 Paolo Castiglioni
Paolo Castiglioni Andrea Faini
Andrea Faini- 1IRCCS Fondazione Don Carlo Gnocchi, Milan, Italy
- 2Department of Cardiovascular Neural and Metabolic Sciences, Istituto Auxologico Italiano, IRCCS, S.Luca Hospital, Milan, Italy
Detrended fluctuation analysis (DFA) is a popular tool in physiological and medical studies for estimating the self-similarity coefficient, α, of time series. Recent researches extended its use for evaluating multifractality (where α is a function of the multifractal parameter q) at different scales n. In this way, the multifractal-multiscale DFA provides a bidimensional surface α(q,n) to quantify the level of multifractality at each scale separately. We recently showed that scale resolution and estimation variability of α(q,n) can be improved at each scale n by splitting the series into maximally overlapped blocks. This, however, increases the computational load making DFA estimations unfeasible in most applications. Our aim is to provide a DFA algorithm sufficiently fast to evaluate the multifractal DFA with maximally overlapped blocks even on long time series, as usually recorded in physiological or clinical settings, therefore improving the quality of the α(q,n) estimate. For this aim, we revise the analytic formulas for multifractal DFA with first- and second-order detrending polynomials (i.e., DFA1 and DFA2) and propose a faster algorithm than the currently available codes. Applying it on synthesized fractal/multifractal series we demonstrate its numerical stability and a computational time about 1% that required by traditional codes. Analyzing long physiological signals (heart-rate tachograms from a 24-h Holter recording and electroencephalographic traces from a sleep study), we illustrate its capability to provide high-resolution α(q,n) surfaces that better describe the multifractal/multiscale properties of time series in physiology. The proposed fast algorithm might, therefore, make it easier deriving richer information on the complex dynamics of clinical signals, possibly improving risk stratification or the assessment of medical interventions and rehabilitation protocols.
Introduction
In the mid of the 90s, the algorithm of detrended fluctuation analysis (DFA) gave a great boost to the study of fractal physiology providing an easy-to-calculate method for evaluating the Hurst's exponent of physiological times series (Castiglioni et al., 2017). DFA estimates the slope α of the log-log plot of a fluctuations function, F(n), over a range of time scales n. The fluctuations function is the root mean square, or second-order moment, of the deviations of blocks of n data from a polynomial trend. Due to the intrinsic variability of the F(n) estimate, α is calculated as the slope of the least-square regression line fitting log F(n) on log n.
DFA became quickly popular in the field of heart rate variability analysis and since its first applications the F(n) of heart rate was described by two slopes, one at the shorter (n < 16) and one at the longer scales (Peng et al., 1995). Then, similar multi-slope approaches were proposed for electroencephalogram (EEG) recordings (Hwa and Ferree, 2002; Jospin et al., 2007). The idea that α may change with the scale n and that the resulting α(n) profile may provide information on physiological or pathophysiological mechanisms was further investigated by different groups in the following years. Continuous α(n) profiles from noisy F(n) estimates were obtained by applying a simplified Kalman filter whose coefficients, however, were defined empirically, making the procedure somehow arbitrary (Echeverria et al., 2003). Other authors extended the two-slope approach fitting the regression line over a short running window (Gieraltowski et al., 2012; Xia et al., 2013): in this way a continuous α(n) profile was obtained as the central point of the window, n, moved from the shortest to the longest scale. The running-window approach was also applied to study multifractality. Multifractal series are composed by interwoven fractal processes and the multifractal DFA approach extends the calculation of the second-order fluctuations function to a range of positive and negative moments that includes q = 2 (the second-order moment): in fact, positive q moments amplify the contribution of fractal components with larger amplitude and negative q moments the contribution of fractal components with smaller amplitude (Kantelhardt et al., 2002). This led to the calculation of the local slope of the qth-order fluctuation function, α(q,n), as the slope of the regression lines fitting Fq(n) over a running window at each q separately (Gieraltowski et al., 2012). It should be considered that the scale resolution achievable with the regression line method is limited because the window width cannot be too short to make α insensitive to the estimation variability.
A third approach is based on estimating the slope as the first derivative of log F(n) (Castiglioni et al., 2009, 2011a). Assuring higher α(n) resolution, it allows obtaining a more detailed description of the deviations of log F(n) from the straight line, which resulted useful for describing the autonomic integrative control (Castiglioni et al., 2011a) and its alterations (Castiglioni and Merati, 2017). However, this approach requires minimizing the variability of the F(n) estimator because of its sensitivity to noise. Traditional DFA estimators calculate F(n) splitting the series into consecutive non-overlapped blocks. If the series is split into maximally overlapped blocks, which means that consecutive blocks of size n have n-1 samples in common, the variability of the F(n) estimator decreases substantially, allowing the evaluation of the slope as the first derivative (Castiglioni et al., 2018). A drawback of this approach is the much higher computational load that may make unfeasible the analysis of long series of data, as often occur in heart-rate variability or EEG studies. The computational load is even greater for calculating Fq(n) and the multifractal-multiscale spectrum, α(q,n).
Strictly related to the determination of the local slope of Fq(n) is the identification of number and position of crossover scales where the fractal properties change. Crossovers may be due to interferences affecting the measures (Ludescher et al., 2011) or may reflect specific aspects of the physiological system generating the series, like short-range correlations (Höll and Kantz, 2015). Statistical models for identifying crossover points in Fq(n) are based on fitting piecewise regressions and on iterative hypothesis testing (Ge and Leung, 2013). Other approaches identify the scales where the Fq(n) curves change their slope by introducing the focus-based multifractal formalism (Mukli et al., 2015): accordingly, if one assumes a bimodal scale dynamics, the multifractal fluctuations function is directly modeled by one or two fan-like structures in which log-log straight lines, each corresponding to an order q, may converge to a focus at the largest scale. Multifractal crossovers are then decomposed by an iterative process that minimizes the residual errors of least-square fittings (Nagy et al., 2017; Mukli et al., 2018). Clearly, the estimation variability of the Fq(n) curves negatively affects the identification of the focuses and decreases the overall statistical power of these methods. Therefore, also these methods can take advantage of the use of maximally overlapped blocks for improving the Fq(n) estimates and for better modeling the multifractal dynamics.
The examples of Figure 1 illustrate the reduction of estimation variability and the related computational costs when using maximum overlapping. In the example of a first-order autoregressive process generated by white Gaussian noise (Figure 1, Upper), the variability of the Fq(n) estimate without overlapping might suggest the presence of a focus at the larger scales. A focus should not be present, because at scales larger than the cut-off frequency the dynamics is determined by white noise. Actually, when the Fq(n) curves are estimated with maximally overlapped blocks, they run in parallel (see inset) with slope α close to 0.5 at the largest scale. In the example of a random series with multifractal Cauchy distribution (Figure 1, Lower), the large variability of the estimate without overlapping makes it difficult to identify the scale where the focus occurs and may completely hide possible crossover points between n = 103 and n = 104 for positive q. These drawbacks are largely mitigated by using maximum overlapping but at the cost of an increased computational load that may lead to unacceptable calculation times for long series.
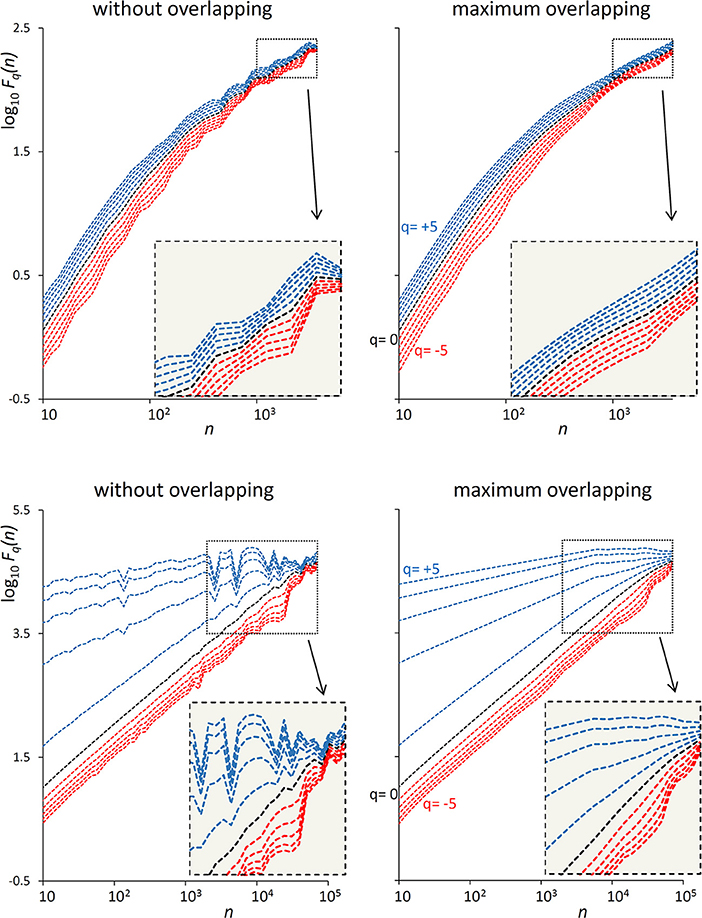
Figure 1. Effect of blocks overlapping on variability and computation time of Fq(n) estimates. (Upper) DFA1 fluctuation functions for an autoregressive series {xi} of N = 16,384 samples generated as xi = axi−1+wni where wni is white Gaussian noise with zero mean and unit variance and a = 0.9391014 as in Kiyono (2015), corresponding to a low-pass filter with cut-off frequency fco = 0.01, or a cross-over scale nco = 100 (Höll and Kantz, 2015); calculation time for estimating Fq(n) over 38 block-sizes n was 4 s without overlapping and 3 min with maximum overlapping on a personal computer. (Lower) DFA1 fluctuation functions for N = 300,000 random samples with Cauchy distribution (location 0, scale 3); calculation time for estimating Fq(n) over 55 block-sizes n was 58 s without overlapping, 5 h and 22 min with maximum overlapping.
To overcome this limit, we designed a fast algorithm for Fq(n) calculation, particularly efficient in case of maximally overlapped blocks. Therefore, the aim of the present work is (1) to describe the theoretical aspects on which we based our fast algorithm; (2) to illustrate its performance by comparison with the traditional DFA algorithm; (3) to show potential applications in the fields of heart rate variability analysis and of EEG signals analysis; and (4) to provide the source code for its implementation. The algorithm optimizes the computation time of Fq(n) and readers can then estimate α(q,n) with any of the methods proposed in literature: Kalman filtering, least-square regression over a running window or first derivative of log Fq(n) vs. log n. In this work, we also include the code for slope estimation with the latter method because our fast algorithm was specifically designed for evaluating α(q,n) with the derivative approach.
Fast Fq(n) Calculation
Given a time series of N samples, Sj, with j = 1, … N, mean μS and standard deviation σS, the mean is removed and the series normalized to unit standard deviation:
The normalization in Equation (1), not required by DFA, is useful for recognizing data blocks with very low dynamics (see section Calculation precision and small blocks overfitting). The cumulative sum yi, with i = 1,… N, is:
To evaluate Fq, the yi series is split into consecutive blocks of size n. At a given scale n, the number of blocks, M, depends on the length of the series N, on the block size n and on the number of overlapped samples between consecutive blocks, L, with 0 ≤ L<n, as:
If N-n is not multiple of n-L, a short segment of N-(M-1)(n-L)-n samples at the end of the series are excluded from the analysis. In the case of maximum overlapping, when L = n-1, all the N samples contribute to the estimation of Fq(n) and the number of blocks reaches the highest value: M = N-n + 1. Each of the M blocks is detrended by least-square fitting a polynomial p(i). The usual notation to indicate a DFA employing a polynomial of order O is DFAO. The variance of the residuals in the k-th detrended block is
with Ik = (n-L)×(k-1)+1 index of the first sample falling into the k-th block. According to Kantelhardt et al. (2002), the variability functions for DFA multifractal analysis are:
Because of the normalization in Equation (1), the variability function of the original series is Fq(n)×σS.
Most of the computational load for evaluating Fq(n) is due to the calculation of Equation (4a), which requires (1) a least-square polynomial fitting and (2) the evaluation of the variance of the residuals, over n points. These steps should be repeated for each of the M blocks and M reaches very large values, close to N, for maximally overlapped blocks (Equation 3). In the following, we describe how to make these calculation steps faster for detrending polynomials of order 1 or 2, i.e., for DFA1 and DFA2. We did not consider polynomials of a higher order because all the DFA biomedical applications we are aware of did not employ detrending polynomials of order greater than 2. However, the same optimization strategy we present here can be extended to higher orders.
Least Square Polynomial Fitting
Freely available DFA codes, as accessible in Ihlen (2012) or described in Peng et al. (1995) and Gieraltowski et al. (2012) and downloadable in Goldberger et al. (2000), calculate the polynomial p(i) of order O with algorithms for least-square fitting a data-set of n points with coordinates (i,yi). This means solving n linear equations operating with a n×(O+1) Vandermonde matrix. The fitting polynomials of first and second order are:
Coefficients of Equation (6a) are:
with
Coefficients of Equation (6b) are:
with, in addition to Equation (8a–d):
Equations (8a,d) and Equations (10a–c) require summing powers “V” of i, with V an integer between 1 and 4 and i consecutive natural numbers. Remembering the Faulhaber's formula:
where Bi is the i-th Bernoulli's number, is the binomial coefficient, and δiV is the Kroenecker's delta (Weisstein, 1999), we have:
Since
the sum of powers of n consecutive integers does not require the actual summation of n terms and can be obtained through the much faster expressions of Equations (12). However, Equations (8b,c, 10d) include sums of the product between iVyi, with V integer between 0 and 2. There are no analytic expressions for these sums but a fast way to calculate them is to define the arrays Av, w(i), i = 0,…,N, as:
Once the arrays have been initialized, the sum of n consecutive iV products is calculated by the following difference:
Variance of the Residuals
To avoid another summation over n points, let's writing the squared expression in Equation (4a) for the linear fitting (Equation 6a) as:
and for quadratic fitting (Equation 6b) as:
The sums in Equations (16a,b) are obtained analytically with Equations (12a–d, 13), and directly from Equation (15) with V = 0 and W = 1 or 2, and with W = 1 and V = 1 or 2.
Calculation Precision
To avoid subtracting terms with very different magnitude, which may introduce errors due to the finite precision of numbers representation, the starting point of the k-th block, Ik, is shifted to 1 rewriting Equation (4a) as:
The difference in Equation (13) is no more required and Equation (15) is calculated as in Appendix. However, numerical errors may affect Av,w(i) in Equation (14). In fact, the array initialization requires adding the term iV to a running summation AV, W(i-1) which may reach very high values for long series when i is close to N, propagating precision errors from the lower to the higher indices i. To avoid this problem, the running summation is split into a sequence of shorter sums over segments of 128 samples. This is done defining the matrix AV, W(r,c) of 129 rows (0 ≤ r ≤ 128) and Q = ⌊(N-1)/128⌋+1 columns (1 ≤ c ≤ Q), as:
Any index i > 0 corresponds to the column c = ⌊(i-1)/128⌋+1 and to the row r = i-c×128, and AV,W(i) is calculated as
avoiding most of the sums that include terms with very different magnitude.
For extremely long series, even Equation (18) cannot exclude errors due to the finite precision of numbers representation. To control further these errors, the variance of the residuals in Equation (4b) is compared with a threshold. The idea is that when the variance of the residuals is extremely low, the relative weight of errors due to the finite precision of numbers representation might have a detectable influence on the estimate. In this case, the variance is recalculated directly as the summation of the n consecutive powers iV and not through (Equation 15). Because of the normalization in Equation (1), the threshold does not depend on the standard deviation of the time series, but only on its length N, on the precision of number representation and on the detrending order. In our implementation the default value of the DFA1 threshold, Th1, is
and of the DFA2 threshold, Th2, is
A numerical problem of different nature may require comparing the variance of the residuals in Equation (4b) with another threshold EPS, as described in Ihlen (2012). A detrending polynomial of too high order might overfit the blocks of smaller size n, or pre-processing procedures, as low-pass filtering, might remove fractal components at the shortest scales. In these cases, the variance of the residuals could be so low to severely distort log Fq(n) at negative q. The solution proposed in Ihlen (2012) is to discard variances lower than an EPS threshold set “to the precision of the measurement device that is recording the biomedical time series.” Since we normalized the series to unit variance, our approach is to set EPS as a fraction of the dynamics of the original series (for instance, EPS = 10−4).
Algorithm Performance
To assess numerical stability and speed of our algorithm (see Matlab source code in the Supplemental File FMFDFA.m), we applied it to synthesized time series. We synthesized three series of N = 106 samples: a white Gaussian noise with zero mean and unit variance, {wni}; a Brownian motion as the integral of a zero-mean white noise with variance = 0.01986918, {Bmi}; and the series {wbi} obtained as their superposition, i.e.,:
As indicated in Kiyono (2015), the power spectrum of {wbi} has a crossover frequency separating the spectral profiles of white and brown noises at fco = 10−2.5, corresponding to a crossover scale nco = 316 samples. Figure 2 shows an example of DFA1 and DFA2 estimates on N = 200,000 samples of {wbi} (we analyze EEG series of the same length in the next paragraph “Application on real biomedical time series”).
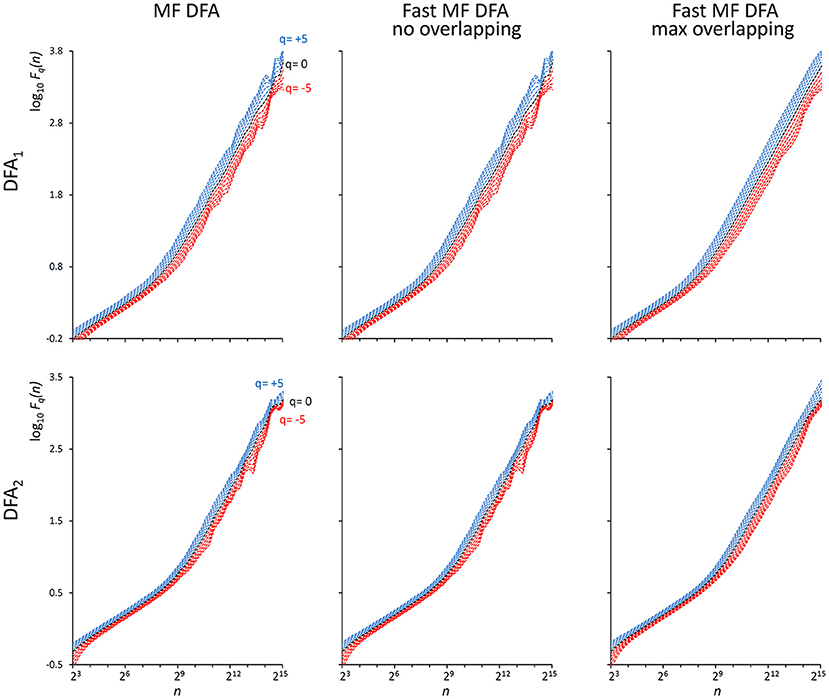
Figure 2. Fq(n) functions by the traditional (MF DFA) and the proposed fast algorithm (Fast MF DFA) for the {wbi} series. The series of N = 200,000 samples is the superposition of white noise and Brownian motion (see text); estimates without overlapping by the traditional algorithm (Left) and by our fast algorithm (Center) and with maximum overlapping by our fast algorithm (Right) were performed over 56 block sizes exponentially distributed over the n axis, with thresholds Th1 and Th2 as in Equations (19) and EPS = 0. On a laptop computer, the traditional algorithm employed T = 57 s for calculating DFA1 and T = 146 s for calculating DFA2 without overlapping, the fast algorithm employed 2.2 s without overlapping and 65 s with maximum overlapping for calculating both the DFA1 and DFA2 estimates simultaneously.
To evaluate how the finite precision of number representation may affect the sum of n consecutive products when obtained by Equation (15), we extracted segments of length N = 10k+1, with k integer between 1 and 5, from the three synthesized series. For each segment, we estimated Fq(n) for all integers q between −5 and +5 and for scales nb = 10b with b an integer between 1 and k-1 (e.g., for a segment of length N4 = 10,000 samples we considered the scales n1 = 10, n2 = 100 and n3 = 1,000 samples). Estimates were performed with the fast algorithm with maximally overlapped blocks, setting Th1 and Th2 as in Equations (19) and EPS = 0. These “fast” estimates were compared with estimates from a reference algorithm in which the difference on the right side of Equation (15) is replaced by the slower but more precise summation of n products on the left side of the equation. The relative error between the fast estimate, Fq(nb)F, and the reference estimate, Fq(nb)R, was computed for each q and each block size nb as:
The largest of these errors among all the nb block sizes, among all the q values and among the three series ({wbi}, {wni} and {Bmi}) was taken as a global measure of the precision of the fast algorithm for any given length Nk. Relative errors are reported in Table 1: even in the worst case (corresponding to the length N = 106 samples), the highest relative error is less than 1%.
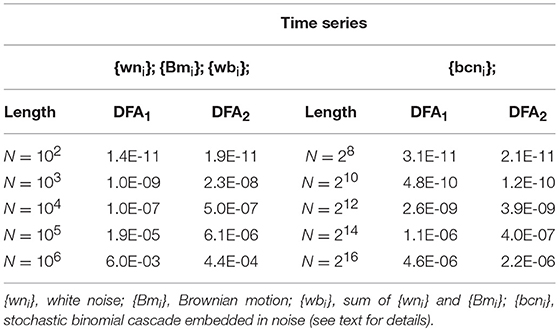
Table 1. Largest relative error in Fq(n) estimates induced by calculating the sum of n products with the fast Equation (15).
We also generated a stochastic binomial cascade embedded in noise, {bcni}, with a procedure similar to that described in Gieraltowski et al. (2012). We started from a series of N = 214 samples equal to 1, we split it into two segments of the same length, and multiplied one segment by the weight 0.25 and one by the weight (1-0.25), randomly selecting the weights of the first and second segment. We repeated the splitting/weighting procedure for each segment of the previous step, up to 14 steps. To include random noise, we substituted all values lower than 10−6 with random samples uniformly distributed between 0 and 0.01. From this cascade, we subtracted its reversed duplicate to obtain a symmetric distribution. Figure 3 shows examples of F(n) estimates for the {bcni} series (we analyzed heart-rate series of similar length in the paragraph “Application on real biomedical time series”). We generated and concatenated four of these binomial cascades to obtain a series of length N = 216. Relative errors were assessed from fast, Fq(nb)F, and reference, Fq(nb)R, estimates (calculated with maximally overlapped blocks, thresholds as in Equation 19 and EPS = 0) for segments of length Nk = 22k+6 with 1 ≤ k ≤ 5, and block sizes nb = 22b+1 with 1 ≤ b ≤ k (e.g., for the length N4 = 16,384 we considered the scales n1 = 16, n2 = 64, n3 = 256 and n4 = 1,024). Results in Table 1 show negligible errors also for this multifractal series.
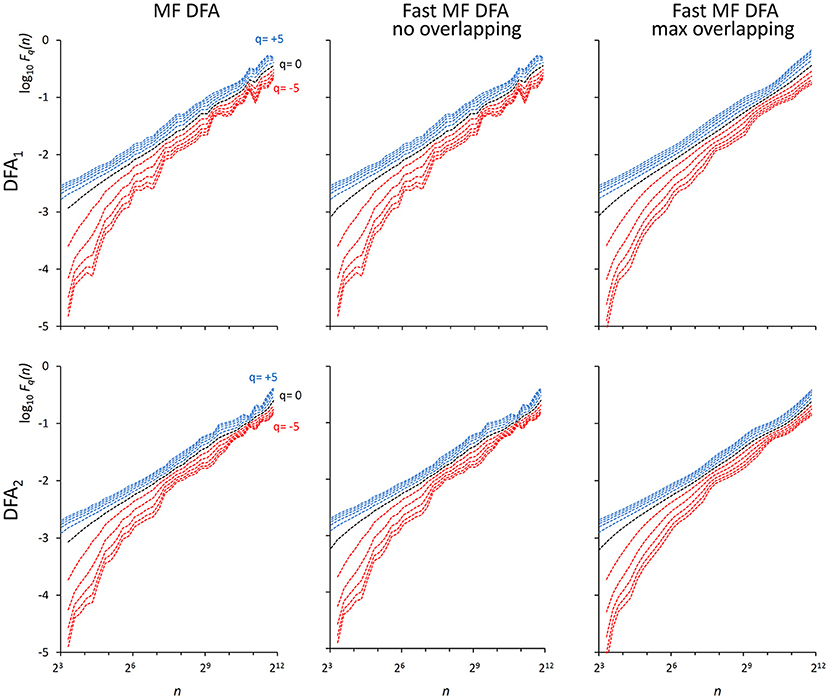
Figure 3. Fq(n) functions for a multifractal binomial cascade embedded in noise of N = 65,536 samples. Estimates without overlapping by the traditional (Left) and fast (Center) algorithm and with maximum overlapping by the fast algorithm (Right) were performed over 38 block sizes, with thresholds as in Equations (19) and EPS = 0. On a laptop computer, the traditional algorithm employed T = 4.3 s for DFA1 and T = 9.5 s for DFA2 without overlapping while the fast algorithm employed 0.12 s without overlapping and 3.6 s with maximum overlapping for calculating DFA1 and DFA2 estimates simultaneously.
We compared the calculation times employed by the traditional and the fast MF DFA algorithm to analyze {wbi} series of length Nk = 10k+1 and binomial cascade series of length Nk = 22k+6, with 1 ≤ k ≤ 5. Results in Figure 4 indicate that the fast algorithm is about two orders of magnitude faster than the traditional one.
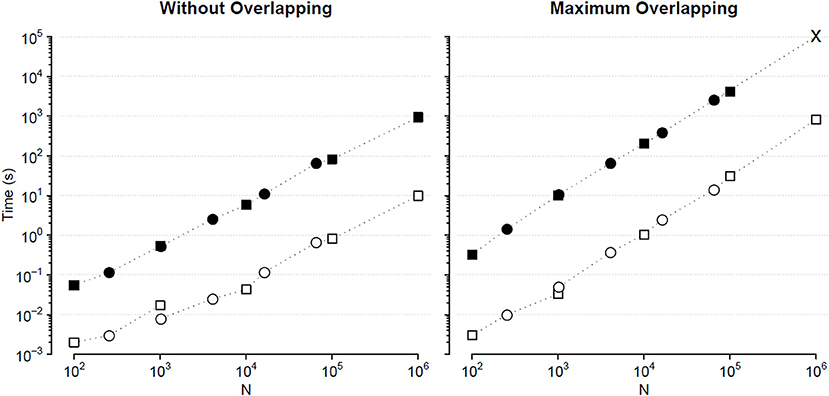
Figure 4. Comparison of Fq(n) calculation times (sum of DFA1 and DFA2) for series of length N. Times for analyzing {wbi} (square) and binomial cascade (circle) series (see text) by traditional (solid symbols) and fast MF DFA algorithm (open symbols): average of 10 runs on a personal computer with Intel i7-7600U CPU at 2.80 GHz, 16 GB RAM and Samsung MZVLW1T0HMLH-000L7 hard disk. As the series length, N, increases, the number of block sizes, n, also increases remaining constant the block-size density of four n values per decade. The calculation time of the traditional algorithm for maximum overlapping and N = 106 has been extrapolated (cross symbol).
Local Slopes of Fq(n)
Once that Fq(n) has been estimated with maximally overlapped blocks, the multifractal DFA coefficients α(q,n) may be obtained as the first derivative of log Fq(n) vs. log n. To have equispaced log n values we interpolate the log Fq(n) samples by a spline function, obtaining H values Fq(nh) with nh real numbers spaced exponentially on the scale axis. The slope at nh is the derivative formula on 5 points (Castiglioni et al., 2018):
or on 3 points at the extremes of the scale axis:
The code for calculating Equations (22) is available as the Supplemental Matlab File slpMFMSDFA.m.
Combining Information From DFA1 and DFA2
Our algorithm provides both DFA1 and DFA2 estimates in a single run. In some cases, there are reasons to prefer one of the two estimates. For instance, DFA1 may identify the scale where possible crossovers occur better than DFA2 (Höll and Kantz, 2015; Kiyono, 2015); however, if the power spectrum of the time series depends on the frequency f proportionally to 1/f β, then DFA2 estimates the correct α up to β < 5, while DFA1 can estimate it only up to β < 3 (Kiyono, 2015). Furthermore, it is possible that the nature of the physiological system under analysis may make preferable one of the two detrending orders. For instance, in the field of heart-rate variability analysis, some studies highlighted that the slope α at q = 2 reflects the sympatho/vagal balance over scales shorter than 11 beats and allows stratifying the cardiovascular risk (Perkiomaki, 2011). Since high-order detrending polynomials overfit the shortest blocks (Kantelhardt et al., 2001), most of the clinical studies estimated this index by DFA1, and a first-order detrending should be used to get an autonomic index comparable with the medical literature. On the other hand, a crossover at the larger heart-rate scales was found for DFA1 but not for DFA2 during light sleep, suggesting that in this sleep phase DFA2 can better remove long-term trends (Bunde et al., 2000). This would make DFA2 preferable to DFA1 when comparing heart rate variability by phases of sleep over the larger scales.
These examples suggest that the best detrending order may differ if the focus of the analysis is on the shorter rather than on the larger scales. For a multifractal series, it is even possible that the best detrending order may depend also on q because components with different amplitude may have different fractal structures. Therefore, it is conceivable that the assessment of α(q,n) could be improved by properly combining the results of DFA1 and DFA2 at each scale. To investigate this possibility, we considered 10 white-noise and 10 Brownian-motion series, each of N = 200,000 samples. Often the fractal dynamics of physiological time series is described as belonging to the family of fractional Gaussian noises and fractional Brownian motions (Eke et al., 2000), and the behavior at the extremes of this family of random processes (i.e., white noise and Brownian motion) may be assumed to represent a large class of physiological series. Then we calculated α(q,n) by DFA1 and by DFA2 with q = −5, q = 0, and q = +5, for each series. Figure 5 illustrates the deviations of the scale exponents from the theoretical value showing mean and standard deviation of the estimates separately over the groups of white noise and Brownian motion. The figure shows that at the shorter scales the estimation bias is greater for DFA2 while, at the larger scales, DFA2 appears more stable than DFA1 for q = −5, less stable than DFA1 for q = +5 and of quality similar to DFA1 for q = 0.
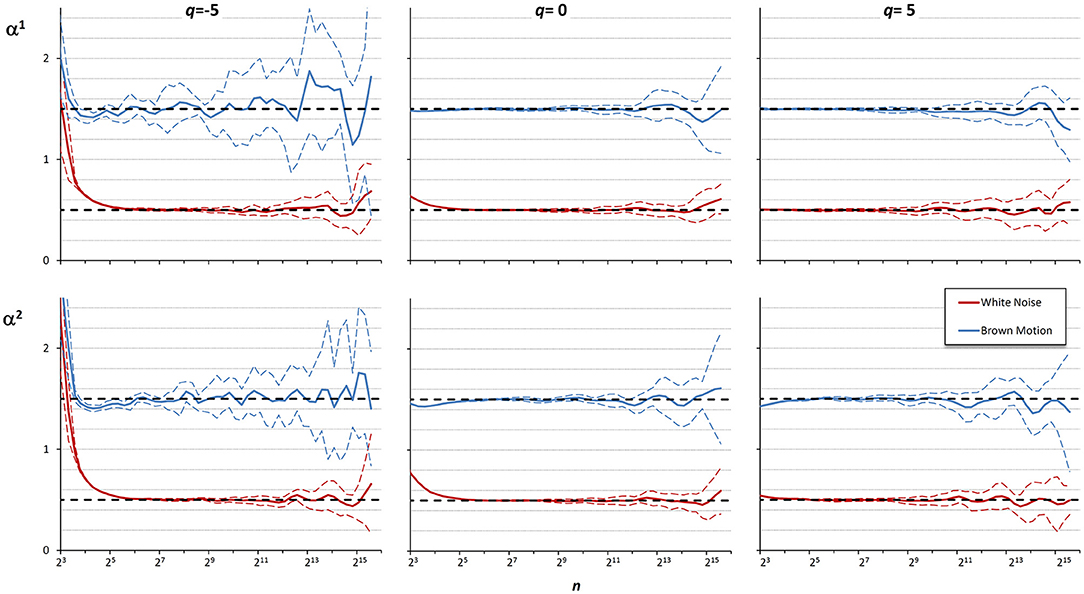
Figure 5. Multifractal multiscale coefficients by DFA1, α1, and by DFA2, α2. Values as derivative of log Fq(n) vs. log n with maximally overlapped blocks: mean ± SD for 10 white noises and 10 Brownian motions. Dashed horizontal lines represent the theoretical value for white noise (=0.5) or Brownian motion (=1.5).
These findings suggest that if the time series is composed by fractional Gaussian noises and/or fractional Brownian motions, DFA1 is preferable to DFA2 at the shorter scales, while at the larger scales the choice may depend on the sign of q, and if q = 0 averaging the DFA1 and DFA2 coefficients might improve the estimate. Accordingly, we combined the estimates by DFA1, α1(q,n), and by DFA2, α2(q,n), defining a weighted average, αw(q,n), when q = −5, as:
when q = 0, as:
and when q = +5, as:
Figure 6 shows the αw coefficients derived from α1 and α2 of Figure 5.
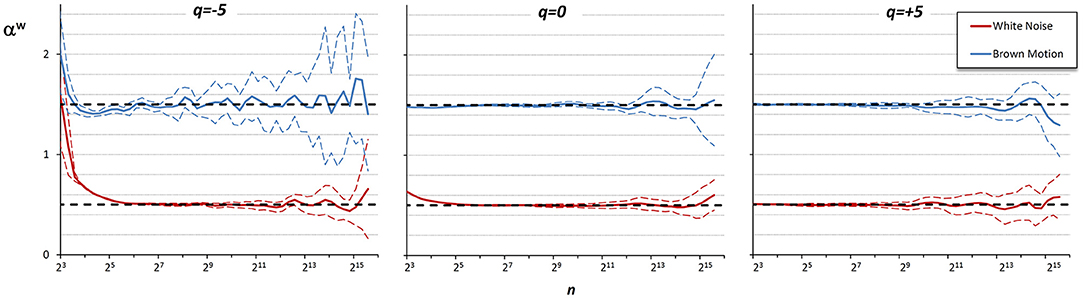
Figure 6. Multifractal Multiscale coefficients by combining DFA1 and DFA2. Weights defined by Equations (23a–c).
Values of αw for q between −5 and +5 are calculated linearly interpolating the weights for q = −5 and q = +5. Figure 7 illustrates how the weights for the mixed coefficients are defined.
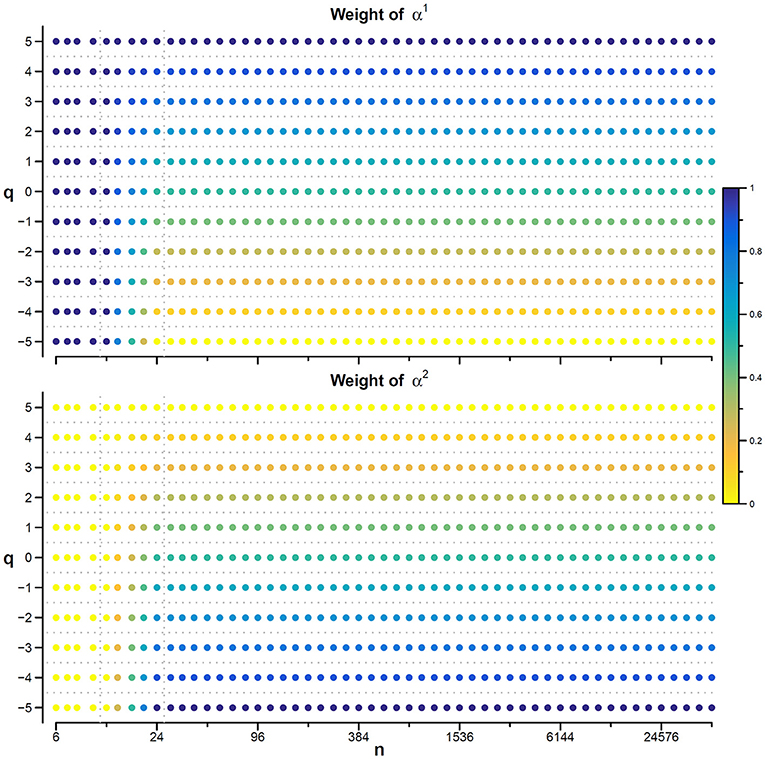
Figure 7. Weights for combining DFA1 and DFA2 estimates. The weighted estimate, αw(q,n), is a linear combination of DFA1 coefficients, α1(q,n), and DFA2 coefficients, α2(q,n), and it is proposed if there are no specific reasons to prefer one of the two detrending orders and if the time-series dynamics is assumed to be composed by fractional Gaussian noises or fractional Brownian motions. The weights, based on Equations (23), range between 0 (yellow) and 1 (dark blue). When n ≤ 12, αw = α1 for all q values; when n≥24, αw = α1 for q = 5, αw = α2 for q = −5, and α1 and α2 weights change linearly with q between −5 and +5 so that αw is the average between α1 and α2 for q = 0. The α1 and α2 weights change linearly also with n between 12 and 24.
Applications on Real Biomedical Time Series
This section presents examples of applications of our algorithm on physiological time series collected in volunteers that gave their written informed consent to participate to the study, which was approved by the Ethics Committee of Istituto Auxologico Italiano, IRCCS, Milan, Italy.
Heart Rate
Most of DFA applications in physiology regard the analysis of heart rate variability. In this field, the evaluation of the self-similarity exponents as a continuous function of the scale, α(n), proved useful for associating a short-term crossover to the dynamics of removal of noradrenaline released by the sympathetic nerve endings (Castiglioni, 2011), for quantifying alterations during sleep at high-altitude (Castiglioni et al., 2011b) and for evaluating clinical conditions like congestive heart failure (Bojorges-Valdez et al., 2007) or spinal lesions (Castiglioni and Merati, 2017). When the self-similarity exponents were estimated as a multifractal multiscale surface of the moment q and scale n, α(q,n), they provided information on the autonomic development from fetal heart rate recordings (Gieraltowski et al., 2013), on differences between the dynamics of heart rate and other cardiovascular variables (Castiglioni et al., 2018) and helped modeling the heart rate dynamics during sleep (Solinski et al., 2016).
In this context, our fast algorithm is expected to improve existing methods by calculating α(q,n) surfaces with higher scale resolution and lower estimation variability, thanks to its ability to provide estimates with maximally overlapped blocks in short time. As an example in the field of heart rate variability, we compare multiscale multifractality during nighttime sleep and during daytime activities in a healthy male volunteer. We derived R-R interval series from a 24-h electrocardiogram sampled at 250 Hz. We compared Fq(n) functions calculated on two segments of 4 h duration, one selected during daytime, from 2 p.m. to 6 p.m. (Wake condition), one during nighttime after sleep onset, from 2 a.m. to 6 a.m. (Sleep condition). The mean heart rate was 50 bpm during Sleep (N = 12,000 beats) and 71 bpm during Wake (N = 17,000 beats). Four premature beats were identified visually and removed, and Fq(n) functions were derived by DFA1 and DFA2 with maximally overlapped blocks. Since the mean heart rate is lower in Sleep than in Wake condition, the same block of n beats corresponds to different time scales, in seconds, during Sleep and during Wake. Therefore, the fluctuation functions were plotted vs. the corresponding temporal scale τ, in seconds, by multiplying n by the mean R-R interval. Figure 8 shows that Wake and Sleep have different fluctuations functions, increasing with τ as parallel lines in Wake and converging to a focus at the longest scales in Sleep. This suggests a multifractal behavior (i.e., different slopes for different q), more evident at some scales (i.e., a multiscale dynamics), during sleep. The Fq(τ) functions by DFA1 and by DFA2 appear similar: this confirms a previous observation on 24-h heart rate recordings (Gieraltowski et al., 2012) and does not suggest the presence of long-term trends that make one of the two detrending orders preferable. Therefore, we derived the surface of multifractal multiscale coefficients by applying the weighted approach of Equations (23). Figure 9 illustrates the resulting α(q,τ) surfaces. During daytime, the surface represents a relatively monofractal process with multiscale dynamics, i.e., α depends more on τ than on q. By contrast, during sleep, the surface also shows a strong dependence on q at some scales, like at τ = 1250 s, where it ranges between α = 2.05 at q = −5 and α = 0.9 at q = +5.
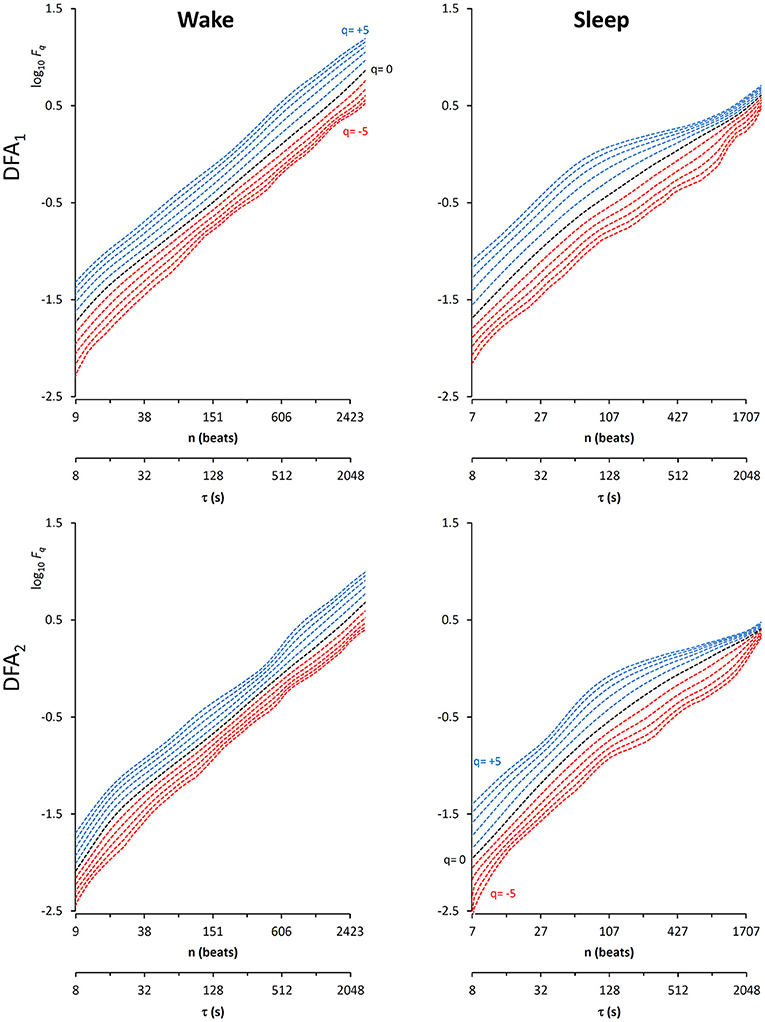
Figure 8. Multifractal fluctuation functions of heart-rate variability during Wake and Sleep with maximally overlapped blocks. The original series are two 4-h segments of beat-by-beat R-R intervals from a 24-h ECG recording in a healthy volunteer. The first horizontal axis is the box size n, in number of beats; the second horizontal axis is the temporal scale τ, in seconds, obtained multiplying n by the mean R-R interval, which is shorter in Wake than in Sleep. Thresholds Th1 and Th2 as in Equations (19) and EPS = 0.
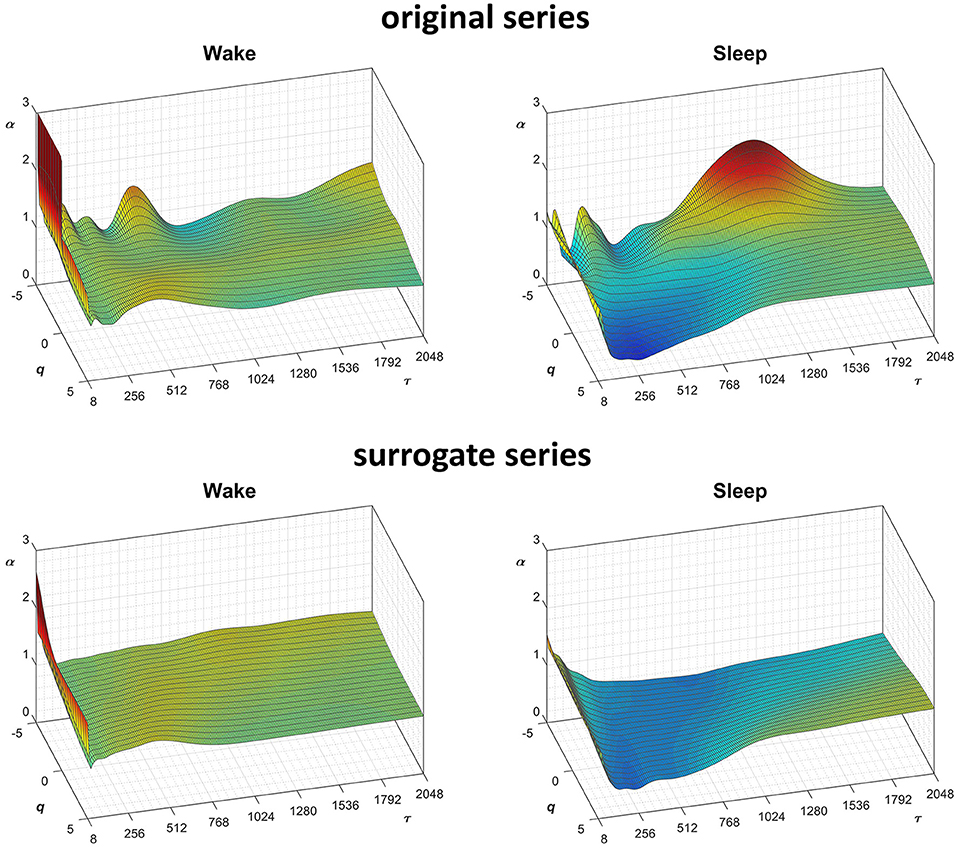
Figure 9. Scale coefficients of heart-rate variability during Wake and Sleep, for original and surrogate series. Coefficients calculated by Equations (22), combining DFA1 and DFA2 estimates by Equations (23); for surrogate data, the figure shows the average α surface over 100 series generated shuffling the phases of the Fourier spectrum of the original series. To more easily compare Wake and Sleep conditions, which are characterized by different heart rates, the τ axis represents the temporal scale in seconds; τ is obtained multiplying the box size, n, with the mean R-R interval (see Figure 8).
Fractal structures in physiological systems may arise from nonlinear chaotic dynamics or may be due to linear spectral features. We tested whether the α(q,n) surfaces we estimated for the heart-rate series actually reflect an underlying nonlinear dynamics with the method of surrogate data analysis (Theiler et al., 1992). For this purpose, we generated a dataset of 100 Fourier-phase shuffled time series (Schreiber and Schmitz, 2000) from each of the two recordings. The surrogate series have the same power spectrum of the original recording but a random phase. We calculated α(q,n) for the “Wake” and “Sleep” surrogate datasets. The average of each dataset is plotted in Figure 9 for comparison with the original data. Multifractal structures evident in the original series are absent in the surrogate data.
The statistical significance of the difference between the original and surrogate series was assessed evaluating in which percentile of the surrogate dataset the α(q,τ) coefficients of the original series fall. Figure 10 plots the significance p at each scale and moment order. The figure demonstrates the presence of a multifractal dynamics that does not depend on the linear characteristics of the power spectrum, and which characterizes Sleep more than Wake. The whole surrogate analysis of the 200 phase-shuffled series took less than 10 min with our algorithm, while the traditional algorithm would take more than 18 h according to Figure 4.
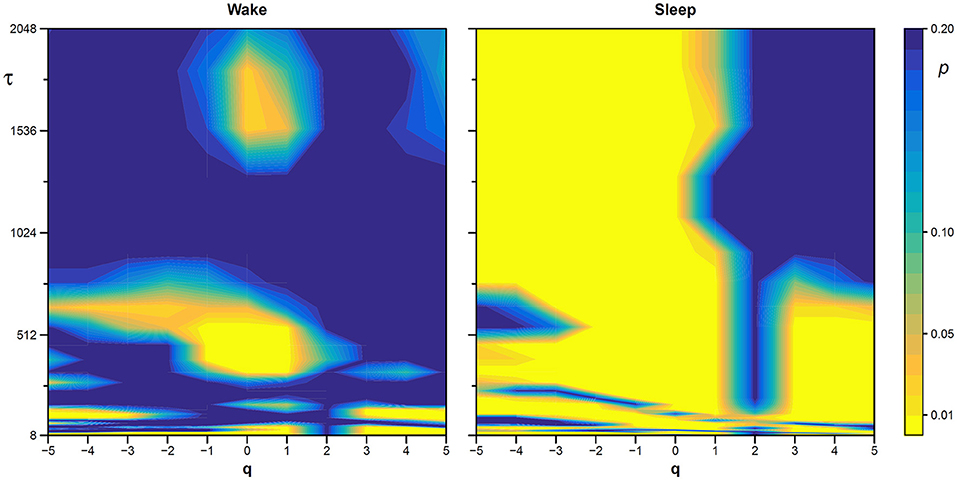
Figure 10. Statistical significance of the nonlinearity test on scale coefficients of heart rate. Each point represents the two-sided, type-I error probability to reject the null hypothesis comparing scale coefficients of the original series and of Fourier-phase shuffled surrogate series at each scale τ and at each moment-order q; differences significant at p < 0.01 are indicated in yellow. The temporal scale τ, in seconds, is obtained multiplying the box size, n, by the mean R-R interval (see Figure 8).
Electroencephalogram
Another important field of DFA applications in physiology regards the study of EEG recordings (Hardstone et al., 2012). Traditionally, EEG is described by two (Ferree and Hwa, 2003; Abasolo et al., 2008) or three DFA coefficients (Jospin et al., 2007), but α(n) represented as a continuous function of the scale n suggests more complex structures (Castiglioni, 2011). Therefore, we considered an overnight EEG recording (C4 lead) during sleep in a healthy adult male as an additional example. The EEG signal was band-pass filtered (cut-off frequencies between 0.3 and 35 Hz) before sampling at 128 Hz, and two segments of 1,600 s duration (N = 204,800 samples) were selected, one during NREM and one during REM sleep. Due to the 128 Hz sampling rate, the scale n, expressed in number of samples, corresponds to the temporal scale τ = n×(1000/128) milliseconds. The fluctuation functions (Figure 11) have an almost flat profile at scales larger than 4 s, likely an effect of the filter. Furthermore, they show remarkable differences between sleep phases at shorter scales, running in parallel during NREM sleep and following a sigmoidal pattern in REM sleep. Since DFA1 and DFA2 estimates are similar, excluding the shorter scales where DFA1 provides a more linear increase of log Fq(τ) with log τ, we estimated the scale coefficients with the weighted approach of Equations (23). The α(q,τ) surfaces (Figure 12) show a more evident multifractal structure in REM than in NREM sleep.
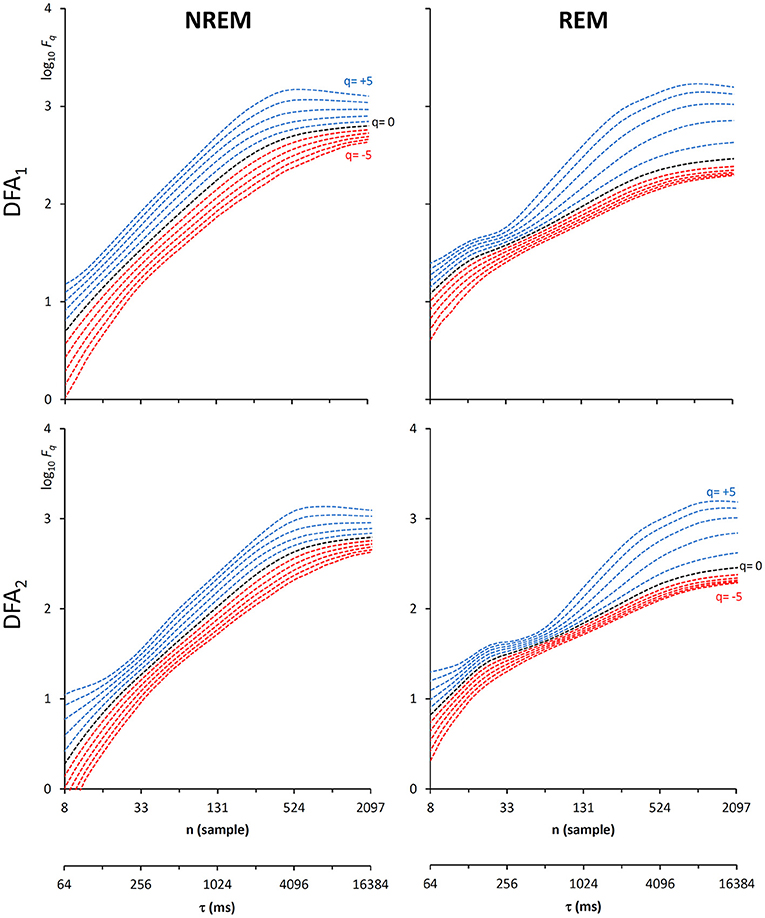
Figure 11. Fluctuation functions of EEG during NREM and REM sleep with maximally overlapped blocks. Time series are 1600-s segments of an EEG C4 lead sampled at 128 Hz during sleep in a healthy volunteer. The first horizontal axis is the box size, n, in number of samples, the second horizontal axis is the temporal scale, τ, in milliseconds, obtained multiplying n by the sampling period. Thresholds Th1 and Th2 as in Equations (19) and EPS = 10−4.
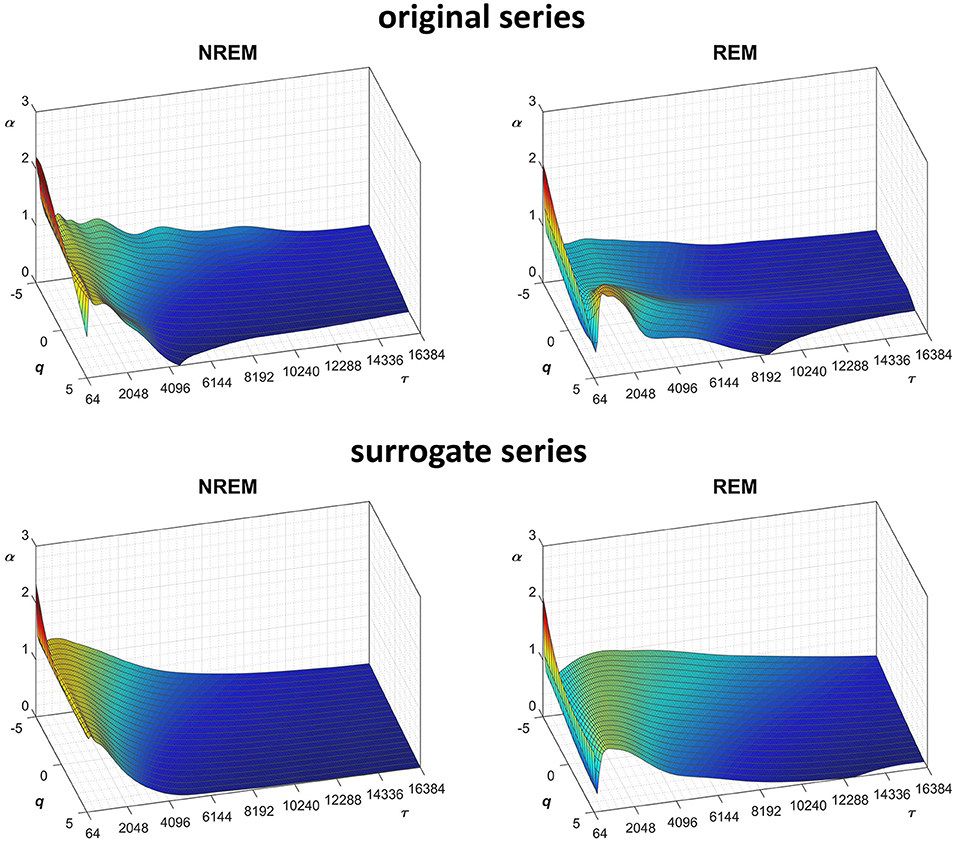
Figure 12. Scale coefficients during NREM and REM sleep. Coefficients calculated by Equations (22), combining DFA1 and DFA2 estimates by Equations (23), for original (Left) and Fourier-phase shuffled surrogate series (Right). The scale τ, in milliseconds, is the box size n multiplied by the sampling period.
We also generated a surrogate dataset of 100 Fourier-phase shuffled time series for each recording, one during NREM and one during REM sleep. The average α(q,τ) surface of each surrogate dataset is plotted in Figure 12 for comparison with the original series. Figure 13, shows the significance of the difference between original and phase-shuffled series and indicates that the null hypothesis is rejected and nonlinearity detected almost at all scales and moment orders. The whole analysis on 200 surrogate series took 3 h and 22 min: this calculation time should be compared with the calculation time of 27 days and 8 h that the traditional algorithm would take, as from Figure 4.
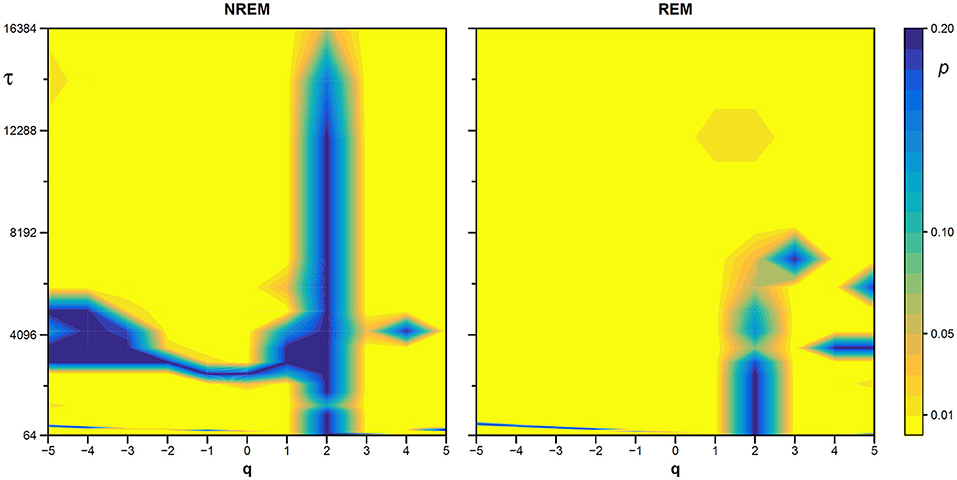
Figure 13. Statistical significance of nonlinearity test on EEG scale coefficients. Each point represents the two-sided, type-I error probability to reject the null hypothesis comparing scale coefficients of the original series and of Fourier-phase shuffled surrogate series at each scale τ and moment-order q; differences significant at p < 0.01 are indicated in yellow. The scale, τ, in milliseconds, is the box size n multiplied by the sampling period.
Summary of Advantages and Limitations, and Conclusions
Since the DFA introduction, hundredths of works in physiological or clinical settings quantified the fractal dynamics by α. Almost all of them provided a monofractal description, most considering only one or two ranges of scales (Perkiomaki, 2011; Sassi et al., 2015). Even if the results were promising, particularly in the field of heart rate variability, it is questioned whether a monofractal DFA estimating one or two coefficients may improve health assessment and risk stratification compared to nonfractal methods (Sassi et al., 2015). Therefore, the more advanced research in this field is investigating how DFA can be enhanced by jointly depicting the multifractal and multiscale nature of the time series in order to model pathophysiological mechanisms more completely (Zebrowski et al., 2015; Solinski et al., 2016).
In this regard, the proposed algorithm is aimed at improving scale resolution and at reducing estimation variability of the multifractal fluctuations function without the cost of an increase in calculation time that may make unfeasible the analysis of relatively long series. Therefore, we redesigned the multifractal DFA algorithm to provide estimates in a relatively short time even by using maximally overlapped blocks, with first and second-order detrending polynomials simultaneously. This allows comparing DFA1 and DFA2 estimates easily, which may be useful for evaluating the consistency of the estimates and for selecting the best detrending order. Simultaneously obtaining the DFA1 and DFA2 scale coefficients, which have a certain degree of statistical independence, also suggests new ways to improve the estimate, as in the weighted approach we proposed. The examples on real biomedical series point out that the algorithm is sufficiently fast to allow using challenging bootstrapping procedures on surrogate data that may separate linear and nonlinear components of the multiscale/multifractal dynamics. The possibility to apply such tests in clinical studies may make it easier deriving richer information to improve diagnosis or risk stratification from DFA.
Some limitations, however, should be considered. The algorithm employs detrending polynomials of first and second order only. Although these orders are used in most (if not all) DFA applications on real biosignal, the algorithm cannot be considered as general as other DFA codes. If a higher order “o” is required, the analytic expression of the polynomial regression should be derived as done in Equations (7–10) for DFA1 and DFA2, powers summations should be calculated by extending the array definition of Equation (14) and, to maintain calculation errors negligible also for DFAo, a new threshold Tho should be defined in Equations (19), which will decrease the speed of the algorithm.
Author Contributions
PC conceived the study and wrote the manuscript. AF wrote the code and created the figures. PC and AF developed the theoretical formulas on which the algorithm is based, designed the algorithm validation with synthesized series, made the acquisition and the analysis of real time series, interpreted the results and critically revised the manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Matlab source code for generating surrogate data was provided by Temu Gautama in Matlab central, downloadable from https://it.mathworks.com/matlabcentral/fileexchange/4612-surrogate-data.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2019.00115/full#supplementary-material
References
Abasolo, D., Hornero, R., Escudero, J., and Espino, P. (2008). A study on the possible usefulness of detrended fluctuation analysis of the electroencephalogram background activity in Alzheimer's disease. IEEE Trans. Biomed. Eng. 55, 2171–2179. doi: 10.1109/TBME.2008.923145
Bojorges-Valdez, E. R., Echeverria, J. C., Valdes-Cristerna, R., and Pena, M. A. (2007). Scaling patterns of heart rate variability data. Physiol. Meas. 28, 721–730. doi: 10.1088/0967-3334/28/6/010
Bunde, A., Havlin, S., Kantelhardt, J. W., Penzel, T., Peter, J.-H., and Voigt, K. (2000). Correlated and Uncorrelated Regions in Heart-Rate Fluctuations during Sleep. Phys. Rev. Lett. 85, 3736–3739. doi: 10.1103/PhysRevLett.85.3736
Castiglioni, P. (2011). “Self-similarity in physiological time series: new perspectives from the temporal spectrum of scale exponents,” in Computational Intelligence Methods for Bioinformatics and Biostatistics: 8th International Meeting, eds E. Biganzoli, A. Vellido, F. Ambrogi, R. Tagliaferri CIBB (Gargnano del Garda; Berlin, Heidelberg: Springer), 164–175.
Castiglioni, P., Di Rienzo, M., and Faini, A. (2017). “Self-similarity and detrended fluctuation analysis of cardiovascular signals,” in Complexity and Nonlinearity in Cardiovascular Signals, eds R. Barbieri, E. P. Scilingo, and G. Valenza (Cham: Springer International Publishing), 197–232. doi: 10.1007/978-3-319-58709-7_7
Castiglioni, P., Lazzeroni, D., Coruzzi, P., and Faini, A. (2018). Multifractal-multiscale analysis of cardiovascular signals: a DFA-based characterization of blood pressure and heart-rate complexity by gender. Complexity 2018, 1–14. doi: 10.1155/2018/4801924
Castiglioni, P., and Merati, G. (2017). Fractal analysis of heart rate variability reveals alterations of the integrative autonomic control of circulation in paraplegic individuals. Physiol. Measur. 38, 774–786. doi: 10.1088/1361-6579/aa5b7e
Castiglioni, P., Parati, G., Civijian, A., Quintin, L., and Di Rienzo, M. (2009). Local scale exponents of blood pressure and heart rate variability by detrended fluctuation analysis: effects of posture, exercise, and aging. IEEE Trans. Biomed. Eng. 56, 675–684. doi: 10.1109/TBME.2008.2005949
Castiglioni, P., Parati, G., Di Rienzo, M., Carabalona, R., Cividjian, A., and Quintin, L. (2011a). Scale exponents of blood pressure and heart rate during autonomic blockade as assessed by detrended fluctuation analysis. J. Physiol. 589, 355–369. doi: 10.1113/jphysiol.2010.196428
Castiglioni, P., Parati, G., Lombardi, C., Quintin, L., and Di Rienzo, M. (2011b). Assessing the fractal structure of heart rate by the temporal spectrum of scale exponents: a new approach for detrended fluctuation analysis of heart rate variability. Biomed. Tech. 56, 175–183. doi: 10.1515/bmt.2011.010
Echeverria, J. C., Woolfson, M. S., Crowe, J. A., Hayes-Gill, B. R., Croaker, G. D., and Vyas, H. (2003). Interpretation of heart rate variability via detrended fluctuation analysis and alphabeta filter. Chaos. 13, 467–475. doi: 10.1063/1.1562051
Eke, A., Herman, P., Bassingthwaighte, J. B., Raymond, G. M., Percival, D. B., Cannon, M., et al. (2000). Physiological time series: distinguishing fractal noises from motions. Pflug. Arch. 439, 403–415. doi: 10.1007/s004249900135
Ferree, T. C., and Hwa, R. C. (2003). Power-law scaling in human EEG: relation to Fourier power spectrum. Neurocomputing 52–54, 755–761. doi: 10.1016/S0925-2312(02)00760-9
Ge, E., and Leung, Y. (2013). Detection of crossover time scales in multifractal detrended fluctuation analysis. J. Geograph. Syst. 15, 115–147. doi: 10.1007/s10109-012-0169-9
Gieraltowski, J., Hoyer, D., Tetschke, F., Nowack, S., Schneider, U., and Zebrowski, J. (2013). Development of multiscale complexity and multifractality of fetal heart rate variability. Auton. Neurosci. 178, 29–36. doi: 10.1016/j.autneu.2013.01.009
Gieraltowski, J., Zebrowski, J. J., and Baranowski, R. (2012). Multiscale multifractal analysis of heart rate variability recordings with a large number of occurrences of arrhythmia. Phys. Rev. E Stat. Nonlin. Soft. Matter Phys. 85:021915. doi: 10.1103/PhysRevE.85.021915
Goldberger, A. L., Amaral, L. A., Glass, L., Hausdorff, J. M., Ivanov, P. C., Mark, R. G., et al. (2000). PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation 101, E215–E220. doi: 10.1161/01.CIR.101.23.e215
Hardstone, R., Poil, S.-S., Schiavone, G., Jansen, R., Nikulin, V. V., Mansvelder, H. D., et al. (2012). Detrended fluctuation analysis: a scale-free view on neuronal oscillations. Front. Physiol. 3:450. doi: 10.3389/fphys.2012.00450
Höll, M., and Kantz, H. (2015). The relationship between the detrendend fluctuation analysis and the autocorrelation function of a signal. Eur. Phys. J. B. 88:327. doi: 10.1140/epjb/e2015-60721-1
Hwa, R. C., and Ferree, T. C. (2002). Scaling properties of fluctuations in the human electroencephalogram. Phys. Rev. E. Stat. Nonlin. Soft. Matter. Phys. 66:021901. doi: 10.1103/PhysRevE.66.021901
Ihlen, E. A. F. (2012). Introduction to multifractal wavelet and detrended fluctuation analyses. Front. Physiol. 3:141. doi: 10.3389/fphys.2012.00141
Jospin, M., Caminal, P., Jensen, E. W., Litvan, H., Vallverdu, M., Struys, M. M., et al. (2007). Detrended fluctuation analysis of EEG as a measure of depth of anesthesia. IEEE Trans. Biomed. Eng. 54, 840–846. doi: 10.1109/TBME.2007.893453
Kantelhardt, J. W., Koscielny-Bunde, E., Rego, H. H. A., Havlin, S., and Bunde, A. (2001). Detecting long-range correlations with detrended fluctuation analysis. Phys. A 295, 441–454. doi: 10.1016/S0378-4371(01)00144-3
Kantelhardt, J. W., Zschiegner, S. A., Koscielny-Bunde, E., Havlin, S., Bunde, A., and Stanley, H. E. (2002). Multifractal detrended fluctuation analysis of nonstationary time series. Phys. A 316, 87–114. doi: 10.1016/S0378-4371(02)01383-3
Kiyono, K. (2015). Establishing a direct connection between detrended fluctuation analysis and Fourier analysis. Phys. Rev. E 92:042925. doi: 10.1103/PhysRevE.92.042925
Ludescher, J., Bogachev, M. I., Kantelhardt, J. W., Schumann, A. Y., and Bunde, A. (2011). On spurious and corrupted multifractality: the effects of additive noise, short-term memory and periodic trends. Phys. A 390, 2480–2490. doi: 10.1016/j.physa.2011.03.008
Mukli, P., Nagy, Z., and Eke, A. (2015). Multifractal formalism by enforcing the universal behavior of scaling functions. Phys. A 417, 150–167. doi: 10.1016/j.physa.2014.09.002
Mukli, P., Nagy, Z., Racz, F. S., Herman, P., and Eke, A. (2018). Impact of healthy aging on multifractal hemodynamic fluctuations in the human prefrontal cortex. Front. Physiol. 9:1072. doi: 10.3389/fphys.2018.01072
Nagy, Z., Mukli, P., Herman, P., and Eke, A. (2017). Decomposing multifractal crossovers. Front. Physiol. 8:533. doi: 10.3389/fphys.2017.00533
Peng, C. K., Havlin, S., Stanley, H. E., and Goldberger, A. L. (1995). Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series. Chaos 5, 82–87. doi: 10.1063/1.166141
Perkiomaki, J. S. (2011). Heart rate variability and non-linear dynamics in risk stratification. Front Physiol. 2:81. doi: 10.3389/fphys.2011.00081
Sassi, R., Cerutti, S., Lombardi, F., Malik, M., Huikuri, H. V., Peng, C. K., et al. (2015). Advances in heart rate variability signal analysis: joint position statement by the e-Cardiology ESC Working Group and the European Heart Rhythm Association co-endorsed by the Asia Pacific Heart Rhythm Society. Europace 17, 1341–1353. doi: 10.1093/europace/euv015
Schreiber, T., and Schmitz, A. (2000). Surrogate time series. Phys. D 142, 346–382. doi: 10.1016/S0167-2789(00)00043-9
Solinski, M., Gieraltowski, J., and Zebrowski, J. (2016). Modeling heart rate variability including the effect of sleep stages. Chaos 26:023101. doi: 10.1063/1.4940762
Theiler, J., Eubank, S., Longtin, A., Galdrikian, B., and Doyne Farmer, J. (1992). Testing for nonlinearity in time series: the method of surrogate data. Phys. D. 58, 77–94. doi: 10.1016/0167-2789(92)90102-S
Xia, J., Shang, P., and Wang, J. (2013). Estimation of local scale exponents for heartbeat time series based on DFA. Nonlin. Dyn. 74, 1183–1190. doi: 10.1007/s11071-013-1033-2
Zebrowski, J. J., Kowalik, I., Orlowska-Baranowska, E., Andrzejewska, M., Baranowski, R., and Gieraltowski, J. (2015). On the risk of aortic valve replacement surgery assessed by heart rate variability parameters. Physiol. Meas. 36, 163–175. doi: 10.1088/0967-3334/36/1/163
Appendix
Given the time series yi with index i from 1 to N, let's shift i by the integer quantity J so that each sample yi is associated with the new index j = i-J running from 1-J to N-J.
The average i = i can be rewritten as
Similarly, the summation siy = in Equation (8c) can be rewritten as
and = in Equation (10d) as
Through Equations (A1–3), sjy and can be obtained from siy and as calculated in Equation (15).
Keywords: hurst exponent, multiscale analysis, multifractality, HRV, EEG
Citation: Castiglioni P and Faini A (2019) A Fast DFA Algorithm for Multifractal Multiscale Analysis of Physiological Time Series. Front. Physiol. 10:115. doi: 10.3389/fphys.2019.00115
Received: 08 October 2018; Accepted: 30 January 2019;
Published: 01 March 2019.
Edited by:
Zbigniew R. Struzik, The University of Tokyo, JapanReviewed by:
Piotr Suffczynski, University of Warsaw, PolandStanislaw Drozdz, Institute of Nuclear Physics (PAN), Poland
Copyright © 2019 Castiglioni and Faini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Paolo Castiglioni, cGNhc3RpZ2xpb25pQGRvbmdub2NjaGkuaXQ=
orcid.org/0000-0002-8775-2605