 H. N. Mhaskar
H. N. Mhaskar S. V. Pereverzyev
S. V. Pereverzyev M. D. van der Walt
M. D. van der Walt- 1Institute of Mathematical Sciences, Claremont Graduate University, Claremont, CA, , United States
- 2The Johann Radon Institute for Computational and Applied Mathematics (RICAM), Austrian Academy of Sciences, Linz, Austria
- 3Department of Mathematics and Computer Science, Westmont College, Santa Barbara, CA, United States
The problem of real time prediction of blood glucose (BG) levels based on the readings from a continuous glucose monitoring (CGM) device is a problem of great importance in diabetes care, and therefore, has attracted a lot of research in recent years, especially based on machine learning. An accurate prediction with a 30, 60, or 90 min prediction horizon has the potential of saving millions of dollars in emergency care costs. In this paper, we treat the problem as one of function approximation, where the value of the BG level at time
1 Introduction
Diabetes is a major disease affecting humanity. According to the 2020 National Diabetes Statistics report [3], more than 34,000,000 people had diabetes in the United States alone in 2018, contributing to nearly 270,000 deaths and costing nearly 327 billion dollars in 2017. There is so far no cure for diabetes, and one of the important ingredients in keeping it in control is to monitor blood glucose levels regularly. Continuous glucose monitoring (CGM) devices are used increasingly for this purpose. These devices typically record blood sugar readings at 5 min intervals, resulting in a time series. This paper aims at predicting the level and rate of change of the sugar levels at a medium range prediction horizon; i.e., looking ahead for 30–60 min. A clinically reliable prediction of this nature is extremely useful in conjunction with other communication devices in avoiding unnecessary costs and dangers. For example, hypoglycemia may lead to loss of consciousness, confusion or seizures [9]. However, since the onset of hypoglycemic periods are often silent (without indicating symptoms), it can be very hard for a human to predict in advance. If these predictions are getting communicated to a hospital by some wearable communication device linked with the CGM device, then a nurse could alert the patient if the sugar levels are expected to reach dangerous levels, so that the patient could drive to the hospital if necessary, avoiding a dangerous situation, not to mention an expensive call for an ambulance.
Naturally, there are many papers dealing with prediction of blood glucose (BG) based not just on CGM recordings but also other factors such as meals, exercise, etc. In particular, machine learning has been used extensively for this purpose. We refer to [9] for a recent review of BG prediction methods based on machine learning, with specific focus on predicting and detecting hypoglycemia.
The fundamental problem of machine learning is the following. We have (training) data of the form
Such problems have been studied in approximation theory for more than a century. Unfortunately, classical approximation theory techniques do not apply directly in this context, mainly because the data does not necessarily become dense on any known domain such as a cube, sphere, etc., and we cannot control the locations of the points
Manifold learning tries to ameliorate this problem by assuming that the data lies on some unknown manifold, and developing techniques to learn various quantities related to the manifold, in particular, the eigen-decomposition of the Laplace-Beltrami operator. Since these objects must be learnt from the data, these techniques are applicable in the semi-supervised setting, in which we have all the data points
Recently, we have discovered [7] a more direct method to approximate functions on unknown manifolds without trying to learn anything about the manifold itself, and giving an approximation with theoretically guaranteed errors on the entire manifold; not just the points in the original data set. The purpose of this paper is to use this new tool for BG prediction based on CGM readings which can be used on patients not in the same data sets, and for readings for the patients in the data set which are not included among the training data.
In this context, the numerical accuracy of the prediction alone is not clinically relevant. The Clarke Error-Grid Analysis (C-EGA) [2] is devised to predict whether the prediction is reasonably accurate, or erroneous without serious consequences (clinically uncritical), or results in unnecessary treatment (overcorrection), or dangerous (either because it fails to identify a rise or drop in BG or because it confuses a rise in BG for a drop or vice versa). The Prediction Error-Grid Analysis (PRED-EGA), on the other hand, categorizes a prediction as accurate, erroneous with benign (not serious) consequences or erroneous with potentially dangerous consequences in the hypoglycemic (low BG), euglycemic (normal BG), and hyperglycemic (high BG) ranges separately. This stratification is of great importance because consequences caused by a prediction error in the hypoglycemic range are very different from ones in the euglycemic or the hyperglycemic range. In addition, the categorization is based not only on reference BG estimates paired with the BG estimates predicted for the same moments (as C-EGA does), but also on reference BG directions and rates of change paired with the corresponding estimates predicted for the same moments. It is argued in [14] that this is a much better clinically meaningful assessment tool than C-EGA, and is therefore the assessment tool we choose to use in this paper.
Since different papers on the subject use different criterion for assessment it is impossible for us to compare our results with those in most of these papers. Besides, a major objective of this paper is to illustrate the use and utility of the theory in [7] from the point of view of machine learning. So, we will demonstrate the superiority of our results in the hypoglycemic and hyperglycemic regimes over those obtained by a blind training of a deep network using the MATLAB Deep Learning Toolbox. We will also compare our results with those obtained by the techniques used in [6, 8, 10]. However, we note that these methods are not directly comparable to ours. In [10], the authors use the data for only one patient as training data, which leads to a meta-learning model that can be used serendipitously on other patients, although a little bit of further training is still required for each patient to apply this model. In contrast, we require a more extensive “training data,” but there is no training in the classical sense, and the application to new patients consists of a simple matrix vector multiplication. The method in [6] is a linear extrapolation method, where the coefficients are learnt separately on each patient. It does not result in a model that can be trained once for all and applied to other patients in a simple manner. As pointed out earlier, the method in [8] requires that the entire data set be available even before the method can start to work. So, unlike our method, it cannot be trained on a part of the data set and applied to a completely different data set, not available at the beginning.
We will explain the problem and the evaluation criterion in Section 3. Prior work on this problem is reviewed briefly in Section 2. The methodology and algorithm used in this paper are described in Section 4. The results are discussed in Section 5. The mathematical background behind the methods described in Section 4 is summarized in Appendix A.
2 Prior Work
Given the importance of the problem, many researchers have worked on it in several directions. Below we highlight the main trends relevant to our work.
The majority of machine learning models (30% of those studied in the survey paper [9]) are based on artificial neural networks such as convolutional neural networks, recurrent neural networks and deep learning techniques. For example, in [17], the authors develop a deep learning model based on a dilated recurrent neural network to achieve 30-min blood glucose prediction. The authors assess the accuracy of their method by calculating the root mean squared error (RMSE) and mean absolute relative difference (MARD). While they achieve good results, a limitation of the method is the reliance on various input parameters such as meal intake and insulin dose which are often recorded manually and might therefore be inaccurate. In [11], on the other hand, a feed-forward neural network is designed with eleven neurons in the input layer (corresponding to variables such as CGM data, the rate of change of glucose levels, meal intake and insulin dosage), and nine neurons with hyperbolic tangent transfer function in the hidden layer. The network was trained with the use of data from 17 patients and tested on data from 10 other patients for a 75-min prediction, and evaluated using C-EGA. Although good results are achieved in the C-EGA grid in this paper, a limitation of the method is again the large amount of additional input information necessary to design the model, as described above.
A second BG prediction class employs decision trees. The authors of [13], for example, use random forests to perform a 30-min prediction to specifically detect postprandial hypoglycemia, that is, hypoglycemia occurring after a meal. They use statistical analyses like sensitivity and specificity to evaluate their method. In [16], prediction is again achieved by random forests and incorporating a wide variety of additional input features such as physiological and physical activity parameters. Mean Absolute Percentage Error (MAPE) is used as assessment methodology. The authors of [5] use a classification and regression tree (CART) to perform a 15-min prediction using BG data only, again using sensitivity and specificity to test the performance of their method.
A third class of methods employ kernel-based regularization techniques to achieve prediction (for example [10], and references therein), where Tikhonov regularization is used to find the best least square fit to the data, assuming the minimizer belongs to a reproducing kernel Hilbert space (RKHS). Of course, these methods are quite sensitive to the choice of kernel and regularization parameters. Therefore, the authors in [10] develop methods to choose both the kernel and regularization parameter adaptively, or through meta-learning (“learning to learn”) approaches. C-EGA and PRED-EGA are used as performance metrics.
Time series techniques are also employed in the literature. In [12], a tenth-order auto-regression (AR) model is developed, where the AR coefficients are determined through a regularized least square method. The model is trained patient-by-patient, typically using the first 30% of the patient’s BG measurements, for a 30-min or 60-min prediction. The method is tested on a time series containing glucose values measured every minute, and evaluation is again done through the C-EGA grid. The authors in [15] develop a first-order AR model, patient-by-patient, with time-varying AR coefficients determined through weighted least squares. Their method is tested on a time series containing glucose values measured every 3 min, and quantified using statistical metrics such as RMSE. As noted in [10], these methods seem to be sensitive to gaps in the input data.
A summary of the methods described above is given in Table 1.
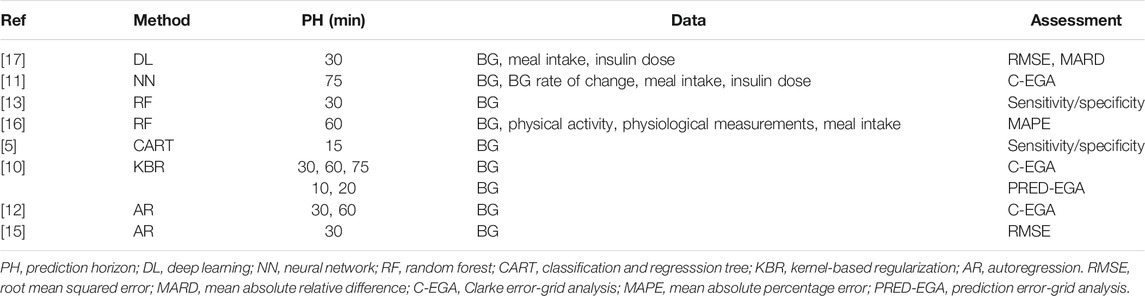
TABLE 1. A summary of related work on BG prediction.
It should be noted that the majority of BG prediction models (63.64% of those analyzed in [9]), including many of the references described above, are dependent on additional input features (such as meal intake, insulin dosage and physical activity) in addition to historical BG data. Since such data could be inaccurate and hard to obtain, we have intentionally made the design decision in our work to base our method on historical BG data only.
3 The Set-up
We use two different clinical data sets provided by the DirectNet Central Laboratory [1], which lists BG levels of different patients taken at 5-min intervals with the CGM device; i.e., for each patient p in the patient set P, we are given a time series
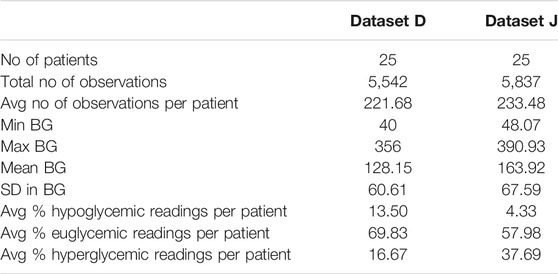
TABLE 2. Summary statistics for datasets D and J.
Our goal is to predict for each j, the level
4 Methodology in the Current Paper
4.1 Data Reformulation
For each patient p in the set P of patients in the data sets, the data is in the form of a time series
For any patient
and write
The problem of BG prediction is then seen as the classical problem of machine learning; i.e., to find a functional relationship f such that
4.2 Training Data Selection
To obtain training data, we form the training set C by randomly selecting (according to a uniform probability distribution) c % of the patients in P. The training data are now defined to be all the data of each patient in C, that is,
Since we define the training and test data in terms of patients, choosing the entire data for a patient in the training (respectively, test) data, we may now simplify the notation by writing
and the testing patient set
4.3 BG Range Classification
To get accurate results in each BG range, we want to be able to adapt the training data and parameters used for predictions in each range–as noted previously, consequences of prediction errors in the separate BG ranges are very different. To this end, we divide the measurements in
with
In addition, we also classify each
Ideally, the classification of each
4.4 Prediction
Before making the BG predictions, it is necessary to scale the input readings so that the components of each
where
With
The construction of the estimator
4.5 Evaluation
To evaluate the performance of the final output
as well as the rates of change
for all
We repeat the entire process described in Subsections 4.2–4.5 for a fixed number of trials, after which we report the average of the PRED-EGA grid placements, over all
A Summary of the method is given in Algorithm 1.

5 Results and Discussion
As mentioned in Section 3, we apply our method to data provided by the DirecNet Central Laboratory. Time series for the 25 patients in data set D and the 25 patients in data set J that contain the largest number of BG measurements are considered. These specific data sets were obtained to study the performance of CGM devices in children with Type I diabetes; as such, all of the patients are less than 18 years old. Summary statistics of the two data sets are provided in Table 2. Our method is a general purpose algorithm, where these details do not play any significant role, except in affecting the outcome of the experiments.
We provide results obtained by implementing our method in MATLAB, as described in Algorithm 1. For our implementation, we employ a sampling horizon
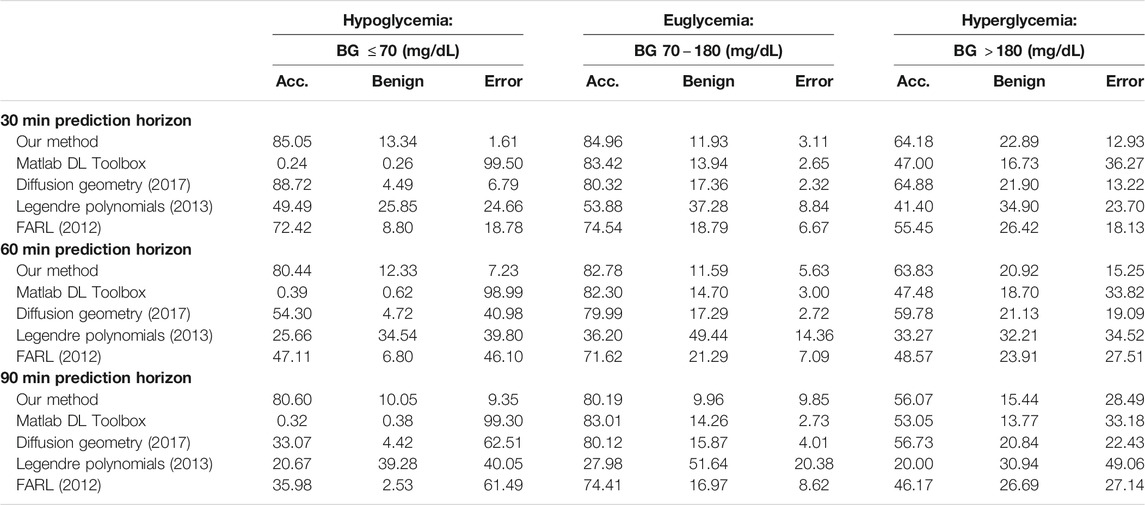
TABLE 3. Average PRED-EGA scores (in percent) for different prediction horizons on dataset D.
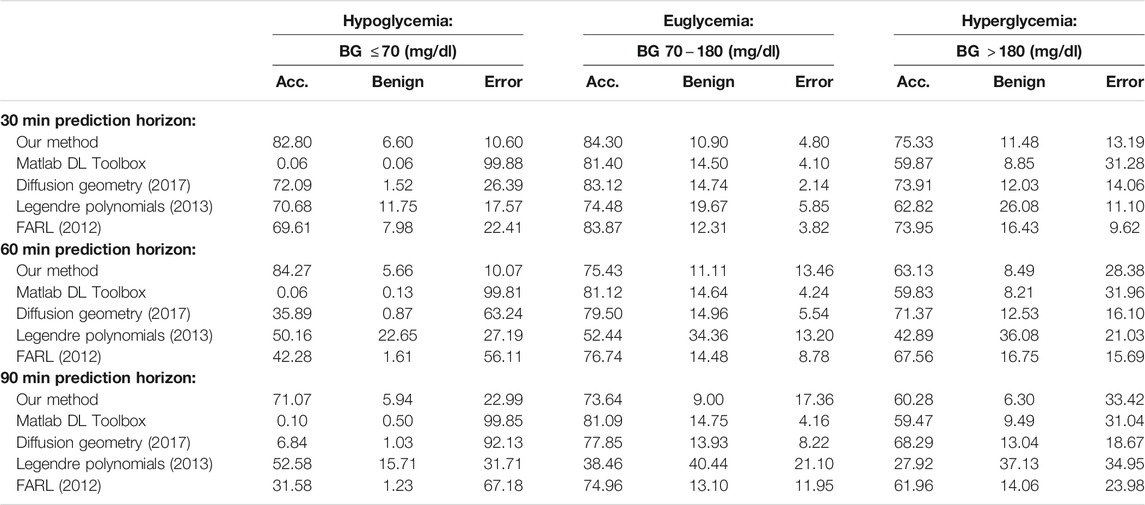
TABLE 4. Average PRED-EGA scores (in percent) for different prediction horizons on dataset J.
For comparison, Tables 3, 4 also display predictions on the same data sets using four other methods:
i) MATLAB’s built-in Deep Learning Toolbox. We used a network architecture consisting of three fully connected convolutional and output layers and appropriate input, normalization, activation, and averaging layers. As before, we used 50% training data and averaged the experiment over 100 trials, for prediction windows of 30 min, 60 and 90 min and data sets D and J.
ii) The diffusion geometry approach, based on the eigen-decomposition of the Laplace-Beltrami operator, we followed in our 2017 paper [8]. As mentioned in Section 1, this approach can be classified as semi-supervised learning, where we need to have all the data points
iii) The Legendre polynomial prediction method followed in our 2013 paper [6]. In this context, the main mathematical problem can be summarized as that of estimating the derivative of a function at the end point of an interval, based on measurements of the function in the past. An important difference between our current method and the Legendre polynoimal approach is that with the latter, learning is based on the data for each patient separately (each patient forms a data set in itself, as explained in Section 1). Therefore, the method is philosophically different from ours. We nevertheless include a comparison for prediction windows of 30 min, 60 and 90 min and data sets D and J.
iv) The Fully Adaptive Regularized Learning (FARL) approach in the 2012 paper [10], which uses meta-learning to choose the kernel and regularization parameters adaptively (briefly described in Section 2). As explained in [10], a strong suit of FARL is that it is expected to be portable from patient to patient without any readjustment. Therefore, the results reported below were obtained by implementing the code and parameters used in [10] directly on data sets D and J for prediction windows of 30 min, 60 and 90 min, with no adjustments for the kernel and regularization parameters. As explained earlier, this method is also not directly compared to our theoretically well founded method.
The percentage accurate predictions and predictions with benign consequences in all three BG ranges, as obtained using all five methods, for a 30 min, 60 and 90 min prediction window, are displayed visually in Figures 1, 2.
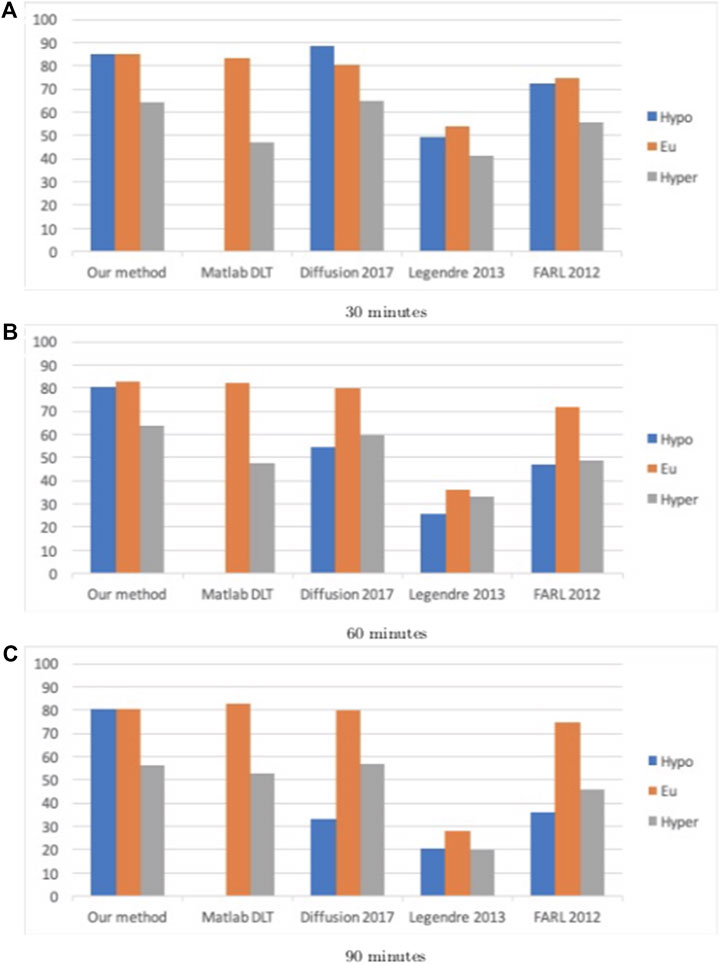
FIGURE 1. Percentage accurate predictions and predictions with benign consequences in all three BG ranges (blue: hypoglycemia; orange: euglycemia; grey: hyperglycemia) for dataset D, for all five methods for different prediction windows (30, 60, and 90 min).
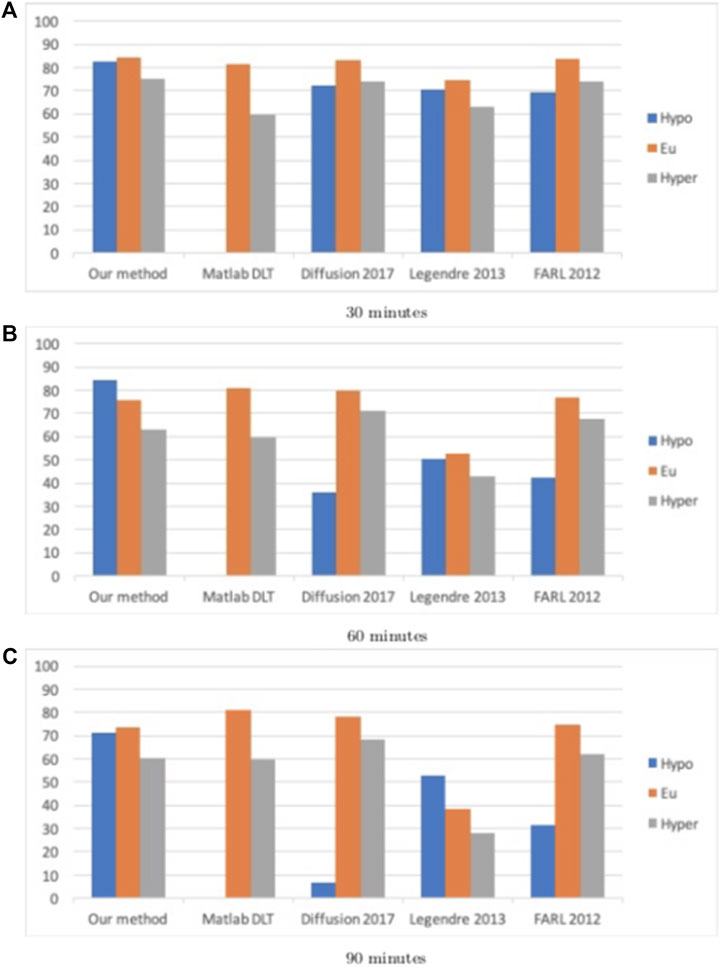
FIGURE 2. Percentage accurate predictions and predictions with benign consequences in all three BG ranges (blue: hypoglycemia; orange: euglycemia; grey: hyperglycemia) for dataset J, for all five methods for different prediction windows (30, 60, and 90 min).
By comparing the percentages in Tables 3, 4 and the bar heights in Figures 1, 2, it is clear that our method far outperforms the competitors in the hypoglycemic range, except for the 30 min prediction on data set D, where the diffusion geometry approach is slightly more accurate–but it is important to remember that the diffusion geometry approach has all the data points available from the outset. The starkest difference is between our method and Matlab’s Deep Learning Toolbox–the latter achieves less than 1.5% accurate and benign consequence predictions regardless of the size of the prediction window or data set. There is also a marked difference between our method and the Legendre polynomial approach, especially for longer prediction horizons. Our method achieves comparable or higher accuracy in the hyperglycemic range, except for the 60 and 90 min predictions on data set J, where the diffusion geometry and FARL approaches achieve more accurate predictions. The methods display comparable accuracy in the euglycemic range, except for the 60 and 90 min predictions on dataset J, where Matlab’s toolbox, the diffusion geometry approach and the FARL method achieve higher accuracy.
Tables 5, 6 display the results when testing those methods that are dependent on training data selection (that is, our current method, the Deep Learning Toolbox and the diffusion geometry approach in our 2017 paper) on different training set sizes (namely, 30, 50, 70 and 90%). For these experiments, we used a fixed prediction window of 30 min, and training data was drawn randomly according to a uniform probability distribution in each case. While the Deep Learning Toolbox and diffusion geometry approach sometimes perform slightly better than our method in the euglycemic and hypoglycemic ranges, respectively, our method consistently outperforms both of these in the other two blood glucose ranges. The results are displayed visually as well in Figures 3, 4.
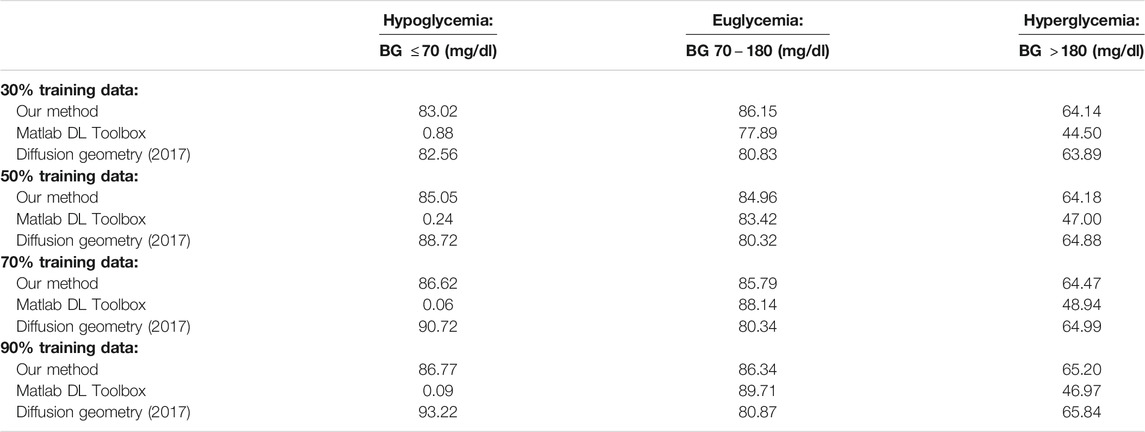
TABLE 5. Percentage accurate predictions for different training set sizes and a 30 min prediction horizon on dataset D.
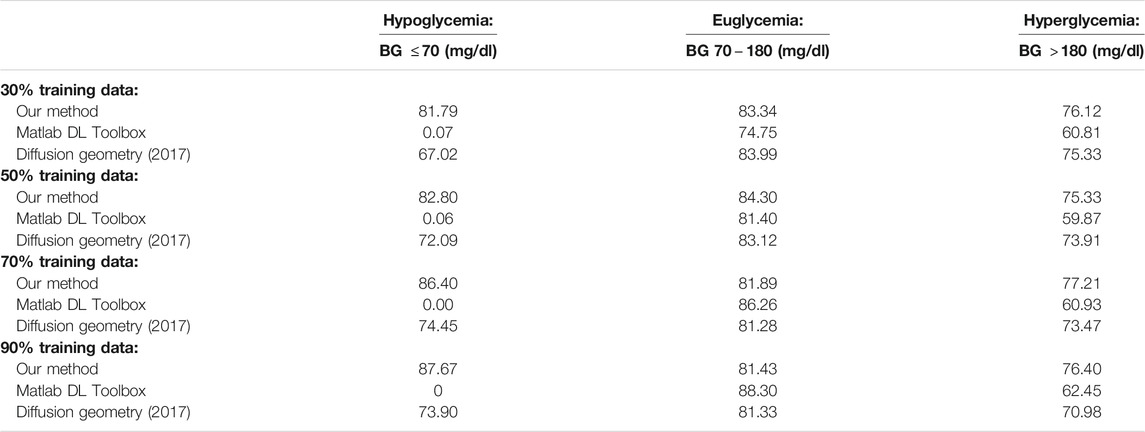
TABLE 6. Percentage accurate predictions for different training set sizes and a 30 min prediction horizon on dataset J.
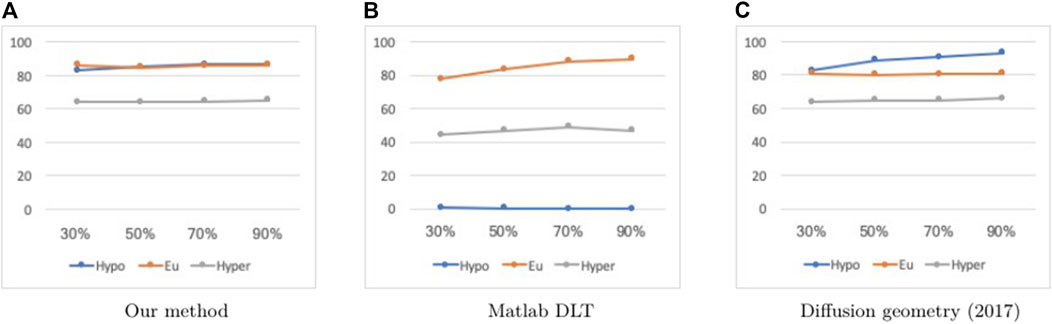
FIGURE 3. Percentage accurate predictions and predictions with benign consequences in all three BG ranges (blue: hypoglycemia; orange: euglycemia; grey: hyperglycemia) with a 30 min prediction window on dataset D, for different training set sizes (30, 50, 70 and 90%).
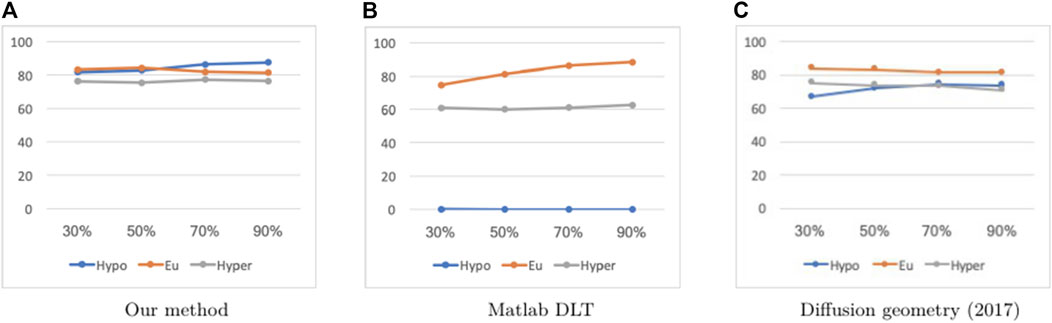
FIGURE 4. Percentage accurate predictions and predictions with benign consequences in all three BG ranges (blue: hypoglycemia; orange: euglycemia; grey: hyperglycemia) with a 30 min prediction window on dataset J, for different training set sizes (30, 50, 70 and 90%).
As mentioned in Section 1, a feature of our method is that it does not require any information about the data manifold other than its dimension. So, in principle, one could “train” on one data set and apply the resulting model to another data set taken from a different manifold. We illustrate this by constructing our model based on one of the data sets D or J and testing it on the other data set. Building on this idea, we also demonstrate the accuracy of our method as compared to MATLAB’s Deep Learning Toolbox when trained on data set D and applied to perform prediction on data set J, and vice versa, which is the only other method that is directly comparable with the philosophy behind our method. These results are reported in Tables 7, 8. It is clear that we are successful in our goal of training on one data set and predicting on a different data set. The percentage accurate predictions and predictions with benign consequences when training and testing on different datasets are comparable to the cases when we are training and testing on the same dataset; in fact, we obtain even better results in the hypoglycemic BG range when training and testing across different datasets.
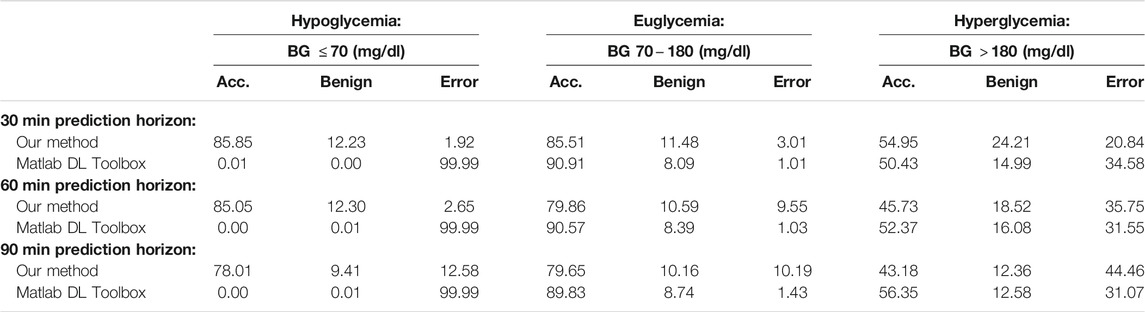
TABLE 7. Average PRED-EGA scores (in percent) for different prediction horizons on dataset D, with training data selected from dataset J.
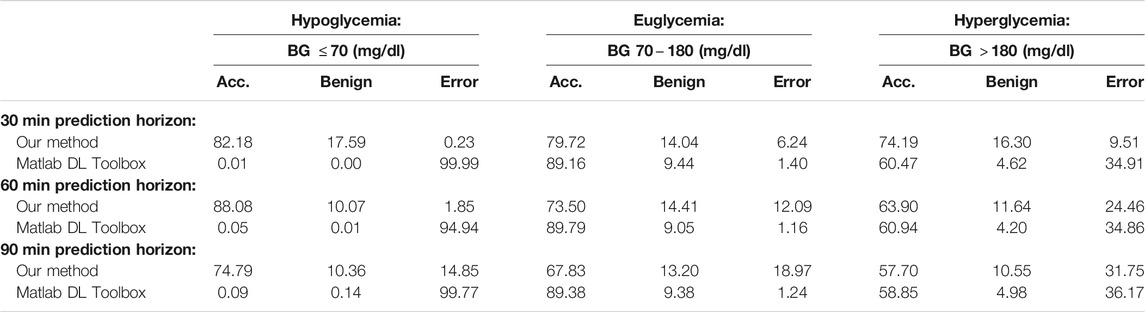
TABLE 8. Average PRED-EGA scores (in percent) for different prediction horizons on dataset J, with training data selected from dataset D.
Figures 5, 6 display box plots for the 100 trials for the methods dependent on training data selection (that is, our current method, the Deep Learning Toolbox and the 2017 diffusion geometry approach) and prediction windows using data sets D and J, respectively. Our method performs fairly consistently over different trials.
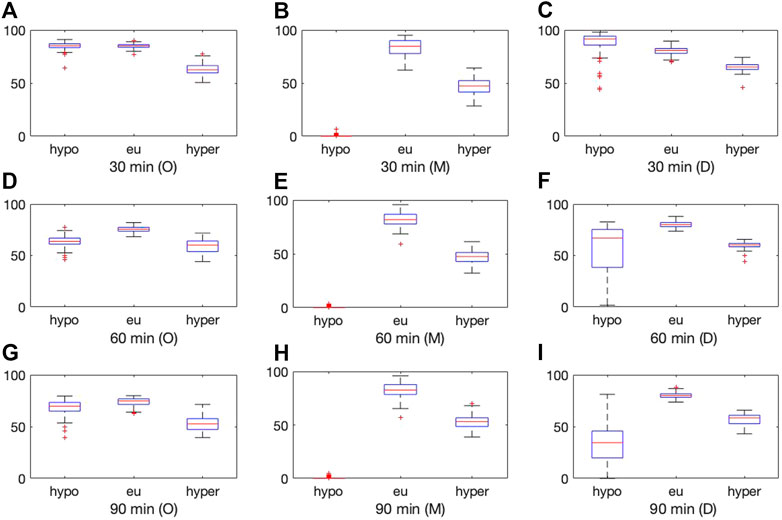
FIGURE 5. Boxplot for the 100 experiments conducted with 50% training data for each prediction method (O = our method, M = MATLAB Deep Learning Toolbox, D = diffusion geometry approach) with a 30 min (top), 60 min (middle) and 90 min (bottom) prediction horizon and dataset D. Each of the graphs show the percentage accurate predictions in the hypoglycemic range (left), euglycemic range (middle) and hyperglycemic range (right).
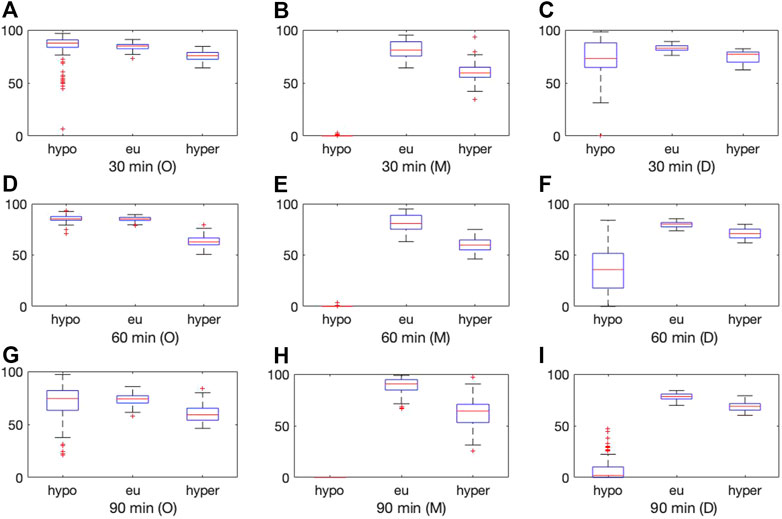
FIGURE 6. Boxplot for the 100 experiments conducted with 50% training data for each prediction method (O = our method, M = MATLAB Deep Learning Toolbox, D = diffusion geometry approach) with a 30 min (top), 60 min (middle) and 90 min (bottom) prediction horizon and dataset J. Each of the graphs show the percentage accurate predictions in the hypoglycemic range (left), euglycemic range (middle) and hyperglycemic range (right).
6 Conclusion
In this paper, we demonstrate a direct method to approximate functions on unknown manifolds [7] in the context of BG prediction for diabetes management. The results are evaluated using the state-of-the-art PRED-EGA grid [14]. Unlike classical manifold learning, our method yields a model for the BG prediction on data not seen during training, even for test data which is drawn from a different distribution from the training data. Our method outperforms other methods in the literature in 30, 60, and 90 min predictions in the hypoglycemic and hyperglycemic BG ranges, and is especially useful for BG prediction for patients that are not included in the training set.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://direcnet.jaeb.org/Studies.aspx.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
The research of HM is supported in part by NSF grant DMS 2012355 and ARO grant W911NF2110218. The research by SP has been partly supported by BMK, BMDW, and the Province of Upper Austria in the frame of the COMET Programme managed by FFG in the COMET Module S3AI.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank Professor Sampath Sivananthan at the Indian Institute of Technology, Delhi, India for providing us with the code used in [10] for the FARL approach.
References
1.DirecNet Central Laboratory (2005). Available at: http://direcnet.jaeb.org/Studies.aspx (Accessed January 1, 2021).
2. Clarke, WL, Cox, D, Gonder-Frederick, L. A, Carter, W, and Pohl, S. L. Evaluating Clinical Accuracy of Systems for Self-Monitoring of Blood Glucose. Diabetes care (1987) 10(5):622–8. doi:10.2337/diacare.10.5.622
3.Centers for Disease Control, Prevention. National Diabetes Statistics Report. Atlanta, GA: Centers for Disease Control and Prevention, US Department of Health and Human Services (2020). p. 12 15.
4. Hayes, AC, Mastrototaro, J. J, Moberg, SB, Mueller, JC, Clark, HB, Tolle, MCV, et al. Algorithm Sensor Augmented Bolus Estimator for Semi-closed Loop Infusion System. US Patent (2009) 7(547):281. June 16. Available at: https://patents.google.com/patent/US20060173406A1/en
5. Jung, M, Lee, Y-B, Jin, S-M, and Park, S-M. Prediction of Daytime Hypoglycemic Events Using Continuous Glucose Monitoring Data and Classification Technique. arXiv preprint arXiv:1704.08769, 2017.
6. Mhaskar, HN, Naumova, V, and Pereverzyev, SV. Filtered Legendre Expansion Method for Numerical Differentiation at the Boundary point with Application to Blood Glucose Predictions. Appl Maths Comput (2013) 224:835–47. doi:10.1016/j.amc.2013.09.015
7. Mhaskar, H. Deep Gaussian Networks for Function Approximation on Data Defined Manifolds (2019). arXiv preprint arXiv:1908.00156.
8. Mhaskar, HN, Sergei, V, and Mariavan der Walt, D. A Deep Learning Approach to Diabetic Blood Glucose Prediction. Front Appl Maths Stat (2017) 3(14). doi:10.3389/fams.2017.00014 Pereverzyev.
9. Mujahid, O, Contreras, I, and Vehi, J. Machine Learning Techniques for Hypoglycemia Prediction: Trends and Challenges. Sensors (2021) 21(2):546. doi:10.3390/s21020546
10. Naumova, V, Pereverzyev, SV, and Sivananthan, S. A Meta-Learning Approach to the Regularized Learning-Case Study: Blood Glucose Prediction. Neural Networks (2012) 33:181–93. doi:10.1016/j.neunet.2012.05.004
11. Pappada, SM, Cameron, BD, Rosman, PM, Bourey, RE, Papadimos, TJ, Olorunto, W, et al. Neural Network-Based Real-Time Prediction of Glucose in Patients with Insulin-dependent Diabetes. Diabetes Tech Ther (2011) 13(2):135–41. doi:10.1089/dia.2010.0104
12. Reifman, J, Rajaraman, S, Gribok, A, and Ward, WK. Predictive Monitoring for Improved Management of Glucose Levels. J Diabetes Sci Technol (2007) 1(4):478–86. doi:10.1177/193229680700100405
13. Seo, W, Lee, YB, Lee, S, Jin, SM, and Park, SM. A Machine-Learning Approach to Predict Postprandial Hypoglycemia. BMC Med Inform Decis Mak (2019) 19(1):210–3. doi:10.1186/s12911-019-0943-4
14. Sivananthan, S, Naumova, V, Man, CD, Facchinetti, A, Renard, E, Cobelli, C, et al. Assessment of Blood Glucose Predictors: the Prediction-Error Grid Analysis. Diabetes Tech Ther (2011) 13(8):787–96. doi:10.1089/dia.2011.0033
15. Sparacino, G, Zanderigo, F, Corazza, S, Maran, A, Facchinetti, A, and Cobelli, C. Glucose Concentration Can Be Predicted Ahead in Time from Continuous Glucose Monitoring Sensor Time-Series. IEEE Trans Biomed Eng (2007) 54(5):931–7. doi:10.1109/tbme.2006.889774
16. Reza Vahedi, M, MacBride, KB, Woo, W, Kim, Y, Fong, C, Padilla, AJ, et al. “Predicting Glucose Levels in Patients with Type1 Diabetes Based on Physiological and Activity Data,” In Proceedings of the 8th ACM MobiHoc 2018 Workshop on Pervasive Wireless Healthcare Workshop (2018). p. 1–5. doi:10.1145/3220127.3220133
17. Zhu, T, Li, K, Chen, J, Herrero, P, and Georgiou, P. Dilated Recurrent Neural Networks for Glucose Forecasting in Type 1 Diabetes. J Healthc Inform Res (2020) 4(3):308–24. doi:10.1007/s41666-020-00068-2
Appendix
A Theoretical aspects
In this section, we describe the theoretical background behind the estimator
Let
We write
The functions
In the sequel, we fix an infinitely differentiable function
and the kernel
We assume here a noisy data of the form
Remark A.1
In practice, the data may not lie on a manifold, but it is reasonable to assume that it lies on a tubular neighborhood of the manifold. Our notation accommodates this - if
Our approximation process is simple: given by
where
The theoretical underpinning of our method is described by Theorem A.1, and in particular, by Corollary A.1, describing the convergence properties of the estimator. In order to state these results, we need a smoothness class
Theorem A.1
Let
Let
then for every
Corollary A.1
With the set-up as in Theorem A.1, let
Keywords: hermite polynomial, continuous glucose monitoring, blood glucose prediction, supervised learning, prediction error-grid analysis
Citation: Mhaskar HN, Pereverzyev SV and van der Walt MD (2021) A Function Approximation Approach to the Prediction of Blood Glucose Levels. Front. Appl. Math. Stat. 7:707884. doi: 10.3389/fams.2021.707884
Received: 10 May 2021; Accepted: 09 July 2021;
Published: 30 August 2021.
Edited by:
Hau-Tieng Wu, Duke University, United StatesReviewed by:
Valeriya Naumova, Simula Research Laboratory, NorwayXin Guo, Hong Kong Polytechnic University, China
Copyright © 2021 Mhaskar, Pereverzyev and van der Walt. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: H. N, Mhaskar, aHJ1c2hpa2VzaC5taGFza2FyQGNndS5lZHU=