 Yinying Kong
Yinying Kong Niangqiu Huang
Niangqiu Huang Haodong Deng1†
Haodong Deng1†
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 22 September 2023
Sec. Optimization
Volume 9 - 2023 | https://doi.org/10.3389/fams.2023.1177081
Introduction: Ensuring fair competition through manual review is a complex undertaking. This paper introduces the utilization of Long Short-Term Memory (LSTM) neural networks and TextCNN to establish a text classifier for classifying and reviewing normative documents.
Methods: The experimental dataset used consists of policy measure samples provided by the antitrust division of the Guangdong Market Supervision Administration. We conduct a comparative analysis of the performance of LSTM and TextCNN classification models.
Results: In three classification experiments conducted without an enhanced experimental dataset, the LSTM classifier achieved an accuracy of 95.74%, while the TextCNN classifier achieved an accuracy of 92.7% on the test set. Conversely, in three classification experiments utilizing an enhanced experimental dataset, the LSTM classifier demonstrated an accuracy of 96.36%, and the TextCNN classifier achieved an accuracy of 96.19% on the test set.
Discussion: The experimental results highlight the effectiveness of LSTM and TextCNN in classifying and reviewing normative documents. The superior accuracy achieved with the enhanced experimental dataset underscores the potential of these models in real-world applications, particularly in tasks involving fair competition review.
The application of computer technology to tackle complex challenges in human society has long been a central focus of machine learning. In pursuit of machines that can approach problem-solving in a manner closer to human thinking, the field of machine learning has witnessed the emergence of a novel research direction known as deep learning. Deep learning constructs neural networks that simulate the functioning of human brain neurons through the use of computer programs, enabling the prediction of outcomes following training with vast amounts of data. As deep learning continues to advance and computer hardware performance improves, this technology has found widespread implementation across industries such as language translation, image recognition, driverless cars, and online advertising. Deep learning holds distinctive advantages in handling unstructured data, which has led to its prominent role in addressing various natural language processing challenges.
Text recognition is widely welcomed by researchers and industry due to its wide-ranging applications. Currently, many scene text recognition methods perform well in benchmark tests. However, existing methods are unable to recognize unknown characters such as other language characters or special symbols. These characters have not appeared in the training set, so an effective method is needed to differentiate and map them to improve the level of scene text recognition. Chang et al. [1] proposed a method called “label-to-prototype learning framework,” which can handle new character categories and is not affected by language. This method uses a “label-to-prototype mapping module” to generate character prototypes and uses them as classifier weights. Their approach achieved 13.98% improvement in character recognition accuracy compared with other recent methods on the CTW dataset.
Deep learning holds significant potential for widespread application in the realm of government governance. In China, the State Council has issued a series of policies aimed at dismantling local market protection, industry access barriers, and monopolies established by certain local governments through administrative means. These policies seek to establish a unified national market and deepen the reform of the economic system. While many departments have made progress in establishing and implementing fair competition review systems, there remains a need for government agencies to collect government documents from local governments' public websites and assess whether they violate the fair competition review system. Deep learning and natural language processing technologies can play a crucial role in facilitating this review process, thereby enhancing the efficiency of government governance.
Text examination inherently involves sequential models. When dealing with texts of varying lengths, it becomes necessary to map them to corresponding words or sentences that represent different responses. Standard neural networks often face challenges when addressing sequential model problems in natural language processing. This is primarily due to the requirement of sharing learned features from different parts of the text when processing natural language. Standard neural networks lack the ability to share features effectively and are thus ill-suited for examining comprehensive canonical files that possess logical and contextual linkages.
At present, the recurrent neural network (RNN) is commonly employed for Chinese text classification. RNNs possess a cyclic structure that enables the persistence of text information throughout the neural network's training, effectively capturing short-term dependencies within the text. However, RNNs encounter challenges in dealing with long-term dependencies, leading to issues such as vanishing gradients or exploding gradients. To address these problems, Sepp Hochreiter and Jurgen Schmidhuber introduced the Long Short-Term Memory (LSTM) neural network architecture. LSTM incorporates forgetting gates and update gates to regulate the flow of information within the cell state of the neural network, enabling the removal or addition of information as needed. This innovative approach successfully mitigates the vanishing gradient and exploding gradient issues inherent in RNNs [2].
While convolutional neural networks (CNNs) have traditionally been applied to image processing tasks, in recent years, researchers have started exploring their application in the field of natural language processing (NLP). Yoon Kim, among others, has made adaptations to CNN architectures by modifying the input data from images to text. This innovative approach has resulted in the development of the TextCNN model, which has demonstrated notable performance in the realm of text classification.
Government documents possess distinct characteristics that set them apart from general text. They typically exhibit lengthy content, formal writing styles, and limited emotional bias. Even manual review of these documents necessitates reviewers to possess extensive accumulated experience. Consequently, this paper utilizes unsupervised in-depth learning algorithms for classification review, while also comparing the performance of LSTM and TextCNN neural network classifiers.
The dataset of government documents used in this study is sourced from the Antitrust Office of Guangdong Province Market Supervision and Administration. The dataset comprises exclusively Chinese government documents. To facilitate the experiment, the dataset is divided into three subsets: a training set, a validation set, and a test set, distributed in proportions of 60%, 20%, and 20%, respectively.
In line with the Fair Competition Review System, manual labeling of the datasets is conducted and categorized into three distinct classes. The first category involves labeling text that pertains to market subjects but does not violate the Fair Competition Review, which is labeled as “relevant.” The second category comprises labeling text that involves market subjects and violates the Fair Competition Review, and is thus classified as “suspect documents.” Lastly, ordinary policy text that does not involve market players and does not violate the fair competition review is labeled as “irrelevant.”
Following the implementation of the Fair Competition Review system, policy measure documents that are deemed to violate the system are withdrawn from the government website. As a result, the dataset contains only 1,512 instances of the “Suspect Files” class. The remaining number of instances in the validation and test sets after dataset division is too small to achieve adequate training effectiveness. Therefore, in this experiment, the “suspect file” class is expanded using the EDA (Easy Data Augmentation) text enhancement technique.
The NLPCDA Chinese data enhancement tool, an open-source resource, is utilized to replace the text data with random entities, effectively augmenting the dataset. The change rate for each text is set to 0.3, resulting in three new augmented texts per original text. Consequently, the initial 1,512 instances of the “suspect file” class are expanded to 4,536 instances. To validate the effectiveness of text enhancement, this experiment will conduct tests and comparisons on the dataset before and after augmentation.
For this experiment, PyTorch is selected as the framework for the neural network implementation. PyTorch is a lightweight distributed machine learning platform that offers several advantages. One notable feature is its “Dynamic Computational Graph,” which enables faster model convergence [3]. The hardware utilized in the experiment consists of an Intel(R) Core(TM) i5-8300H CPU and NVIDIA GeForce GTX 1060 Max-Q GPU. The software environment is based on Python 3.6 programming language.
Prior to conducting the classification experiment, the normative files in the dataset undergo preprocessing. The first step involves importing the THUCNews deactivated Thesaurus from the Tsinghua NLP group for data cleaning purposes. Subsequently, the Jieba word-breaking tool is utilized for word segmentation. The labels “ irrelevant,” “ relevant,” and “ suspect documents” are encoded as 0, 1, and 2, respectively. The preprocessed data is then saved in the CSV file format, as shown in Table 1.

Table 1. Unprocessed dataset styles.
After preprocessing, the following steps are performed on each text in the dataset:
1. Removal of stop words: All stop words, punctuation marks, and numeric characters are removed from the text.
2. Word tokenization: The text is divided into individual words, with each word separated by spaces.
By removing stop words, punctuation, and numeric characters, the focus is placed on the essential content of the text, facilitating further analysis and classification.
As shown in Table 2, after word segmentation, the data in the CSV file is partitioned into three subsets: the training set, validation set, and test set, with proportions of 60%, 20%, and 20% respectively.

Table 2. Processed dataset styles.
Next, a vocabulary is constructed based on the highest frequency of the first 5,000 words present in the dataset. This vocabulary is created using the torchtext tool and serves as the reference for word indexing and representation.
The constructed vocabulary is saved as the parent vocabulary for subsequent text processing and model training.
Long Short-Term Memory (LSTM) is a widely used type of recurrent neural network known for its effectiveness in handling sequential data. Over the years, several extensions and variations of the LSTM architecture have been proposed. While the pioneering work on LSTM was introduced by Sepp Hochreiter and Jurgen Schmidhuber, the current mainstream LSTM architecture, as popularized by Graves A and Schmidhuber J, forms the basis of this experiment.
In line with this, a classifier based on the LSTM neural network design proposed by Graves A and others is developed for this experiment.
A single LSTM neuron comprises four essential components: an input gate, a forget gate, a cell state, and an output gate. These components work together to enable the LSTM cell to capture and retain relevant information over long sequences.
The LSTM cell structure can be visualized as shown in Figures 1, 2. The input gate regulates the flow of information into the cell, determining which input values are significant for updating the cell state. The forget gate controls the extent to which the previous cell state is retained or discarded. The cell state serves as the memory of the LSTM cell, storing relevant information throughout the sequence. Finally, the output gate controls the flow of information from the cell, allowing selective output based on the current cell state and input.

Figure 1. Structure diagram of LSTM unit.
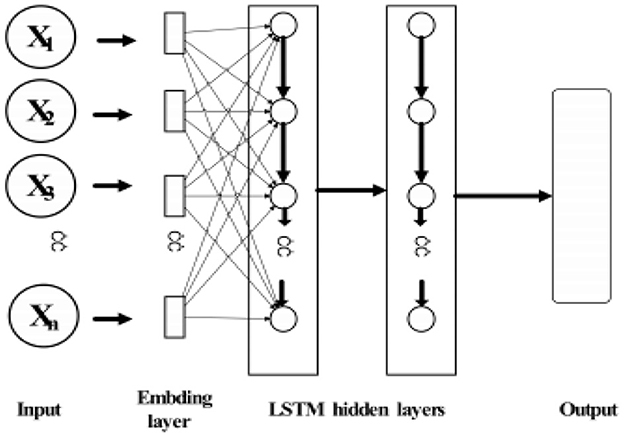
Figure 2. Schematic diagram of LSTM neural network structure
(1) The forget gate helps the network decide what information to retain and what to forget. Its input is the output from the previous timestep and the current input xt, and it outputs a vector that controls what information should be retained in the previous timestep's cell state ht−1.
(2) Then there is the input gate, which determines what type of new signal the cell state stores. It consists of two segments. The first segment controls which input information at the current moment can be stored in the current memory unit; The second part is to create a new candidate value vector to add to the cell state.
(3) Update the cell state. The future behavior depends on the previous steps and how our present goal is achieved.
We use the output of the oblivion gate to determine how much information can be retained from the previous cell state and how much of the current input can be stored in the new cell state. The updated formula is:
(4) Finally, the output gate, whose output depends on the current state of the cell, consists of two segments. The first is the amount of information that ht−1 and xt can be passed to the next moment by calculating the sum. The second fragment is the cell state processed by the tanh activation function and multiplied by the output of the first fragment, resulting in the information that needs to be passed on to the next moment.
The LSTM neural network classifier is constructed with the following layers:
Input layer: The input layer loads the preprocessed datasets. It processes 64 samples at a time.
Embedding layer: The input samples are embedded into a dense vector representation using an embedding layer with a dimension of 100. This layer helps capture semantic relationships between words.
LSTM hidden layers: The network includes two LSTM hidden layers, each consisting of 128 LSTM neurons. These layers enable the network to capture long-term dependencies and temporal patterns in the input sequences.
Fully connected layer: The output from the LSTM layers is fed into a fully connected layer, which maps the LSTM hidden states to the desired output dimension. In this case, the output layer consists of 4 neurons, corresponding to the number of classes.
The loss function used in this experiment is the multiclass cross-entropy loss function, which is suitable for classification tasks involving multiple classes.
Additionally, an early stopping mechanism is implemented during the training phase of the LSTM. This mechanism automatically stops the training process when the loss function and accuracy on the validation set reach a stable state.
The network structure, as described, involves the forward and backward propagation of each LSTM neuron in the hidden layers, capturing both the temporal dependencies and their reverse order.
TextCNN (Convolutional Neural Network for Text Classification) is a popular deep learning algorithm for natural language processing (NLP) tasks such as text classification and sentiment analysis. TextCNN is designed to capture local features from text data by applying convolutional filters to the input sentences. The convolutional filters act as feature detectors, scanning the input sentences to identify key patterns and features. The output of the filters is then fed into a max-pooling layer, which extracts and retains the most important features. The resulting feature vector is then passed through a fully connected layer and eventually used to classify the input text into relevant categories.
As shown in Figure 3, TextCNN contains an embedding layer, a convolution layer, a pooling layer and an output layer.
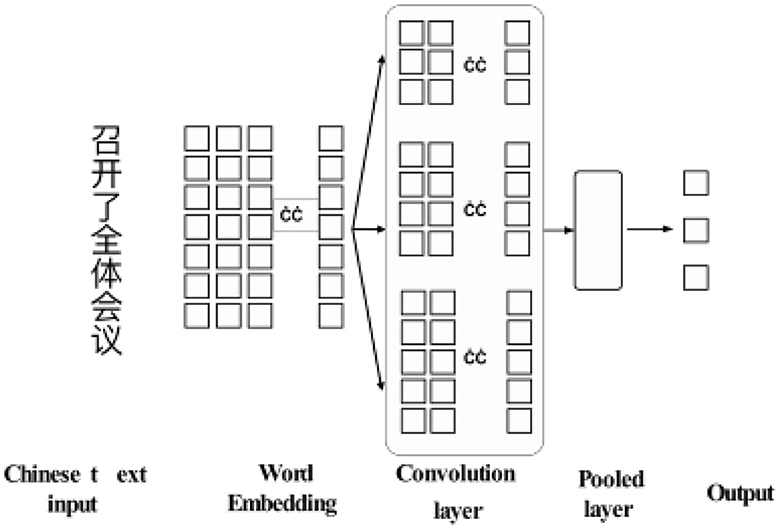
Figure 3. Schematic diagram of TextCNN neural network structure.
This layer converts the text data vector to the specified size, and each row in the matrix represents a word. If sentence X has n words, then the sentence can be expressed in matrix form:
Where, Xi represents the ith word and ⊕ is the concatenation symbol of vectors.
The TextCNN model uses a convolution kernel filter with an input layer sentence matrix to calculate the unit node matrix. The matrix can extract different hierarchical features and then obtain the feature mapping matrix by nonlinear activation function C = [ c1, c2, , c3..., cn]
Where W is the weight matrix of the output convolution kernel, b is the bias parameter, and f is the activation function.
Through the maximum pooling of feature vectors, a one-dimensional vector is formed to represent the aggregation of important features, so as to reduce the number of neural network parameters and feature vectors, achieve dimensionality reduction, and prevent overfitting phenomenon to a certain extent.
The convolution operation using different convolution kernels can extract different features and then combine these features into a one-dimensional vector by pooling operation. Finally, the vector is entered into a fully connected softmax layer to get a probability distribution that the sample belongs to different categories.
The dimension setting of word vector and the size of batch_size of the model in this section are the same as those in 3.2.2 of this paper. The height of convolution kernel is Kim [4], Zhang [5], and Shu et al. [6], the number of convolution kernel is 100, ReLU activation function is used, and multi-class cross entropy loss function is used for loss function.
This experiment focuses on analyzing and comparing the performance of the LSTM classifier and TextCNN classifier using the same normalized file dataset. The aim is to assess their effectiveness in text classification. Furthermore, the experiment investigates the robustness [7, 8] of the classifiers by comparing their performance on two datasets: one before text enhancement and the other after text enhancement. This analysis aims to evaluate how well the classifiers can handle enhanced data.
Additionally, the experiment examines and compares the training speed and the number of training iterations required for each classifier. This analysis provides insights into the practicality and efficiency [9] of the two approaches.
In this experiment, several evaluation criteria are used to assess the effectiveness of the classification review: accuracy, recall rate, and multi-class cross-entropy loss function. The formulas for these metrics are as follows:
Accuracy: The percentage of correctly classified instances in the test set.
LSTM accuracy on the test set for the canonical file datasets without text enhancement in the three-class experiments was 93.71%.
TextCNN accuracy on the test set was 92.84%.
Recall rate: The proportion of true positive instances identified correctly out of all relevant instances.
The recall rates for LSTM and TextCNN classifiers were 88.5% and 86.2% respectively.
Multi-class cross-entropy loss function: A measure of the dissimilarity between the predicted and actual class probabilities.
The loss function values for LSTM were stable at 0.002 for the training set and 0.19 for the validation set.
The loss function values for TextCNN eventually stabilized at 0.0034 for the training set and 0.3 for the validation set.
Additionally, the training set accuracy for LSTM stabilized at 99.82%, while the training set accuracy for TextCNN reached 100%. These results indicate that both classifiers achieved high accuracy on the training set.
After text enhancement, the LSTM classifier achieved an accuracy of 96.36% on the test set. The training set accuracy and loss function values were 99.84% and 0.0015 respectively, while the validation set accuracy and loss function values were 95.96% and 0.25.
Similarly, the TextCNN classifier achieved an accuracy of 96.19% on the test set. The training set accuracy and loss function values were 100% and 0.001, and the validation set accuracy and loss function values were 96.01% and 0.13.
Furthermore, the recall rates for the two classifiers on the test set were 92.45% for LSTM and 93.71% for TextCNN.
These results indicate that both LSTM and TextCNN classifiers showed improved performance after text enhancement, with higher accuracy and relatively lower loss values. The recall rates also suggest the ability of the classifiers to identify relevant instances correctly.
Tables 3, 4 show that both the LSTM and TextCNN classifiers achieved high accuracy on the validation and test sets, surpassing 90% even before text enhancement. After text enhancement, the accuracy further increased to over 95%. This indicates that the robustness of the classification model was maintained, as the synonym conversion and random word replacement operations did not negatively impact accuracy.
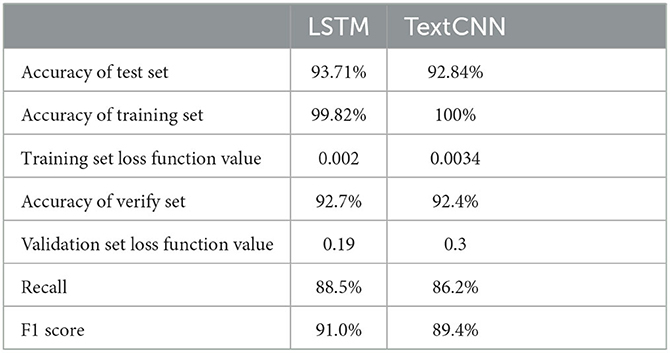
Table 3. Performance of LSTM and TextCNN before text enhancement.
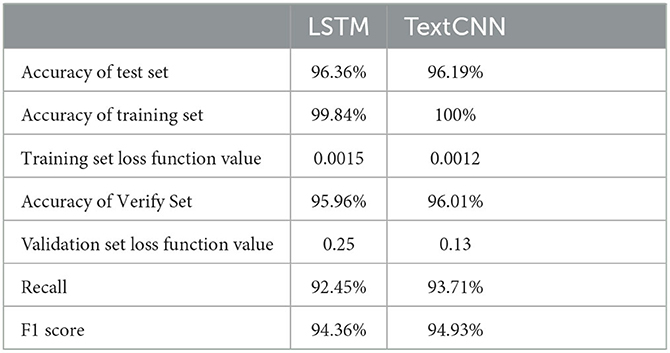
Table 4. Performance of LSTM and TextCNN after text enhancement.
Figures 4, 5 illustrate the changes in the loss function of the LSTM and TextCNN models on the training set, as well as the accuracy changes on the validation set, following text enhancement. The results show that the LSTM model reaches convergence at epoch 15, whereas the TextCNN model achieves convergence at epoch 8. Furthermore, the accuracy of the validation set shows a clear upward trend during the training process, indicating a positive impact of model optimization.
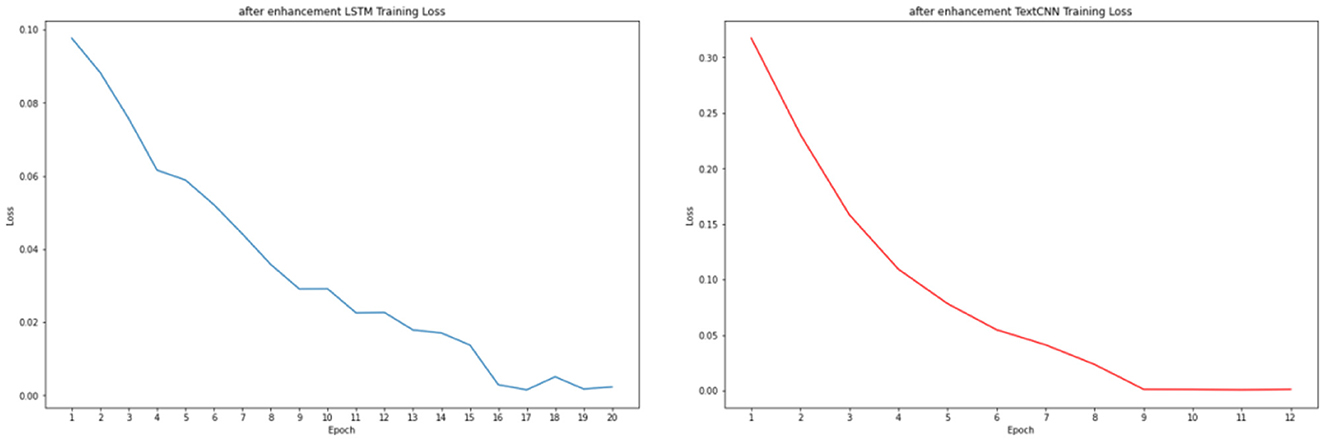
Figure 4. Loss function of LSTM and TextCNN after text enhancement.
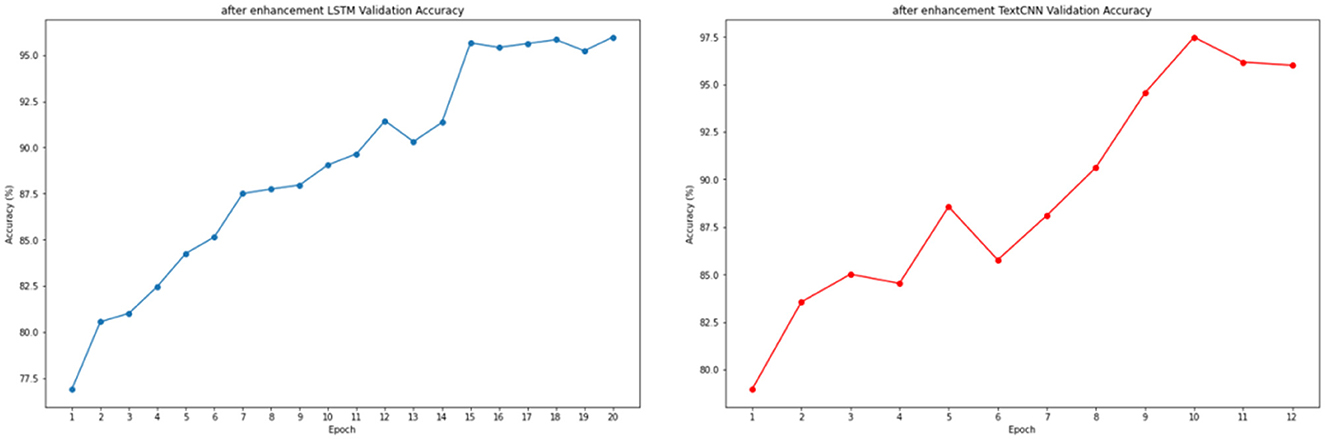
Figure 5. Validation accuracy of LSTM and TextCNN after text enhancement.
However, there are differences between the LSTM and TextCNN classifiers. As shown in Table 5, the LSTM network required more training epochs and had a longer training time compared to TextCNN. Additionally, the accuracy of each classification varied between the two models. Both classifiers performed well, but the LSTM classifier had a longer training time and required more epochs.
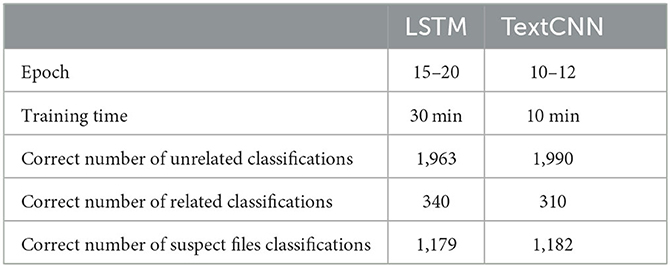
Table 5. Training cost of LSTM and TextCNN.
In summary, both the LSTM classifier and TextCNN classifier achieve high levels of accuracy and recall. The difference between them is minimal. The standardized file dataset used in this study presents more challenges compared to general short text classification due to its larger size, complex structure, and reduced emotional expression. However, both classifiers outperform manual review methods in terms of efficiency. Notably, TextCNN demonstrates better speed due to its ability to process text in parallel, whereas LSTM processes text linearly.
In conclusion, the application of deep learning technology to the fair competition review system is an interdisciplinary endeavor that encompasses computer technology, government governance, and legal treatment. The field of deep learning is rapidly advancing, offering endless possibilities for neural network configurations. Incorporating advanced technologies into government decision-making processes is crucial for fostering top-level design and planning, ultimately contributing to the development of a “smart government.” Chinese text classification based on deep learning has also made significant progress, and its integration with the fair competition system is a natural progression [10, 11].
However, it is important to acknowledge the limitations of this study. The paper focuses on commonly used technologies for combining fair competition review and deep learning, but more advanced techniques and practical implementations still require further development. Both classification models have room for improvement, and future research should aim to address these shortcomings.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
YK contributed to the conception and design of the study. JF wrote the initial draft of the manuscript. NH and HD significantly contributed to the major revision of the manuscript. All authors participated in the revision process, read, and approved the final submitted version.
The authors express gratitude for the support provided by the Guangdong Basic and Applied Basic Research Foundation (2022A1515012429) and the Guangdong Provincial Department of Education Innovation Team Project (2022WCXTD009). The support from these organizations has been instrumental in conducting this study and has contributed to its success.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Chang, L, Chun Y., Hai-bo Q., Xiaobin Z., Xu-Cheng Y. (2021). Towards open-set text recognition via label-to-prototype learning. Pattern Recog. 134, 109109. doi: 10.1016/j.patcog.2022.109109
2. Zhang S. Economic law analysis of fair competition examination system. Polit Sci Law. (2017) 11:2–10. doi: 10.15984/j.cnki.1005-9512.2017.11.001
3. Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM networks proceedings. 2005 IEEE International Joint Conference on Neural Networks. IEEE. (2005) 4:2047–52. doi: 10.1109/IJCNN.2005.1556215
4. Kim Y. Convolutional neural networks for sentence classification. Eprint Arxiv. arXiv preprint arXiv. (2014) 1408.5882. doi: 10.48550/arXiv.1408.5882
6. Shu N, Liu B, Lin W, Li PF. Survey of distributed machine learning platforms and algorithms. Comp Sci. (2019) 46:9–18. doi: 10.11896/j.issn.1002-137X.2019.03.002
7. Zhu J. An empirical study on the implementation of the fair competition review system-sample of 59 cases published by the national development and reform commission. Compet Policy Res. (2018) 04:121–35.
8. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. (1997) 9:1735–80. doi: 10.1162/neco.1997.9.8.1735
10. LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceed of the IEEE. (1998) 86:2278–324. doi: 10.1109/5.726791
Keywords: fair competition review, text classifier, LSTM, TextCNN, deep learning—artificial intelligence
Citation: Kong Y, Huang N, Deng H, Feng J, Liang X, Lv W and Liu J (2023) Text classification in fair competition law violations using deep learning. Front. Appl. Math. Stat. 9:1177081. doi: 10.3389/fams.2023.1177081
Received: 01 March 2023; Accepted: 14 August 2023;
Published: 22 September 2023.
Edited by:
Quansheng Liu, Université Bretagne Sud, FranceReviewed by:
Rahib Abiyev, Near East University, CyprusCopyright © 2023 Kong, Huang, Deng, Feng, Liang, Lv and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yinying Kong, a29uZ3l5QGdkdWZlLmVkdS5jbg==
†These authors have contributed equally to this work and share second authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.