 Peipei Chen
Peipei Chen Bo Long2
Bo Long2 Shuyang Zhang
Shuyang Zhang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Physiol. , 06 December 2018
Sec. Systems Biology Archive
Volume 9 - 2018 | https://doi.org/10.3389/fphys.2018.01778
As one common disease causing young people to die suddenly due to cardiac arrest, arrhythmogenic right ventricular cardiomyopathy (ARVC) is a disorder of heart muscle whose progression covers one complicated gene interaction network that influence the diagnosis and prognosis of it. In our research, differentially expressed genes (DEGs) were screened, and we established a weighted gene coexpression network analysis (WGCNA) and gene set net correlations analysis (GSNCA) for identifying crucial genes as well as pathways related to ARVC pathogenic mechanism (n = 12). In the research, the results demonstrated that there were 619 DEGs in total between non-failing donor myocardial samples and ARVC tissues (FDR < 0.05). WGCNA analysis identified the two gene modules (brown and turquoise) as being most significantly associated with ARVC state. Then the ARVC-related four key biological pathways (cytokine–cytokine receptor interaction, chemokine signaling pathway, neuroactive ligand receptor interaction, and JAK-STAT signaling pathway) and four hub genes (CXCL2, TNFRSF11B, LIFR, and C5AR1) in ARVC samples were further identified by GSNCA method. Finally, we used t-test and receiver operating characteristic (ROC) curves for validating hub genes, results showed significant differences in t-test and their AUC areas all greater than 0.8. Together, these results revealed that the new four hub genes as well as key pathways that might be involved into ARVC diagnosis. Even though further experimental validation is required for the implication by association, our findings demonstrate that the computational methods based on systems biology might complement the traditional gene-wide approaches, as such, might offer a new insight in therapeutic intervention within rare diseases of people like ARVC.
As one inherited cardiomyopathy involved into the right ventricle primarily, arrhythmogenic right ventricular cardiomyopathy (ARVC) is characterized by cardiomyocytes’ fibrofatty replacement (Calkins et al., 2017; Corrado et al., 2017). The prevalence of the general population is estimated to be 1:5000 to 1:1000 (Rampazzo et al., 1994; Peters et al., 2004). ARVC is a common cause resulting in young people’s sudden cardiac death (SCD) (Bagnall et al., 2016; Finocchiaro et al., 2016), and SCD may be the first manifestation of the disease (Dalal et al., 2005; Gupta et al., 2017). The detailed clinical features of ARVC were first described in 1982 (Marcus et al., 1982), followed by reports showing that pathogenic genetic mutations occurred in more than 60% of patients (Bhonsale et al., 2015), and high genetic heterogeneity and dominant inheritance most commonly causes the genetic etiology to patients with ARVC. Currently, the most effective treatment of ARVC is implantable cardioverter defibrillator (ICD), and early diagnosis and detection is needed. Hundred of genes were estimated to be involved into ARVC molecular mechanism, leading to a more complex ARVC diagnosis and prognosis. However, molecular genetic diagnostic yield is known to be highly variable, ARVC-related targeted genes is still unclear (Bhonsale et al., 2015). For obtaining a better understanding of complicated mechanism and exploring potential ARVC eigengenes, we used the weighted gene coexpression network analysis (WGCNA) approach for the research analysis.
At present, gene expression profiles have been utilized for identifying genes related to diagnosis or progression in the cardiovascular field (Boileau et al., 2018; Molina et al., 2018; Theriault et al., 2018). However, while genes that have similar patterns of expression might be related in a functional way, most studies are only interested in screening for differentially expressed genes (DEGs) and ignoring highly interconnected genes (Tavazoie et al., 1999). WGCNA is one system biology approach used to describe pattern of correlation between genes in RNA sequencing data or microarray. It is one algorithm to discover highly related gene clusters (modules) and identifying phenotypically related modules or gene clusters (Langfelder and Horvath, 2008). At present, many studies in the cardiovascular field have revealed genes related to the phenotype and differentiation stages by the method of WGCNA (Liu et al., 2017; Wang T. et al., 2017; Tang Y. et al., 2018). For instance, ZEB1 was found to be essential for early cardiomyocyte differentiation (?). FKBP11 could act as one critical regulator within acute aortic dissection (Wang T. et al., 2017). In the research, we try to screen the DEGs, and establish the coexpression network to find the key biological pathways and hub genes that are involved within ARVC state.
We downloaded the gene expression profile in the database, Gene Expression Omnibus (GEO)1. The dataset GSE29819 from an Affymetrix Human Genome U133 Plus 2.0 Array [transcript (gene) version] (Affymetrix, Santa Clara, CA, United States) was utilized in this study. This dataset contains 6 ARVC specimens derived from heart transplantation candidates were compared with six non-failing donor hearts (NF) which could not be transplanted due to technical reason. From the hearts, both right ventricle (RV) and left ventricle (LV) myocardial samples were analyzed using Affymetrix HG-U133 Plus 2.0 arrays.
One flow diagram (Figure 1) shows the research design. We calculated the raw expression data using the preprocessing steps as follows: robust multichip average background correction, log2 transformation, quantile normalization as well as median polish algorithm summarization utilizing “affy” R package (Gautier et al., 2004). The Affymetrix annotation files annotated the probes. Sample clustering was used to assess the quality of microarray in accordance with distance between various samples within Pearson’s correlation matrices. All samples from the data set were not removed in the subsequent analysis (Figure 2A).
Figure 1. Study flow diagram. Data preparation, processing, and analysis are shown in the flow diagram.
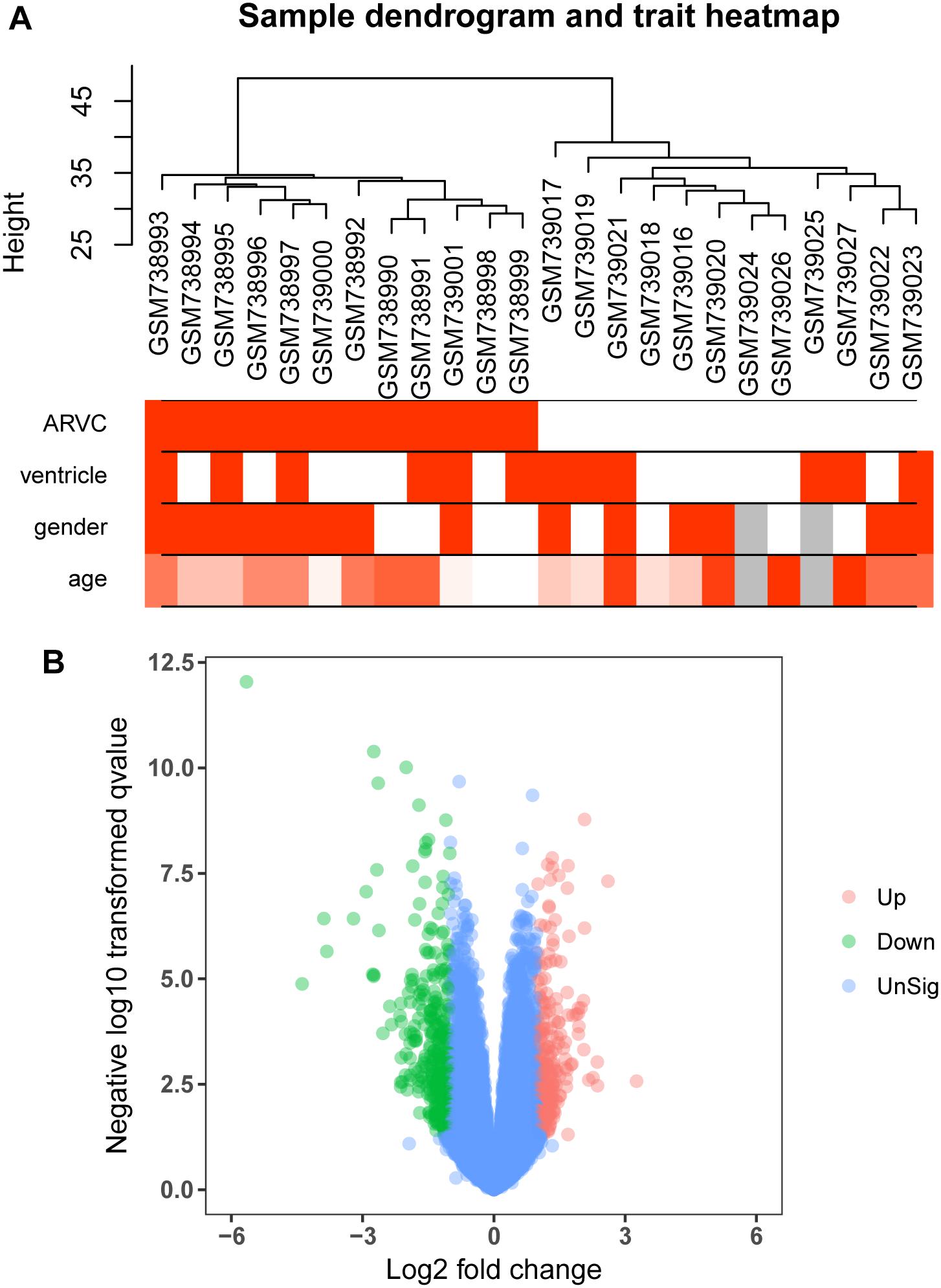
Figure 2. Clustering dendrogram and the clinical traits, as well as identification of differentially expressed genes (DEGs) in ARVC tissues. (A) Clustering dendrogram and clinical traits of GSE29819. The clustering was on the basis of the expression data of DEGs between ARVC samples and non-failing donor myocardial samples. The red color represents the right ventricle and men. The color intensity was in proportion to the older age. (B) The volcano plot of all DEGs.
We use the “limma” R package (Ritchie et al., 2015) for screening DEGs between ARVC samples and non-failing donor myocardial samples. The false discovery rate (FDR) < 0.05 and |log2fold change (log2FC)|>1 were selected to be cutoff criteria (Figure 2B). A heatmap was plotted using the pheatmap package (Figure 3A). Two features were extracted from the genes of each group using an unsupervised principal component analysis (PCA) method (Figure 3B).
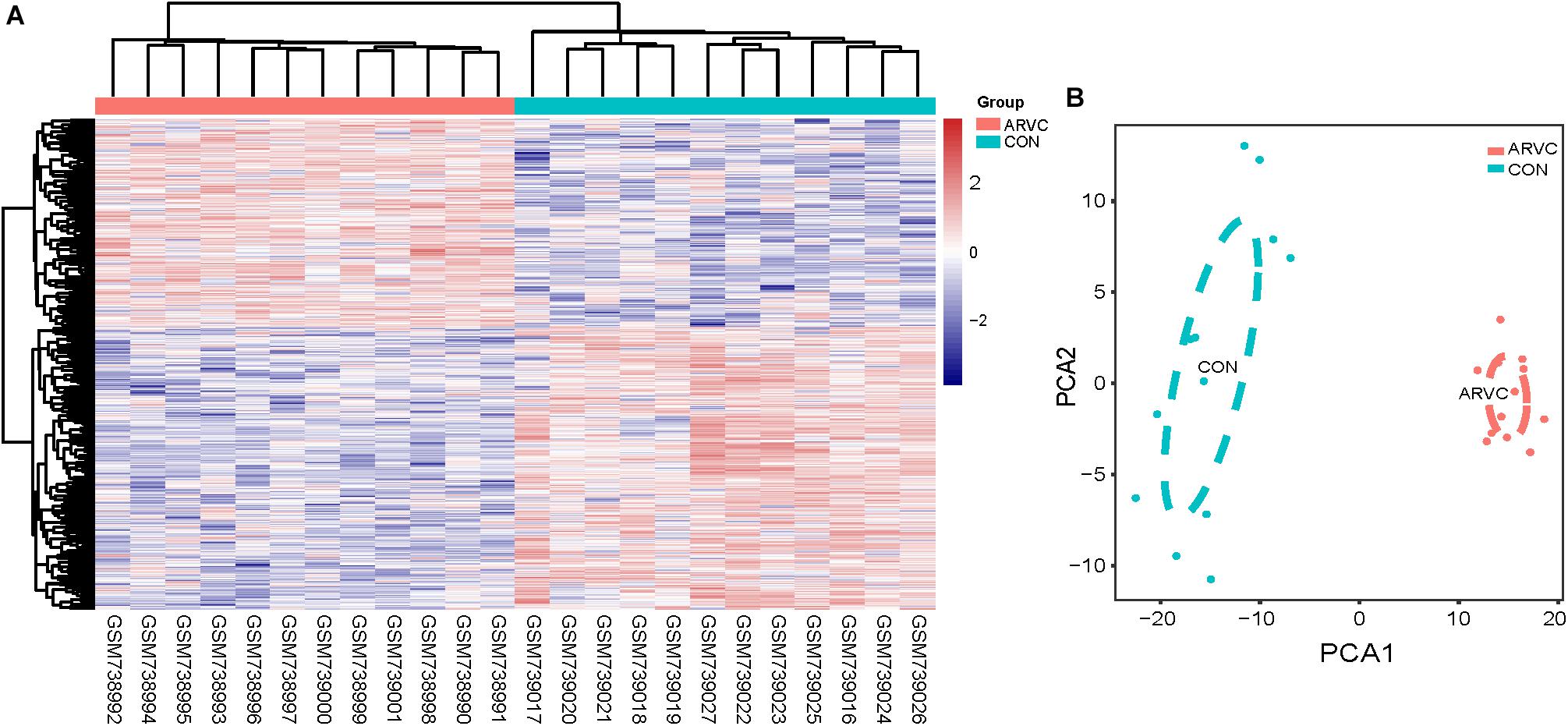
Figure 3. (A) Heatmap showing significantly differentially expressed protein-coding genes of ARVC and non-failing donor myocardial tissues. In the heatmap, samples are sorted by columns, and genes by rows. Cyan square represented Control group, and red square represented ARVC group. (B) PCA scores trajectory plots showing obvious differences resulting from the ARVC and Control groups. Cyan point, control group; red point, ARVC group.
First of all, DEGs expression data profile was tested for confirming that they meet the subsequent analysis requirements. Secondly, package of “WGCNA” within R was used for constructing DEGs coexpression network (Horvath and Dong, 2008; Mason et al., 2009). WGCNA is one statistical method which sets up gene sets (modules) from gene expression data that are observed using unsupervised clustering, briefly, it assigns a connection weight between pairs of genes in network on the basis of one scale-free topology (SFT) criterion as well as tries to recognize related modules using one soft threshold to correlations between pairs of genes in one network, and thus does not rely on a priori defined gene sets. Within one biological network that has an SFT, gene relationship distribution adheres to the law of power decay, for example, the genes that have the maximum number of connections appears at the minimum frequency (van Noort et al., 2004; Barabasi, 2009). Function firstly calculates one pairwise correlation matrix for all gene sets, then, it computes a nearby matrix by elevating matrix to one soft threshold power (β). Pearson’s correlation matrix was conducted for each pairwise gene and used the power function amn = |cmn|β (cmn = Pearson’s correlation between gene n and gene m; amn = adjacency between gene n and gene m) was used. The β utilized for transforming similarity matrix is chosen when resultant network approximates one scale-free topology the best. The transformation process of correlation matrix to approximate architecture of scale-free network starts by elevating matrix to one range of β (such as β = 1–20 in Figure 4A) for producing one series of adjacency matrices. The connectivity of genes could be defined as significance of one specific gene in one network of coexpression and is computed only by summing all rows within one adjacency matrix. For selecting the most suitable β value, linear model fit (R2) between log(k) and log(p(k)) is computed from all adjacency matrices, where k = connectivity, p(k) proportion of genes with connectivity k (Figures 4A,D). Perfect agreement with SFT could generated an R2 = 1, nevertheless, if the SFT fit index for reference data set reached above-0.8 values for the lower power (<30) (Langfelder and Horvath, 2017), as power of threshold defined in. For example, within WGCNA signed, β values which generated one R2 > 0.8 is regarded to be one fit acceptable for SFT, and usually chose the one which first approached the highest value. Fitting to a power-law has been a frequent strategy of WGCNA in previous researches (Sikri et al., 2018; Tang J. et al., 2018; Yuan et al., 2018; Zhou et al., 2018), and is also the strategy followed in this study. The value of R2 was 0.89 in this study (Figure 4D). Therefore, in this study, we chose the beta value (β = 7, Figure 4A) when we first approached the highest value to construct a gene network. WGCNA is shown to be very robust to β choice in terms of previously elucidated biological information. Then, adjacency was transformed to the topological overlap matrix (TOM) for measuring connectivity of network of the genes, which was defined to be sum of the adjacency of it and any other gene used for generation of networks (Yip and Horvath, 2007). In accordance with dissimilarity measure based on TOM within one 30 of smallest size (gene group) for genes dendrograms, a mean linkage hierarchical clustering was carried out to identify any gene that had the similar expression profile in gene modules.
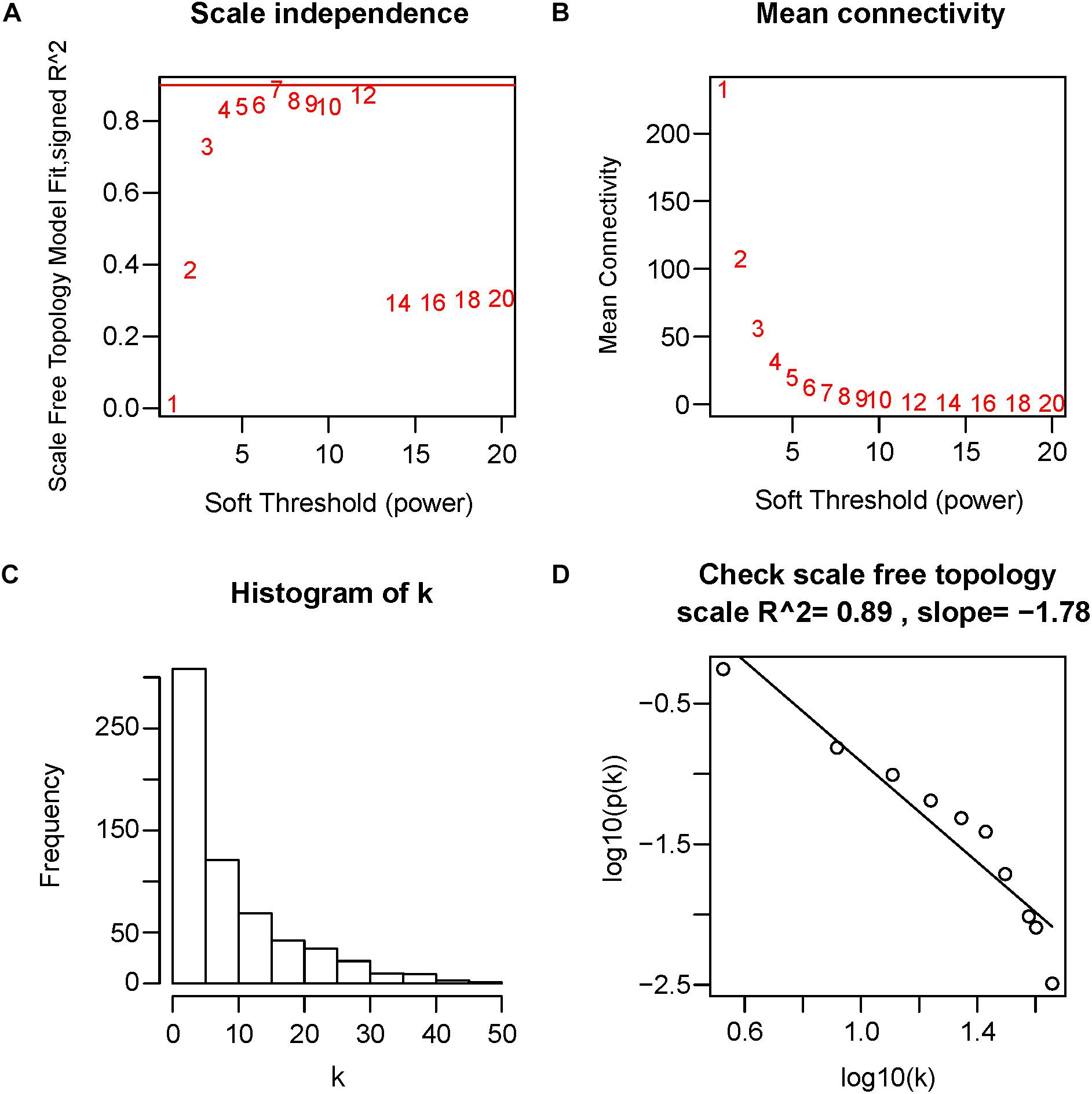
Figure 4. Determination of soft-threshold power in WGCNA. The scale-free topology index and the mean connectivity for each power value between 1 and 20 are shown in (A,B) panels, respectively. The histogram of connectivity distribution and the scale-free topology are shown in (C,D) panels, respectively.
Two methods were utilized for identifying ARVC state-related modules. Firstly, we defined gene significance (GS) to be log10 transformation of P-value within linear regression between ARVC state and gene expression. Additionally, module significance (MS) was defined to be mean GS for each gene within one module (Figure 5C). Generally, module that had absolute MS and ranked the first or second in the whole modules selected was regarded to be associated with clinical trait. Module eigengenes (MEs) were generally supposed to be the primary component within analysis of principal components for all gene modules, and each gene’s patterns of expression could be summarized in one singe characteristic expression profile in one given module. In the present study, we computed correlation between clinical trait and MEs for identifying related modules (Figure 5B).
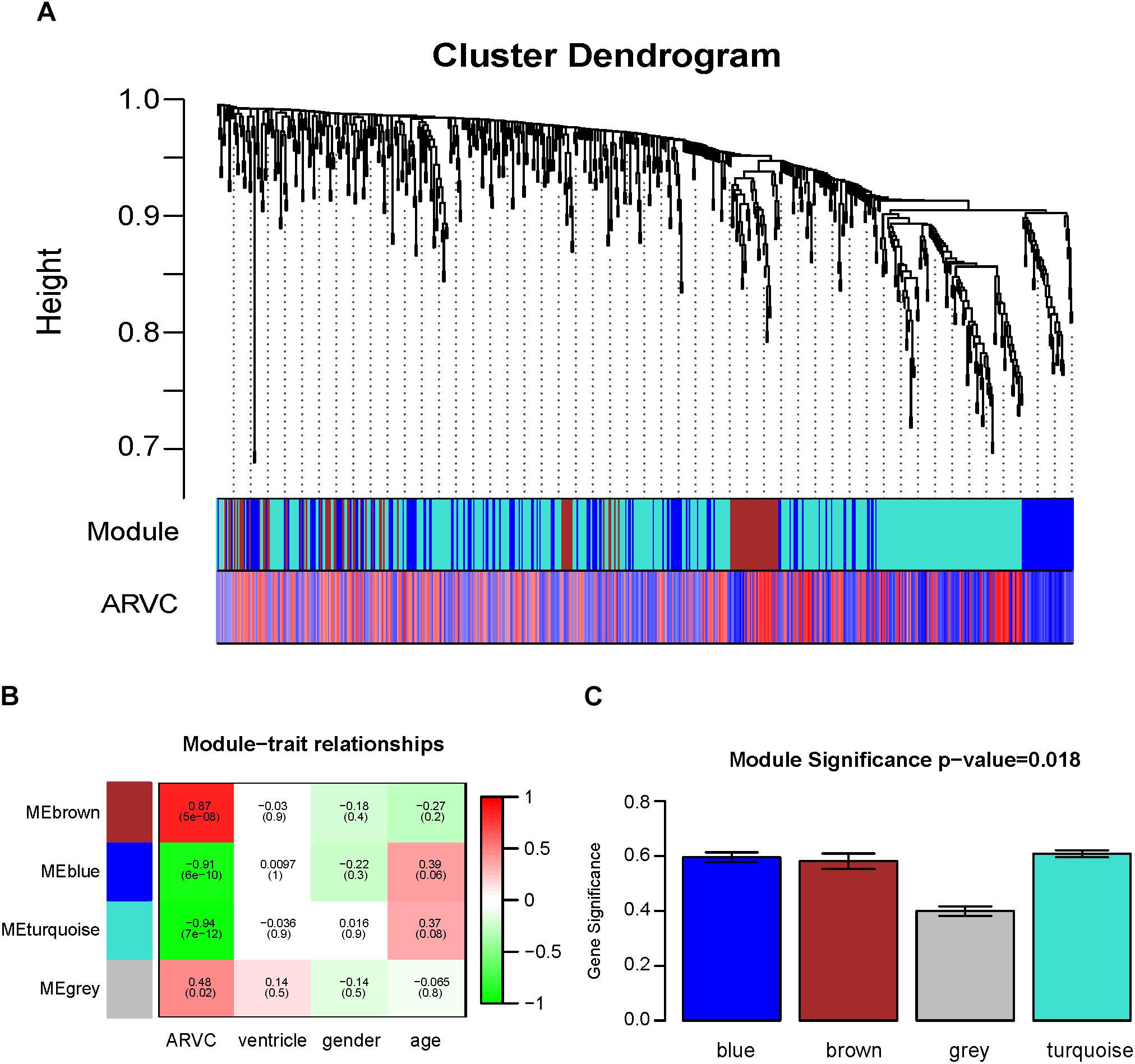
Figure 5. Identification of modules related to the clinical traits of the ARVC. (A) Dendrogram of all differentially expressed genes clustered on the basis of one dissimilarity measure (1-TOM). (B) Heatmap of the correlation between module eigengenes and ARVC clinical traits. (C) Distribution of the mean gene significance and errors in the modules related to ARVC state. Barplot of module significance (MS) defined as the average gene significance across all genes in modules.
The gene set net correlations analysis (GSNCA) (Rahmatallah et al., 2014) upon resultant modules was conducted for identifying the module which is differentially coexpressed between two ARVC sample and non-failing donor myocardial samples. The questions in this analysis test were gene sets’ identification expressed with various distributions, variances, means, or structure of correlation between two conditions. On the significance level of 0.05, pathways shows one statistical evidence that they are differentially coexpressed. GSNCA assigns one normalized eigenvector version of correlation matrix corresponding to biggest eigenvalue as one weight vector for genes within gene set under the two conditions. For ensuring appropriate indexing within modules by gene name within all significant pathways in this study, genes’ lists within each pathway are supposed to consist of only the available genes within the most relevant modules (brown and turquoise modules in WGCNA results). Any gene with not special mapping to the identifiers of gene symbol or does not exist within data set of the modules was abandoned from pathways. This ensures appropriate gene indexing within modules by gene name within all significant pathways. At last, we kept pathways only with 10 ≤ n ≤ 500 where n denotes the number of genes that remain within pathways after filtering procedures. Additionally, the GSNCA approach is part of Bioconductor GSAR package (Rahmatallah et al., 2017b).
The most highly correlated pathways in both ARVC and control samples, recognized utilizing structure of minimum spanning tree-2 (MST-2) carried out within package GSAR’s plotMST2.pathway function. One correlation network’s MST2 is formed through combination of the first and second MSTs as well as highlights minimum essential link set (i.e., highest correlation) between genes within coexpression network (Rahmatallah et al., 2014). The MST is defined to be acyclic tree that has shortest link which connects each gene within coexpression network. Within structure of MST2, genes with degree of highly associated are put into central position. The colors of nodes suggest weight factor (w)’s value assigned to all genes for reflecting the mean correlation with any other gene within gene set coexpression.
Receiver operating characteristic (ROC) curves were set up for assessing areas under the curves (AUCs) that had 95% of CI. Results of AUC are regarded excellent for the values of AUC ranging between 0.9 and 1, good for the values of AUC ranging between 0.8 and 0.9 (El Khouli et al., 2009). Thus, when hub gene’s AUC value > 0.8, it was considered to have good specificity and sensitivity to distinguish between ARVC and healthy control group. We used this as one of the indicator for diagnostic effectiveness evaluation by maximizing Youden’s index, plotted ROC curve, and calculated the AUC with “ROCR” package (Sing et al., 2005). Then, comparative analysis on hub genes within two groups was analyzed by independent sample t-test at the significance level of 0.05.
Figure 1 shows the research workflow. We obtained gene expression matrices from the training set GSE29819, including 6 ARVC specimens derived from heart transplantation candidates and 6 non-failing myocardial donor hearts myocardial samples after preprocessing of data and assessment of quality. Genes that have one stable expression across both groups were abandoned, as they provide little or no distinction. From ∼21,755 genes within dataset, a total of 619 DEGs (263 upregulated and 356 down-regulated) were selected for network construction under threshold of FDR < 0.05 and |log2FC|>1 (Supplementary Table S1). Figure 2B shows each gene’s volcano plot. A heatmap showing significantly DEGs can be found in Figure 3A. The score plots of PCA disclosed one tendency of intragroup aggregation and separation after unit variance scaling, normalization, and alignment of data (Figure 3B). The PCA score trajectory plots of ARVC did not substantially overlap with the profiles of the control group, indicating that the heatmap visualization and parallel PCA score trajectory plots both showed apparent differences resulting from the ARVC and control group.
Twelve ARVC samples that had clinical data were incorporated into coexpression analyses (Figure 2A). We used the “WGCNA” R package for putting DEGs that had similar patterns of expression to modules by the average linking clustering. In the present research, power of β = 7 (scale-free R2 = 0.89) was chosen to be soft-threshold (Figure 4).
Then, the hierarchical clustering tree for 619 DEGs was determined by conducting hierarchical clustering for dissTOM (Figure 5A), and we determined the most significant correlation modules with clinical features. Finally, a total of three modules related to the ARVC status were identified (Figure 5A and Supplementary Table S2), with the size of modules between 87 genes (brown modules) to 365 genes (turquoise modules). Additionally, 2 genes (L3MBTL4 and EPN2) were assigned into the gray module (insignificant module), so they were omitted in subsequent analyses.
Correlation between ARVC state and level of expression of the module eigengenes was calculated for identifying the most remarkable correlations. The highest positive correlation within module-feature relation was discovered between ARVC state and brown module (r = 0.87, p = 5e-08; Figure 5B), and the highest negative correlation between turquoise modules and ARVC state (r = -0.94, p2 = 7e-12; Figure 5B). Brown module includes 87 genes and the turquoise module includes 365 genes. MS between modules was also compared (Figure 5C), the result demonstrated that genes in brown or turquoise modules had highest positive or negative correlation with to ARVC status.
It was found that genes in modules were related to representative eigengene of it with various levels of module membership (MM), quantified by the module eigengene-based connectivity. For identifying the genes related to ARVC state, we defined measure of gene significance (GS) to be one Pearson gene expression correlation with ARVC state. The results showed one marked Pearson correlation between GS and MM values within brown module (correlation = 0.88, FDR corrected p-value = 3.2e-29, Figure 6A) as well as within turquoise module (correlation = 0.9, FDR corrected p-value = 5.8e-133, Figure 6B). The genes that were markedly related to ARVC state were usually the most important module members related to ARVC state. The input data of the WGCNA method in this study have been filtered for gene expression difference analysis using package Limma (Ritchie et al., 2015). The cut-off criteria are FDR < 0.05 and | log2FC| > 1. Therefore, the genes contained in the brown and turquoise modules satisfy the above conditions.
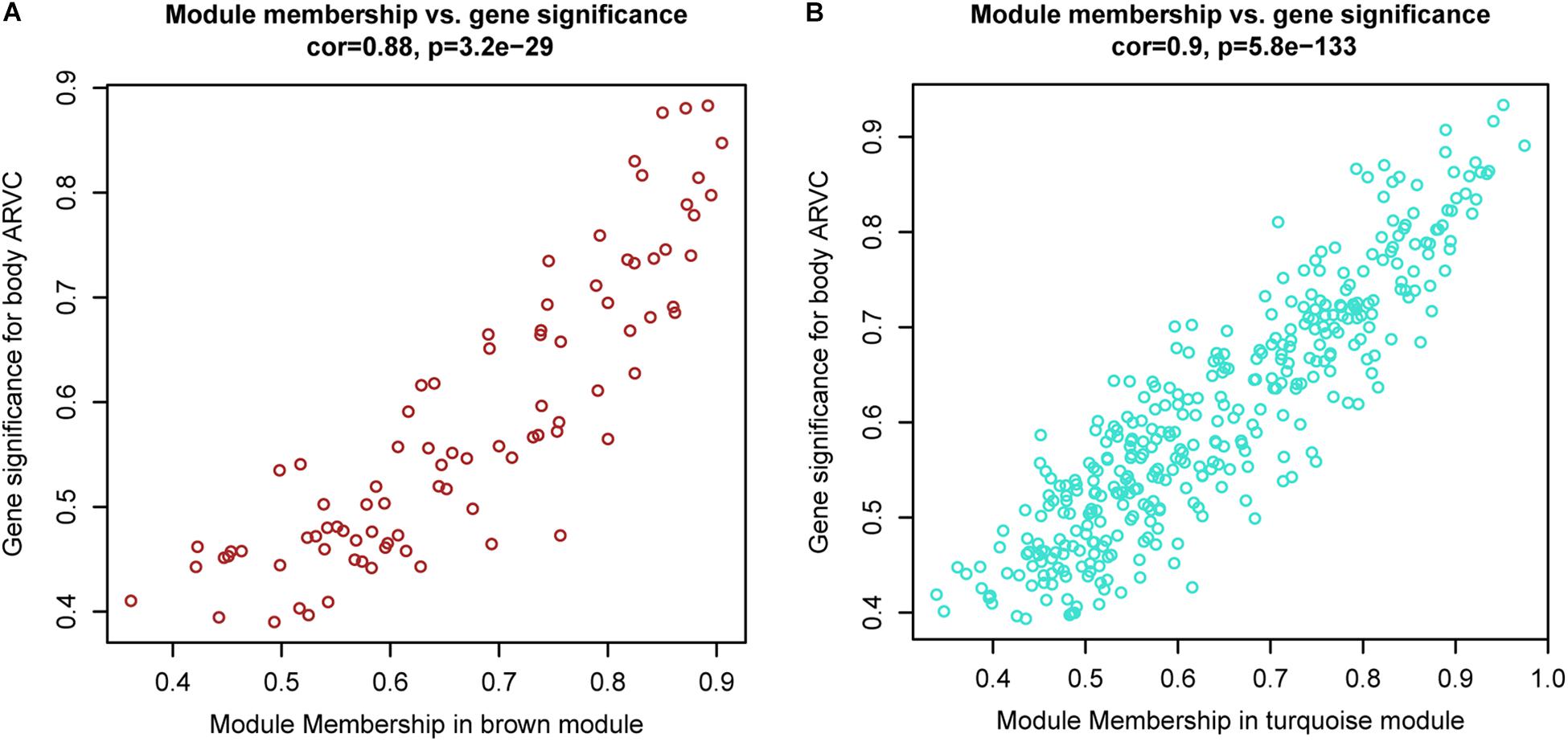
Figure 6. Scatterplots showing gene significance versus module membership for the brown (A) and turquoise (B) modules.
To find out the vital pathways and hub genes contained in the coexpression modules, we used the function GSNCA test (Rahmatallah et al., 2014) of GSAR package (Rahmatallah et al., 2017b). We found that GSNCA identified four key pathways and their hub genes (p < 0.05, Supplementary Table S3). The cytokine-cytokine receptor interaction, chemokine signaling pathway, JAK-STAT signaling pathway, and neuroactive ligand–receptor interaction were identified in the ARVC samples as key pathways (Figure 7). The MST2 plot for ARVC samples demonstrates that CXCL2 is comparatively highly associated between with lots of other genes within the chemokine signaling pathway (Figure 7A). The same are true for the TNFRSF11B, LIFR, and C5AR1 gene in the cytokine–cytokine receptor interaction pathway (Figure 7B), JAK-STAT signaling pathway (Figure 7C), as well as the neuroactive ligand–receptor interaction (Figure 7D), respectively. The w-values of them are decreased within control samples. The pattern may indicate regulatory roles of these genes in ARVC samples that are lost in the control samples. Even though the four genes lost the high w-values within control samples, these genes were still close to each other within structure of MST2 in control group, this indicates that correlation of them with other genes was not entirely lost, instead, it was reduced.
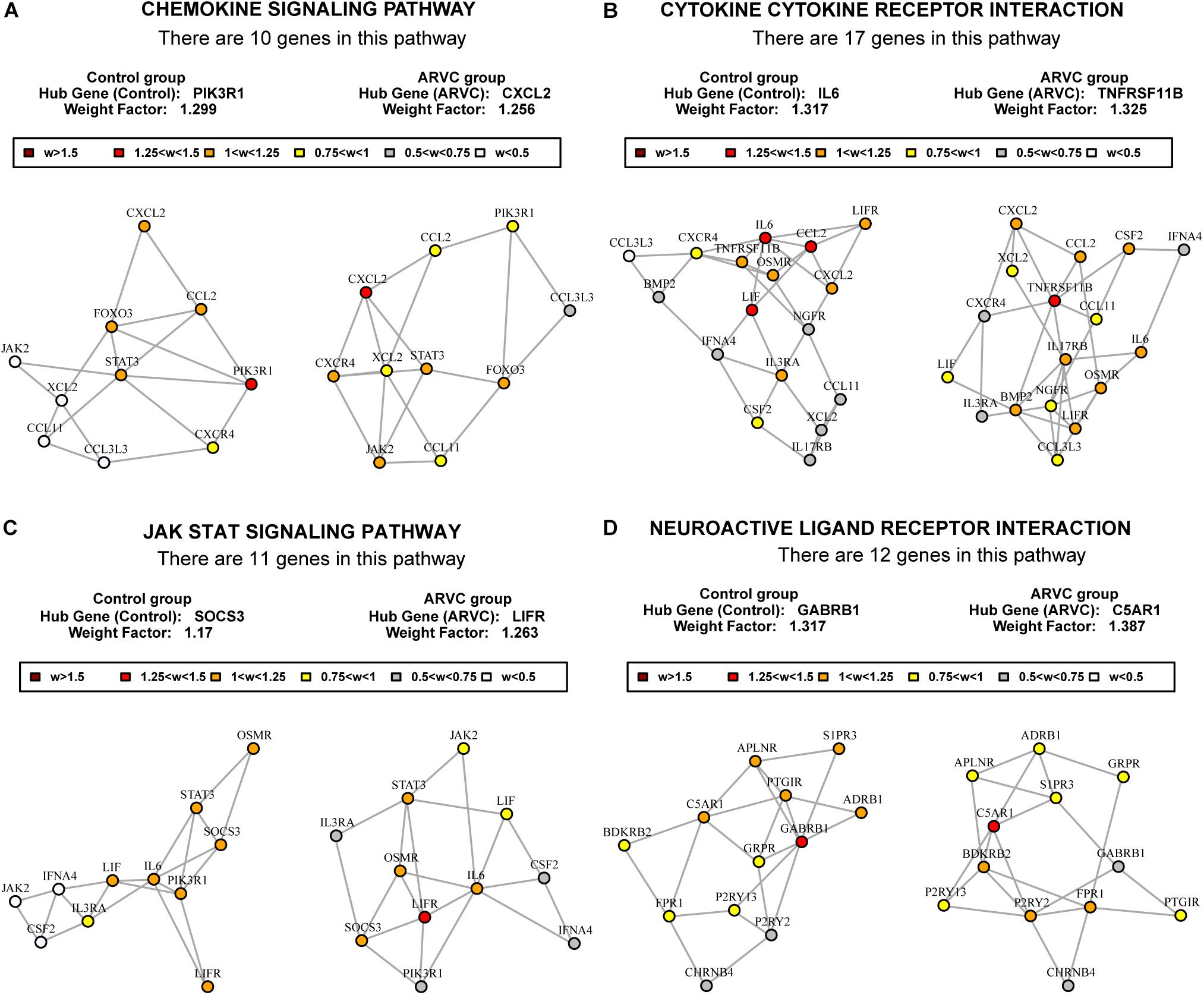
Figure 7. MST2s plot of the four key pathways correlation network. This plot was produced by package GSAR to illustrate the most highly correlated pathways and their hub genes of the two modules in both control samples and ARVC samples. Four ARVC state related biological pathways were identified by GSNCA (A–D).
As we described earlier, after combined WGCNA and GSNCA test analysis filtering, the four key pathways and four genes (CXCL2, TNFRSF11B, LIFR, and C5AR1) in ARVC samples were identified, and they were entered t-tests subsequently, and their results showed significant differences (all p < 0.05, Figure 8A) between two groups. The AUC areas of the above genes were all greater than 0.8 (Figure 8B), and the four genes with a high correlation (|r| > 0.6, Table 1), suggesting that they might be good diagnostic biomarkers of ARVC.
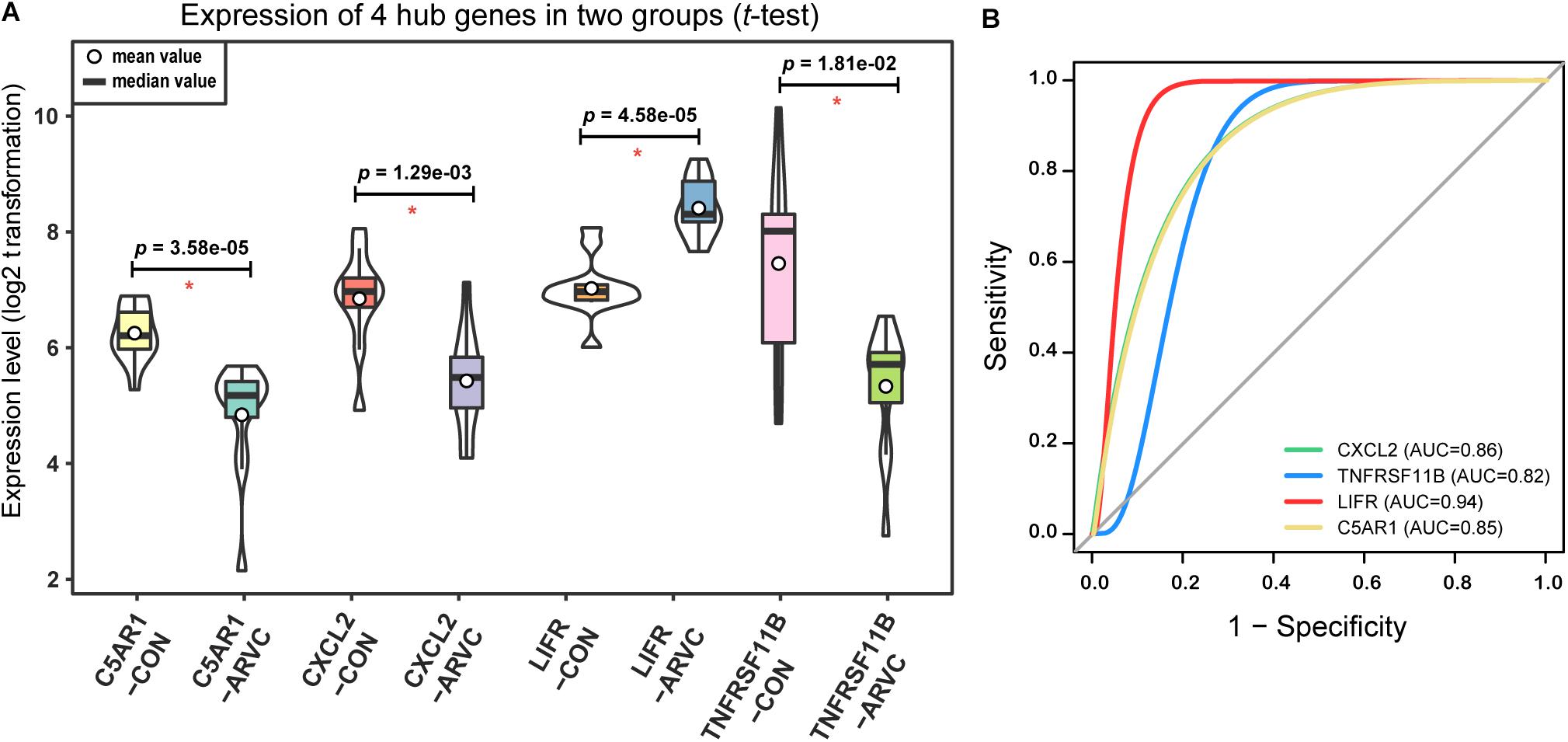
Figure 8. Hub genes validation. (A) Violin plot of the four correlated hub genes (C5AR1, CXCL2, LIFR, and TNFRSF11B) expression between ARVC group and control group. The violin plot showed the mean value, median value (while circle and black horizontal band, respectively), and range (black thin vertical line). The curve on the sides provided the approximate frequency distribution at each expression level. The p-values of the t-test were marked on the black lines. (B) ROC curves and AUC areas were used for evaluating the efficiency of diagnosis of these four hub genes (C5AR1, CXCL2, LIFR, and TNFRSF11B). They all be with high AUC areas (AUC > 0.8).
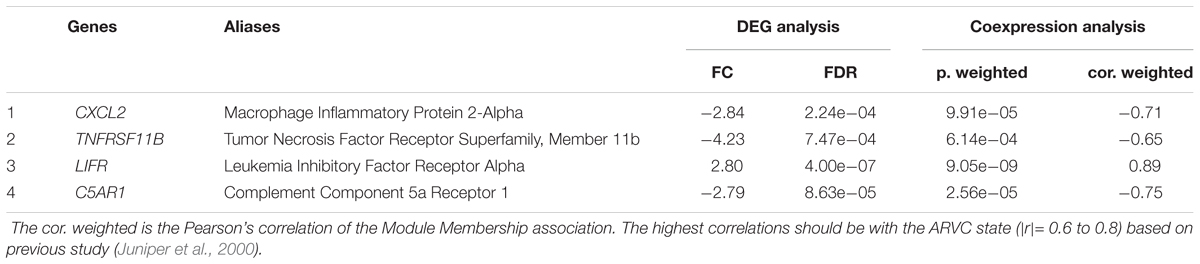
Table 1. Potential hub genes related to the ARVC state.
Sudden cardiac arrest might be ARVC’s first manifestation. It has a variable clinical course and is biologically heterogeneous. Therefore, understanding the molecular mechanisms of ARVC is crucial for early diagnosis, which helps make effective therapy of ICD. Endomyocardial biopsy is invasive, so obtaining myocardial tissue from ARVC patients is very difficult in clinical practice. In the research, we explored GSE29819 gene expression profile with 12 ARVC specimens (including all heart right and left ventricular myocardial samples) and 12 non-failing donor myocardial samples for exploring ARVC molecular mechanism and discover four hub genes and key pathways, which may be meaningful candidate therapeutic targets based on bioinformatic analysis.
As far as we know, this is the first attempt to combine WGCNA with GSNCA methods for identifying hub genes to be biomarkers able to distinguish ARVC from the non-failing control group. In this study, the results showed that there were a total of 619 DEGs (263 upregulated genes and 356 downregulated genes) between non-failing donor myocardial samples and ARVC tissues (FDR < 0.05). The PCA score trajectory plots showed apparent differences resulting from ARVC and the control group. WGCNA analysis used coexpression patterns to identify the two gene modules (brown and turquoise) as being most significantly associated with ARVC state. The sample traits obtained from our raw data were ARVC status, gender and ventricle, follow by the gene modules (brown and turquoise) related to ARVC status were further analyzed according to the prompts in Figure 5. Then the ARVC-related four key biological pathways (cytokine–cytokine receptor interaction, chemokine signaling pathway, JAK-STAT signaling pathway, and neuroactive ligand–receptor interaction) and four hub genes (CXCL2, TNFRSF11B, LIFR, and C5AR1) in ARVC samples were identified by GSNCA method. Together, the results suggest that the new candidate genes from modules might be added on biomarker list of ARVC state that is known at present, and hence suggest that the genes and their pathways require further analysis.
This study used two bioinformatics analysis methods, WGCNA and GSNCA. WGCNA is a system biology method that constructs a coexpression network on the basis of expression profiles’ similarity within a sample, providing global interpretation of gene expression information (Langfelder and Horvath, 2008). The WGCNA algorithm was utilized for identifying the involved biological pathways, disease-related genes, and therapeutic targets, like a familial combination of hyperlipidemia (Plaisier et al., 2009), pemphigus and systemic lupus erythematosus (Sezin et al., 2017), and rheumatoid arthritis (Sumitomo et al., 2018). Briefly, WGCNA is designed to uncover highly correlated gene modules and to relate gene clusters to one another and to sample traits. In recent studies, it has been verified in previous sample characteristics such as disease status (Yan et al., 2018), gender (Fatima et al., 2018), age (Maffei et al., 2017), and BMI (Wang W. et al., 2017). It was also proved that it was a reliable and promising instrument for cardiovascular diseases’ clinical diagnosis (Chen et al., 2016) and cardiomyocyte differentiation (Liu et al., 2017). The second method is GSNCA. Currently, although GSA methods have been published in some literature, their test hypotheses have not been fully studied. For instance, Gene Set Coexpression Analysis (GSCA) aggregates differences of pairwise correlations between the two conditions coexpression (Choi and Kendziorski, 2009), while other approaches, like differentially coexpressed gene sets (dCoxS), aggregate differences within relative entropy (Cho et al., 2009). In this study, package GSAR (Rahmatallah et al., 2017b) offers one set of approaches to testing multivariate null hypothesis against particular alternatives, which including the net correlation structure (function GSNCA test). GSNCA test is a method for analysis on differentially coexpressed pathways, and evaluates significance of genes within pathways as well. It examines the concordance and regulatory relations between expressions of genes vary between the phenotypes based on unchanged net correlation structure (Rahmatallah et al., 2014). Other approaches, like Coexpression Graph Analysis (CoGA) identify co-expressed gene sets through testing spectral distribution equality, it compares two networks’ structural property by using Jensen-Shannon divergence to be one measure of distance between the distribution of graphs, and establishes one full network from the pairwise correlation coexpression (Santos Sde et al., 2015; de Assis et al., 2018). However, in GSNCA, differences do not exist within vectors of gene weight between the two conditions, and MSTs of correlation network are used for examining changes of correlation structure of one gene set between the two conditions, and the most influential (hub) genes are highlighted (Rahmatallah et al., 2014). This is the methodological basis used in this study (Figure 7) and previous researches (Mousavian et al., 2017; Rahmatallah et al., 2017a).
The balance between apoptotic and protective mechanism of cardiomyocytes can be decided by some signaling pathway networks. According to the GSNCA analysis on the genes within two modules (Figure 7), we found that the ARVC state related biological pathways were significantly enriched in the cytokine–cytokine receptor interaction, chemokine signaling pathway, JAK-STAT signaling pathway, and neuroactive ligand–receptor interaction pathway. An amount of research mentioned the close relation between the above processes and cardiomyopathy or cardiovascular disease. At present, the first three pathways have been confirmed in other non-ARVC cardiomyopathy. Chemokine receptors and chemokines control leukocyte migration in process of inflammation and they are involved into heart inflammation and dysfunction, and cardiac myocytes themselves also can produce inflammatory mediators (Nian et al., 2004; Rohini et al., 2010). Some studies reported that the genetic variants of chemokine receptors and chemokines are weakly but importantly related to chagasic cardiomyopathy development (Cunha-Neto et al., 2009; Florez et al., 2012), an inflammatory dilated cardiomyopathy that is. Additionally, Pilichou et al. (2009) demonstrated that the necrosis of myocytes is principal initiator of the myocardial damage within ARVC, which includes one inflammatory response as well as massive calcification in myocardium, followed by repair of injury that has replacement of fibrous tissue, and the myocardial atrophy. Asimaki et al. (2011) also reported that some cytokines from the myocardium might be involved in the destruction of desmosomal proteins and arrhythmias in ARVC. These studies demonstrate the relevance of chemokines and cytokine receptors in cardiomyopathy, and increase the reliability of this study with regard to the frequent manifestations of differential enrichment in chemokine and inflammatory factor pathways. In addition, previous study has shown that alteration within Janus kinase (JAK)-signal transducer and activator of transcription (STAT) signaling within patients suffering from end stage dilated cardiomyopathy (Podewski et al., 2003). JAK/STAT pathway can effect cardioprotective or proapoptotic gene expression (Gross et al., 2006). Recent studies have shown that cardiac fibrosis and heart failure can be attenuated by JAK/STAT signaling pathway (Al-Rasheed et al., 2016; Liu et al., 2018). The above studies link the JAK/STAT pathway to the cardiomyopathy. Therefore, early attention to the balance of relevant pathways can improve long-run prognosis of people suffering from cardiomyopathy, including those with ARVC. Although the correlation between the last neuroactive ligand receptor interaction pathway and cardiovascular disease has not been reported, this pathway may be a new idea for further study of the ARVC mechanism.
In addition, the four hub genes (CXCL2, TNFRSF11B, LIFR, and C5AR1) with a high correlations (|r| > 0.6, Table 1) were associated with these above four vital signaling pathways in ARVC samples (Figure 7). CXCL2 (also known as macrophage inflammatory protein, MIP-2) is part of one chemokine superfamily encoding secreted proteins that are involved into inflammatory and immunoregulatory process, and released by various cells to respond toward injury or infection, and was detected originally within the macrophages to one part of the responses toward the inflammatory stimuli (Charo and Ransohoff, 2006). Recent genome-wide association studies have recognized CXCL2-related loci related to coronary artery disease risk (McPherson and Davies, 2012). Its role in the cardiovascular field is mostly related to inflammation, it suggested an abnormality in the inflammatory state of ARVC patients, which was also consistently with the reported that patchy inflammatory infiltrates in the right ventricular using autopsy and myocardial biopsy (Campuzano et al., 2012). TNFRSF11B is member 11B, tumor necrosis factor receptor superfamily, expressed within lymphoid cells as well as up-regulated by the stimulation of CD40, involved within the osteoclastogenesis, it is recognized as one candidate cardiovascular disease gene by human protein atlas, and it might also work in arterial calcification prevention (Harper et al., 2016). C5AR1 (Complement C5a Receptor 1) is an important member of the complement system. Studies reported that modulation of complement system could serve as one target for arrhythmogenic cardiomyopathy treatment (Mavroidis et al., 2015), and its signaling pathway upon blood macrophages/monocytes plays one role of pathology in Ang II-induced cardiac remodeling and inflammation (Zhang et al., 2014). LIFR gene encodes one protein belonging to the family of type I cytokine receptors. Previous studies have reported that LIFR gene is one of the important differential genes in the JAK-STAT signaling pathway in people suffering from end stage dilated cardiomyopathy (Podewski et al., 2003). LIF and its receptor also involved in modulating endoderm of embryoid bodies to promote cardiomyogenesis (Bader et al., 2001). Therefore, we suspect that the performance of myocardial cell electrophysiological disorders and cardiac remodeling deficiency in ARVC patients may be related to the above genes. Although the role in ARVC studies of the above hub genes had not yet been demonstrated, their necessary functions and related pathways in the cardiovascular field was emphasized in the results of this study and provided further insights into exploration in the ARVC field. However, further experimental work is required for establishing which candidate discussed above predominantly contributes to ARVC state.
Similarly, our study also has some limitations. Firstly, our conclusions are capable of being applied into one restricted population in ARVC patients as well as non-failing heart donors, but it is not proper to apply our findings to other non-ARVC patients with similar symptoms, including dilated cardiomyopathy patients. Secondly, histopathological changes in ARVC are progressive procedure. The participant samples with ARVC in this research were prepared from the hearts explanted in orthotopic heart transplantation representing the myocardium from patients with end stage heart failure. Our research lacked early-stage of ARVC patients; thus, the results may not be representative with they are applied into ARVC differential diagnosis at early stages. At last, only one genetic dataset from human ARVC heart tissues, the GSE29818 dataset, was searched from the web databases and analyzed in our study, we lacked rigorous testing data. Despite this, the hub gene analysis also gave further research directions for the diagnosis of ARVC.
In conclusion, our research described hub genes as well as key pathways which might be involved into ARVC diagnosis, utilizing bioinformatics-based WGCNA combine with GSNCA for constructing gene coexpression networks. Even though further experimental validation is required for the implication by association, our findings demonstrate that the computational methods based on systems biology might complement traditional gene-wise approaches, and as such, might offer a new insight in therapeutic intervention within rare diseases of people like ARVC.
PC contributed in conceptualization, methodology, data curation, writing, original draft preparation, and visualization. PC and YX contributed in formal analysis. PC and WW contributed in writing the review and editing. BL, WW, and SZ contributed in supervision. WW and SZ contributed in project administration. WW and YZ acquired the funding.
The manuscript was funded by the National Key Research and Development Program of China (2016YFC0901501 and 2016YFC0905102) and CAMS Innovation Fund for Medical Sciences (CIFMS) (2017-I2M-2-002).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2018.01778/full#supplementary-material
TABLE S1 | 619 DEGs in ARVC tissues.
TABLE S2 | DEGs in WGCNA modules.
TABLE S3 | Result_MST of GSNCA.
Al-Rasheed, N. M., Al-Rasheed, N. M., Hasan, I. H., Al-Amin, M. A., Al-Ajmi, H. N., and Mahmoud, A. M. (2016). Sitagliptin attenuates cardiomyopathy by modulating the JAK/STAT signaling pathway in experimental diabetic rats. Drug Des. Dev. Ther. 10, 2095–2107. doi: 10.2147/dddt.S109287
Asimaki, A., Tandri, H., Duffy, E. R., Winterfield, J. R., Mackey-Bojack, S., Picken, M. M., et al. (2011). Altered desmosomal proteins in granulomatous myocarditis and potential pathogenic links to arrhythmogenic right ventricular cardiomyopathy. Circ. Arrhythm. Electrophysiol. 4, 743–752. doi: 10.1161/circep.111.964890
Bader, A., Gruss, A., Hollrigl, A., Al-Dubai, H., Capetanaki, Y., and Weitzer, G. (2001). Paracrine promotion of cardiomyogenesis in embryoid bodies by LIF modulated endoderm. Differentiation 68, 31–43. doi: 10.1046/j.1432-0436.2001.068001031.x
Bagnall, R. D., Weintraub, R. G., Ingles, J., Duflou, J., Yeates, L., Lam, L., et al. (2016). A prospective study of sudden cardiac death among children and young adults. N. Engl. J. Med. 374, 2441–2452. doi: 10.1056/NEJMoa1510687
Barabasi, A. L. (2009). Scale-free networks: a decade and beyond. Science 325, 412–413. doi: 10.1126/science.1173299
Bhonsale, A., Groeneweg, J. A., James, C. A., Dooijes, D., Tichnell, C., Jongbloed, J. D., et al. (2015). Impact of genotype on clinical course in arrhythmogenic right ventricular dysplasia/cardiomyopathy-associated mutation carriers. Eur. Heart J. 36, 847–855. doi: 10.1093/eurheartj/ehu509
Boileau, A., Lalem, T., Vausort, M., Zhang, L., and Devaux, Y. (2018). A 3-gene panel improves the prediction of left ventricular dysfunction after acute myocardial infarction. Int. J. Cardiol. 254, 28–35. doi: 10.1016/j.ijcard.2017.10.109
Calkins, H., Corrado, D., and Marcus, F. (2017). Risk stratification in arrhythmogenic right ventricular cardiomyopathy. Circulation 136, 2068–2082. doi: 10.1161/circulationaha.117.030792
Campuzano, O., Alcalde, M., Iglesias, A., Barahona-Dussault, C., Sarquella-Brugada, G., Benito, B., et al. (2012). Arrhythmogenic right ventricular cardiomyopathy: severe structural alterations are associated with inflammation. J. Clin. Pathol. 65, 1077–1083. doi: 10.1136/jclinpath-2012-201022
Charo, I. F., and Ransohoff, R. M. (2006). The many roles of chemokines and chemokine receptors in inflammation. N. Engl. J. Med. 354, 610–621. doi: 10.1056/NEJMra052723
Chen, J., Yu, L., Zhang, S., and Chen, X. (2016). Network analysis-based approach for exploring the potential diagnostic biomarkers of acute myocardial infarction. Front. Physiol. 7:615. doi: 10.3389/fphys.2016.00615
Cho, S. B., Kim, J., and Kim, J. H. (2009). Identifying set-wise differential co-expression in gene expression microarray data. BMC Bioinformatics 10:109. doi: 10.1186/1471-2105-10-109
Choi, Y., and Kendziorski, C. (2009). Statistical methods for gene set co-expression analysis. Bioinformatics 25, 2780–2786. doi: 10.1093/bioinformatics/btp502
Corrado, D., Link, M. S., and Calkins, H. (2017). Arrhythmogenic right ventricular cardiomyopathy. N. Engl. J. Med. 376, 61–72. doi: 10.1056/NEJMra1509267
Cunha-Neto, E., Nogueira, L. G., Teixeira, P. C., Ramasawmy, R., Drigo, S. A., Goldberg, A. C., et al. (2009). Immunological and non-immunological effects of cytokines and chemokines in the pathogenesis of chronic Chagas disease cardiomyopathy. Mem. Inst. Oswaldo Cruz 104(Suppl. 1), 252–258. doi: 10.1590/S0074-02762009000900032
Dalal, D., Nasir, K., Bomma, C., Prakasa, K., Tandri, H., Piccini, J., et al. (2005). Arrhythmogenic right ventricular dysplasia: a United States experience. Circulation 112, 3823–3832. doi: 10.1161/circulationaha.105.542266
de Assis, L. V. M., Kinker, G. S., Moraes, M. N., Markus, R. P., Fernandes, P. A., and Castrucci, A. M. L. (2018). Expression of the circadian clock gene BMAL1 positively correlates with antitumor immunity and patient survival in metastatic melanoma. Front. Oncol. 8:185. doi: 10.3389/fonc.2018.00185
El Khouli, R. H., Macura, K. J., Barker, P. B., Habba, M. R., Jacobs, M. A., and Bluemke, D. A. (2009). Relationship of temporal resolution to diagnostic performance for dynamic contrast enhanced MRI of the breast. J. Magn. Reson. Imaging 30, 999–1004. doi: 10.1002/jmri.21947
Fatima, A., Connaughton, R., Weiser, A., Murphy, A., O’Grada, C., Ryan, M., et al. (2018). Weighted gene co-expression network analysis identifies gender specific modules and hub genes related to metabolism and inflammation in response to an acute lipid challenge. Mol. Nutr. Food Res. 62:1700388. doi: 10.1002/mnfr.201700388
Finocchiaro, G., Papadakis, M., Robertus, J. L., Dhutia, H., Steriotis, A. K., Tome, M., et al. (2016). Etiology of sudden death in sports: insights from a united kingdom regional registry. J. Am. Coll. Cardiol. 67, 2108–2115. doi: 10.1016/j.jacc.2016.02.062
Florez, O., Martin, J., and Gonzalez, C. I. (2012). Genetic variants in the chemokines and chemokine receptors in Chagas disease. Hum. Immunol. 73, 852–858. doi: 10.1016/j.humimm.2012.04.005
Gautier, L., Cope, L., Bolstad, B. M., and Irizarry, R. A. (2004). affy–analysis of affymetrix genechip data at the probe level. Bioinformatics 20, 307–315. doi: 10.1093/bioinformatics/btg405
Gross, E. R., Hsu, A. K., and Gross, G. J. (2006). The JAK/STAT pathway is essential for opioid-induced cardioprotection: JAK2 as a mediator of STAT3, Akt, and GSK-3 beta. Am. J. Physiol. Heart Circ. Physiol. 291, H827–H834. doi: 10.1152/ajpheart.00003.2006
Gupta, R., Tichnell, C., Murray, B., Rizzo, S., Te Riele, A., Tandri, H., et al. (2017). Comparison of features of fatal versus nonfatal cardiac arrest in patients with arrhythmogenic right ventricular dysplasia cardiomyopathy. Am. J. Cardiol. 120, 111–117. doi: 10.1016/j.amjcard.2017.03.251
Harper, E., Forde, H., Davenport, C., Rochfort, K. D., Smith, D., and Cummins, P. M. (2016). Vascular calcification in type-2 diabetes and cardiovascular disease: integrative roles for OPG, RANKL and TRAIL. Vascul. Pharmacol. 82, 30–40. doi: 10.1016/j.vph.2016.02.003
Horvath, S., and Dong, J. (2008). Geometric interpretation of gene coexpression network analysis. PLoS Comput. Biol. 4:e1000117. doi: 10.1371/journal.pcbi.1000117
Juniper, E. F., O’Byrne, P. M., Ferrie, P. J., King, D. R., and Roberts, J. N., (2000). Measuring asthma control. Clinic questionnaire or daily diary? Am. J. Respir. Crit. Care Med. 162, 1330–1334. doi: 10.1164/ajrccm.162.4.9912138
Langfelder, P., and Horvath, S. (2008). WGCNA: an R package for weighted correlation network analysis. BMC Bioinformatics 9:559. doi: 10.1186/1471-2105-9-559
Langfelder, P., and Horvath, S. (2017). WGCNA Package: Frequently Asked Questions WWW Document. Available at: https://horvath.genetics.ucla.edu/html/CoexpressionNetwork/Rpackages/WGCNA/faq.html [accessed December 24, 2017].
Liu, M., Li, Y., Liang, B., Li, Z., Jiang, Z., Chu, C., et al. (2018). Hydrogen sulfide attenuates myocardial fibrosis in diabetic rats through the JAK/STAT signaling pathway. Int. J. Mol. Med. 41, 1867–1876. doi: 10.3892/ijmm.2018.3419
Liu, Q., Jiang, C., Xu, J., Zhao, M. T., Van Bortle, K., Cheng, X., et al. (2017). Genome-wide temporal profiling of transcriptome and open chromatin of early cardiomyocyte differentiation derived from hiPSCs and hESCs. Circ. Res. 121, 376–391. doi: 10.1161/circresaha.116.310456
Maffei, V., Kim, S., Blanchard, E., Luo, M., Jazwinski, S., Taylor, C., et al. (2017). Biological aging and the human gut microbiota. J. Gerontol. A Biol. Sci. Med. Sci. 72, 1474–1482. doi: 10.1093/gerona/glx042
Marcus, F. I., Fontaine, G. H., Guiraudon, G., Frank, R., Laurenceau, J. L., Malergue, C., et al. (1982). Right ventricular dysplasia: a report of 24 adult cases. Circulation 65, 384–398. doi: 10.1161/01.CIR.65.2.384
Mason, M. J., Fan, G., Plath, K., Zhou, Q., and Horvath, S. (2009). Signed weighted gene co-expression network analysis of transcriptional regulation in murine embryonic stem cells. BMC Genomics 10:327. doi: 10.1186/1471-2164-10-327
Mavroidis, M., Davos, C. H., Psarras, S., Varela, A., Athanasiadis, N., Katsimpoulas, M., et al. (2015). Complement system modulation as a target for treatment of arrhythmogenic cardiomyopathy. Basic Res. Cardiol. 110:27. doi: 10.1007/s00395-015-0485-6
McPherson, R., and Davies, R. W. (2012). Inflammation and coronary artery disease: insights from genetic studies. Can. J. Cardiol. 28, 662–666. doi: 10.1016/j.cjca.2012.05.014
Molina, C. E., Jacquet, E., Ponien, P., Munoz-Guijosa, C., Baczko, I., Maier, L. S., et al. (2018). Identification of optimal reference genes for transcriptomic analyses in normal and diseased human heart. Cardiovasc. Res. 114, 247–258. doi: 10.1093/cvr/cvx182
Mousavian, Z., Nowzari-Dalini, A., Stam, R. W., Rahmatallah, Y., and Masoudi-Nejad, A. (2017). Network-based expression analysis reveals key genes related to glucocorticoid resistance in infant acute lymphoblastic leukemia. Cell Oncol. 40, 33–45. doi: 10.1007/s13402-016-0303-7
Nian, M., Lee, P., Khaper, N., and Liu, P. (2004). Inflammatory cytokines and postmyocardial infarction remodeling. Circ. Res. 94, 1543–1553. doi: 10.1161/01.RES.0000130526.20854.fa
Peters, S., Trummel, M., and Meyners, W. (2004). Prevalence of right ventricular dysplasia-cardiomyopathy in a non-referral hospital. Int. J. Cardiol. 97, 499–501. doi: 10.1016/j.ijcard.2003.10.037
Pilichou, K., Remme, C. A., Basso, C., Campian, M. E., Rizzo, S., Barnett, P., et al. (2009). Myocyte necrosis underlies progressive myocardial dystrophy in mouse dsg2-related arrhythmogenic right ventricular cardiomyopathy. J. Exp. Med. 206, 1787–1802. doi: 10.1084/jem.20090641
Plaisier, C. L., Horvath, S., Huertas-Vazquez, A., Cruz-Bautista, I., Herrera, M. F., Tusie-Luna, T., et al. (2009). A systems genetics approach implicates USF1, FADS3, and other causal candidate genes for familial combined hyperlipidemia. PLoS Genet. 5:e1000642. doi: 10.1371/journal.pgen.1000642
Podewski, E. K., Hilfiker-Kleiner, D., Hilfiker, A., Morawietz, H., Lichtenberg, A., Wollert, K. C., et al. (2003). Alterations in Janus kinase (JAK)-signal transducers and activators of transcription (STAT) signaling in patients with end-stage dilated cardiomyopathy. Circulation 107, 798–802. doi: 10.1161/01.CIR.0000057545.82749.FF
Rahmatallah, Y., Emmert-Streib, F., and Glazko, G. (2014). Gene Sets Net Correlations Analysis (GSNCA): a multivariate differential coexpression test for gene sets. Bioinformatics 30, 360–368. doi: 10.1093/bioinformatics/btt687
Rahmatallah, Y., Khaidakov, M., Lai, K. K., Goyne, H. E., Lamps, L. W., Hagedorn, C. H., et al. (2017a). Platform-independent gene expression signature differentiates sessile serrated adenomas/polyps and hyperplastic polyps of the colon. BMC Med. Genomics 10:81. doi: 10.1186/s12920-017-0317-7
Rahmatallah, Y., Zybailov, B., Emmert-Streib, F., and Glazko, G. (2017b). GSAR: bioconductor package for gene set analysis in R. BMC Bioinformatics 18:61. doi: 10.1186/s12859-017-1482-6
Rampazzo, A., Nava, A., Danieli, G. A., Buja, G., Daliento, L., Fasoli, G., et al. (1994). The gene for arrhythmogenic right ventricular cardiomyopathy maps to chromosome 14q23-q24. Hum. Mol. Genet. 3, 959–962. doi: 10.1093/hmg/3.6.959
Ritchie, M. E., Phipson, B., Wu, D., Hu, Y., Law, C. W., Shi, W., et al. (2015). limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43:e47. doi: 10.1093/nar/gkv007
Rohini, A., Agrawal, N., Koyani, C. N., and Singh, R. (2010). Molecular targets and regulators of cardiac hypertrophy. Pharmacol. Res. 61, 269–280. doi: 10.1016/j.phrs.2009.11.012
Santos Sde, S., Galatro, T. F., Watanabe, R. A., Oba-Shinjo, S. M., Nagahashi Marie, S. K., and Fujita, A. (2015). CoGA: an r package to identify differentially co-expressed gene sets by analyzing the graph spectra. PLoS One 10:e0135831. doi: 10.1371/journal.pone.0135831
Sezin, T., Vorobyev, A., Sadik, C. D., Zillikens, D., Gupta, Y., and Ludwig, R. J. (2017). Gene expression analysis reveals novel shared gene signatures and candidate molecular mechanisms between pemphigus and systemic lupus erythematosus in CD4(+) T cells. Front. Immunol. 8:1992. doi: 10.3389/fimmu.2017.01992
Sikri, K., Duggal, P., Kumar, C., Batra, S. D., Vashist, A., Bhaskar, A., et al. (2018). Multifaceted remodeling by vitamin C boosts sensitivity of Mycobacterium tuberculosis subpopulations to combination treatment by anti-tubercular drugs. Redox Biol. 15, 452–466. doi: 10.1016/j.redox.2017.12.020
Sing, T., Sander, O., Beerenwinkel, N., and Lengauer, T. (2005). ROCR: visualizing classifier performance in R. Bioinformatics 21, 3940–3941. doi: 10.1093/bioinformatics/bti623
Sumitomo, S., Nagafuchi, Y., Tsuchida, Y., Tsuchiya, H., Ota, M., Ishigaki, K., et al. (2018). A gene module associated with dysregulated TCR signaling pathways in CD4(+) T cell subsets in rheumatoid arthritis. J. Autoimmune 89, 21–29. doi: 10.1016/j.jaut.2017.11.001
Tang, J., Kong, D., Cui, Q., Wang, K., Zhang, D., Gong, Y., et al. (2018). Prognostic genes of breast cancer identified by gene co-expression network analysis. Front. Oncol. 8:374. doi: 10.3389/fonc.2018.00374
Tang, Y., Ke, Z. P., Peng, Y. G., and Cai, P. T. (2018). Co-expression analysis reveals key gene modules and pathway of human coronary heart disease. J. Cell. Biochem. 119, 2102–2109. doi: 10.1002/jcb.26372
Tavazoie, S., Hughes, J. D., Campbell, M. J., Cho, R. J., and Church, G. M. (1999). Systematic determination of genetic network architecture. Nat. Genet. 22, 281–285. doi: 10.1038/10343
Theriault, S., Gaudreault, N., Lamontagne, M., Rosa, M., Boulanger, M. C., Messika-Zeitoun, D., et al. (2018). A transcriptome-wide association study identifies PALMD as a susceptibility gene for calcific aortic valve stenosis. Nat. Commun. 9:988. doi: 10.1038/s41467-018-03260-6
van Noort, V., Snel, B., and Huynen, M. A. (2004). The yeast coexpression network has a small-world, scale-free architecture and can be explained by a simple model. EMBO Rep. 5, 280–284. doi: 10.1038/sj.embor.7400090
Wang, T., He, X., Liu, X., Liu, Y., Zhang, W., Huang, Q., et al. (2017). Weighted gene co-expression network analysis identifies FKBP11 as a key regulator in acute aortic dissection through a NF-kB dependent pathway. Front. Physiol. 8:1010. doi: 10.3389/fphys.2017.01010
Wang, W., Jiang, W., Hou, L., Duan, H., Wu, Y., Xu, C., et al. (2017). Weighted gene co-expression network analysis of expression data of monozygotic twins identifies specific modules and hub genes related to BMI. BMC Genomics 18:872. doi: 10.1186/s12864-017-4257-6
Yan, S., Wang, W., Gao, G., Cheng, M., Wang, X., Wang, Z., et al. (2018). Key genes and functional coexpression modules involved in the pathogenesis of systemic lupus erythematosus. J. Cell Physiol. 223, 8815–8825. doi: 10.1002/jcp.26795
Yip, A. M., and Horvath, S. (2007). Gene network interconnectedness and the generalized topological overlap measure. BMC Bioinformatics 8:22. doi: 10.1186/1471-2105-8-22
Yuan, L., Qian, G., Chen, L., Wu, C. L., Dan, H. C., Xiao, Y., et al. (2018). Co-expression network analysis of biomarkers for adrenocortical carcinoma. Front. Genet. 9:328. doi: 10.3389/fgene.2018.00328
Zhang, C., Li, Y., Wang, C., Wu, Y., Cui, W., Miwa, T., et al. (2014). Complement 5a receptor mediates angiotensin II-induced cardiac inflammation and remodeling. Arterioscler. Thromb. Vasc. Biol. 34, 1240–1248. doi: 10.1161/atvbaha.113.303120
Keywords: arrhythmogenic right ventricular cardiomyopathy, weighted gene coexpression network analysis, biomarker, differentially expressed genes, gene set net correlations analysis
Citation: Chen P, Long B, Xu Y, Wu W and Zhang S (2018) Identification of Crucial Genes and Pathways in Human Arrhythmogenic Right Ventricular Cardiomyopathy by Coexpression Analysis. Front. Physiol. 9:1778. doi: 10.3389/fphys.2018.01778
Received: 11 July 2018; Accepted: 23 November 2018;
Published: 06 December 2018.
Edited by:
Luis Mendoza, National Autonomous University of Mexico, MexicoReviewed by:
Carlos Espinosa-Soto, Universidad Autónoma de San Luis Potosí, MexicoCopyright © 2018 Chen, Long, Xu, Wu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei Wu, Y2Ftc3d3QGhvdG1haWwuY29t Shuyang Zhang, c2h1eWFuZ3poYW5nMTAzQG5yZHJzLm9yZw==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.