 Mohamed R. Abonazel
Mohamed R. Abonazel Zakariya Yahya Algamal
Zakariya Yahya Algamal Fuad A. Awwad
Fuad A. Awwad Ibrahim M. Taha
Ibrahim M. Taha- 1Department of Applied Statistics and Econometrics, Faculty of Graduate Studies for Statistical Research, Cairo University, Giza, Egypt
- 2Department of Statistics and Informatics, University of Mosul, Mosul, Iraq
- 3Department of Quantitative Analysis, College of Business Administration, King Saud University, Riyadh, Saudi Arabia
- 4Department of Mathematics, Statistics, and Insurance, Sadat Academy for Management Sciences, Tanta, Egypt
The beta regression is a widely known statistical model when the response (or the dependent) variable has the form of fractions or percentages. In most of the situations in beta regression, the explanatory variables are related to each other which is commonly known as the multicollinearity problem. It is well-known that the multicollinearity problem affects severely the variance of maximum likelihood (ML) estimates. In this article, we developed a new biased estimator (called a two-parameter estimator) for the beta regression model to handle this problem and decrease the variance of the estimation. The properties of the proposed estimator are derived. Furthermore, the performance of the proposed estimator is compared with the ML estimator and other common biased (ridge, Liu, and Liu-type) estimators depending on the mean squared error criterion by making a Monte Carlo simulation study and through two real data applications. The results of the simulation and applications indicated that the proposed estimator outperformed ML, ridge, Liu, and Liu-type estimators.
Introduction
The beta regression model has been common in many areas, primarily economic and medical research, such as income share, unemployment rates in certain nations, the Gini index for each region, graduation rates in major universities, or the percentage of body fat in medical subjects. Beta regression model, such as any regression model in the context of generalized linear models (GLMs) is used to examine the effect of certain explanatory variables on a non-normal response variable. However, in the case of beta regression, the response component is restricted to an interval (0, 1), such as proportions, percentages, and fractions.
Multicollinearity is a popular issue in econometric modeling. It indicates that there is a strong association between the explanatory variables. It is well-established that the covariance matrix of the maximum likelihood (ML) estimator is ill-conditioned in the case of severing multicollinearity. One of the negative consequences of this issue is that the variance of the regression coefficients gets inflated. As a consequence, the significance and the magnitude of the coefficients are affected. Many of the conventional approaches used to address this issue include: gathering additional data, re-specifying the model, or removing the correlated variable/s.
During the last years, shrinkage methods have become a commonly recognized and more effective methodology for solving the impact of the multicollinearity problem in several regression models. To solve this problem, Hoerl and Kennard [1, 2] proposed the ridge estimator. The concept of the ridge estimator is to add a small definite amount (k) to the diagonal entries of the covariance matrix to increase the conditioning of this matrix, reduce the mean squared error (MSE), and achieve consistent coefficients. For a review of the ridge estimator in both linear and GLMs, e.g., as shown in References Rady et al. [3], Abonazel and Taha [4], Qasim et al. [5], Alobaidi et al. [6], and Sami et al. [7].
One of the drawbacks of the ridge estimator is that estimated parameters are non-linear functions of the ridge parameter and the small k selected might not be high enough to solve multicollinearity. As a solution to this problem, Liu [8] developed the Liu estimator which is a linear function of the shrinkage parameter. The Liu estimator is a combination of the ridge estimator and the Stein estimator suggested by Stein [9]. For a review of the Liu estimator in both linear and GLMs, e.g., as shown in References. Liu [8], Karlsson et al. [10], Qasim et al. [11], and Naveed et al. [12]. Furthermore, Liu [13] proved the supremacy of the Liu-type estimator over the ridge and Liu estimators. Details about Liu-type estimator, properties, and applications in regression models are shown in References Liu [14], Özkale and Kaciranlar [15], Li and Yang [16], Kurnaz and Akay [17], Sahriman and Koerniawan [18], and Algamal and Abonazel [19]. As a good alternative for the Liu-type estimator, Özkale and Kaciranlar [15] proposed the two-parameter estimator, and they proved that the two-parameter estimator utilizes the power of both the ridge estimator and the Liu estimator. Extensions of two-parameter estimator in GLMs include Huang and Yang [20], Algamal [21], Asar and Genç [22], Rady et al. [23, 24], Çetinkaya and Kaçiranlar [25], Abonazel and Farghali [26], Akram et al. [27], and Lukman et al. [28].
The rest of the article is arranged as follows: Section Methodology presents an introduction about the beta regression model, its estimation using the ML method, and the proposed two-parameter estimator; Section Choosing the Shrinkage Parameters provides suggested shrinkage parameters for our estimator; Sections Simulation Study and Real Data Applications provide a numerical evaluation using both Monte Carlo simulation and two empirical data applications, respectively; and Section Conclusion offers some concluding remarks.
Methodology
Beta Regression Model
Practitioners usually use linear regression modeling to investigate the relationship and effect of some selected explanatory variables on the normal response variable. However, this is not suitable for circumstances where the response variable is constrained to the interval (0, 1) because it may give fitted values for the variable of concern that surpass its lower and upper limits. Therefore, inference based on the normality assumption can be deceptive. The beta regression model was first developed by Ferrari and Cribari-Neto [29] by connecting the mean function of its response variable to a set of linear predictors via a monotone differentiable function called the link function. This model contains a precision parameter, the inverse of which is called a dispersion scale. In the basic type of a beta regression model, the precision parameter is believed to be constant through observations. Nevertheless, the precision parameter might not be constant through findings such as those of Smithson and Verkuilen [30] and Cribari-Neto and Zeileis [31].
Let y is a continuous random variable that follows a beta distribution with the following probability density function:
where Γ(·) is the gamma function and ϕ is the precision parameter [32]:
The mean and variance of the beta probability distribution are: E(y) = μ, var(y) = μ(1 − μ)σ2. Using the logit link function, the model allows μi, depending on covariates as follows:
where g(·) be a monotonic differentiable link function used to relate the systematic component with the random component, is a p × 1 vector of unknown parameters, is the vector of p regressors, and ηi is a linear predictor.
Estimation of the beta regression parameters is done by using the ML method [33]. The log-likelihood function of the beta regression model is given by:
By differentiating the log-likelihood function in Eq. (3) with respect to β, gives us the score function for β:
where , , , , and , such that ψ(·) denoting the digamma function, and g′(·) is the first derivative of g(·). The iterative reweighted least-squares (IWLS) algorithm or Fisher's scoring algorithm was used for estimating β [34, 35]. The form of this algorithm can be written as:
where is the score function defined in Eq. (4), and is the information matrix for β , as shown in References Espinheira et al. [35] for more details. The initial value of β can be obtained by the least-squares estimation, while the initial value for each precision parameter is:
where and values are obtained from linear regression. Given r = 0, 1, 2, … is the number of iterations that are performed, convergence occurs when the difference between successive estimates becomes smaller than a given small constant. At the final step, the ML estimator of β is obtained as:
where X is an n×p matrix of regressors, , and Ŵ = diag (ŵ1, …, ŵn);
where Ŵ and  are the estimated ML matrices of W and A, respectively. The ML estimator of β is normally distributed with asymptotic mean vectors and asymptotic covariance matrix:
Hence, the asymptotic trace mean squared error (TMSE) of is
Ridge and Liu Estimators
Recently, Abonazel and Taha [4] and Qasim et al. [5] introduced the ridge beta regression (RBR) estimator as follows:
It can note that if k = 0, then . The bias vector of the RBR estimator is
Suppose that λ1 ≥ … ≥ λp ≥ 0 are the ordered eigenvalues of XTŴX matrix and Q is the matrix whose columns are the eigenvectors of XTŴX matrix. Then and α = QTγ. Then, the matrix mean squared error (MMSE) of the RBR estimator is:
where Λk = diag (λ1 + k, …, λp + k), and the TMSE of the RBR estimator is
The first term in Eq. (12) is an asymptotic variance, and the second term is a square bias. Abonazel and Taha [4] and Qasim et al. [5] showed the derivation of the MSE properties of the RBR estimator.
The Liu estimator can be extended to the beta regression model, the Liu beta regression (LBR) estimator is given by Karlsson et al. [10] as:
where d is the Liu parameter, the bias vector of the LBR estimator is:
The MMSE for the LBR estimator can be derived as:
where Λ1 = diag (λ1 + 1, …, λp + 1) and Λd = diag (λ1 + d, …, λp + d). The TMSE of the LBR estimator is:
Recently, Algamal and Abonazel [19] developed the Liu-type beta regression (LTBR) estimator:
The bias vector of the LTBR estimator is:
The MMSE of the LTBR estimator is:
where Λ−d = diag (λ1 − d, …, λp − d). Then, the MSE of the LTBR estimator is
The Proposed Estimator
In this section, we extend the two-parameter estimator introduced by Özkale and Kaçiranlar [15] to the beta regression model to combat multicollinearity and obtain more stable and accurate results. The two-parameter beta regression (TPBR) estimator can be written as follows:
It is worth noting that the TPBR estimator is a general class that has some estimators as special cases. These estimators are the LBR, RBR, and beta maximum likelihood (BML) estimators, which can be given, respectively, as follows:
The bias vector of the TPBR estimator is
The MMSE for TPBR estimator can be derived as:
where Λkd = diag (λ1+kd, λ2 + kd, …, λp + kd), the TMSE of the TPBR estimator is:
The Superiority of the New Estimator
The following lemmas prove the superiority of the two-parameter beta estimator over the other estimators.
Lemma 1. Farebrother [36]: Let M be a positive definite matrix, δ be a vector of non-zero constants, and c be a positive constant. Then, cM − δδT > 0 if and only if (iff) δMδT < c.
Two-Parameter Beta Estimator vs. ML Estimator
The following lemma gives the condition that the TPBR estimator is superior to the ML estimator:
Lemma 2. under the beta regression model, let k > 0, 0 < d < 1, and . Then, iff k(1 − d)(2λj + k(1 + d)) > 0.
Proof: the difference between the MMSE functions of the ML estimator and the TPBR estimator is obtained by:
The matrix is positive definite, if , which is equivalent to [(λj + k) + (λj + kd)][(λj + k) − (λj + kd)] > 0. Simplifying the last inequality, one gets k(1 − d)(2 λ j + k(1 + d)) > 0. The proof is finished by Lemma 1.
Two-Parameter Estimator vs. Ridge Estimator
The following lemma gives that the TPBR estimator is superior to the RBR estimator:
Lemma 3. under the beta regression model, consider k > 0, 0 < d < 1, and . Then, iff kd(2 λ j + kd) > 0.
Proof: the difference between the MMSE functions of the RBR estimator and the TPBR estimator is obtained by:
This can be rewritten as:
The matrix is positive definite if which is equivalent to [λj − (λj + kd)][λj + (λj + kd)] > 0. Simplifying the last inequality, one gets kd(2 λ j + kd) > 0. Then, using Lemma 1, the proof is finished.
Two-Parameter Estimator vs. Liu Estimator
The following lemma gives the condition that the TPBR estimator is superior to the LBR estimator:
Lemma 4. under the beta regression model, consider k > 0, 0 < d < 1, and . Then, iff .
Proof: the difference between the MMSE functions of and is obtained by:
This can be rewritten as:
The matrix is positive definite if , which is equivalent to . For k > 0, 0 < d < 1, it can be observed that . The proof is finished by Lemma 1.
Two-Parameter Estimator vs. Liu-Type Estimator
The following lemma gives the condition that the TPBR estimator is superior to the LTBR estimator:
Lemma 5. under the beta regression model, consider k > 0, −∞ < d1 < ∞, 0 < d2 < 1, and , where d1 and d2 are the d values of LTBR and TPBR estimators, respectively. Then, iff d1(d1 − 2λj) − kd2(kd2 + 2λj) > 0.
Proof: the difference between the MMSE functions of and is obtained by:
This can be rewritten as:
The matrix is positive definite if , which is equivalent to . For k > 0, −∞ < d1 < ∞, 0 < d2 < 1, it can be observed that d1(d1 − 2λj) − kd2(kd2 + 2λj) > 0. The proof is finished by Lemma 1.
Choosing the Shrinkage Parameters
There is no definite rule for estimating the shrinkage parameters (k and d). However, we propose some methods based on the work of Hoerl et al. [37] and Kibria [38]. For the RBR estimator, we can use the k parameter of Hoerl and Kennard [1] after modifying their formula based on the optimal k of the beta regression model [5]:
where is the jth element of the vector .
For the LBR estimator, we can use the optimal d parameter proposed by Karlsson et al. [10]:
For the LTBR estimator, we can use the optimal d parameter of the LTBR estimator that was proposed by Algamal and Abonazel [19]:
Since dLTBR depends on k, we suggest using the k parameter in Eq. (25).
For the proposed estimator (TPBR), we start by taking the derivative of MSE function given in Eq. (24) with respect to k and equating the resulting function to zero and by solving for the parameter k, we obtain the following individual parameters:
Since each individual parameter kj should be positive, we obtain the following upper bound for the kj parameter d's so that kj > 0:
where min(·) is the minimum function such that 0 < d < 1 and is the jth element of the vector . Therefore, we propose the following shrinkage parameters for the TPBR estimator:
Note that dTPBR in Eq. (30) is always <1 and bigger than zero, and kTPBR in Eq. (31) is always positive [15].
Simulation Study
A Monte Carlo simulation study has been conducted to compare the performances of BML, RBR, LBR, and LTBR estimators with the proposed estimator (TPBR estimator). Our simulation study is computed based on R-software, using the “betareg” package.
Simulation Design
The response variable yi is generated as yi ~ Beta(μi, ϕ), with ϕ ∈ {0.5,1,1.5} and for i = 1, 2, …, n, and with and β1 = … = βp [19, 26, 39–41].
The explanatory variables are generated from the following:
where ρ is the coefficient of the correlation between the explanatory variables and wij are independent standard normal pseudo-random numbers.
It is well-known that the sample size (n), the number of explanatory variables (p), and the pairwise correlation (ρ) between the explanatory variables have a direct impact on the prediction accuracy. Therefore, four values of n are considered: 50, 100, 250, and 400. In addition, three values of p are considered: 4, 8, and 12. Further, three values of ρ are considered: 0.90, 0.95, and 0.99. For a combination of these different values of n, ϕ, p, and ρ, the generated data are repeated L = 1, 000 times and the average MSE is calculated as:
where is the estimated vector of β.
Simulation Results
The averaged MSE for all the combinations of n, ϕ, p,, and ρ are summarized in Tables 1–4. According to the simulation results, we conclude the following:
1. The TPBR estimator has the best performance in all the situations considered. Moreover, the performance of the TPBR estimator is better for larger values of ρ.
2. It is noted from Tables 1–4 that the TPBR estimator ranks first with respect to MSE. In the second rank is the LTBR estimator, as it performs better than BML, RBR, and LBR estimators. Additionally, the BML estimator has the worst performance among RBR, LBR, and TPBR estimators which is significantly impacted by the multicollinearity.
3. Regarding the number of explanatory variables, it is easily seen that there is a negative impact on MSE, where there are increases in their values when the p increase from four variables to eight and twelve variables. In addition, in terms of the sample size, the MSE values decrease when n increases, regardless of the value of ρ, ϕ, and p.
4. Clearly, the MSE values are decreasing when ϕ is increasing.
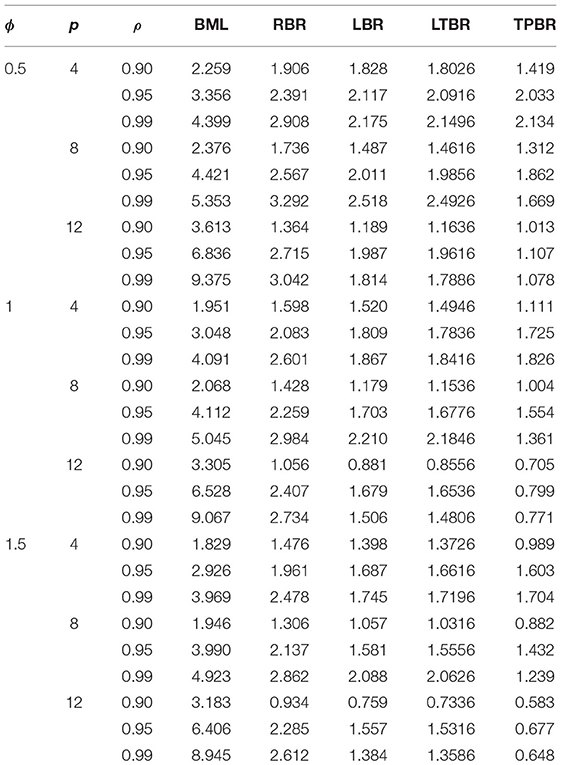
Table 1. Mean squared error (MSE) values for different estimators when n = 50.
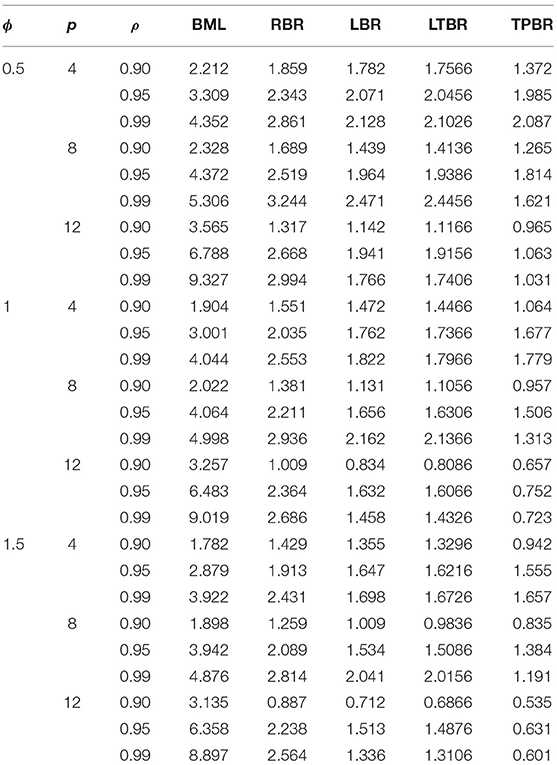
Table 2. Mean squared error values for different estimators when n = 100.
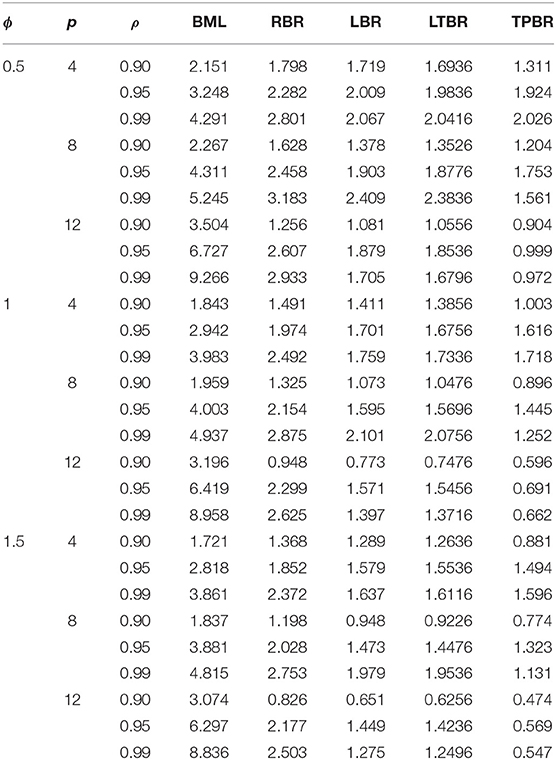
Table 3. Mean squared error values for different estimators when n = 250.
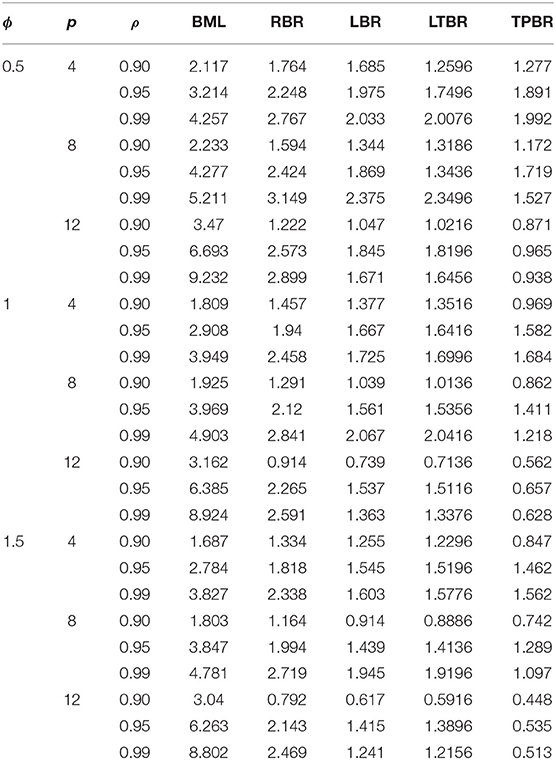
Table 4. Mean squared error values for different estimators when n = 400.
Relative Efficiency
Another comparative performance called relative efficiency (RE) can be utilized, it is calculated based on the MSE in Eq. (33) as follows [4, 39]:
where denotes the estimators of RBR, LBR, LTBR, or TPBR. The RE results are shown in Figure 1.
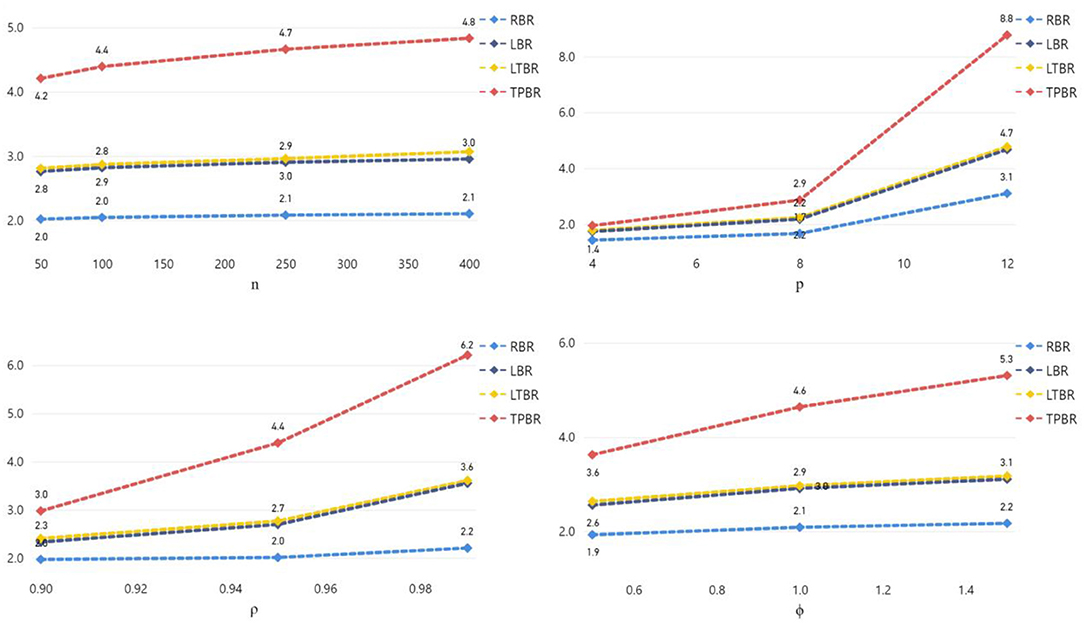
Figure 1. Relative efficiency (RE) of different estimators categorized by levels of n, p, ρ, and ϕ.
Figure 1 shows that the RE of the four biased (RBR, LBR, LTBR, and TPBR) estimators were increased if the sample size (n), the number of explanatory variables (p), the degree of correlation between explanatory variables (ρ), and/or the precision parameter value (ϕ) are increased. Moreover, we can observe that the TPBR estimator has higher RE values than the other estimators.
Real Data Applications
In this section, we used two real data applications to investigate the advantage of our proposed (TPBR) estimator in different fields.
Football Spanish Data
We apply the proposed estimator to the football Spanish La Liga, season 2016–2017 [19]. The data contain 20 teams. The response variable is the proportion of won matches. The six considerable explanatory variables are: x1 is the number of yellow cards, x2 is the number of red cards, x3 is the total number of substitutions, x4 is the number of matches with 2.5 goals on average, x5 is the number of matches that ended with goals, and x6 is the ratio of the goal scores to the number of matches.
First, to check whether there is a multicollinearity problem or not, the correlation matrix and condition number (CN) are used. Based on the correlation matrix among the six explanatory variables that are presented, displayed by Algamal and Abonazel [19]. It is obviously seen that there are correlations >0.82 between x1 and x6, x1 and x4, x2 and x4, and x4 and x6. Second, the condition number, of the data is 806.63 indicating the existence of multicollinearity. The estimated beta regression coefficients and MSE values for the BML, RBR, LBR, LTBR, and TPBR estimators are recorded in Table 5. From Table 5, it can note that the estimated coefficients of all estimators have the same signs; this means that the type of relationship between each explanatory variable and the response variable is not changed from what it was in the BML estimator. But MSE values of RBR, LBR, LTBR, and TPBR estimators are lower than the BML estimator. Whereas, the MSE value of the TPBR estimator is the lowest.
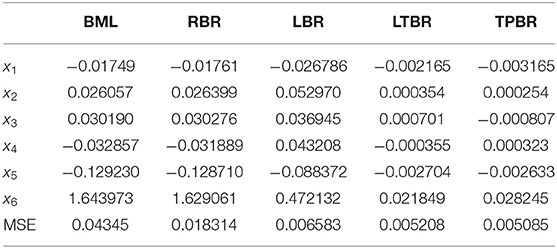
Table 5. The estimated coefficients and MSE values for the used estimators (football data).
Gasoline Yield Data
To further investigate the advantage of our proposed estimator (TPBR), we apply the TPBR estimator to the chemical dataset (gasoline yield data) which was originally obtained by Prater [42], and later used by the following authors: Ospina et al. [43] and Karlsson et al. [10]. The dataset contains 32 observations on the response and four explanatory variables. The variables in the study are described as follows: the dependent variable y is the proportion of crude oil after distillation and fractionation while the explanatory variables are crude oil gravity (Gravity), vapor pressure of crude oil (Pressure), temperature at which 10% of the crude oil has vaporized (Temp10), and temperature at which all petrol in the amount of crude oil vaporizes (Temp). Atkinson [44] analyzed this dataset using the linear regression model and observed some anomalies in the distribution of the error. Recently, Karlsson et al. [10] showed that the beta regression model is more suitable to model the data.
The CN for the dataset under study is 11,281.4, which signals severe multicollinearity. The estimated beta regression coefficients and MSE values for the used estimators are recorded in Table 6. From Table 6, it can be noted that the estimated coefficients of all estimators have the same signs. In addition, MSE values of RBR, LBR, LTBR, and TPBR estimators are lower than the BML estimator. Whereas, the MSE value of the TPBR estimator is the lowest.
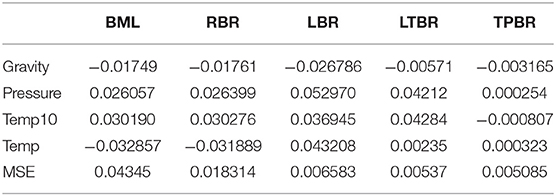
Table 6. The estimated coefficients and MSE values for the used estimators (gasoline yield data).
Conclusion
This article provided a two-parameter (TPBR) estimator for the beta regression model as a remedy for a multicollinearity problem. We proved, theoretically, that our proposed estimator is efficient than other biased estimators (ridge, Liu, and Liu-type estimators) suggested in the literature. Furthermore, a Monte Carlo simulation study was conducted to study the performance of the proposed estimator and ML, ridge, Liu, and Liu-type estimators. The results indicated that the proposed estimator outperforms these estimators, especially when there is a high-to-strong correlation between the explanatory variables. Finally, the benefit is shown by two empirical applications where the TPBR estimator performed well by decreasing the MSE compared with the ML, ridge, Liu, and Liu-type estimators.
For future work, for example, one can study the high-dimensional case in beta regression as an extension to Arashi et al. [45] or provide a robust biased estimation of beta regression as an extension to Awwad et al. [41] and Dawoud and Abonazel [40].
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found at: For first application: https://www.laliga.es. For second application: the R-package betareg.
Author Contributions
MA: methodology, relative efficiency, interpreting the results, abstract, conclusions, writing—original draft, and final revision. ZA: simulation study and applications, interpreting the results, and revision. FA: methodology, interpreting the results, and revision. IT: introduction, methodology, and writing—original draft. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank the Deanship of Scientific Research at King Saud University represented by the Research Center at CBA for supporting this research financially.
References
1. Hoerl AE, Kennard RW. Ridge regression: biased estimation for non-orthogonal problems. Technometrics. (1970) 12:55–67. doi: 10.1080/00401706.1970.10488634
2. Hoerl AE, Kennard RW. Ridge regression: applications to non-orthogonal problems. Technometrics. (1970) 12:69–82. doi: 10.1080/00401706.1970.10488635
3. Rady EA, Abonazel MR, Taha IM. Ridge estimators for the negative binomial regression model with application. In: The 53rd Annual Conference on Statistics, Computer Science, and Operation Research 3-5 Dec, 2018. (2018). Giza: ISSR, Cairo University.
4. Abonazel MR, Taha IM. Beta ridge regression estimators: simulation and application. Commun Statist Simul Computat. (2021) 1–13. doi: 10.1080/03610918.2021.1960373
5. Qasim M, Månsson K, Golam Kibria BM. On some beta ridge regression estimators: method, simulation and application. J Stat Comput Simul. (2021) 91:1699–712. doi: 10.1080/00949655.2020.1867549
6. Alobaidi NN, Shamany RE, Algamal ZY. A new ridge estimator for the negative binomial regression model. Thailand Statistician. (2021) 19:116–25.
7. Sami F, Amin M, Butt MM. On the ridge estimation of the Conway-Maxwell Poisson regression model with multicollinearity: Methods and applications. Concurr Computat Pract Exp. (2021) 2021:6477. doi: 10.1002/cpe.6477
8. Liu K. A new class of biased estimate in linear regression. Commun Statist Theor Method. (1993) 22:393–402. doi: 10.1080/03610929308831027
9. Stein C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In: Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics. Berkeley, CA: University of California Press. (1956). p. 197–206. doi: 10.1525/9780520313880-018
10. Karlsson P, Månsson K, Kibria BG. A Liu estimator for the beta regression model and its application to chemical data. J Chemom. (2020) 34:e3300. doi: 10.1002/cem.3300
11. Qasim M, Kibria BMG, Månsson K, Sjölander P. A new Poisson Liu regression estimator: method and application. J Appl Stat. (2020) 47:2258–71. doi: 10.1080/02664763.2019.1707485
12. Naveed K, Amin M, Afzal S, Qasim M. New shrinkage parameters for the inverse Gaussian Liu regression. Commun Statist Theor Method. (2020) 2020:1–21. doi: 10.1080/03610926.2020.1791339
13. Liu K. Using Liu-type estimator to combat collinearity. Commun Statist Theor Method. (2003) 32:1009–20. doi: 10.1081/STA-120019959
14. Liu K. More on Liu-type estimator in linear regression. Commun Statist Theor Method. (2004) 33:2723–33. doi: 10.1081/STA-200037930
15. Özkale MR, Kaciranlar S. The restricted and unrestricted two-parameter estimators. Commun Stat Theor Method. (2007) 36:2707–25. doi: 10.1080/03610920701386877
16. Li Y, Yang H. A new Liu-type estimator in linear regression model. Stat Pap. (2012) 53:427–37. doi: 10.1007/s00362-010-0349-y
17. Kurnaz FS, Akay KU. A new Liu-type estimator. Stat Pap. (2015) 56:495–517. doi: 10.1007/s00362-014-0594-6
18. Sahriman S, Koerniawan V. Liu-type regression in statistical downscaling models for forecasting monthly rainfall salt as producer regions in Pangkep regency. J Phys Conf Ser. (2019) 1341:092021. doi: 10.1088/1742-6596/1341/9/092021
19. Algamal ZY, Abonazel MR. Developing a Liu-type estimator in beta regression model. Concurr Computat Pract Exp. (2021) 2021:e6685. doi: 10.1002/cpe.6685
20. Huang J, Yang H. A two-parameter estimator in the negative binomial regression model. J Stat Comput Simul. (2014) 84:124–34. doi: 10.1080/00949655.2012.696648
21. Algamal ZY. Shrinkage estimators for gamma regression model. Electr J Appl Stat Anal. (2018) 11:253–68. doi: 10.1285/i20705948v11n1p253
22. Asar Y, Genç A. A new two-parameter estimator for the Poisson regression model. Iran J Sci Technol Trans A Sci. (2018) 42:793–803. doi: 10.1007/s40995-017-0174-4
23. Rady EA, Abonazel MR, Taha IM. A new biased estimator for zero-inflated count regression models. J Modern Appl Stat Method. (2019). Available online at: https://www.researchgate.net/publication/337155202_A_New_Biased_Estimator_for_Zero-Inflated_Count_Regression_Models
24. Rady EA, Abonazel MR, Taha IM. New shrinkage parameters for Liu-type zero inflated negative binomial estimator. In: The 54th Annual Conference on Statistics, Computer Science, and Operation Research 3-5 Dec, 2019. Giza: FGSSR, Cairo University (2019).
25. Çetinkaya M, Kaçiranlar S. Improved two-parameter estimators for the negative binomial and Poisson regression models. J Stat Comput Simul. (2019) 89:2645–60. doi: 10.1080/00949655.2019.1628235
26. Abonazel MR, Farghali RA. Liu-type multinomial logistic estimator. Sankhya B. (2019) 81:203–25. doi: 10.1007/s13571-018-0171-4
27. Akram MN, Amin M, Qasim M. A new Liu-type estimator for the Inverse Gaussian Regression Model. J Stat Comput Simul. (2020) 90:1153–72. doi: 10.1080/00949655.2020.1718150
28. Lukman AF, Aladeitan B, Ayinde K, Abonazel MR. Modified ridge-type for the Poisson regression model: simulation and application. J Appl Stat. (2021) 2021:1–13. doi: 10.1080/02664763.2021.1889998
29. Ferrari S, Cribari-Neto F. Beta regression for modelling rates and proportions. J Appl Stat. (2004) 31:799–815. doi: 10.1080/0266476042000214501
30. Smithson M, Verkuilen J. A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychol Method. (2006) 11:54–71. doi: 10.1037/1082-989X.11.1.54
31. Cribari-Neto F, Zeileis A. Beta regression in R. J Stat Softw. (2010) 34:1–24. doi: 10.18637/jss.v034.i02
32. Bayer FM, Cribari-Neto F. Model selection criteria in beta regression with varying dispersion. Commun Stat Simul Computat. (2017) 46:729–46. doi: 10.1080/03610918.2014.977918
33. Espinheira PL, Ferrari SL, Cribari-Neto F. On beta regression residuals. J Appl Stat. (2008) 35:407–19. doi: 10.1080/02664760701834931
34. Espinheira PL, da Silva LCM, Silva ADO. Prediction measures in beta regression models. arXiv preprint. (2015). arXiv: 1501.04830.
35. Espinheira PL, da Silva LCM, Silva ADO, Ospina R. Model selection criteria on beta regression for machine learning. Machine Learn Knowl Extr. (2019) 1:427–49. doi: 10.3390/make1010026
36. Farebrother RW. Further results on the mean square error of ridge regression. J Royal Stat Soc Ser B. (1976) 38:248–50. doi: 10.1111/j.2517-6161.1976.tb01588.x
37. Hoerl AE, Kennard RW, Baldwin KF. Ridge regression: some simulations. Commun Stat Theor Method. (1975) 4:105–23. doi: 10.1080/03610917508548342
38. Kibria BMG. Performance of some new ridge regression estimators. Commun Stat Simul Computat. (2003) 32:419–35. doi: 10.1081/SAC-120017499
39. Farghali RA, Qasim M, Kibria BG, Abonazel MR. Generalized two-parameter estimators in the multinomial logit regression model: methods, simulation and application. Commun Stat Simul Computat. (2021) 1–16. doi: 10.1080/03610918.2021.1934023
40. Dawoud I, Abonazel MR. Robust Dawoud–Kibria estimator for handling multicollinearity and outliers in the linear regression model. J Stat Comput Simul. (2021) 91:3678–92. doi: 10.1080/00949655.2021.1945063
41. Awwad FA, Dawoud I, Abonazel MR. Development of robust Özkale-Kaçiranlar and Yang-Chang estimators for regression models in the presence of multicollinearity and outliers. Concurr Computat Pract Exp. (2021) 2021:e6779. doi: 10.1002/cpe.6779
43. Ospina R, Cribari-Neto F, Vasconcellos KL. Improved point and interval estimation for a beta regression model. Comput Stat Data Anal. (2006) 51:960–81. doi: 10.1016/j.csda.2005.10.002
44. Atkinson AC. Plots, Transformations and Regression: An Introduction to Graphical Methods of Diagnostic Regression Analysis. New York, NY: Oxford University Press (1985).
Keywords: biased estimation, Fisher's scoring, mean squared error (MSE), multicollinearity, Liu beta regression, relative efficiency, ridge beta regression, two-parameter estimator
Citation: Abonazel MR, Algamal ZY, Awwad FA and Taha IM (2022) A New Two-Parameter Estimator for Beta Regression Model: Method, Simulation, and Application. Front. Appl. Math. Stat. 7:780322. doi: 10.3389/fams.2021.780322
Received: 20 September 2021; Accepted: 17 December 2021;
Published: 26 January 2022.
Edited by:
Gareth William Peters, University of California, Santa Barbara, United StatesReviewed by:
Mingjun Zhong, University of Aberdeen, United KingdomMohammad Arashi, Ferdowsi University of Mashhad, Iran
Copyright © 2022 Abonazel, Algamal, Awwad and Taha. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohamed R. Abonazel, bWFib25hemVsQGN1LmVkdS5lZw==