 Ahmed Abdulhadi Ahmed1
Ahmed Abdulhadi Ahmed1 Zakariya Yahya Algamal
Zakariya Yahya Algamal Olayan Albalawi
Olayan Albalawi- 1Department of Statistics and Informatics, University of Mosul, Mosul, Iraq
- 2Department of Statistics, Faculty of Science, University of Tabuk, Tabuk, Saudi Arabia
The exponentiated Teissier distribution (ETD) offers an alternative for modeling survival data, taking into account flexibility in modeling data with increasing and decreasing hazard rate functions. The most popular method for parameter estimation of the ETD distribution is the maximum likelihood estimation (MLE). The MLE, on the other hand, is notoriously biased for its small sample sizes. We are therefore driven to generate virtually unbiased estimators for ETD parameters. More specifically, we focus on two methods of bias correction, bootstrapping and analytical approaches, to reduce MLE biases to the second order of bias. The performances of these approaches are compared through Monte Carlo simulations and two real-data applications.
1 Introduction
Time-to-event data analysis can be performed statistically using survival data analysis. The time until an event of interest occurs is the main result of interest in survival analysis (1). This could be a number of things, such as the amount of time until a patient relapses, a machine breaks down, or a customer leaves. Statistical modeling of survival data entails modeling and analyzing the amount of time until an event of interest through statistical techniques.
An essential component of survival analysis is selecting a statistical distribution to model survival data (2). The instantaneous failure rate at any given moment is represented by the underlying hazard function, about which different distributions make different assumptions. The properties of the survival data and the underlying biological or physical processes should direct the choice of distribution. Visual evaluations, domain expertise, and goodness-of-fit tests can all be used to guide the selection of a model (3, 4).
In the area of survival analysis, the Teissier distribution is frequently utilized for modeling survival data (5–7). Sharma and Singh (5) presented exponentiated Teissier distributions (ETDs) by adding an extra shape parameter to a well-known baseline distribution. The Teissier distribution is different from other distributions such as Weibull, Gompertz, gamma, and Maxwell distributions in modeling bathtub and upside-down bathtub failure rate functions (5).
The capacity of the Teissier distribution to represent many survival rate phases, such as the growing, constant, and decreasing phases seen in a bathtub failure rate function, is its main advantage. Because it can support many forms and changes in these stages, it is a helpful tool for simulating intricate survival issues.
The Tessier distribution has the following cumulative distribution function (CDF):
The ETD is defined by CDF:
The probability density function (PDF) of the ETD is:
2 Maximum likelihood estimation
Suppose that be a random sample of size from the ETD distribution. The log-likelihood function of and is given by:
Maximize Eq. (4) with respect to and in order to obtain the MLE ( and ) of and , respectively. We have the following equations:
Since Eqs. (5) and (6) are non-linear, they cannot be solved analytically. MLE will be biased by small sample sizes. Therefore, it gives misleading results, which affects the interpretation of phenomena in real-life applications. This motivates us to consider unbiased estimates, almost to reduce the bias of this MLE distribution of these parameters.
3 Bias-corrected MLEs
A statistical method called bias-corrected maximum likelihood estimation (BC-MLE) is used to account for bias in parameter estimations that are derived from MLE. When the average value of the estimates, computed across a large number of samples, differs from the true parameter value, the concept of bias in MLE emerges. In order to give more accurate parameter estimates, bias-corrected (BC) approaches try to minimize or completely remove this systematic mistake (8–10).
To evaluate the bias and apply corrections, methods such as the corrective approach (CA) and bootstrapping are frequently used (11). This method is useful when bias could compromise the validity of statistical conclusions. In the literature, inspired by these two approaches, a large number of authors tackled the BC-MLE issue. Among them are: (12–41).
3.1 A corrective approach
Suppose is the log-likelihood function of a p-dimensional parameter based on a sample of observations . The joint cumulants of the derivatives of the log-likelihood function for are given by:
where the derivatives of the joint cumulants are given by:
The log-likelihood function is well-behaved and regular for all derivatives up to third order.
Cox and Snell (42) showed that when sample data are independent but not always identically distributed, the bias of the sth element of the MLE of τ is:
where Mij is the (i, j)th element of the inverse of the Fisher information matrix. Then, Cordeiro and Cribari-Neto (8) observed that the bias expression still holds if the observations are not independent. They recommended the following convenient form as appropriate instead of Eq. (11).
Since, Eq. (12) does not contain the terms of the form defined in Eqs. (10), (12) has a computational advantage over Eq. (11).
Then, let It is Fisher’s information matrix of τ, and let they are elements matrix for . We have , with .
Accordingly, the bias expression of can then be written in matrix form as:
Thus, this shows that the BC-MLE of using the CA-MLE, , is given by:
where is the MLE of , , and . Whereas the bias of is quadratic. Related to ETD distribution, the derivatives are obtained (Supplementary Material).
Then,
with
where is defined in the Appendix section. Therefore, the bias MLE of ETD distribution is given by:
And then,
3.2 Bootstrap approach
An alternative method based on the parametric bootstrap resampling methodology is used to produce second-order BC estimators (43, 44). Let be a random sample of size from the random variable with the distribution function . By generating independent bootstrap samples from distribution function , the estimated bias of the MLE of is:
where is the MLE of from the bootstrap sample generated from the ETD distribution. Then, the BC bootstrap (BC-Boot) approach is defined as:
4 Simulation results
This simulation study’s objective is to assess how well the several estimators of the ETD distribution’s parameters: MLE, CA-MLE, and BC-Boot perform. The ETD distribution was used to generate samples with sizes n = 10, 30, 50, and 100, with parameters , , and . Each case was generated with Monte Carlo samples 5,000 times and 1,000 bootstrap samples each time. To evaluate the accuracy of the parameter estimates, the bias and root mean squared error (RMSE) of the estimates, which are defined in Eqs. (21) and (22), respectively, are reported. All results of the averaged biases and RMSE are summarized in Tables 1–3.
From Tables 1–3, there are a few conclusions that can be reached:
1. For all the simulations considered, the MLE estimators of seem to be biased in the positive direction. This illustrates how, in general, they overstate the parameter value, particularly in cases where the sample size is small. Furthermore, when the real value of the parameter is equal to or larger than 1.5, the MLE estimators frequently exhibit a positive bias, that is, they continuously overestimate the true value of the parameter for various sample sizes.
2. The MLE estimators underperformed the CA-MLE and BC-Boot of and in terms of bias and RMSE in all simulations for different sample sizes. Further, the BC-Boot of and outperformed the CA-MLE in terms of RMSE. Additionally, in terms of bias, BC-Boot attained better performance than CA-MLE for . Conversely, CA-MLE attained better performance than BC-Boot for .
3. The biases and RMSEs of all examined estimators will naturally decline as sample size n increases. This is mostly because most estimators in statistical theory perform better as sample size n increases. As previously stated, for small sample numbers, both CA-MLE and BC-Boot show extremely significant reductions in bias and RMSE. For instance, from Table 3, in the case of n = 10, it can be seen that the reduction in RMSE of both CA-MLE and BC-Boot was approximately 13.13 and 13.42% for , and 62.96 and 60.63% for lower than that of the MLE. On the other hand, the reduction for the same case of both CA-MLE and BC-Boot in terms of bias was 16.86 and 16.99% for , and 58.37 and 58.63% for lower than that of the MLE, respectively.
4. Finally, although the two approaches, CA-MLE and BC-Boot, are equally efficient, BC-Boot is computationally easier than CA-MLE.
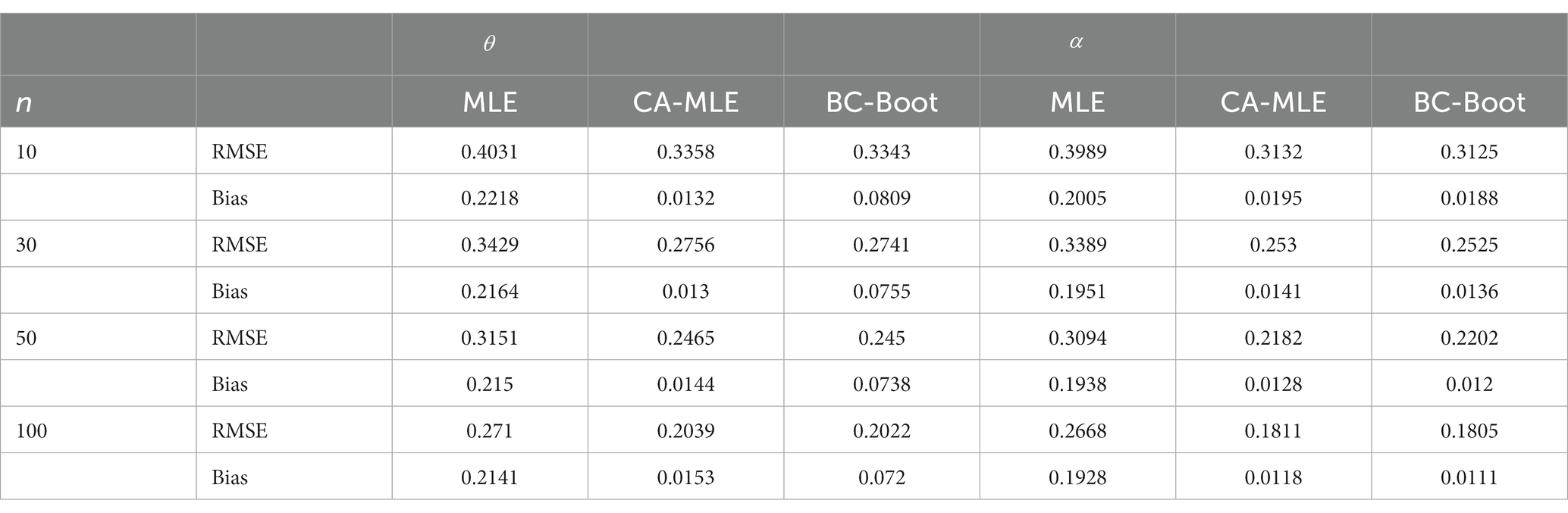
Table 1. Average RMSE and bias when .
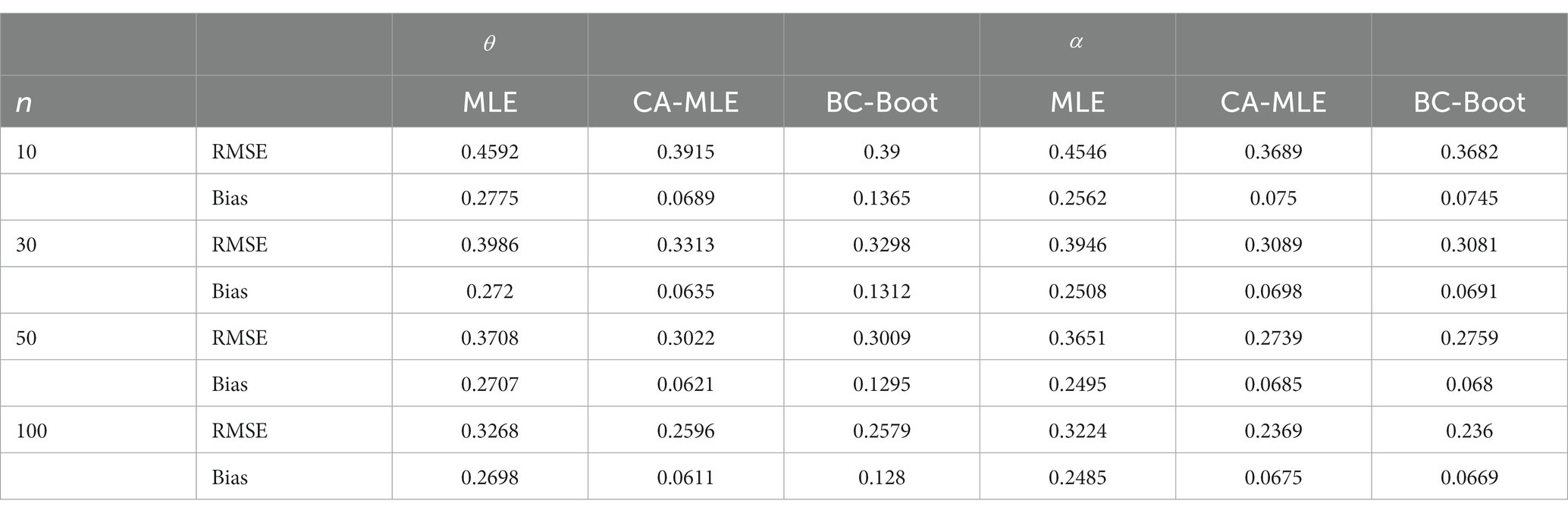
Table 2. Average RMSE and bias when .
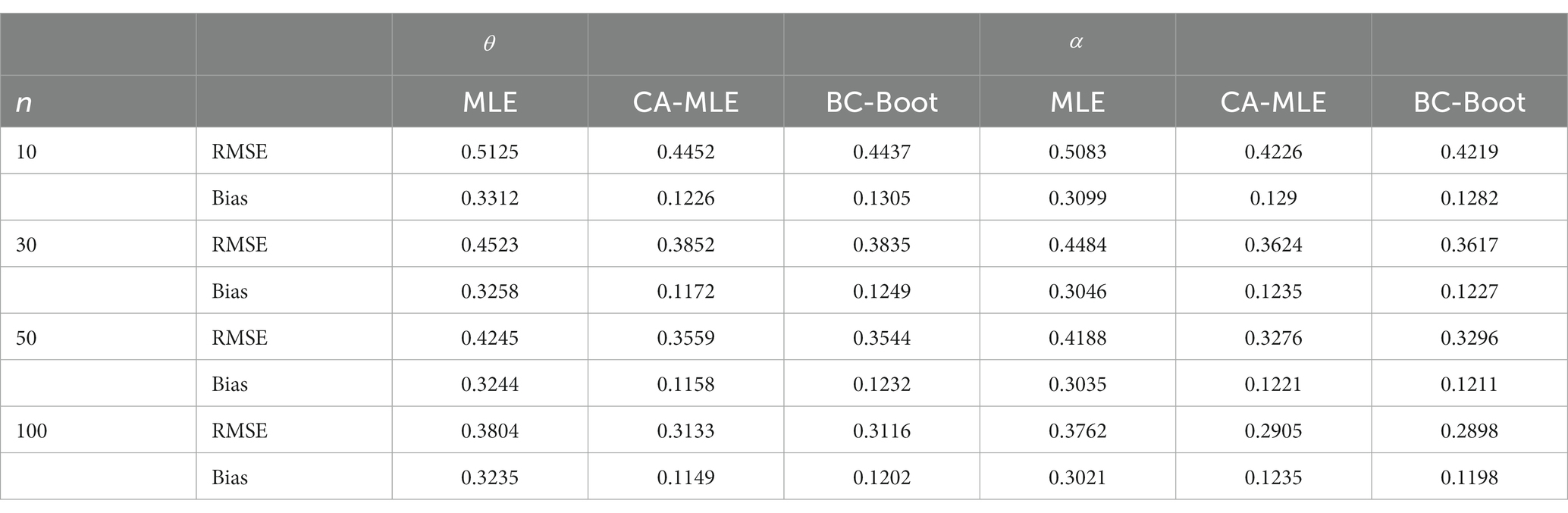
Table 3. Average RMSE and bias when .
5 Real data application
In this part, we use two real datasets with a small sample to demonstrate the usefulness of the suggested BC estimators for the ETD distribution. The first dataset represents the life time failure of 18 electronic devices (45). This data was further analyzed by Wang and Wang (38). The second dataset represents the tubes that show leaks under a 120 psi stress level (46). The sample size of this data is 30. This data was further analyzed by Çetinkaya and Bulut (17).
To check whether the first and second data belong to the ETD distribution, the Kolmogorov–Smirnov test as a goodness-of-fit is used. The result of the test for the first data set is 6.281, with a p-value of 0.611. On the other hand, the result of the goodness-of-fit for the second data set equals 8.068, with a p-value of 0.744. These results indicate that the ETD distribution can fit very well with these data.
Tables 4, 5 show the estimated values for the parameters of the alpha power exponential distribution. Tables 4, 5 demonstrate that the CA-MLE and BC-Boot estimates of and are less than the MLE estimate, indicating that the MLE approach overestimates this parameter.

Table 4. Point estimates of the and of ETD distribution for the electronic device data.

Table 5. Point estimates of the and of ETD distribution for the show leak data.
The analysis of the ETD distribution pdf in relation to Tables 4, 5 for and values of both datasets is shown in Figures 1, 2, respectively. We suggest using CA-MLE and BC-Boot estimates for both datasets because the density shape based on the MLE method may be deceptive, as this figure illustrates.
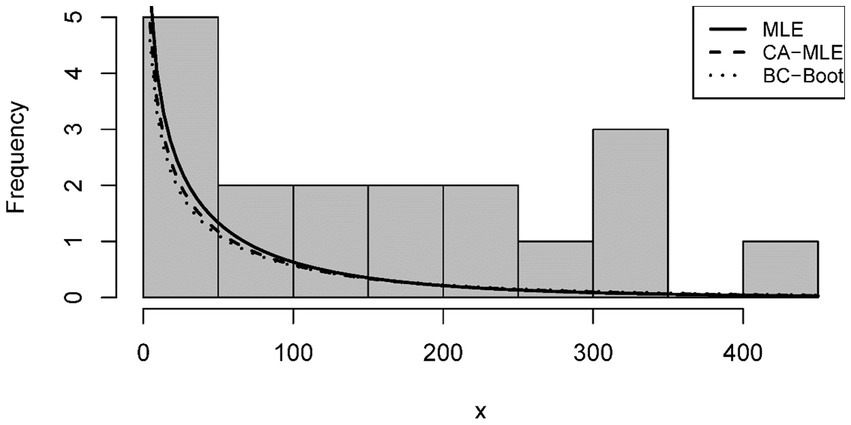
Figure 1. Estimated fitted density functions of the first dataset.
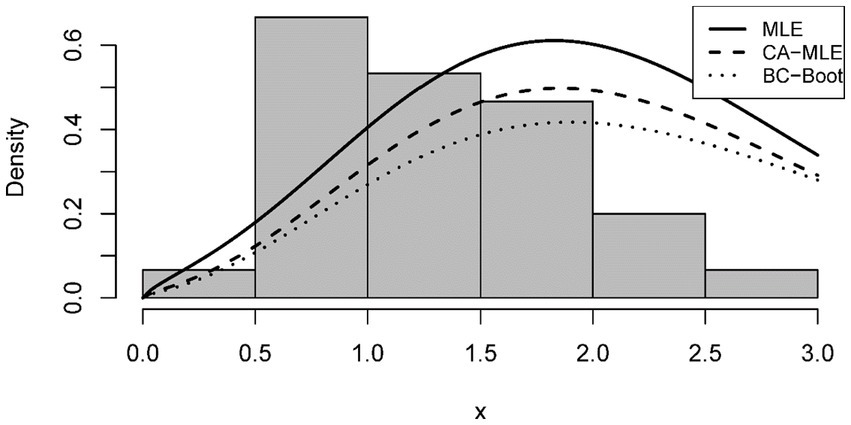
Figure 2. Estimated fitted density functions of the second dataset.
6 Conclusion
In order to obtain straightforward closed-form equations for the second-order biases of the MLE of the parameters of the ETD distribution, the corrective method was proposed in this paper. Namely: CA-MLE and BC-Boot. The newly proposed estimators converge to their real value significantly faster than the MLE, as evidenced by their biases being of order as opposed to for the MLE. The suggested approaches exceed the MLE in terms of bias and RMSE, as demonstrated by the numerical data, making them highly appealing. The suggested BC estimators are highly advised, particularly in cases where the sample size is small.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
AA: Formal analysis, Validation, Writing – original draft. ZA: Supervision, Writing – original draft, Writing – review & editing. OA: Methodology, Software, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2024.1351651/full#supplementary-material
References
1. Alanaz, MM, and Algamal, ZY. Neutrosophic exponentiated inverse Rayleigh distribution: properties and applications. Int. J. Neutrosophic Sci. (2023) 21:36–42. doi: 10.54216/IJNS.210404
2. Bibani, A, and Algamal, Z. Survival function estimation for fuzzy Gompertz distribution with neutrosophic data. Int. J. Neutrosophic Sci. (2023) 21:137–42. doi: 10.54216/IJNS.210313
3. Mustafa, MY, and Algamal, ZY. Neutrosophic inverse power Lindley distribution: a modeling and application for bladder cancer patients. Int J Neutrosophic Sci. (2023) 21:216–23. doi: 10.54216/IJNS.210218
4. Alanaz, MM, Mustafa, MY, and Algamal, ZY. Neutrosophic Lindley distribution with application for alloying metal melting point. Int. J. Neutrosophic Sci. (2023) 21:65–71. doi: 10.54216/IJNS.210407
5. Sharma, VK, Singh, SV, and Shekhawat, K. Exponentiated Teissier distribution with increasing, decreasing and bathtub hazard functions. J Appl Stat. (2022) 49:371–93. doi: 10.1080/02664763.2020.1813694
6. Jodra, P, Gomez, HW, Jimenez-Gamero, MD, and Alba-Fernandez, MV. The power Muth distribution∗. Math Model Anal. (2017) 22:186–201. doi: 10.3846/13926292.2017.1289481
7. Chesneau, C, and Agiwal, V. Statistical theory and practice of the inverse power Muth distribution. J. Comput. Math. Data Sci. (2021) 1:100004. doi: 10.1016/j.jcmds.2021.100004
8. Cordeiro, GM, and Cribari-Neto, F. An Introduction to Bartlett Correction and Bias Reduction. New York: Springer (2014).
9. Firth, D . Bias reduction of maximum likelihood estimates. Biometrika. (1993) 80:27–38. doi: 10.1093/biomet/80.1.27
10. Zhang, J . Bias correction for the maximum likelihood estimate of ability. ETS Res. Rep. Ser. (2005) 2005:i–39.
11. Stošić, BD, and Cordeiro, GM. Using maple and Mathematica to derive bias corrections for two parameter distributions. J Stat Comput Simul. (2009) 79:751–67. doi: 10.1080/00949650801911047
12. Afify, AZ, Aljohani, HM, Alghamdi, AS, Gemeay, AM, and Sarg, AM. A new two-parameter Burr-Hatke distribution: properties and Bayesian and non-Bayesian inference with applications. J. Math. (2021) 2021:1–16. doi: 10.1155/2021/1061083
13. Al-Shomrani, AA . An improvement in maximum likelihood estimation of the Burr XII distribution parameters. AIMS Math. (2022) 7:17444–60. doi: 10.3934/math.2022961
14. Al-Shomrani, AA . An improvement in maximum likelihood estimation of the Gompertz distribution parameters. J. Stat. Theory Appl. (2023) 22:98–115. doi: 10.1007/s44199-023-00057-5
15. Arrué, J, Arellano-Valle, RB, Calderín-Ojeda, E, Venegas, O, and Gómez, HW. Likelihood based inference and bias reduction in the modified skew-t-normal distribution. Math. (2023) 11:3287. doi: 10.3390/math11153287
16. Arrué, J, Arellano-Valle, RB, and Gómez, HW. Bias reduction of maximum likelihood estimates for a modified skew-normal distribution. J Stat Comput Simul. (2016) 86:2967–84. doi: 10.1080/00949655.2016.1143471
17. Çetinkaya, Ç, and Bulut, YM. Bias-reduced and heuristics parameter estimations for the inverse power Lindley distribution. Int J Model Simul. (2022) 43:600–11. doi: 10.1080/02286203.2022.2107865
18. Giles, DE . Bias reduction for the maximum likelihood estimators of the parameters in the half-logistic distribution. Commun. Stat. Theory Methods. (2012) 41:212–22. doi: 10.1080/03610926.2010.521278
19. Giles, DE . Improved maximum likelihood estimation for the Weibull distribution under length-biased sampling. J Quant Econ. (2021) 19:59–77. doi: 10.1007/s40953-021-00263-x
20. Giles, DE, Feng, H, and Godwin, RT. On the Bias of the maximum likelihood estimator for the two-parameter Lomax distribution. Commun. Stat. Theory Methods. (2013) 42:1934–50. doi: 10.1080/03610926.2011.600506
21. Giles, DE, Feng, H, and Godwin, RT. Bias-corrected maximum likelihood estimation of the parameters of the generalized Pareto distribution. Commun. Stat. Theory Methods. (2015) 45:2465–83. doi: 10.1080/03610926.2014.887104
22. Gómez, YM, Santos, B, Gallardo, DI, Venegas, O, and Gómez, HW. Bias reduction of maximum likelihood estimates for an asymmetric class of power models with applications. Revstat Stat J. (2023) 21:491–507. doi: 10.57805/revstat.v21i4.431
23. Hashemi, M, and Schneider, KA. Bias-corrected maximum-likelihood estimation of multiplicity of infection and lineage frequencies. PLoS One. (2021) 16:e0261889. doi: 10.1371/journal.pone.0261889
24. Honda, F, and Kurosawa, T. Bias reduction of a conditional maximum likelihood estimator for a Gaussian second-order moving average model. Mod. Stochastics Theory Appl. (2021) 8:435–63. doi: 10.15559/21-VMSTA187
25. Lagos Álvarez, B, and Jiménez Gamero, MD. A note on bias reduction of maximum likelihood estimates for the scalar skew t distribution. J. Stat. Plan. Inference. (2012) 142:608–12. doi: 10.1016/j.jspi.2011.08.012
26. Lagos-Álvarez, B, Jiménez-Gamero, MD, and Alba-Fernández, V. Bias correction in the type I generalized logistic distribution. Commun. Stat. Simul. Comput. (2011) 40:511–31. doi: 10.1080/03610918.2010.546542
27. Lemonte, AJ, Cribari-Neto, F, and Vasconcellos, KLP. Improved statistical inference for the two-parameter Birnbaum–Saunders distribution. Comput. Stat. Data Anal. (2007) 51:4656–81. doi: 10.1016/j.csda.2006.08.016
28. Ling, X, and Giles, DE. Bias reduction for the maximum likelihood estimator of the parameters of the generalized Rayleigh family of distributions. Commun. Stat. Theory Methods. (2014) 43:1778–92. doi: 10.1080/03610926.2012.675114
29. Magalhães, TM, Gómez, YM, Gallardo, DI, and Venegas, O. Bias reduction for the Marshall-Olkin extended family of distributions with application to an Airplane’s air conditioning system and precipitation data. Symmetry. (2020) 12:851. doi: 10.3390/sym12050851
30. Mazucheli, J, and Dey, S. Bias-corrected maximum likelihood estimation of the parameters of the generalized half-normal distribution. J Stat Comput Simul. (2017) 88:1027–38. doi: 10.1080/00949655.2017.1413649
31. Mazucheli, J, Menezes, AFB, and Dey, S. Bias-corrected maximum likelihood estimators of the parameters of the inverse Weibull distribution. Commun. Stat. Simul. Comput. (2019) 48:2046–55. doi: 10.1080/03610918.2018.1433838
32. Menezes, A, Mazucheli, J, Alqallaf, F, and Ghitany, ME. Bias-corrected maximum likelihood estimators of the parameters of the unit-Weibull distribution. Aust. J. Stat. (2021) 50:41–53. doi: 10.17713/ajs.v50i3.1023
33. Ramos, PL, Louzada, F, and Ramos, E. Bias reduction in the closed-form maximum likelihood estimator for the Nakagami-m fading parameter. IEEE Wire. Commun. Lett. (2020) 9:1692–5. doi: 10.1109/LWC.2020.3001453
34. Reath, J, Dong, J, and Wang, M. Improved parameter estimation of the log-logistic distribution with applications. Comput Stat. (2017) 33:339–56. doi: 10.1007/s00180-017-0738-y
35. Saha, K, and Paul, S. Bias-corrected maximum likelihood estimator of the negative binomial dispersion parameter. Biometrics. (2005) 61:179–85. doi: 10.1111/j.0006-341X.2005.030833.x
36. Sartori, N . Bias prevention of maximum likelihood estimates for scalar skew normal and skew t distributions. J. Stat. Plan. Inference. (2006) 136:4259–75. doi: 10.1016/j.jspi.2005.08.043
37. Schwartz, J, and Giles, DE. Bias-reduced maximum likelihood estimation of the zero-inflated Poisson distribution. Commun. Stat. Theory Methods. (2016) 45:465–78. doi: 10.1080/03610926.2013.824590
38. Wang, M, and Wang, W. Bias-corrected maximum likelihood estimation of the parameters of the weighted Lindley distribution. Commun. Stat. Simul. Comput. (2016) 46:530–45. doi: 10.1080/03610918.2014.970696
39. Yadav, AS, Maiti, SS, and Saha, M. The inverse Xgamma distribution: statistical properties and different methods of estimation. Ann Data Sci. (2019) 8:275–93. doi: 10.1007/s40745-019-00211-w
40. Zhang, J . Reducing bias of the maximum likelihood estimator of shape parameter for the gamma distribution. Comput Stat. (2012) 28:1715–24. doi: 10.1007/s00180-012-0375-4
41. Zhang, J . Reducing bias of the maximum-likelihood estimation for the truncated Pareto distribution. Statistics. (2013) 47:792–9. doi: 10.1080/02331888.2011.648641
42. Cox, DR, and Snell, EJ. A general definition of residuals. J R Stat Soc Ser B. (1968) 30:248–65.
44. Tibshirani, RJ, and Efron, B. An Introduction to the Bootstrap. New York: Chapman and Hall (1993).
45. Wang, F . A new model with bathtub-shaped failure rate using an additive Burr XII distribution. Reliabil. Eng. Syst. Saf. (2000) 70:305–12. doi: 10.1016/S0951-8320(00)00066-1
Keywords: bias correction, survival analysis, exponentiated Teissier distribution, bootstrap, hazard rate
Citation: Ahmed AA, Algamal ZY and Albalawi O (2024) Bias reduction of maximum likelihood estimation in exponentiated Teissier distribution. Front. Appl. Math. Stat. 10:1351651. doi: 10.3389/fams.2024.1351651
Edited by:
Min Wang, University of Texas at San Antonio, United StatesReviewed by:
Diganta Mukherjee, Indian Statistical Institute, IndiaSeng Huat Ong, UCSI University, Malaysia
Ranran Chen, University of Texas at San Antonio, United States
Copyright © 2024 Ahmed, Algamal and Albalawi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zakariya Yahya Algamal, emFrYXJpeWEuYWxnYW1hbEB1b21vc3VsLmVkdS5pcQ==
†ORCID: Zakariya Yahya Algamal, orcid.org/0000-0002-0229-7958
Olayan Albalawi, orcid.org/0000-0002-7772-0386