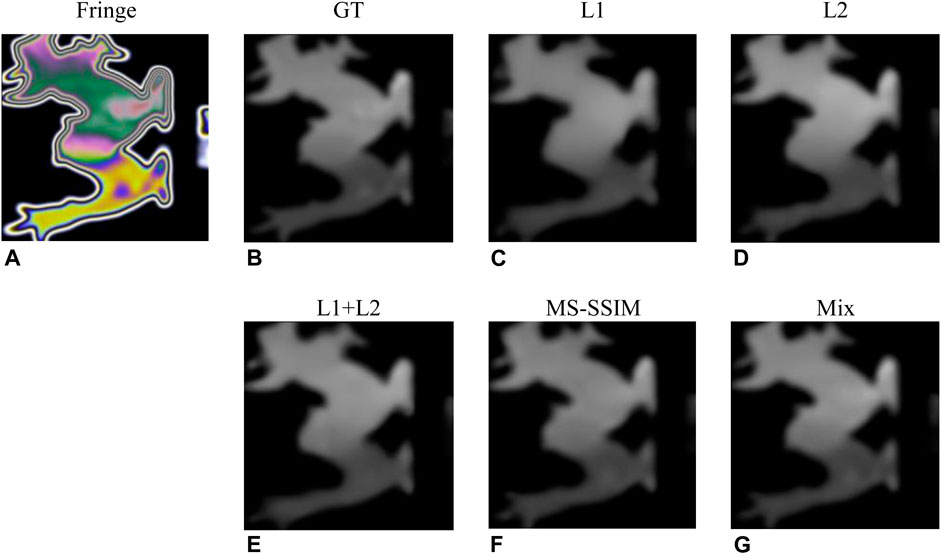
FIGURE 7. Results for different loss functions. (A,B) are image pairs randomly selected from the test set (Briñez-de León et al., 2020e) and (C–G) are the stress maps recovered under different loss functions.
4.4 Further Result Analysis
The prediction of the stress concentration area is the key point of practical engineering because it has a great influence on the fatigue life of components. We compared the maximum stress difference between the predicted stress map and ground truth and calculated the ratio of the maximum stress difference among 20,000 randomly selected image pairs.
The experimental results show that the average RMSD value of 20,000 predicted and real stress maps is 1.0109, and the standard deviation is 0.0652. This indicates that our network model accurately predicts the maximum stress difference in the stress concentration area with very dense fringes, which is the benefit brought by the fusion of MS-SSIM and L1. Multiloss function fusion not only considers the change of global value but also has a good effect on optimizing the local minimum value in the training process. Figures 8, 9 list some specific examples. The color fringe images in Figure 8 are obtained by using a Sony_IMX250 camera sensor with a constant light source, and its maximum stress value is 72 MPa. Table 7 shows all the metric values of the recovered stress maps in Figure 8. The SSIM values of Figures 8C,F both exceed 0.99, and the maximum stress difference of them are 68.5 and 73.5 MPa, respectively. The results show that the maximum principal stress difference appears in the area with dense fringes, and their maximum stress difference error is less than 5%.
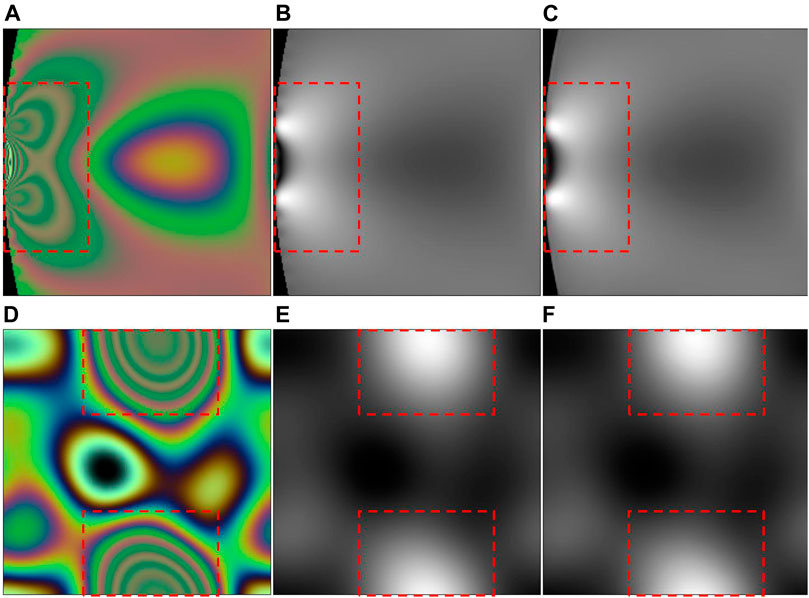
FIGURE 8. Stress concentration zones. Photoelastic fringes (A,D) and corresponding stress maps (B,E) are selected from the test set (Briñez-de León et al., 2020e). (C,F) are stress maps recovered by our proposed method. The region inside the red box is the stress concentration zone.
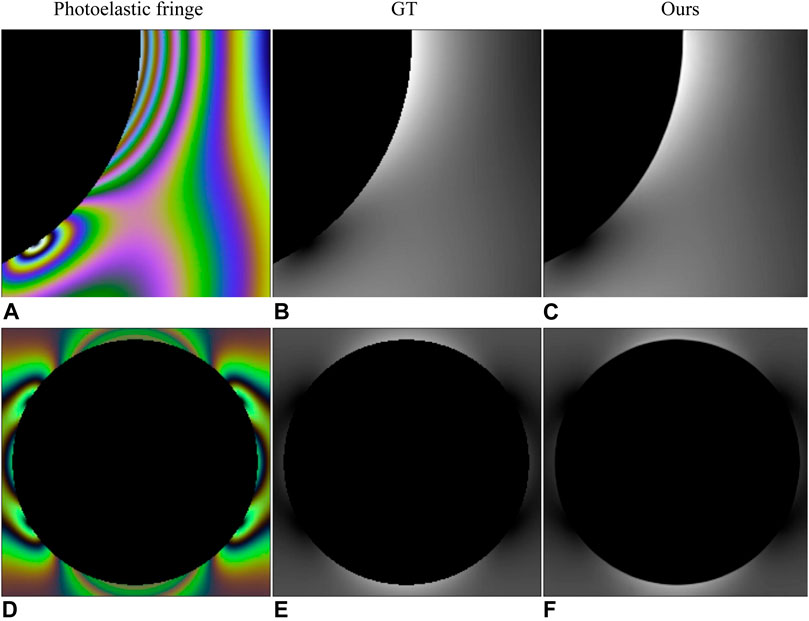
FIGURE 9. Edge of the stress map. Photoelastic fringes (A,D) and corresponding stress maps (B,E) are selected from the test set (Briñez-de León et al., 2020e). (C,F) are stress maps recovered by the proposed method. (A) is obtained by the human vision camera sensor with a cold white laser as the light source, and the maximum stress value of (B) is 72 MPa. (D) is obtained by a Sony_IMX 250 camera sensor with Willard_LED as the light source, and the maximum stress value of (e) is 48 MPa.

TABLE 7. All the metric values of the recovered stress maps in Figure 8.
In order to evaluate the performance of the proposed method at image edges, Figure 9 shows that the predicted stress map is very smooth in the edge area of the pattern, and the SSIM between the estimated stress map and ground truth in the edge area can reach 0.99. From the perspective of human vision, the prediction of stress concentration zones and edges is almost consistent with the ground truth. Table 8 shows all the metric values of the recovered stress maps in Figure 9.

TABLE 8. All the metric values of the recovered stress maps in Figure 9.
When solving the stress field of complex geometric objects under different experimental conditions, there were some problems in the previous study, such as complicated calculation methods and inaccurate calculation results. Figure 10 shows the advantage of our method in solving the stress field of complex geometry. Due to the strong unwrapping ability of the network model, the stress field recovery of the complex fringe pattern performs well in the edge and stress concentration area. The predicted results of the stress map in the first two rows in Figure 10 can reach 0.99 on the SSIM, and the more complex patterns in the last two rows can also exceed 0.97. Table 9 shows all the metric values of the recovered stress maps in Figure 10.
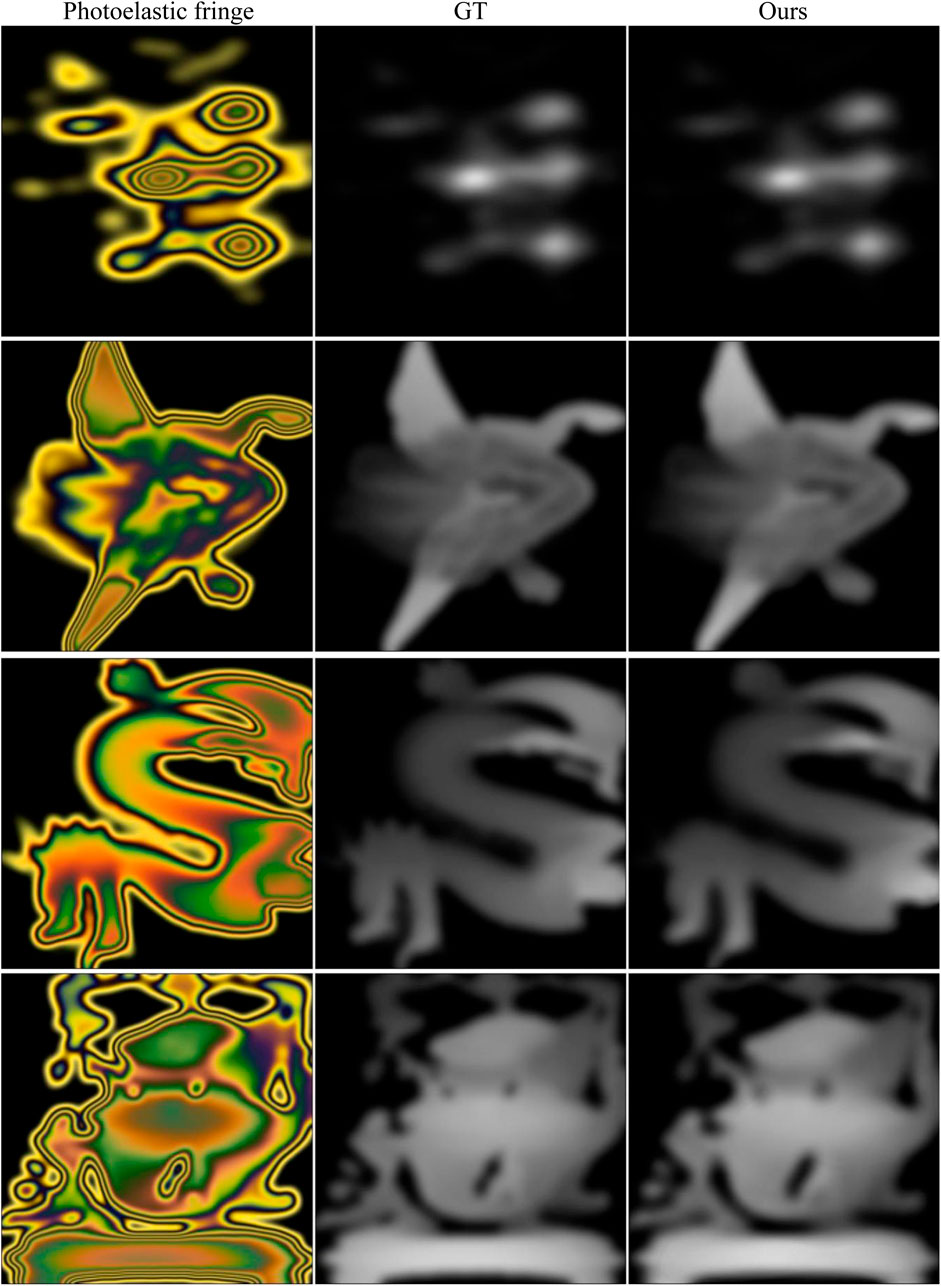
FIGURE 10. Stress recovery results of complex fringe patterns. First column: photoelastic color fringe pattern; second column: ground truth; third column: predicted stress map. All fringe patterns and corresponding stress maps are selected from the test set (Briñez-de León et al., 2020e). The maximum stress values of the ground truth from top to bottom are 72, 48, 48, and 60 MPa.
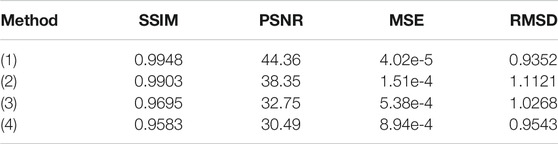
TABLE 9. All the metric values of the recovered stress maps in Figure 10.
4.5 Experimental Cases
The model was also evaluated when dealing with experimental cases. Based on experiments in literature (Restrepo Martínez and Branch Bedoya, 2020), 12 images were selected to fine-tune the network, and the remaining four images were used to test the performance of the network model. In the experiment, an LED was used as the light source, different loads were applied in a circularly polarized light field, and the photoelastic images were captured by the camera sensor DCC3260. The ground truth is generated by simulation. The test results are shown in Figure 11 and Table 10.
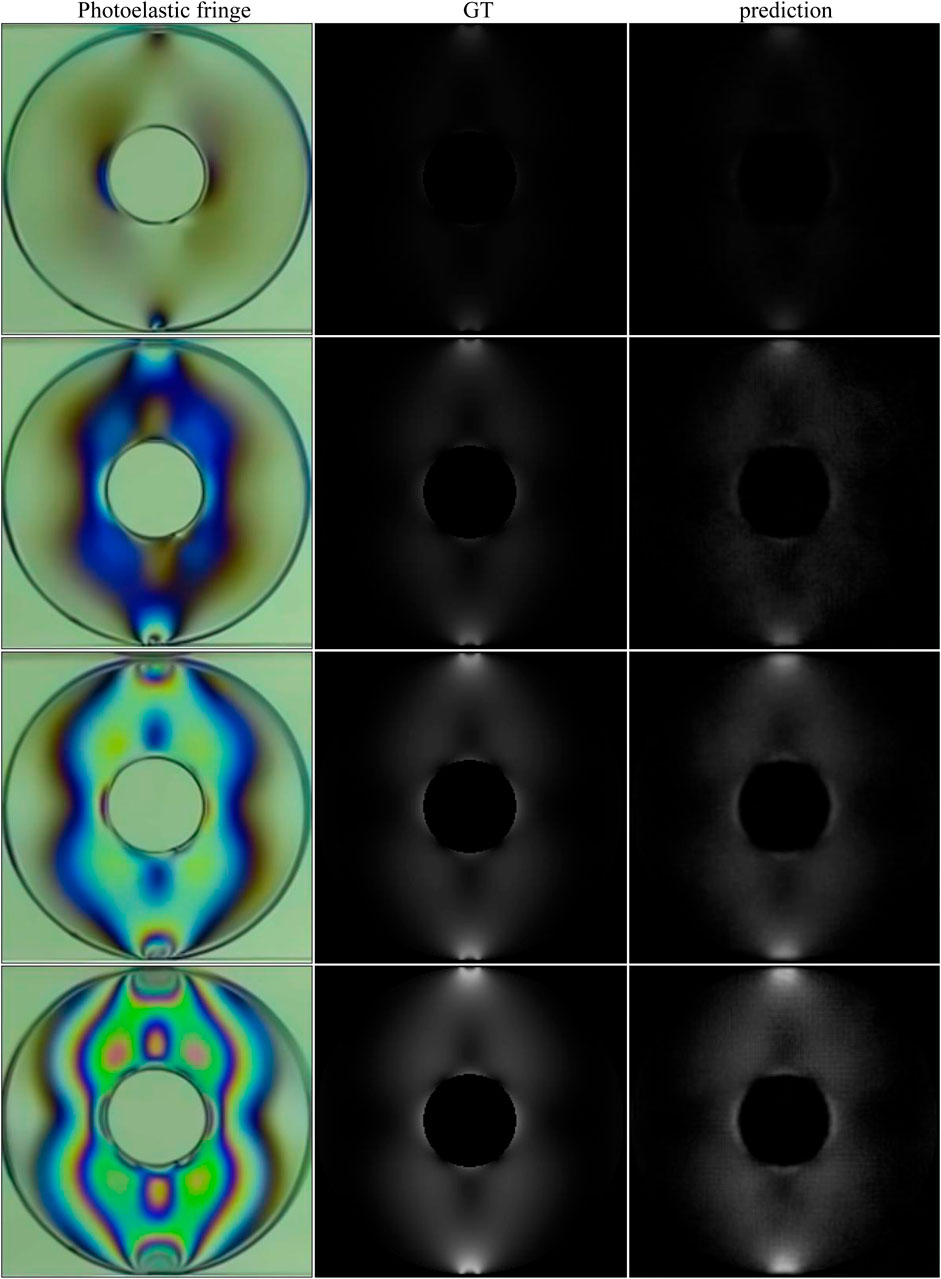
FIGURE 11. Stress recovery results of experimental cases. First column: photoelastic color fringe pattern; second column: ground truth generated by simulation; third column: predicted stress map.
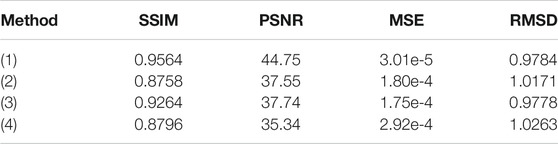
TABLE 10. All the metric values of the recovered stress maps in Figure 11.
5 Conclusion
We propose a deep convolutional neural network based on the encoder–decoder structure and design an objective optimization function weighted with multiple loss functions to recover the stress field distribution from color photoelastic fringe patterns. Verification results on open data sets show that our stress field recovery model can achieve an average performance of 0.99 on the SSIM. Other indexes also show that the model has the ability to accurately recover the stress map. When testing the photoelastic fringe patterns with complex geometry under different experimental conditions, our model still shows excellent generalization performance and strong unwrapping ability.
However, the proposed method only calculates the difference of principal stress. In practice, we also want to know the specific component of principal stress. In the future, a dataset containing principal stress components will be built, and then the principal stress can be obtained through the deep convolutional neural network.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Author Contributions
BT provided research ideas and plans; YW and FH wrote programs and conducted experiments; XQ proposed suggestions for improving the experimental methods; and XT, BC, WY, and BJC analyzed the results of the experiment and gave suggestions for writing the manuscript. All authors contributed to the writing and editing of the article and approved the submitted version.
Funding
This project is supported by the National Natural Science Foundation of China (Nos. 51505349, 71501148, 52075530, 51575407, and 51975324), Hubei Provincial Department of Education (D20201106), and the Open Fund of Hubei Key Laboratory of Hydroelectric Machinery Design & Maintenance in Three Gorges University(2021KJX13).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ajovalasit, A., Petrucci, G., and Scafidi, M. (2015). Review of RGB Photoelasticity. Opt. Lasers Eng. 68, 58–73. doi:10.1016/j.optlaseng.2014.12.008
Briñez de León, J. C., Rico, M., Branch, J. W., and Restrepo Martínez, A. (2020a). Pattern Recognition Based Strategy to Evaluate the Stress Field from Dynamic Photoelasticity Experiments. Opt. Photon. Inf. Process. XIV 11509, 112–126. SPIE. doi:10.1117/12.2568630
Briñez de León, J. C., Rico, M., Branch, J. W., and Restrepo-Martínez, A. (2020b). StressNet: A Deep Convolutional Neural Network for Recovering the Stress Field from Isochromatic Images. Appl. Digital Image Process. XLIII 11510, 126–137. SPIE. doi:10.1117/12.2568609
Briñez de León, J. C., Fonnegra, R. D., and Restrepo-Martínez, A. (2020c). Generalized Adversarial Networks for Stress Field Recovering Processes from Photoelasticity Images. Appl. Digital Image Process. XLIII 11510, 138–147. SPIE. doi:10.1117/12.2568700
Briñez-de León, J. C., Branch, J. W., and Restrepo-M, A. (2020d). “Toward Photoelastic Sensors: a Hybrid Proposal for Imaging the Stress Field through Load Stepping Methods,” in Computational Optical Sensing and Imaging (Washington: Optical Society of America), CTh3C–4. doi:10.1364/COSI.2020.CTh3C.4)
Brinez-de León, J. C., Rico-Garcıa, M., Restrepo-Martınez, A., and Branch, J. W. (2020e). Isochromatic-art: A Computational Dataset for Evaluating the Stress Distribution of Loaded Bodies by Digital Photoelasticity. Mendeley Data. v4 Available from: https://data.mendeley.com/datasets/z8yhd3sj23/4.
Briñez-de León, J. C., Rico-García, M., and Restrepo-Martínez, A. (2022). PhotoelastNet: a Deep Convolutional Neural Network for Evaluating the Stress Field by Using a Single Color Photoelasticity Image. Appl. Opt. 61 (7), D50–D62. doi:10.1364/AO.444563
Chen, T., Peng, L., Yang, J., Cong, G., and Li, G. (2021a). Evolutionary Game of Multi-Subjects in Live Streaming and Governance Strategies Based on Social Preference Theory during the COVID-19 Pandemic. Mathematics 9 (21), 2743. doi:10.3390/math9212743
Chen, T., Yin, X., Yang, J., Cong, G., and Li, G. (2021b). Modeling Multi-Dimensional Public Opinion Process Based on Complex Network Dynamics Model in the Context of Derived Topics. Axioms 10 (4), 270. doi:10.3390/axioms10040270
Chen, T., Qiu, Y., Wang, B., and Yang, J. (2022). Analysis of Effects on the Dual Circulation Promotion Policy for Cross-Border E-Commerce B2B Export Trade Based on System Dynamics during COVID-19. Systems 10 (1), 13. doi:10.3390/systems10010013
Cheng, Y., Li, G., Yu, M., Jiang, D., Yun, J., Liu, Y., et al. (2021). Gesture Recognition Based on Surface Electromyography ‐feature Image. Concurrency Computat Pract. Exper 33 (6), e6051. doi:10.1002/cpe.6051
Choi, M. G., Jung, J. H., and Jeon, J. W. (2009). No-reference Image Quality Assessment Using Blur and Noise. Int. J. Comp. Sci. Eng. 3 (2), 76–80. doi:10.5281/zenodo.1078462
Ding, X., Zhang, X., Ma, N., Han, J., Ding, G., and Sun, J. (2021). “Repvgg: Making Vgg-Style Convnets Great Again,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, June 2021 (IEEE), 13733–13742. doi:10.1109/CVPR46437.2021.01352
Dong, X., Pan, X., Liu, C., and Zhu, J. (2018). Single Shot Multi-Wavelength Phase Retrieval with Coherent Modulation Imaging. Opt. Lett. 43 (8), 1762–1765. doi:10.1364/OL.43.001762
Duan, H., Sun, Y., Cheng, W., Jiang, D., Yun, J., Liu, Y., et al. (2021). Gesture Recognition Based on Multi‐modal Feature Weight. Concurrency Computat Pract. Exper 33 (5), e5991. doi:10.1002/cpe.5991
Feng, S., Chen, Q., Gu, G., Tao, T., Zhang, L., Hu, Y., et al. (2019). Fringe Pattern Analysis Using Deep Learning. Adv. Photon. 1 (2), 1. doi:10.1117/1.AP.1.2.025001
Godard, C., Aodha, O. M., and Brostow, G. J. (2017). “Unsupervised Monocular Depth Estimation with Left-Right Consistency,” in Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, July 2017 (IEEE), 6602–6611. doi:10.1109/CVPR.2017.699
Gondal, M. W., Schölkopf, B., and Hirsch, M. (2019). “The Unreasonable Effectiveness of Texture Transfer for Single Image Super-resolution,” in European Conference on Computer Vision (Cham: Springer), 80–97. doi:10.1007/978-3-030-11021-5_6
Gongfa Li, G., Jiang, D., Zhou, Y., Jiang, G., Kong, J., and Manogaran, G. (2019). Human Lesion Detection Method Based on Image Information and Brain Signal. IEEE Access 7, 11533–11542. doi:10.1109/ACCESS.2019.2891749
Gupta, P., Srivastava, P., Bhardwaj, S., and Bhateja, V. (2011). “A Modified PSNR Metric Based on HVS for Quality Assessment of Color Images,” in Proceedings of the 2011 International Conference on Communication and Industrial Application, Kolkata, India, Dec. 2011 (IEEE), 1–4. doi:10.1109/ICCIndA.2011.6146669
Hao, Z., Wang, Z., Bai, D., Tao, B., Tong, X., and Chen, B. (2021). Intelligent Detection of Steel Defects Based on Improved Split Attention Networks. Front. Bioeng. Biotechnol. 9, 810876. doi:10.3389/fbioe.2021.810876
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, June 2016 (IEEE), 770–778. doi:10.1109/CVPR.2016.90
Huang, L., He, M., Tan, C., Jiang, D., Li, G., and Yu, H. (2020). Jointly Network Image Processing: Multi‐task Image Semantic Segmentation of Indoor Scene Based on CNN. IET image process 14 (15), 3689–3697. doi:10.1049/iet-ipr.2020.0088
Huang, L., Fu, Q., He, M., Jiang, D., and Hao, Z. (2021). Detection Algorithm of Safety Helmet Wearing Based on Deep Learning. Concurrency Computat Pract. Exper 33 (13), e6234. doi:10.1002/cpe.6234
Huang, Z., and Cao, L. (2020). Bicubic Interpolation and Extrapolation Iteration Method for High Resolution Digital Holographic Reconstruction. Opt. Lasers Eng. 130, 106090. doi:10.1016/j.optlaseng.2020.106090
Ioffe, S., and Szegedy, C. (2015). “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” in International Conference on Machine Learning (Lille, France: PMLR), 448–456. Available from: http://proceedings.mlr.press/v37/ioffe15.html.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017). “Image-to-image Translation with Conditional Adversarial Networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, July 2017 (IEEE), 1125–1134. doi:10.1109/CVPR.2017.632
Jiang, D., Zheng, Z., Li, G., Sun, Y., Kong, J., Jiang, G., et al. (2019a). Gesture Recognition Based on Binocular Vision. Cluster Comput. 22 (6), 13261–13271. doi:10.1007/s10586-018-1844-5
Jiang, D., Li, G., Sun, Y., Kong, J., and Tao, B. (2019b). Gesture Recognition Based on Skeletonization Algorithm and CNN with ASL Database. Multimed Tools Appl. 78 (21), 29953–29970. doi:10.1007/s11042-018-6748-0
Jiang, D., Li, G., Tan, C., Huang, L., Sun, Y., and Kong, J. (2021a). Semantic Segmentation for Multiscale Target Based on Object Recognition Using the Improved Faster-RCNN Model. Future Generation Comp. Syst. 123, 94–104. doi:10.1016/j.future.2021.04.019
Jiang, D., Li, G., Sun, Y., Hu, J., Yun, J., and Liu, Y. (2021b). Manipulator Grabbing Position Detection with Information Fusion of Color Image and Depth Image Using Deep Learning. J. Ambient Intell. Hum. Comput 12, 10809–10822. doi:10.1007/s12652-020-02843-w
Li, C., Li, G., Jiang, G., Chen, D., and Liu, H. (2020). Surface EMG Data Aggregation Processing for Intelligent Prosthetic Action Recognition. Neural Comput. Applic 32 (22), 16795–16806. doi:10.1007/s00521-018-3909-z
Liao, S., Li, G., Wu, H., Jiang, D., Liu, Y., Yun, J., et al. (2021). Occlusion Gesture Recognition Based on Improved SSD. Concurrency Computat Pract. Exper 33 (6), e6063. doi:10.1002/cpe.6063
Ma, R., Zhang, L., Li, G., Jiang, D., Xu, S., and Chen, D. (2020). Grasping Force Prediction Based on sEMG Signals. Alexandria Eng. J. 59 (3), 1135–1147. doi:10.1016/j.aej.2020.01.007
Markides, C. F., and Kourkoulis, S. K. (2012). The Stress Field in a Standardized Brazilian Disc: The Influence of the Loading Type Acting on the Actual Contact Length. Rock Mech. Rock Eng. 45 (2), 145–158. doi:10.1007/s00603-011-0201-2
Ng, T. W. (1997). Photoelastic Stress Analysis Using an Object Step-Loading Method. Exp. Mech. 37 (2), 137–141. doi:10.1007/BF02317849
Ramesh, K., Kasimayan, T., and Neethi Simon, B. (2011). Digital Photoelasticity - A Comprehensive Review. J. Strain Anal. Eng. Des. 46 (4), 245–266. doi:10.1177/0309324711401501
Ramesh, K., and Sasikumar, S. (2020). Digital Photoelasticity: Recent Developments and Diverse Applications. Opt. Lasers Eng. 135, 106186. doi:10.1016/j.optlaseng.2020.106186
Restrepo Martínez, A., and Branch Bedoya, J. W. (2020). Evaluación del campo de esfuerzos mediante el análisis, descripción y clasificación de la dinámica temporal de secuencias de imágenes de fotoelasticidad. Available from: https://repositorio.unal.edu.co/handle/unal/78194.
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-net: Convolutional Networks for Biomedical Image Segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Cham: Springer), 234–241. doi:10.1007/978-3-319-24574-4_28
Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychol. Rev. 65 (6), 386–408. doi:10.1037/h0042519
Sergazinov, R., and Kramár, M. (2021). Machine Learning Approach to Force Reconstruction in Photoelastic Materials. Mach. Learn. Sci. Technol. 2 (4), 045030. doi:10.1088/2632-2153/ac29d5
Simonyan, K., and Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv:1409.1556 Available from: http://arxiv.org/abs/1409.1556.
Sun, Y., Xu, C., Li, G., Xu, W., Kong, J., Jiang, D., et al. (2020a). Intelligent Human Computer Interaction Based on Non Redundant EMG Signal. Alexandria Eng. J. 59 (3), 1149–1157. doi:10.1016/j.aej.2020.01.015
Sun, Y., Weng, Y., Luo, B., Li, G., Tao, B., Jiang, D., et al. (2020b). Gesture Recognition Algorithm Based on Multi‐scale Feature Fusion in RGB‐D Images. IET image process 14 (15), 3662–3668. doi:10.1049/iet-ipr.2020.0148
Sun, Y., Hu, J., Li, G., Jiang, G., Xiong, H., Tao, B., et al. (2020c). Gear Reducer Optimal Design Based on Computer Multimedia Simulation. J. Supercomput 76 (6), 4132–4148. doi:10.1007/s11227-018-2255-3
Sun, Y., Yang, Z., Tao, B., Jiang, G., Hao, Z., and Chen, B. (2021). Multiscale Generative Adversarial Network for Real‐world Super‐resolution. Concurrency Computat Pract. Exper 33 (21), e6430. doi:10.1002/cpe.6430
Sun, Y., Zhao, Z., Jiang, D., Tong, X., Tao, B., Jiang, G., et al. (2022). Low-illumination Image Enhancement Algorithm Based on Improved Multi-Scale Retinex and ABC Algorithm Optimization. Front. Bioeng. Biotechnol. doi:10.3389/fbioe.2022.865820
Tan, C., Sun, Y., Li, G., Jiang, G., Chen, D., and Liu, H. (2020). Research on Gesture Recognition of Smart Data Fusion Features in the IoT. Neural Comput. Applic 32 (22), 16917–16929. doi:10.1007/s00521-019-04023-0
Tao, B., Huang, L., Zhao, H., Li, G., and Tong, X. (2021). A Time Sequence Images Matching Method Based on the Siamese Network. Sensors 21 (17), 5900. doi:10.3390/s21175900
Tao, B., Liu, Y., Huang, L., Chen, G., and Chen, B. (2022). 3D Reconstruction Based on Photoelastic Fringes. Concurrency Computat Pract. Exper 34 (1), e6481. doi:10.1002/cpe.6481
Wang, K., Li, Y., Kemao, Q., Di, J., and Zhao, J. (2019). One-step Robust Deep Learning Phase Unwrapping. Opt. Express 27 (10), 15100–15115. doi:10.1364/OE.27.015100
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. (2004). Image Quality Assessment: from Error Visibility to Structural Similarity. IEEE Trans. Image Process. 13 (4), 600–612. doi:10.1109/TIP.2003.819861
Wang, Z., Simoncelli, E. P., and Bovik, A. C. (2003). “Multiscale Structural Similarity for Image Quality Assessment,” in Proceeding of The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, Pacific Grove, CA, USA, November 2003 (IEEE), 1398–1402. Vol. 2. doi:10.1109/ACSSC.2003.1292216
Weng, Y., Sun, Y., Jiang, D., Tao, B., Liu, Y., Yun, J., et al. (2021). Enhancement of Real‐time Grasp Detection by Cascaded Deep Convolutional Neural Networks. Concurrency Computat Pract. Exper 33 (5), e5976. doi:10.1002/CPE.5976
Wu, X., Jiang, D., Yun, J., Liu, X., Sun, Y., Tao, B., et al. (2022). Attitude Stabilization Control of Autonomous Underwater Vehicle Based on Decoupling Algorithm and PSO-ADRC. Front. Bioeng. Biotechnol. doi:10.3389/fbioe.2022.843020
Xin Liu, X., Jiang, D., Tao, B., Jiang, G., Sun, Y., Kong, J., et al. (2021). Genetic Algorithm-Based Trajectory Optimization for Digital Twin Robots. Front. Bioeng. Biotechnol. 9, 793782. doi:10.3389/fbioe.2021.793782
Xiu Li, X., Qi, H., Jiang, S., Song, P., Zheng, G., and Zhang, Y. (2019). Quantitative Phase Imaging via a cGAN Network with Dual Intensity Images Captured under Centrosymmetric Illumination. Opt. Lett. 44 (11), 2879–2882. doi:10.1364/OL.44.002879
Yang, Z., Jiang, D., Sun, Y., Tao, B., Tong, X., Jiang, G., et al. (2021). Dynamic Gesture Recognition Using Surface EMG Signals Based on Multi-Stream Residual Network. Front. Bioeng. Biotechnol. 9, 779353. doi:10.3389/fbioe.2021.779353
Ying Liu, Y., Jiang, D., Yun, J., Sun, Y., Li, C., Jiang, G., et al. (2021). Self-tuning Control of Manipulator Positioning Based on Fuzzy PID and PSO Algorithm. Front. Bioeng. Biotechnol. 9, 817723. doi:10.3389/fbioe.2021.817723
Zhang, X., Xiao, F., Tong, X., Yun, J., Liu, Y., Sun, Y., et al. (2022). Time Optimal Trajectory Planing Based on Improved Sparrow Search Algorithm. Front. Bioeng. Biotechnol. doi:10.3389/fbioe.2022.852408
Zhao, H., Gallo, O., Frosio, I., and Kautz, J. (2017). Loss Functions for Image Restoration with Neural Networks. IEEE Trans. Comput. Imaging 3 (1), 47–57. doi:10.1109/TCI.2016.2644865
Keywords: neural network, deep learning, inverse problem solving, stress evaluation, digital photoelasticity
Citation: Tao B, Wang Y, Qian X, Tong X, He F, Yao W, Chen B and Chen B (2022) Photoelastic Stress Field Recovery Using Deep Convolutional Neural Network. Front. Bioeng. Biotechnol. 10:818112. doi: 10.3389/fbioe.2022.818112
Received: 19 November 2021; Accepted: 22 February 2022;
Published: 21 March 2022.
Edited by:
Tinggui Chen, Zhejiang Gongshang University, ChinaReviewed by:
Juan Carlos Briñez De León, Pascual Bravo Institute of Technology, ColombiaAlejandro Restrepo Martinez, National University of Colombia, Medellin, Colombia
Copyright © 2022 Tao, Wang, Qian, Tong, He, Yao, Chen and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bo Tao, dGFvYm9xQHd1c3QuZWR1LmNu; Yan Wang, d2FuZ3lhbkB3dXN0LmVkdS5jbg==; Baojia Chen, YmppYUAxNjMuY29t