 Song-Ju Kim
Song-Ju Kim Taiki Takahashi
Taiki Takahashi
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 25 July 2018
Sec. Mathematical Finance
Volume 4 - 2018 | https://doi.org/10.3389/fams.2018.00027
This article is part of the Research Topic Intertemporal Choice and Its Anomalies View all 11 articles
Ellsberg paradox in decision theory posits that people will inevitably choose a known probability of winning over an unknown probability of winning even if the known probability is low [1]. One of the prevailing theories that addresses the Ellsberg paradox is known as “ambiguity-aversion.” In this study, we investigated the properties of ambiguity-aversion in four distinct types of reinforcement learning algorithms: ucb1-tuned [2], modified ucb1-tuned, softmax [3], and tug-of-war [4, 5]. We took the following scenario as our sample, in which there were two slot machines and each machine dispenses a coin according to a probability that is generated by its own probability density function (PDF). We then investigated the choices of a learning algorithm in such multi-armed bandit tasks. There were different reactions in multi-armed bandit tasks, depending on the ambiguity-preference in the learning algorithms. Notably, we discovered a clear performance enhancement related to ambiguity-preference in a learning algorithm. Although this study does not directly address the issue of ambiguity-aversion theory highlighted in Ellsberg paradox, the differences among different learning algorithms suggest that there is room for further study regarding the Ellsberg paradox and the decision theory.
Recently, neuroeconomics has been developing into an increasingly important academic discipline that helps to explain human behavior. Ellsberg paradox is a crucial topic in neuroeconomics, and researchers have employed various theories to approach and to resolve the paradox. The basic concept behind the Ellsberg paradox is that people will always choose a known probability of winning over an unknown probability of winning, even if the known probability is low and the unknown probability could be a near guarantee of winning.
Let us start with an example. Suppose we have an urn that contains 30 red balls and 60 other balls that are either black or yellow. We do not know how many black or yellow balls are there, but we know that the total number of black balls plus the total number of yellow balls equals 60. The balls are well mixed so that each individual ball is as likely to be drawn as any other.
You are now given a choice between two gambles:
[Gamble A] You receive $100 if you draw a red ball,
[Gamble B] You receive $100 if you draw a black ball.
In addition, you are given the choice between these two gambles (about a different draw from the same urn):
[Gamble C] You receive $100 if you draw a red or yellow ball,
[Gamble D] You receive $100 if you draw a black or yellow ball.
Participants are tempted to choose [Gamble A] and [Gamble D]. However, these choices violate the postulates of subjective expected utility [1].
It is well known that ambiguity-aversion property of decision-making is one of the prevailing theories advanced to explain this paradox. On the other hand, reinforcement learning algorithms, such as ucb1-tuned [2], modified ucb1-tuned, softmax [3], and tug-of-war dynamics [4, 5], have been employed in multiple approaches in artificial intelligence (AI) applications. There is tremendous potential for neuroeconomic studies to investigate the properties of decision-making through the use of AI (learning) algorithms. This study is the first attempt to investigate the properties of learning algorithms with regards to the ambiguity-preference point of view.
In this study, we took a multi-armed bandit problem (MAB) as a decision-making problem. We considered two slot machines A and B. Each machine gave rewards with individual probability density function (PDF) whose mean and standard deviations were μA (μB) and σA (σB), respectively. The player makes a decision on which machine to play at each trial, trying to maximize the total reward obtained after repeating several trials. The MAB is used to determine the optimal strategy for finding the machine with the highest rewards as accurately and quickly as possible by referring to past experiences. The MAB is related to many application problems in diverse fields, such as communications (cognitive networks [6, 7]), commerce (internet advertising [8]), and entertainment (Monte Carlo tree search techniques in computer game programs [9, 10]).
In this study, we focused on limited MAB cases. Machine A has constant probability 1/3, and machine B has probabilities generated by normal distribution N( + Δ μ, σ2). Here, we hypothesize that the total rewards from probabilities generated by a PDF is the same as the total rewards directly from the same PDF if we only focus on the average rewards using 1, 000 samples. On the basis of this hypothesis, we consider MABs, where PDFs are and N( + Δ μ, σ2). Here, δ(x) is a delta function. In this study, “ambiguity” is expressed by σ although “ambiguity” becomes “risk” if our hypothesis does not hold.
SOFTMAX algorithm is a well-known algorithm for solving MABs [3]. In this algorithm, the selecting probability of A or B, or , is given by the following Boltzmann distributions:
where Qk(t) (k ∈ {A, B}) is given by . Here, Nk(t) is the number of selections of machine k until time t and Rk(j) is the reward from machine k at time j. β is a time-dependent form in our study, which is as follows:
β = 0 corresponds to a random selection and β → ∞ corresponds to a greedy action. The SOFTMAX algorithm is “ambiguity-neutral” because “ambiguity” σ is not used in the algorithm.
In the tug-of-war (TOW) dynamics, a machine that has larger Xk (k ∈ {A, B}) is played in each time [4, 5]. Displacement XA (= −XB) is determined by the following equations:
Here, Qk(t) is an “estimate” of information of past experiences accumulated from the initial time 1 to the current time t, Nk(t) is the number of selections of machine k until time t, Rk(j) is the reward from machine k at time j, ξ(t) is an arbitrary fluctuation to which the body is subjected, and K is a parameter. Consequently, the TOW evolves according to a simple rule: in addition to the fluctuation, if machine k is played at each time t, Rk−K is added to Xk(t). The TOW is also “ambiguity-neutral” because “ambiguity” σ is not used in the algorithm.
In the UCB1-tuned algorithm, a machine that has larger “index” is played in each time [2].
Initialization: Play each machine once.
Loop: Play machine j that maximizes following index,
where is the average reward obtained from machine j, nj is the number of times machine j has been played so far, and n is the overall number of plays done so far. The UCB1-tuned algorithm has “ambiguity-preference” property because it selects high variance (“ambiguity”) machines in the early stage.
In the modified UCB1-tuned algorithm, a machine that has larger “index” is played in each time. Compared to UCB1-tuned algorithm, the sign of the second term in the index becomes minus.
Initialization: Play each machine once.
Loop: Play machine j that maximizes following index,
where is the average reward obtained from machine j, nj is the number of times machine j has been played so far, and n is the overall number of plays done so far. The UCB1-tuned algorithm has “ambiguity-aversion” property because it selects low variance (“ambiguity”) machines in the early stage.
In this study, we focused on the following limited MAB cases. On the basis of the hypothesis, we considered MABs where PDF of machine A is , and PDF of machine B is N( + Δ μ, σ2), respectively. “Ambiguity” is expressed by σ.
For positive Δμ, we investigate 30 cases where Δμ = 0.00, 0.05, 0.10, 0.15, and 0.20, and σ = 0.05, 0.10, 0.15, 0.20, 0.25, and 0.30, respectively. Figure 1 shows performance comparison between four learning algorithms for the MABs. The horizontal axis denotes Δ μ (6 different σ cases for each either Δ μ). The vertical axis denotes total rewards (average of 1, 000 samples) until time t = 1, 000 (also see Appendix in Supplementary Material).
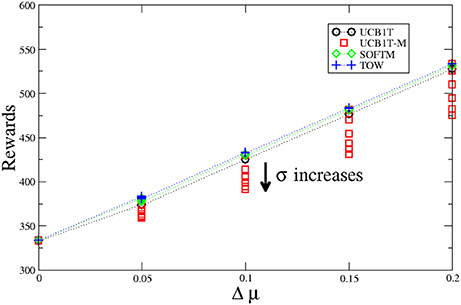
Figure 1. Performance comparison between four learning algorithms for MAB where PDFs are and N( + Δ μ, σ2). Δ μ is positive (cases where machine B is correct decision).
For positive Δμ cases, machine B is the correct selection because expected value of machine B is higher than A. This means that ambiguity-preference is needed for correct selections. The UCB1-tuned algorithm (ambiguity-preference) has higher performance than the modified UCB1-tuned algorithm (ambiguity-aversion) in the positive Δμ cases. Performance of the UCB1-tuned algorithms (ambiguity-preference) slightly increases as the ambiguity (σ) of the problems increases, whereas performance of the modified UCB1-tuned algorithms (ambiguity-aversion) largely decreases as ambiguity (σ) of the problems increases.
Performances of TOW and SOFTMAX are higher than those of UCB1-tuned and modified UCB1-tuned algorithms because each of the former two algorithms has a parameter that optimized the problems. That is, each of the two algorithms has an advantage over the latter two algorithms that have no parameter. Performances of the former two algorithms (ambiguity-neutral) slightly decrease as ambiguity (σ) of the problems increases. This is because incorrect decisions are slightly increased as estimation for mean value of rewards becomes largely fluctuated.
For negative Δμ, we also investigated 30 cases where Δμ = 0.00, 0.05, 0.10, 0.15, and 0.20, and σ = 0.05, 0.10, 0.15, 0.20, 0.25, and 0.30, respectively. Figure 2 shows the performance comparison between four learning algorithms for the MABs. The horizontal axis denotes Δ μ (6 different σ cases for each Δ μ). The vertical axis denotes total rewards (average of 1, 000 samples) until time t = 1, 000 (also see Appendix in Supplementary Material).
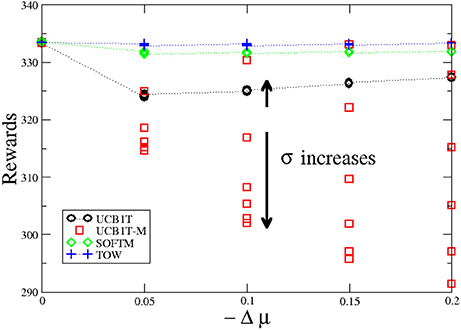
Figure 2. Performance comparison between four learning algorithms for MAB where PDFs are and N( + Δ μ, σ2). Δ μ is negative (cases where machine A is correct decision).
For negative Δμ cases, machine A is correct selection because expected value of machine A is higher than B. This means that ambiguity-aversion is needed for correct selections. The modified UCB1-tuned algorithm (ambiguity-aversion) has higher performance than the UCB1-tuned algorithm (ambiguity-preference) in the negative Δμ cases only in σ = 0.05. Performance of the UCB1-tuned algorithms (ambiguity-preference) slightly increases as ambiguity (σ) of the problems increases, whereas performance of the modified UCB1-tuned algorithms (ambiguity-aversion) largely decreases as ambiguity (σ) of the problems increases.
Performances of TOW and SOFTMAX are higher than those of UCB1-tuned and modified UCB1-tuned algorithms because each of the former two algorithms has a parameter that optimized the problems as well as the positive Δμ cases. Performances of the former two algorithms (ambiguity-neutral) also slightly decrease as the ambiguity (σ) of the problems increases because of the same reason as the positive Δμ cases.
In both cases (positive Δμ and negative Δμ), performance of the UCB1-tuned algorithms (ambiguity-preference) slightly increases as the ambiguity (σ) of the problems increases, whereas performance of the modified UCB1-tuned algorithms (ambiguity-aversion) largely decreases as the ambiguity (σ) of the problems increases. This means that ambiguity-aversion property of learning algorithm has a negative contribution to its performances for MABs, whereas ambiguity-preference has a positive contribution.
From these limited computer simulation results, we conclude that ambiguity-aversion property does not work for efficient decision-making in the learning point of view (repeated decision-making situations). Another point of view will be necessary for justification of ambiguity-aversion property. We suggest that the differences among learning algorithms require further study on the Ellsberg paradox and decision theory.
S-JK and TT designed research. S-JK performed computer simulations. S-JK and TT analyzed the data. S-JK wrote the manuscript. All authors reviewed the manuscript.
This work was supported in part by the Grant-in-Aid for Challenging Exploratory Research (15K13387) from the Japan Society for the Promotion of Science, and by the CREST (JPMJCR17A4) ID-17941861 from Japan Science and Technology Agency.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We would like to thank Prof. Masashi Aono and Dr. Makoto Naruse for fruitful discussions in an early stage of this work.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2018.00027/full#supplementary-material
2. Auer P, Cesa-Bianchi N, Fischer P. Finite-time analysis of the multiarmed bandit problem. Mach Learn. (2002) 47:235–56. doi: 10.1023/A:1013689704352
4. Kim S-J, Aono M, Nameda E. Efficient decision-making by volume-conserving physical object. New J. Phys. (2015) 17:083023. doi: 10.1088/1367-2630/17/8/083023
5. Kim S-J, Tsuruoka T, Hasegawa T, Aono M, Terabe K, Aono M. Decision maker based on atomic switches. AIMS Mater. Sci. (2016) 3:245–59. doi: 10.3934/matersci.2016.1.245
6. Lai L, Jiang H, Poor HV. Medium access in cognitive radio networks: a competitive multi-armed bandit framework. In: Proceedings of IEEE 42nd Asilomar Conference on Signals, System and Computers (California, CA) (2008). p. 98–102.
7. Lai L, Gamal HE, Jiang H, Poor HV. Cognitive medium access: exploration, exploitation, and competition. IEEE Trans Mobile Comput. (2011) 10:239–53. doi: 10.1109/TMC.2010.65
8. Agarwal D, Chen BC, Elango P. Explore/exploit schemes for web content optimization. In: Proceedings of ICDM2009 (2009). doi: 10.1109/ICDM.2009.52
9. Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning. In: ECML2006, LNAI 4212. Berlin: Springer (2006). p. 282–93.
Keywords: decision making, Ellsberg paradox, ambiguity aversion, reinforcement learning, machine learning, artificial intelligence, natural computing, neuroeconomics
Citation: Kim S-J and Takahashi T (2018) Performance in Multi-Armed Bandit Tasks in Relation to Ambiguity-Preference Within a Learning Algorithm. Front. Appl. Math. Stat. 4:27. doi: 10.3389/fams.2018.00027
Received: 20 April 2018; Accepted: 14 June 2018;
Published: 25 July 2018.
Edited by:
Hyeng Keun Koo, Ajou University, South KoreaReviewed by:
Simon Grima, University of Malta, MaltaCopyright © 2018 Kim and Takahashi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Song-Ju Kim, c29uZ2p1QHNmYy5rZWlvLmFjLmpw
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.