 Alessandro Rudi
Alessandro Rudi Ernesto De Vito
Ernesto De Vito Alessandro Verri4
Alessandro Verri4 Francesca Odone
Francesca Odone
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat., 08 November 2017
Sec. Mathematics of Computation and Data Science
Volume 3 - 2017 | https://doi.org/10.3389/fams.2017.00023
In the framework of non-parametric support estimation, we study the statistical properties of a set estimator defined by means of Kernel Principal Component Analysis. Under a suitable assumption on the kernel, we prove that the algorithm is strongly consistent with respect to the Hausdorff distance. We also extend the above analysis to a larger class of set estimators defined in terms of a low-pass filter function. We finally provide numerical simulations on synthetic data to highlight the role of the hyper parameters, which affect the algorithm.
A classical issue in statistics is support estimation, i.e., the problem of learning the support of a probability distribution from a set of points identically sampled according to the distribution. For example, the Devroye-Wise algorithm [1] estimates the support with the union of suitable balls centered in the training points. In the last two decades, many algorithms have been proposed and their statistical properties analyzed [1–14] and references therein.
An instance of the above setting, which plays an important role in applications, is the problem of novelty/anomaly detection, see Campos et al. [15] for an updated review. In this context, in Hoffmann [16] the author proposed an estimator based on Kernel Principal Component Analysis (KPCA), first introduced in Schölkopf et al. [17] in the context of dimensionality reduction. The algorithm was successfully tested in many applications from computer vision to biochemistry [18–24]. In many of these examples the data are often represented by high dimensional vectors, but they actually live close to a nonlinear low dimensional submanifold of the original space, and the proposed estimator takes advantage of the fact that KPCA provides an efficient compression/dimensionality reduction of the original data [16, 17], whereas many classical set estimators refer to the dimension of the original space, as it happens for the Devroye-Wise algorithm.
In this paper we prove that KPCA is a consistent estimator of the support of the distribution with respect to the Hausdorff distance. The result is based on an intriguing property of the reproducing kernel, called separating condition, first introduced in De Vito et al. [25]. This assumption ensures that any closed subset of the original space is represented in the feature space by a linear subspace. We show that this property remains true if the data are recentered to have zero mean in the feature space. Together with the results in De Vito et al. [25], we conclude that the consistency of KPCA algorithm is preserved by recentering of the data, which can be regarded as a degree of freedom to improve the empirical performance of the algorithm in a specific application.
Our main contribution is sketched in the next subsection together with some basic properties of KPCA and some relevant previous works. In section 2, we describe the mathematical framework and the related notations. Section 3 introduces the spectral support estimator and informally discusses its main features, whereas its statistical properties and the meaning of the separating condition for the kernel are analyzed in section 4. Finally section 5 presents the effective algorithm to compute the decision function and discusses the role of the two meta-parameters based on the previous theoretical analysis. In the Appendix (Supplementary Material), we collect some technical results.
In this section we sketch our main result by first recalling the construction of the KPCA estimator introduced in Hoffmann [16]. We have at disposal a training set of n points independently sampled according to some probability distribution P. The input space is a known compact subset of ℝd, but the probability distribution P is unknown and the goal is to estimate the support C of P from the empirical data. We recall that C is the smallest closed subset of such that ℙ[C] = 1 and we stress that C is in general a proper subset of , possibly of low dimension.
Classical Principal Component Analysis (PCA) is based on the construction of the vector space V spanned by the first m eigenvectors associated with the largest eigenvalues of the empirical covariance matrix
where is the empirical mean. However, if the data do not live on an affine subspace, the set V is not a consistent estimator of the support. In order to take into account non-linear models, following the idea introduced in Schölkopf et al. [17] we consider a feature map Φ from the input space into the corresponding feature space , which is assumed to be a Hilbert space, and we replace the empirical covariance matrix with the empirical covariance operator
where is the empirical mean in the feature space. As it happens in PCA, we consider the subspace of spanned by the first m- eigenvectors of . According to the proposal in Hoffmann [16], we consider the following estimator of the support of the probability distribution P
where τn is a suitable threshold depending on the number of examples and
is the projection of an arbitrary point onto the affine subspace . We show that, under a suitable assumption on the feature map, called separating property, is a consistent estimator of C with respect to the Hausdorff distance between compact sets, see Theorem 3 of section 4.2.
The separating property was introduced in De Vito et al. [25] and it ensures that the feature space is rich enough to learn any closed subset of . This assumption plays the same role of the notion of universal kernel [26] in supervised learning.
Moreover, following [25, 27] we extend the KPCA estimator to a class of learning algorithms defined in terms of a low-pass filter function rm(σ) acting on the spectrum of the covariance matrix and depending on a regularization parameter m ∈ ℕ. The projection of onto is replaced by the vector
where is the family of eigenvectors of and is the corresponding family of eigenvalues. The support is then estimated by the set
Note that KPCA corresponds to the choice of the hard-cut off filter
However, other filter functions can be considered, inspired by the theory of regularization for inverse problems [28] and by supervised learning algorithms [29, 30]. In this paper we show that the explicit computation of these spectral estimators reduces to a finite dimensional problem depending only on the kernel K(x, w) = 〈Φ(x), Φ(w)〉 associated with the feature map, as for KPCA. The computational properties of each learning algorithm depend on the choice of the low-pass filter rm(σ), which can be tuned to out-perform of some specific data set, see the discussion in Rudi et al. [31].
We conclude this section with two considerations. First, in De Vito et al. [25, 27] it is proven a consistency result for a similar estimator, where the subspace is computed with respect to the non-centered covariance matrix in the feature space , instead of the covariance matrix. In this paper we analyze the impact of recentering the data in the feature space on the support estimation problem, see Theorem 1 below. This point of view is further analyzed in Rudi et al. [32, 33].
Finally note that, our consistency results are based on convergence rates of empirical subspaces to true subspaces of the covariance operator, see Theorem 2 below. The main difference between our result and the result in Blanchard et al. [34], is that we prove the consistency for the case when the dimension m = mn of the subspace goes to infinity slowly enough. On the contrary, in their seminal paper [34] the authors analyze the most specific case when the dimension of the projection space is fixed.
In this section we introduce the statistical model generating the data, the notion of separating feature map and the properties of the filter function. Furthermore, we show that KPCA can be seen as a filter function and we recall the main properties of the covariance operators.
We assume that the input space is a bounded closed subset of ℝd. However, our results also hold true by replacing with any compact metric space. We denote by d(x, w) the Euclidean distance |x − w| between two points x, w ∈ ℝd and by dH(A, B) the Hausdorff distance between two compact subsets , explicitly given by
where .
The statistical model is described by a random vector X taking value in . We denote by P the probability distribution of X, defined on the Borel σ-algebra of , and by C the support of P.
Since the probability distribution P is unknown, so is its support. We aim to estimate C from a training set of empirical data, which are described by a family X1, …, Xn of random vectors, which are independent and identically distributed as X. More precisely, we are looking for a closed subset , depending only on X1, …, Xn, but independent of P, such that
for all probability distributions P. In the context of regression estimate, the above convergence is usually called universal strong consistency [35].
To define the estimator we first map the data into a suitable feature space, so that the support C is represented by a linear subspace.
Assumption 1. Given a Hilbert space , take satisfying the following properties:
(H1) the set is total in , i.e.,
where denotes the closure of the linear span;
(H2) the map Φ is continuous.
The space is called the feature space and the map Φ is called a Mercer feature map.
In the following the norm and scalar product of are denoted by ||·|| and 〈··〉, respectively.
Assumptions (H1) and (H2) are standard for kernel methods, see Steinwart and Christmann [36]. We now briefly recall some basic consequences. First of all, the map
is a Mercer kernel and we denote by the corresponding (separable) reproducing kernel Hilbert space, whose elements are continuous functions on . Moreover, each element defines a function by setting fΦ(x) = 〈f, Φ(x)〉 for all . Since is total in , the linear map f ↦ fΦ is an isometry from onto . In the following, with slight abuse of notation, we write f instead of fΦ, so that the elements are viewed as functions on satisfying the reproducing property
Finally, since is compact and Φ is continuous, it holds that
Following De Vito et al. [27], we call Φ a separating Mercer feature map if the following the separating property also holds true.
(H3) The map Φ is injective and for all closed subsets
It states that any closed subset is mapped by Φ onto the intersection of and the closed subspace . Examples of kernels satisfying the separating property are for [27]:
• Sobolev kernels with smoothness index ;
• the Abel/Laplacian kernel K(x, w) = e − γ|x − w| with γ > 0;
• the ℓ1-kernel , where |·|1 is the ℓ1-norm and γ > 0.
As shown in De Vito et al. [25], given a closed set the equality (2) is equivalent to the condition that for every there exists such that
Clearly, an arbitrary Mercer feature map is not able to separate all the closed subsets, but only few of them. To better describe these sets, we introduce the elementary learnable sets, namely
where . Clearly, is closed and the equality (3) holds true. Furthermore the intersection of an arbitrary family of elementary learnable sets with satisfies (3), too. Conversely, if is a set satisfying (2), select a maximal family {fj}j∈J of orthonormal functions in such that
i.e., a basis of the orthogonal complement of , then it is easy to prove that
so that any set which is separating by Φ is the (possibly denumerable) intersection of elementary sets. Assumption (H3) is hence a requirement that the family of the elementary learnable sets, labeled by the elements of , is rich enough to parameterize all the closed subsets of by means of (4). In section 4.3 we present some examples.
The Gaussian kernel K(x, w) = e−γ|x−w|2 is a popular choice in machine learning, however it is not separating. Indeed, since K is analytic, the elements of the corresponding reproducing kernel Hilbert space are analytic functions, too [36]. It is known that, given an analytic function f ≠ 0, the corresponding elementary learnable set is a closed set whose interior is the empty set. Hence also the denumerable intersections have empty interior, so that K can not separate a support with not-empty interior. In Figure 1 we compare the decay behavior of the eigenvalues of the Laplacian and the Gaussian kernels.
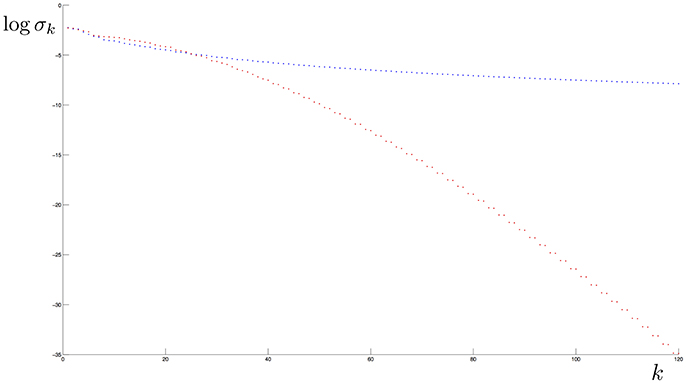
Figure 1. Eigenvalues in logarithmic scale of the Covariance operator when the kernel is Abel (blue) and Gaussian (red) and the distribution is uniformly supported on the “8” curve in Figure 2. Note that the eigenvalue decay rate of the first operator has a polynomial behavior while the second has an exponential one.
The second building block is a low pass filter, we introduce to avoid that the estimator overfits the empirical data. The filter functions were first introduced in the context of inverse problem, see Engl et al. [28] and references therein, and in the context of supervised learning, see Lo Gerfo et al. [29] and Blanchard and Mucke [30].
We now fix some notations. For any , we denote by f ⊗ f the rank one operator (f ⊗ f)g = 〈gf〉f. We recall that a bounded operator A on is a Hilbert-Schmidt operator if for some (any) basis {fj}j the series is finite, ||A||2 is called the Hilbert-Schmidt norm and ||A||∞ ≤ ||A||2, where ||·||∞ is the spectral norm. We denote by the space of Hilbert-Schmidt operators, which is a separable Hilbert space under the scalar product .
Assumption 2. A filter function is a sequence of functions rm:[0, R] → [0, 1], with m ∈ ℕ, satisfying
(H4) for any m ∈ ℕ, rm(0) = 0;
(H5) for all σ > 0, ;
(H6) for all m ∈ ℕ, there is Lm > 0 such that
i.e., rm is a Lipschitz function with Lipschitz constant Lm.
For fixed m, rm is a filter cutting the smallest eigenvalues (high frequencies). Indeed, (H4) and (H6) with σ′ = 0 give
On the contrary, if m goes to infinity, by (H5) rm converges point-wisely to the Heaviside function
Since rm(σ) converges to Θ(σ), which does not satisfy (5), we have that .
We fix the interval [0, R] as domain of the filter functions rm since the eigenvalues of the operators we are interested belong to [0, R], see (23).
Examples of filter functions are
• Tikhonov filter
• Soft cut-off
• Landweber iteration
We recall a technical result, which is based on functional calculus for compact operators. If A is a positive Hilbert-Schmidt operator, Hilbert-Schmidt theorem (for compact self-adjoint operators) gives that there exist a basis {fj}j of and a family {σj}j of positive numbers such that
If the spectral norm ||A||∞ ≤ R, then all the eigenvalues σj belong to [0, R] and the spectral calculus defines rm(A) as the operator on given by
With this definition each fj is still an eigenvector of rm(A), but the corresponding eigenvalue is shrunk to rm(σj). Proposition 1 in the Appendix in Supplementary Material summarizes the main properties of rm(A).
As anticipated in the introduction, the estimators we propose are a generalization of KPCA suggested by Hoffmann [16] in the context of novelty detection. In our framework this corresponds to the hard cut-off filter, i.e., by labeling the different eigenvalues of A in a decreasing order1 σ1 > σ2 > … > σm > σm+1 > …, the filter function is
Clearly, rm satisfies (H4) and (H5), but (H6) does not hold. However, the Lipschitz assumption is needed only to prove the bound (21e) and, for the hard cut-off filter, rm(A) is simply the orthogonal projector onto the linear space spanned by the eigenvectors whose eigenvalues are bigger than σm+1. For such projections [37] proves the following bound
so that (21e) holds true with . Hence, our results also hold for hard cut-off filter at the price to have a Lipschitz constant Lm depending on the eigenvalues of A.
The third building block is made of the eigenvectors of the distribution dependent covariance operator and of its empirical version. The covariance operators are computed by first mapping the data in the feature space .
As usual, we introduce two random variables Φ(X) and Φ(X) ⊗ Φ(X), taking value in and in , respectively. Since Φ is continuous and X belongs to the compact subset , both random variables are bounded. We set
where the integrals are in the Bochner sense.
We denote by and the empirical mean of Φ(X) and Φ(X) ⊗ Φ(X), respectively, and by the empirical covariance operator, respectively. Explicitly,
The main properties of the covariance operator and its empirical version are summarized in Proposition 2 in the Appendix in Supplementary Material.
Now we are ready to construct the estimator, whose computational aspects are discussed in section 5. The set is defined by the following three steps:
a) the points are mapped into the corresponding centered vectors , where the center is the empirical mean;
b) the operator is applied to each vector ;
c) the point is assigned to if the distance between and is smaller than a threshold τ.
Explicitly we have that
where τ = τn and m = mn are chosen as a function of the number n of training data.
With the choice of the hard cut-off filter, this reduces to the KPCA algorithm [16, 17]. Indeed, is the projection Qm onto the vector space spanned by the first m eigenvectors. Hence is the set of points x whose image is close to Qm. For an arbitrary filter function rm, Qm is replaced by , which can be interpreted as a smooth version of Qm. Note that, in general, is not a projection.
In De Vito et al. [27] a different estimator is defined. In that paper the data are mapped in the feature space without centering the points with respect to the empirical mean and the estimator is given by
where the filter function rm is as in the present work, but is defined in terms of the eigenvectors of the non-centered second momentum . To compare the two estimators note that
where , which is a filter function too, possibly with a Lipschitz constant . Note that for the hard cut-off filter .
Though and are different, both and converge to the support of the probability distribution P, provided that the separating property (H3) holds true. Hence, one has the freedom to choose if the empirical data have or not zero mean in the feature space.
In this section, we prove that the estimator we introduce is strongly consistent. To state our results, for each n ∈ ℕ, we fix an integer mn ∈ ℕ and set to be
so that Equation (9) becomes
First of all, we characterize the support of P by means of Qc, the orthogonal projector onto the null space of the distribution dependence covariance operator Tc. The following theorem will show that the centered feature map
sends the support C onto the intersection of and the closed subspace , i.e,
Theorem 1. Assume that Φ is a separating Mercer feature map, then
where Qc is the orthogonal projector onto the null space of the covariance operator Tc.
Proof. To prove the result we need some technical lemmas, we state and prove in the Appendix in Supplementary Material. Assume first that is such that Qc(Φ(x) − μ) = 0. Denoted by Q the orthogonal projection onto the null space of T, by Lemma 2 QQc = Q and Qμ = 0, so that
Hence Lemma 1 implies that x ∈ C.
Conversely, if x ∈ C, then as above Q(Φ(x) − μ) = 0. By Lemma 2 we have that Qc(1 − Q) = ||Qcμ||−2Qc μ ⊗ Qcμ. Hence it is enough to prove that
which holds true by Lemma 3.
Our first result is about the convergence of .
Theorem 2. Assume that Φ is a Mercer feature map. Take the sequence {mn}n such that
for some constant κ > 0, then
Proof. We first prove Equation (13). Set . Given ,
where the fourth line is due to (21e), the bound , and the fact that both Φ(x) and μ are bounded by . By (12b) it follows that
so that, taking into account (24a) and (24c), it holds that
almost surely, provided that limn→+∞∥(rmn(Tc) − (I − Qc))(Φ(x) − μ)∥ = 0. This last limit is a consequence of (21d) observing that is compact since is compact and Φ is continuous.
We add some comments. Theorem 1 suggests that the consistency depends on the fact that the vector is a good approximation of Qc(Φ(x)−μ). By the law of large numbers, and converge to T and μ, respectively, and Equation (21d) implies that, if m is large enough, (I − rm(T))(Φ(x)−μ) is closed to Qc(Φ(x)−μ). Hence, if mn is large enough, see condition (12a), we expect that is close to . However, this is true only if mn goes to infinity slowly enough, see condition (12b). The rate depends on the behavior of the Lipschitz constant Lm, which goes to infinity if m goes to infinity. For example, for Tikhonov filter a sufficient condition is that with ϵ > 0. With the right choice of mn, the empirical decision function converges uniformly to the function F(x) = Qc(Φ(x) − μ), see Equation (13).
If the map Φ is separating, Theorem 1 gives that the zero level set of F is precisely the support C. However, if C is not learnable by Φ, i.e., the equality (2) does not hold, then the zero level set of F is bigger than C. For example, if is connected, C has not-empty interior and Φ is the feature map associated with the Gaussian kernel, it is possible to prove that F is an analytic function, which is zero on an open set, hence it is zero on the whole space . We note that, in real applications the difference between Gaussian and Abel kernel, which is separating, is not so big and in our experience the Gaussian kernel provides a reasonable estimator.
From now on we assume that Φ is separating, so that Theorem 1 holds true. However, the uniform convergence of to F does not imply that the zero level sets of converges to C = F−1(0) with respect to the Hausdorff distance. For example, with the Tikhonov filter is always the empty set. To overcome the problem, is defined as the τn-neighborhood of the zero level set of , where the threshold τm goes to zero slowly enough.
Define the data dependent parameter as
Since , clearly and the set estimator becomes
The following result shows that is a universal strongly consistent estimator of the support of the probability distribution P. Note that for KPCA the consistency is not universal since the choice of mn depends on some a-priori information about the decay of the eigenvalues of the covariance operator Tc, which depends on P.
Theorem 3. Assume that Φ is a separating Mercer feature map. Take the sequence {mn}n satisfying (12a)-(12b) and define by (14). Then
Proof. We first show Equation (15a). Set F(x) = Qc(Φ(x) − μ) and let E be the event on which converges uniformly to F(x), and F be the event such that Xi ∈ C for all i ≥ 1. Theorem 2 shows that ℙ[E] = 1 and, since C is the support, then ℙ[F] = 1. Take ω ∈ E ∩ F and fix ϵ > 0, then there exists n0 > 0 (possibly depending on ω and ϵ) such that for all n ≥ n0 for all . By Theorem 1 F(x) = 0 for all x ∈ C and X1(ω), …, Xn(ω) ∈ C, it follows that for all 1 ≤ i ≤ n so that , so that the sequence goes to zero. Since ℙ[E ∩ F] = 1 Equation (15a) holds true.
We split the proof of Equation (15b) in two steps. We first show that with probability one . On the event E ∩ F, suppose, by contraction, that the sequence does not converge to zero. Possibly passing to a subsequence, for all n ∈ ℕ there exists such that for some fixed ϵ0 > 0. Since is compact, possibly passing to a subsequence, {xn}n converges to with d(x0, C) ≥ ϵ0. We claim that x0 ∈ C. Indeed,
since means that . If n goes to infinity, since Φ is continuous and by the definition of E and F, the right side of the above inequality goes to zero, so that , i.e., by Theorem 1 we get x0 ∈ C, which is a contraction since by construction d(x0, C) ≥ ϵ0 > 0.
We now prove that
For any , set X1,n(x) to be a first neighbor of x in the training set {X1, …, Xn}. It is known that for all x ∈ C,
see for example Lemma 6.1 of Györfi et al. [35].
Choose a denumerable family {zj}j ∈ J in C such that is dense in C. By Equation (16) there exists an event G with such that ℙ[G] = 1 and, on G, for all j ∈ J
Fix ω ∈ G, we claim that . Observe that, by definition of , for all 1 ≤ i ≤ n and
so that it is enough to show that .
Fix ϵ > 0. Since C is compact, there is a finite subset Jϵ ⊂ J such that {B(zj, ϵ)}j ∈ Jϵ is a finite covering of C. Furthermore,
Indeed, fix x ∈ C, there exists an index j ∈ Jϵ such that x ∈ B(zj, ϵ). By definition of first neighbor, clearly
so that by triangular inequality we get
Taking the supremum over C we get the claim. Since ω ∈ G and Jϵ is finite,
so that by Equation (17)
Since ϵ is arbitrary, we get , which implies that
Theorem 3 is an asymptotic result. Up to now, we are not able to provide finite sample bounds on dH(Ĉn, C). It is possible to have finite sample bounds on , as in Theorem 7 of De Vito et al. [25] with the same kind of proof.
The following two examples clarify the notion of the separating condition.
Example 1. Let be a compact subset of ℝ2, with the euclidean scalar product, and be the feature map
whose corresponding Mercer kernel is a polynomial kernel of degree two, explicitly given by
Given a vector , the corresponding elementary set is the conic
Conversely, all the conics are elementary sets. The family of all the intersections of at most five conics, i.e., the sets whose cartesian equation is a system of the form
where f11, …, f56 ∈ ℝ.
Example 2. The data are the random vectors in ℝ2
where a, c ∈ ℕ, b, d ∈ [0, 2π] and Θ1, …, Θn are independent random variables, each of them uniformly distributed on [0, 2π]. Setting , clearly and the support of their common probability distribution is the Lissajous curve
Figure 2 shows two examples of Lissajous curves. As a filter function rm, we fix the hard cut-off filter where m is the number of eigenvectors corresponding to the highest eigenvalues we keep. We denote by the corresponding estimator given by (10).
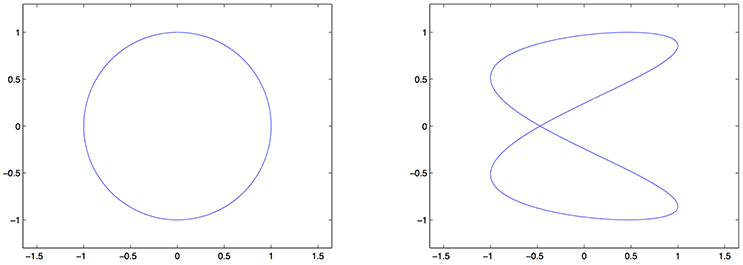
Figure 2. Examples of Lissajous curves for different values of the parameters. (Left) . (Right) Lis2,0.11,1,0.3.
In the first two tests we use the polynomial kernel (18), so that the elementary learnable sets are conics. One can check that the rank of Tc is less or equal than 5. More precisely, if Lisa,b,c,d is a conic, the rank of Tc is 4 and we need to estimate five parameters, whereas if Lisa,b,c,d is not a conic, Lisa,b,c,d is not a learnable set and the rank of Tc is 5.
In the first test the data are sampled from the distribution supported on the circumference (see panel left of Figure 2). In Figure 3 we draw the set for different values of m and τ when n varies. In this toy example n = 5 is enough to learn exactly the support, hence for each n = 2, …, 5 the corresponding values of mn and τn are mn = 1, 2, 3, 4 and τn = 0.01, 0.005, 0.005, 0.002.
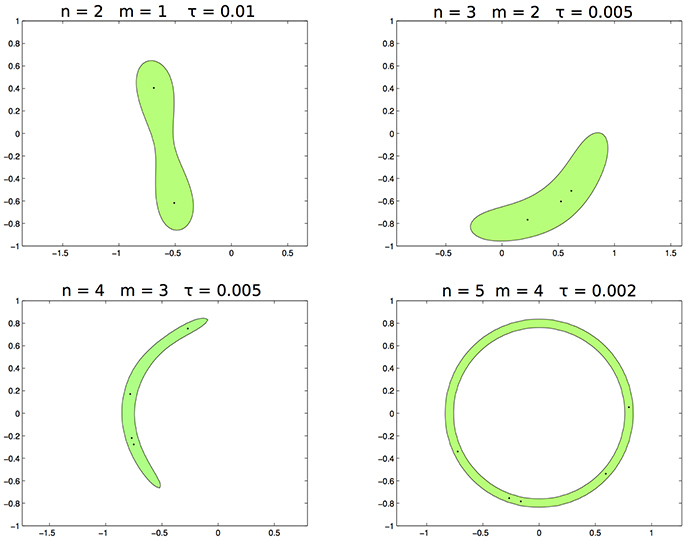
Figure 3. From left to right, top to bottom. The set with n, respectively 2, 3, 4, 5, m = 1, 2, 3, 4 and τ = 0.1, 0.005, 0.005, 0.002.
In the second test the data are sampled from the distribution supported on the curve Lis2,0.11,1,0.3, which is not a conic (see panel right of Figure 2). In Figure 4 we draw the set for n = 10, 20, 50, 100, m = 4, and τ = 0.01. Clearly, is not able to estimate Lis2,0.11,1,0.3.
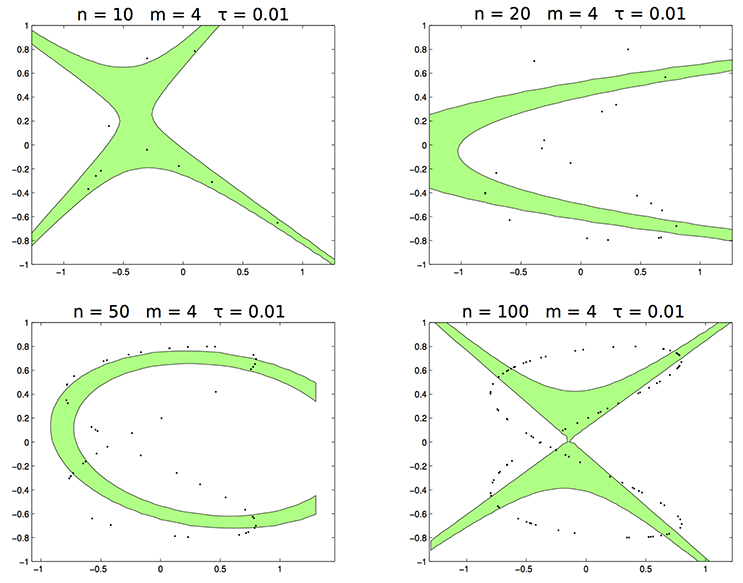
Figure 4. The set with n respectively 10, 20, 50, 100.
In the third test, we use the Abel kernel with the data sampled from the distribution supported on the curve Lis2,0.11,1,0.3 (see panel right of Figure 2). In Figure 5 we show the set for n = 20, 50, 100, 500, m = 5, 20, 30, 50, and τ = 0.4, 0.35, 0.3, 0.2. According the fact that the kernel is separating, is able to estimate Lis2,0.11,1,0.3 correctly.
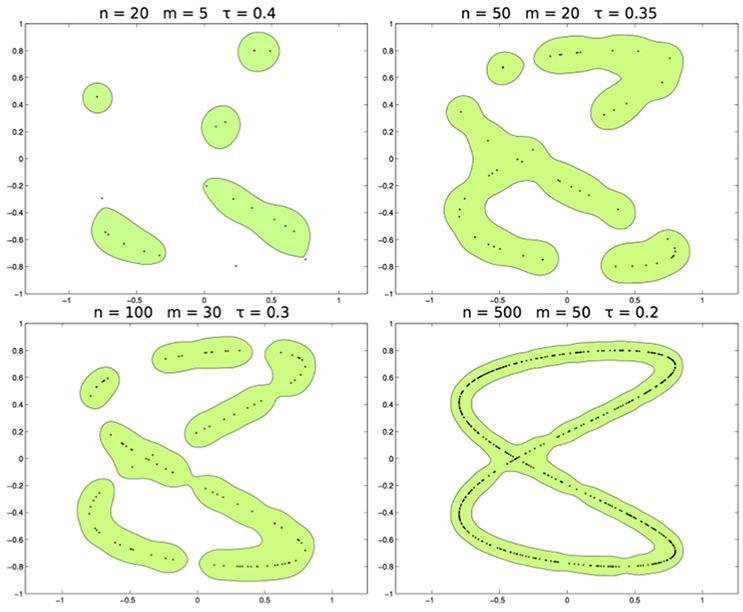
Figure 5. From left to right and top to bottom. The learned set with n respectively of 20, 50, 100, 500, and m = 5, 20, 30, 50, τ = 0.4, 0.35, 0.3, 0.2.
We now briefly discuss how to select the parameter mn and τn from the data. The goal of set-learning problem is to recover the support of the probability distribution generating the data by using the given input observations. Since no output is present, set-learning belongs to the category of unsupervised learning problems, for which there is not a general framework accounting for model selection. However there are some possible strategies (whose analysis is out of the scope of this paper). A first approach, we used in our simulations, is based on the monotonicity properties of with respect to m, τ. More precisely, given f ∈ (0, 1), we select (the smallest) m and (the biggest) τ such that at most nf observed points belong to the the estimated set. It is possible to prove that this method is consistent when f tends to 1 as the number of observations increases. Another way to select the parameters consists in transforming the set-learning problem is a supervised one and then performing standard model selection techniques like cross validation. In particular set-learning can be casted in a classification problem by associating the observed example to the class +1 and by defining an auxiliary measure μ (e.g., uniform on a ball of interest in ) associated to −1, from which n i.i.d. points are drawn. It is possible to prove that this last method is consistent when μ(suppρ) = 0.
We now explain the role of the filter function. Given a training set X1, …, Xn of size n, the separating property (3) applied to the support of the empirical distribution gives that
where is the empirical mean and is the orthogonal projection onto the linear space spanned by the family , which are the centered images of the examples. Hence, given a new point x ∈ D the condition with τ ≪ 1 is satisfied if only if x is close to one of the examples in the training set. Hence the naive estimator overfits the data. Hence we would like to replace with an operator, which should be close to the identity on the linear subspace spanned by and it should have a small range. To modulate the two requests, one can consider the following optimization problem
We note that if A is a projection its Hilbert-Schmidt norm ||A||2 is the square root of the dimension of the range of A. Since
where Tr(A) is the trace, A⊤ is the transpose and is the Hilbert-Schmidt norm, then
and the optimal solution is given by
i.e., Aopt is precisely the operator with the Tikhonov filter and . A different choice of the filter function rm corresponds to a different regularization of the least-square problem
In this section we show that the computation of , in terms of which is defined the estimator , reduces to a finite dimensional problem, depending only on the Mercer kernel K, associated with the feature map. We introduce the centered sampling operator
whose transpose is given by
where vi is the i-th entry of the column vector v ∈ ℝn. Hence, it holds that
where Kn is the n × n matrix whose (i, j)-entry is K(Xi, Xj) and In is the identity n × n matrix, so that the (i, j)-entry of is
Denoted by ℓ the rank of , take the singular value decomposition of , i.e.,
where V is an n × ℓ matrix whose columns are the normalized eigenvectors, , and Σ is a diagonal ℓ × ℓ matrix with the strictly positive eigenvalues on the diagonal, i.e., . Set , regarded as operator from ℝℓ to , then a simple calculation shows that
where rm(Σ) is the diagonal ℓ × ℓ matrix
and the equation for holds true since by assumption rm(0) = 0. Hence
where the real number is
the i-th entry of the column vector v(x) ∈ ℝn is
the diagonal ℓ × ℓ matrix is
and the n × n-matrix Gm is
In Algorithm 1 we list the corresponding MatLab Code.

Algorithm 1. Matlab code for Set Learning.
The above equations make clear that both and can be computed in terms of the singular value decomposition (V, Σ) of the n × n Gram matrix Kn and of the filter function rm, so that belongs to the class of kernel methods and is a plug-in estimator. For the hard cut-off filter, one simply has
For real applications, a delicate issue is the choice of the parameters m and τ, we refer to Rudi et al. [31] for a detailed discussion. Here, we add some simple remarks.
We first discuss the role of τ. According to (10), whenever τ < τ′. We exemplify this behavior with the dataset of Example 2. The training set is sampled from the distribution supported on the curve Lis2,0.11,1,0.3 (see panel right of Figure 2) and we compute with the Abel kernel, n = 100 and m ranging over 5, 10, 20, 50. Figure 6 shows the nested sets when τ runs in the associated color-bar.
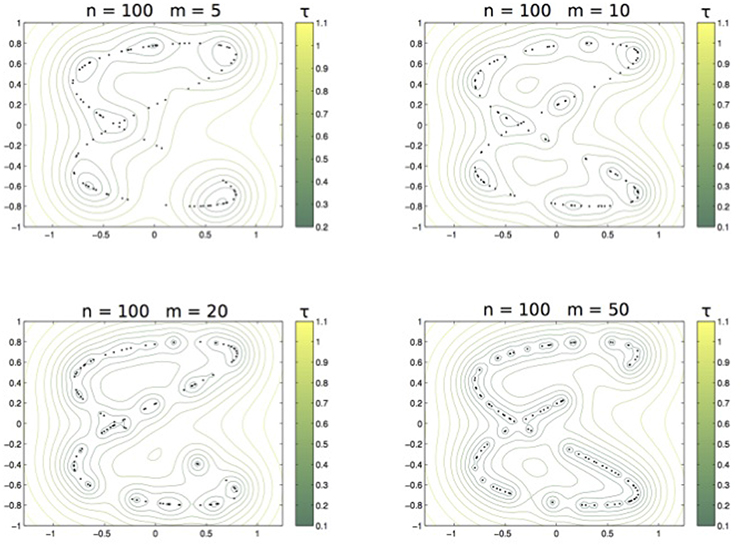
Figure 6. From left to right and top to bottom: The family of sets ,,, with τ varying as in the related colorbar.
Analyzing the role of m, we now show that, for the the hard cut-off filter, whenever m′ ≤ m. Indeed, this filter satisfies and, since 0 ≤ rm(σ) ≤ 1, one has . Hence, denoted by a base of eigenvectors of , it holds that
Hence, for any point in ,
so that .
As above, we illustrate the different choices of m with the data sampled from the curve Lis2,0.11,1,0.3 and the Abel kernel where n = 100 and τ ranges over 0.25, 0.3, 0.4, 0.5. Figure 7 shows the nested sets when m runs in the associated color-bar.
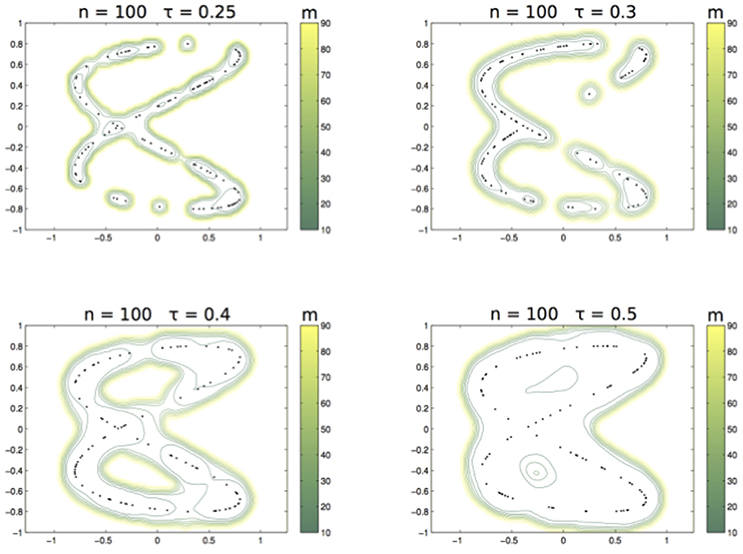
Figure 7. From left to right and top to bottom: The family of sets ,,, with m varying as in the related colorbar.
We presented a new class of set estimators, which are able to learn the support of an unknown probability distribution from a training set of random data. The set estimator is defined through a decision function, which can be seen as a novelty/anomality detection algorithm as in Schölkopf et al. [6].
The decision function we defined is a kernel machine. It is computed by the singular value decomposition of the empirical (kernel)-covariance matrix and by a low pass filter. An example of filter is the hard cut-off function and the corresponding decision function reduces to KPCA algorithm for novelty detection first introduced by Hoffmann [16]. However, we showed that it is possible to choose other low pass filters, as it was done for a class of supervised algorithms in the regression/classification setting [38].
Under some weak assumptions on the low pass filter, we proved that the corresponding set estimator is strongly consistent with respect to the Hausdorff distance, provided that the kernel satisfies a suitable separating condition, as it happens, for example, for the Abel kernel. Furthermore, by comparing Theorem 2 with a similar consistency result in De Vito et al. [27], it appears clear that the algorithm correctly learns the support both if the data have zero mean, as in our paper, and if the data are not centered, as in De Vito et al. [27]. On the contrary, if the separating property does not hold, the algorithm learns only the supports that are mapped into linear subspaces by the feature map defined by the kernel.
The set estimator we introduced depends on two parameters: the effective number m of eigenvectors defining the decision function and the thickness τ of the region estimating the support. The role of these parameters and of the separating property was briefly discussed by a few tests on toy data.
We finally observe that our class of set learning algorithms is very similar to classical kernel machines in supervised learning. So, in order to reduce both the computational cost and the memory requirements, there is the possibility to successfully implement some new advanced approximation techniques, for which there exist theoretical guarantees for the statistical learning setting. For example random features [39, 40], Nyström projections [41, 42] or mixed approaches with iterative regularization and preconditioning [43, 44].
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
ED is member of the Gruppo Nazionale per l'Analisi Matematica, la Probabilità e le loro Applicazioni (GNAMPA) of the Istituto Nazionale di Alta Matematica (INdAM).
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2017.00023/full#supplementary-material
1. ^Here, the labeling is different from the one in (6), where the eigenvalues are repeated according to their multiplicity.
1. Devroye L, Wise GL. Detection of abnormal behavior via nonparametric estimation of the support. SIAM J Appl Math. (1980) 38:480–8. doi: 10.1137/0138038
2. Korostelëv AP, Tsybakov AB. Minimax Theory of Image Reconstruction. New York, NY: Springer-Verlag (1993).
3. Dümbgen L, Walther G. Rates of convergence for random approximations of convex sets. Adv Appl Probab. (1996) 28:384–93. doi: 10.2307/1428063
4. Cuevas A, Fraiman R. A plug-in approach to support estimation. Ann Stat. (1997) 25:2300–12. doi: 10.1214/aos/1030741073
5. Tsybakov AB. On nonparametric estimation of density level sets. Ann Stat. (1997) 25:948–69. doi: 10.1214/aos/1069362732
6. Schölkopf B, Platt J, Shawe-Taylor J, Smola A, Williamson R. Estimating the support of a high-dimensional distribution. Neural Comput. (2001) 13:1443–71. doi: 10.1162/089976601750264965
7. Cuevas A, Rodríguez-Casal A. Set estimation: an overview and some recent developments. In: Recent Advances and Trends in Nonparametric Statistics. Elsevier: Amsterdam (2003). p. 251–64.
8. Reitzner M. Random polytopes and the Efron-Stein jackknife inequality. Ann Probab. (2003) 31:2136–66. doi: 10.1214/aop/1068646381
9. Steinwart I, Hush D, Scovel C. A classification framework for anomaly detection. J Mach Learn Res. (2005) 6:211–32.
10. Vert R, Vert JP. Consistency and convergence rates of one-class SVMs and related algorithms. J Mach Learn Res. (2006) 7:817–54.
12. Biau G, Cadre B, Mason D, Pelletier B. Asymptotic normality in density support estimation. Electron J Probab. (2009) 91:2617–35.
13. Cuevas A, Fraiman R. Set estimation. In: W. Kendall and I. Molchanov, editors. New Perspectives in Stochastic Geometry. Oxford: Oxford University Press (2010). p. 374–97.
14. Bobrowski O, Mukherjee S, Taylor JE. Topological consistency via kernel estimation. Bernoulli (2017) 23:288–328. doi: 10.3150/15-BEJ744
15. Campos GO, Zimek A, Sander J, Campello RJ, Micenková B, Schubert E, et al. On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study. Data Min Knowl Discov. (2016) 30:891–927. doi: 10.1007/s10618-015-0444-8
16. Hoffmann H. Kernel PCA for novelty detection. Pattern Recognit. (2007) 40:863–74. doi: 10.1016/j.patcog.2006.07.009
17. Schölkopf B, Smola A, Müller KR. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. (1998) 10:1299–319.
18. Ristic B, La Scala B, Morelande M, Gordon N. Statistical analysis of motion patterns in AIS data: anomaly detection and motion prediction. In: 2008 11th International Conference on Information Fusion (2008). p. 1–7.
19. Lee HJ, Cho S, Shin MS. Supporting diagnosis of attention-deficit hyperactive disorder with novelty detection. Artif Intell Med. (2008) 42:199–212. doi: 10.1016/j.artmed.2007.11.001
20. Valero-Cuevas FJ, Hoffmann H, Kurse MU, Kutch JJ, Theodorou EA. Computational models for neuromuscular function. IEEE Rev Biomed Eng. (2009) 2:110–35. doi: 10.1109/RBME.2009.2034981
21. He F, Yang JH, Li M, Xu JW. Research on nonlinear process monitoring and fault diagnosis based on kernel principal component analysis. Key Eng Mater. (2009) 413:583–90. doi: 10.4028/www.scientific.net/KEM.413-414.583
22. Maestri ML, Cassanello MC, Horowitz GI. Kernel PCA performance in processes with multiple operation modes. Chem Prod Process Model. (2009) 4:1934–2659. doi: 10.2202/1934-2659.1383
23. Cheng P, Li W, Ogunbona P. Kernel PCA of HOG features for posture detection. In: VCNZ'09. 24th International Conference on Image and Vision Computing New Zealand, 2009. Wellington (2009). p. 415–20.
24. Sofman B, Bagnell JA, Stentz A. Anytime online novelty detection for vehicle safeguarding. In: 2010 IEEE International Conference on Robotics and Automation (ICRA). Pittsburgh, PA (2010). p. 1247–54.
25. De Vito E, Rosasco L, Toigo A. A universally consistent spectral estimator for the support of a distribution. Appl Comput Harmonic Anal. (2014) 37:185–217. doi: 10.1016/j.acha.2013.11.003
26. Steinwart I. On the influence of the kernel on the consistency of support vector machines. J Mach Learn Res. (2002) 2:67–93. doi: 10.1162/153244302760185252
27. De Vito E, Rosasco L, Toigo A. Spectral regularization for support estimation. In: NIPS. Vancouver, BC (2010). p. 1–9.
28. Engl HW, Hanke M, Neubauer A. Regularization of Inverse Problems. Vol. 375 of Mathematics and its Applications. Dordrecht: Kluwer Academic Publishers Group (1996).
29. Lo Gerfo L, Rosasco L, Odone F, De Vito E, Verri A. Spectral algorithms for supervised learning. Neural Comput. (2008) 20:1873–97. doi: 10.1162/neco.2008.05-07-517
30. Blanchard G, Mücke N. Optimal rates for regularization of statistical inverse learning problems. In: Foundations of Computational Mathematics. (2017). Available online at: https://arxiv.org/abs/1604.04054
31. Rudi A, Odone, F, De Vito E. Geometrical and computational aspects of Spectral Support Estimation for novelty detection. Pattern Recognit Lett. (2014) 36:107–16. doi: 10.1016/j.patrec.2013.09.025
32. Rudi A, Canas, GD, Rosasco L. On the sample complexity of subspace learning. In: Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KQ, editors. Advances in Neural Information Processing Systems. Lake Tahoe: Neural Information Processing Systems Conference (2013). p. 2067–75.
33. Rudi A, Canas GD, De Vito E, Rosasco L. Learning Sets and Subspaces. In: Suykens JAK, Signoretto M, and Argyriou A, editors. Regularization, Optimization, Kernels, and Support Vector Machines. Boca Raton, FL: Chapman and Hall/CRC (2014). p. 337.
34. Blanchard G, Bousquet O, Zwald L. Statistical properties of kernel principal component analysis. Machine Learn. (2007) 66:259–94. doi: 10.1007/s10994-006-8886-2
35. Györfi L, Kohler M, Krzy zak A, Walk H. A Distribution-Free Theory of Nonparametric Regression. Springer Series in Statistics. New York, NY: Springer-Verlag (2002).
36. Steinwart I, Christmann A. Support Vector Machines. Information Science and Statistics. New York, NY: Springer (2008).
37. Zwald L, Blanchard G. On the Convergence of eigenspaces in kernel principal component analysis. In: Weiss Y, Schölkopf B, Platt J, editors. Advances in Neural Information Processing Systems 18. Cambridge, MA: MIT Press (2006). p. 1649–56.
38. De Vito E, Rosasco L, Caponnetto A, De Giovannini U, Odone F. Learning from examples as an inverse problem. J Machine Learn Res. (2005) 6:883–904.
39. Rahimi A, Recht B. Random features for large-scale kernel machines. In: Koller D, Schuurmans D, Bengio, Y, Bottou L, editors. Advances in Neural Information Processing Systems. Vancouver, BC: Neural Information Processing Systems Conference (2008). p. 1177–84.
40. Rudi A, Camoriano R, Rosasco L. Generalization properties of learning with random features. arXiv preprint arXiv:160204474 (2016).
41. Smola AJ, Schölkopf B. Sparse greedy matrix approximation for machine learning. In: Proceeding ICML '00 Proceedings of the Seventeenth International Conference on Machine Learning. Stanford, CA: Morgan Kaufmann (2000). p. 911–18.
42. Rudi A, Camoriano R, Rosasco L. Less is more: nyström computational regularization. In: Cortes C, Lawrence ND, Lee DD, Sugiyama M, Garnett R, editors. Advances in Neural Information Processing Systems. Montreal, QC: Neural Information Processing Systems Conference (2015). p. 1657–1665.
43. Camoriano R, Angles T, Rudi A, Rosasco L. NYTRO: when subsampling meets early stopping. In: Gretton A, Robert CC, editors. Artificial Intelligence and Statistics. Cadiz: Proceedings of Machine Learning Research (2016). p. 1403–11.
44. Rudi A, Carratino L, Rosasco L. FALKON: an optimal large scale Kernel method. arXiv preprint arXiv:170510958 (2017).
45. Folland G. A Course in Abstract Harmonic Analysis. Studies in Advanced Mathematics. Boca Raton, FL: CRC Press (1995).
46. Birman MS, Solomyak M. Double operator integrals in a Hilbert space. Integr Equat Oper Theor. (2003) 47:131–68. doi: 10.1007/s00020-003-1157-8
Keywords: support estimation, Kernel PCA, novelty detection, dimensionality reduction, regularized Kernel methods
Citation: Rudi A, De Vito E, Verri A and Odone F (2017) Regularized Kernel Algorithms for Support Estimation. Front. Appl. Math. Stat. 3:23. doi: 10.3389/fams.2017.00023
Received: 11 August 2017; Accepted: 25 October 2017;
Published: 08 November 2017.
Edited by:
Ding-Xuan Zhou, City University of Hong Kong, Hong KongReviewed by:
Ting Hu, Wuhan University, ChinaCopyright © 2017 Rudi, De Vito, Verri and Odone. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ernesto De Vito, ZGV2aXRvQGRpbWEudW5pZ2UuaXQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.