 Frederic von Wegner
Frederic von Wegner
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Physiol. , 11 October 2018
Sec. Fractal Physiology
Volume 9 - 2018 | https://doi.org/10.3389/fphys.2018.01382
This article is part of the Research Topic Nonlinearity in Living Systems: Theoretical and Practical Perspectives on Metrics of Physiological Signal Complexity View all 21 articles
An information-theoretic approach to numerically determine the Markov order of discrete stochastic processes defined over a finite state space is introduced. To measure statistical dependencies between different time points of symbolic time series, two information-theoretic measures are proposed. The first measure is time-lagged mutual information between the random variables Xn and Xn+k, representing the values of the process at time points n and n + k, respectively. The measure will be termed autoinformation, in analogy to the autocorrelation function for metric time series, but using Shannon entropy rather than linear correlation. This measure is complemented by the conditional mutual information between Xn and Xn+k, removing the influence of the intermediate values Xn+k−1, …, Xn+1. The second measure is termed partial autoinformation, in analogy to the partial autocorrelation function (PACF) in metric time series analysis. Mathematical relations with known quantities such as the entropy rate and active information storage are established. Both measures are applied to a number of examples, ranging from theoretical Markov and non-Markov processes with known stochastic properties, to models from statistical physics, and finally, to a discrete transform of an EEG data set. The combination of autoinformation and partial autoinformation yields important insights into the temporal structure of the data in all test cases. For first- and higher-order Markov processes, partial autoinformation correctly identifies the order parameter, but also suggests extended, non-Markovian effects in the examples that lack the Markov property. For three hidden Markov models (HMMs), the underlying Markov order is found. The combination of both quantities may be used as an early step in the analysis of experimental, non-metric time series and can be employed to discover higher-order Markov dependencies, non-Markovianity and periodicities in symbolic time series.
Information theory occupies a central role in time series analysis. The concept of entropy provides numerous important connections to statistical physics and thermodynamics, often useful in the interpretation of the results (Kullback, 1959; Cover and Thomas, 2006). Despite the large number of available measures, there is no generally accepted systematic procedure for the analysis of symbolic time series, although collections of theory and methods are readily available (Daw et al., 2003; Mézard and Montanari, 2009). In metric time series analysis however, a hierarchical set of analyses and tests has been established by Box and Jenkins (Box and Jenkins, 1976). The seminal work by these authors deals with autoregressive and moving average processes, some of the most prominent Markov processes across many fields of science (Häggström, 2002). The result is a standardized procedure for analyzing continuous valued, discrete time stochastic processes (Box and Jenkins, 1976). The procedure addresses the impressive complexity of possible stochastic processes by combining semi-quantitative, visual analysis steps with a number of rigorous statistical test procedures. The first step in Box-Jenkins analysis is the visual and statistical assessment of the autocorrelation function (ACF) and the partial autocorrelation function (PACF) of the data. In particular, the order of purely autoregressive processes can be directly deduced from the PACF coefficients. For a p-th order autoregressive process, it can be shown that PACF coefficients for time lags larger than p are equal to zero, within statistical limits.
Information-theoretical time series analysis is closely linked to the theory of Markov processes, as Markov processes are defined via their temporal dependencies. The elemental case is a first-order Markov process (Xn)n∈ℤ, for which the transition Xn → Xn+1 depends on the current state Xn only. Due to this property, first-order Markov processes are termed memory-less, as their past does not influence transitions to future states. Markov processes of order M generalize this property and have transition probabilities defined by M past states (Xn, …, Xn−M+1), thus representing finite memory effects of the time series. Using information-theoretical methods, memory effects and temporal dependencies can be quantified. A more formal treatment of Markov processes follows in the Materials and Methods section, after introducing the necessary notation.
To assess the Markov property of a time series, and to identify the Markov order of an empirical symbol sequence, classical statistics derives a number of tests as detailed in the Materials and Methods section (Hoel, 1954; Anderson and Goodman, 1957; Goodman, 1958; Billingsley, 1961; Kullback et al., 1962). We recently used the tests developed in (Kullback et al., 1962) to characterize electroencephalographic (EEG) data transformed into a symbolic time series termed microstate sequences (von Wegner and Laufs, 2018). Using time-lagged mutual information, we could show that the symbolic four-state sequences still retain periodic features of the underlying continuous EEG signal (von Wegner et al., 2017, 2018). The aim of the present article is to introduce partial autoinformation as a measure that is complementary to the time-lagged mutual information function, in the same sense that the PACF complements the autocorrelation function in classical time series analysis of continuous random variables. In the past, we have used the term autoinformation function (AIF) for time-lagged mutual information, in analogy with the autocorrelation function (ACF) of classical time series analysis (von Wegner et al., 2017). To continue the analogy, the newly introduced measure will be termed partial autoinformation function (PAIF), because it answers the same question about the information content of a symbolic time series as the partial autocorrelation function (PACF) does about correlations. The new measure is derived based on the analogy with the PACF and theoretical connections with well-known functionals such as the entropy rate and active information storage are established. Next, we apply the AIF/PAIF approach to a number of symbolic time series ranging from Markov and non-Markov model data with known properties to simulated data representing physical systems (Ising model, abstract ion channel model) and experimental EEG microstate data. Finally, limitations and possible applications are discussed for larger state spaces and finite samples.
To illustrate the motivation for this study, an exemplary autoregressive process is used to explain the principles of time series analysis with the (partial) autocorrelation approach. Autoregressive (AR) processes model time series of continuous random variables in discrete time (Box and Jenkins, 1976). The p-th order or AR(p) process models the dependency of Xn on its past via a linear combination of the p values preceding Xn:
where ϕ1, …, ϕp are called the autoregression coefficients and εn represents identically and independently distributed (iid) Gaussian noise.
The linear dependencies created by Equation (1) can be quantified by the time autocorrelation function (ACF). The ACF coefficients ρk of a stationary stochastic process Xn are defined as:
where denotes Pearson's correlation coefficient. The ACF coefficients describe the linear correlation between process values at two different time steps Xn and Xn+k, without taking into account the effect of the intermediate time steps Xn+k−1, …, Xn+1. However, Xn could be correlated with Xn+k directly, independent of the intermediate values, or the correlation between Xn and Xn+k could be conveyed via the intermediate values and vanish when conditioned on these intermediates. To distinguish these cases, the PACF performs a multivariate regression of Xn+k on all values Xn+k−1, …, Xn and finally records the conditioned or partial correlation between Xn and Xn+k, removing the effect of the intermediate values:
Continuous-valued, discrete time AR processes can be systematically assessed using the combination of the autocorrelation function and the PACF (Box and Jenkins, 1976). We here present an example using a third-order autoregressive process that is parametrized by:
with AR coefficients ϕ1 = 0.85, ϕ2 = −0.2 and ϕ3 = 0.1. Figure 1 shows the ACF/PACF analysis of a simulated sample path (N = 105 samples). The left panel, Figure 1A shows the exponentially decaying ACF. Though the analytical form of the ACF can be expressed in terms of the three AR coefficients, visual analysis does not allow to deduce the order of the AR process or the magnitude of the coefficients. The right panel, Figure 1B shows the PACF whose zero-lag coefficient φ00 = 1, by definition. The following three values φ11−33 directly reflect the relative magnitude and sign of the AR coefficients ϕ1−3. Thus, through PACF analysis, the AR(3) structure of the process can be conjectured from visual analysis already. In practice, the statistical significance of each coefficient can also be assessed quantitatively. In Figure 1, confidence intervals (α = 0.05) are shown in blue.
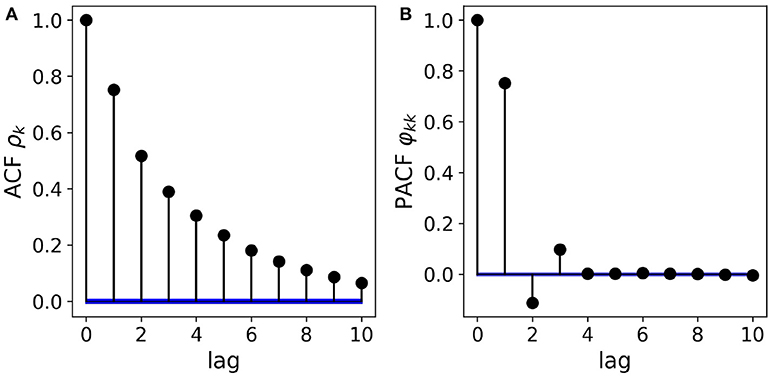
Figure 1. Partial autocorrelation analysis of a real-valued autoregressive process. (A) The AR(3) structure of the data cannot be deduced visually from the shape of the ACF, though the exponential decay can be parametrized exactly by the three AR coefficients. (B) Removing the effect of intermediate values, the PACF coefficients directly reflect the AR(3) structure as well as the magnitude and sign of the AR coefficients. Confidence intervals (α = 0.05) for the absence of correlations are shown in blue.
The classical Box-Jenkins approach to time series analysis considers the magnitude of ACF and PACF coefficients to guess the statistical structure of the data (Box and Jenkins, 1976). For a pure autoregressive process of order p, the PACF coefficients φkk vanish for k > p. In case of a pure moving average process, the expected value of the ACF coefficients ρk are zero for k > p. For mixed (ARMA) processes, the model orders cannot be determined visually. Although the pure AR model order can be deduced from the decay of the PACF, and the PACF coefficients φkk can be expressed in terms of the AR coefficients ϕk, the exact value of the AR coefficients ϕk cannot be derived visually, with the exception of a few simple low-order cases.
Information theory is rooted in mathematical statistics and uses entropy as one of its main concepts (Kullback, 1959). Entropy characterizes the shape of probability distributions and thereby, the amount of uncertainty or surprise associated with samples generated from the distribution. This section summarizes the concepts and definitions needed to derive the PAIF, more extensive treatments can be found in classical and more recent monographs (Kullback, 1959; Cover and Thomas, 2006; Mézard and Montanari, 2009). Connections of the PAIF with other information-theoretical quantities are derived in the first paragraph of the Results section. Logarithms are computed as log2, such that all information-theoretical quantities are measured in bits.
We here consider stochastic processes (Xn)n∈ℤ, i.e., sequences of random variables Xn, where each Xn takes values in some finite alphabet of L different symbols S = {s0, …, sL−1}. In practice, we deal with finite samples of the underlying process, (Xn)n = 0, …, N−1. In the following, contiguous data blocks starting from index n, and covering the past k values of the process, (Xn, Xn−1, …Xn−k+1) will be termed k-histories and are written as
Denoting a specific realization of the random variable Xi as xi, the joint probability distribution of k-histories is given by
where xi ∈ S, for all i = n − k + 1, …, n. In the following, the compact notation will be used.
The information content of a random variable X with possible values xi ∈ S and associated probabilities P(X = xi) = pi is measured by the Shannon entropy (Kullback, 1959). The information content of the joint distribution representing the k-history is measured by the joint entropy, which is defined as (Kullback, 1959; Cover and Thomas, 2006):
where the sum runs over all possible values of Xn = xn, …, Xn−k+1 = xn−k+1. The expression HX(n, k) contains the time parameter n, such that the expression for HX(n, k) can be used even in the case of non-stationary processes, whose statistical properties may depend on n. Under time-stationary conditions, the entropy is obtained by averaging over all time points and the resulting entropy will be abbreviated
where 〈·〉n denotes time averaging.
Adding information about the value of another random variable Y reduces the uncertainty about X, in case X and Y are statistically dependent. If X and Y are independent, the entropy of X does not change with the additional information about Y. To measure the influence of Y on X, conditional entropy is defined as H(X ∣ Y) = H(X, Y) − H(Y). In the following, two conditional entropy terms will be used.
The first term is a finite approximation to the entropy rate of the stochastic process X. The entropy rate hX of a process quantifies the amount of surprise about the next symbol Xn+1 emitted by the process, given knowledge about its past values . The theoretical or analytical value hX is defined via an infinitely long history
When working with finite experimental data samples, the entropy rate has to be estimated from finite k-histories (Runge et al., 2012; Barnett and Seth, 2015; Faes et al., 2015; Xiong et al., 2017):
Using the definition of conditional entropy, hX(n, k) can be computed from joint entropies as:
Following the notation used for Shannon entropy, the time-stationary expression for the entropy rate will be denoted hk = 〈 hX(n, k)〉n.
The second conditional entropy term used is the two-point conditional entropy H(Xn+k ∣ Xn), that measures the amount of information about Xn+k contained in Xn.
Next, mutual information between two random variables is defined as I(X; Y) = H(X) − H(X ∣ Y) and measures the information shared between both variables. Mutual information will be used to compute two quantities that are useful in characterizing symbol sequences.
First, active information storage (AIS) (Lizier et al., 2012) is complementary to the entropy rate. While the entropy rate measures how much information (or surprise) is contained in Xn+1, despite knowledge of its k-history , AIS measures the amount of common (or shared) information between Xn+1 and its k-history. The active information storage term for a history of length k is defined as
and the stationary expression is ak = < aX(n, k)>n.
For computational implementation, active information storage is decomposed into joint entropy terms:
The second mutual information term used is I(Xn+1; Xk), and yields an estimate of the statistical dependency between the random variables Xn and Xn+k. In a recent publication, we used the term autoinformation function (AIF) to denote the set of time-lagged mutual information terms computed for a number of time lags (von Wegner et al., 2017). The name AIF was derived from the formal analogy with the autocorrelation function (ACF) for metric time series. We defined the AIF coefficient at time lag k as:
and the stationary term is αk = < αX(n, k)>n. Rather than using linear correlation to measure the dependency between two time points, as the ACF does, the AIF employs mutual information between the random variables at time points n and n+k. The measure is symmetric, i.e., I(Xn; Xn+k) = I(Xn+k; Xn) and therefore does not contain directional information. In analogy to the autocorrelation function, division of all coefficients by αX(n, 0) normalizes the AIF to αX(n, 0) = 1. The computational cost is independent of the time lag k, as all entropies are computed from one-dimensional (H(Xn+k), H(Xn)) and two-dimensional (H(Xn+k, Xn)) distributions.
Finally, the definition of partial autoinformation, the central concept of this work, is based on the concept of conditional mutual information which includes a third random variable Z, on which the mutual information between X and Y is conditioned:
The information-theoretical match for the PACF should estimate the two-point dependency between Xn and Xn+k, while removing the influence of the intermediate variables . This is achieved by computing the conditional mutual information (Equation 15) between Xn and Xn+k, given .
We therefore define the PAIF coefficient πX(n, k) at time lag k as:
Using the definition of conditional mutual information in terms of conditional entropies, and the expression of conditional entropy in terms of joint entropies, the computation of πX(n, k) can be reduced to the estimation of joint entropies:
The stationary expression is
For the first two coefficients πX(n, 0) and πX(n, 1), there are no intermediate values to condition on. Analogous to the PACF algorithm, we set πX(n, 0) = αX(n, 0) and πX(n, 1) = αX(n, 1). The computational load increases exponentially with history length k, as the discrete joint distribution over L labels has Lk−1 elements.
The computation of the quantity of interest, the PAIF coefficients, is visualized in Figure 2. Above, the relationships between the quantities discussed here are shown as an information diagram, a special form of a Venn diagram. AIF coefficients are represented by the intersection of the two dark gray circles which represent H(Xn+k) and H(Xn), respectively. In the scheme below, where each element of the time series Xn is visualized as a square box, the AIF coefficients represent the shared information between Xn+k and Xn, without taking into account the effects of (light gray areas in the information diagram above and the symbolic sequence below). The PAIF corresponds to the part of I(Xn+k; Xn) that does not intersect with the lower circle, representing the intermediate values . The area that represents the PAIF is shown in dark blue in the information scheme.
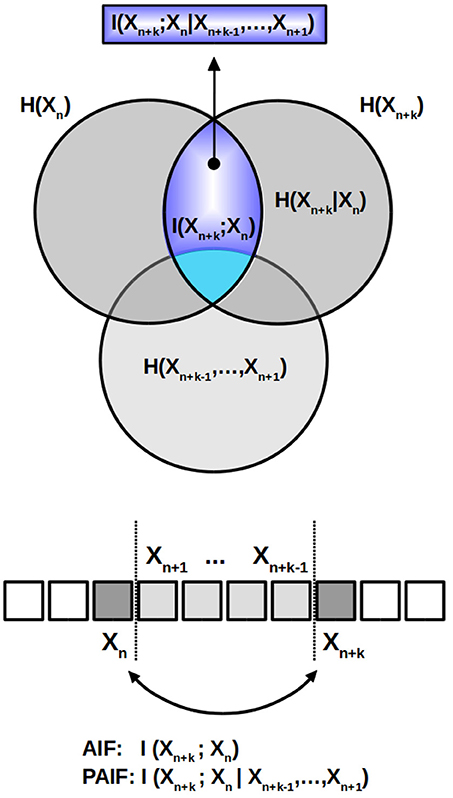
Figure 2. AIF/PAIF analysis. The information diagram above illustrates the partition of the total data entropy. The intersection of the two dark gray circles, representing Hn and Hn+k, respectively, corresponds to the AIF coefficient I(Xn+k; Xn) (light blue area). It measures the shared information between the time points n and n+k, while ignoring the intermediate variables. The PAIF coefficients are represented by the dark blue sub-area of I(Xn+k; Xn) that results from excluding all elements that belong to the intermediate values H(Xn+k−1, …, Xn+1), shown in light gray color in the Venn diagram and the symbolic time series below.
A discrete Markov process (Xn)n∈ℤ of order M is defined via the property
for all positive integers k ≥ 0. In words, the transition probabilities from Xn to the state Xn+1 depend on the M-history of Xn, whereas inclusion of more values from the process' past, beyond Xn−M+1, does not convey further information about the transition probabilities.
General tests for the Markov property of low orders have been introduced in the 1950s and further tests for many special cases are still being developed today. Early works used analytical expressions for the distribution of symbol counts, given a certain Markov structure, and developed likelihood ratio tests for the cases of known (Bartlett, 1951) and unknown (Hoel, 1954) transition probabilities. Further developments included χ2 tests for hypotheses about the time-stationarity of transition probabilities, direct comparisons of different Markov orders (Anderson and Goodman, 1957; Goodman, 1958), as well as parameter estimation methods and tests for continuous time Markov processes (Billingsley, 1961). Using close relationships between χ2 statistics and information-theoretical expressions, test statistics based on Kullback-Leibler metrics were summarized as a monograph and in a practice-oriented article containing many numerical examples by Kullback (Kullback, 1959; Kullback et al., 1962). Further approaches include the application of the Akaike information criterion to optimize the order estimate for a discrete Markov chain (Tong, 1975) as well as data compression oriented algorithms (Merhav et al., 1989) and extensive surrogate data tests (Pethel and Hahs, 2014). The results of the PAIF method developed here is compared to the Markov order test presented in van der Heyden et al. (1998). The latter test compares finite entropy rate estimates (hX(n, k)) of the data to be tested with surrogate statistics obtained from M-order Markov surrogates with the same transition probabilities as the data. The algorithm for the computation of the surrogates is given in detail in (van der Heyden et al., 1998) and is summarized in the following section 2.4. This test will be termed conditional entropy test. In this article, surrogate statistics for each test data set are computed from n = 100 surrogate sequences for each Markov order M = 0, …, 5. The Markov order identified by the conditional entropy test is taken to be the value M for which all hX(n, k) lie within the α = 0.05 confidence interval defined by the surrogates.
We recently published our Python implementation of the Markovianity tests of order 0-2 as well as symmetry and stationarity tests as given in Kullback et al. (1962), in article form (von Wegner and Laufs, 2018), and as open-source code. Although the code is part of an algorithm to process EEG microstate sequences, the tests can be exported and applied generically.
A Markov process of order M is also defined via its transition probabilities , where the probability to go into state Xn+1 is conditioned on the M-history . To synthesize a Markov process of order M, using the same transition probabilities as the underlying experimental time series (Xn), the empirical M-order transition matrix is estimated first. To this end, all contiguous tuples of length (M+1) taken from the time series, i.e., tuples of the form (Xn−M+1, …, Xn, Xn+1) are considered. The maximum likelihood estimate for the transition probability based on this sample is given by
where #(·) denotes the number of times a specific outcome occurs in the empirical sequence (Xn) (Anderson and Goodman, 1957; van der Heyden et al., 1998). For instance, is the number of realizations (Xn = xn, …, Xn−M+1 = xn−M+1). While counting the tuples, the joint distribution of is recorded at the same time.
Following van der Heyden et al. (1998), the first M values of each surrogate Markov sequence are initialized with a sample from the joint distribution . From there, we have a M-history for every subsequent value Xn+1. The value of Xn+1 is chosen according to the transition probabilities and the given M-history. Given a specific M-history , there are L transition probabilities q0, …, qL−1, where . The distribution of the state Xn+1 = si is sampled correctly using a pseudo-random number r, uniformly distributed on the unit interval, , and the condition .
We recently published a Python implementation for first-order Markov surrogates in the open-source package described in von Wegner and Laufs (2018), and have included the M-order Markov surrogates in the Github repository associated with this paper.
The general concepts introduced above are easily applied to a two-state, first-order Markov process that can be written as
with transition rates p and q. The self-transition rate for A → A is 1 − p, and the rate of B → B is 1 − q. The complete transition matrix T reads
and has eigenvalues λ0 = 1 and λ1 = 1 − (p + q). The eigenvalue λ0 = 1 is assured by the Perron-Frobenius theorem as T is a stochastic matrix, i.e., for all i. The normalized positive eigenvector to λ0 is the equilibrium or stationary distribution pst of the process,
We set and . With the auxiliary functions φ, ψ : [0, 1] → ℝ defined as φ(x) = −xlogx and ψ(x) = φ(x)+φ(1−x), the analytical quantities Hpq, hpq and apq for the 2-state first-order Markov process acquire a very simple form.
The Shannon entropy of the 2-state Markov process is
Due to the Markov property, the entropy rate is hpq = H(Xn+1 ∣ Xn) and evaluates to
The Markov property reduces the full expression for information storage to apq = I(Xn+1; Xn):
The total entropy is conserved between active information storage and the entropy rate:
To validate the proposed approach, these analytical results will later be compared with numerical results of a hidden Markov process classified as first-order Markovian by the PAIF method.
To test the properties of the PAIF, two higher-order Markov processes with known properties are synthesized.
The first process is a third-order Markov process denoted MC1..M = 3, with transition probabilities that depend on . Given L states, there are LM possible M-histories preceding Xn+1, such that in matrix form has shape (LM, L). The specific transition probabilities are random numbers fulfilling for all M-histories . Sample paths are generated using the method described in section 2.4.
The second process will be termed MCM = 3 and is constructed in such a way that the Xn → Xn+1 transition only depends on Xn−2. Like the first process, this process can also be classified as third-order Markovian (M = 3), with the particular property that the influence of Xn and Xn−1 vanishes.
A more general class of discrete processes is represented by probabilistic finite state machines (Crutchfield and Young, 1989), which implement hidden Markov models (HMMs). Hidden Markov models generate sequences of symbols defined over a set of observable states that correspond to our measurements. The observable symbols are emitted by a set of hidden states that follow a Markov process, usually of first order. Each hidden state emits the observable symbols according to its own probability distribution defined over the observable set. It is important to note that the sequence of emitted symbols does not necessarily follow a Markov law.
The even process is a non-Markov process with two hidden states ({A, B}) and two observables ({0, 1}). The process scheme is visualized in Figure 4A. The process can emit arbitrarily long sequences of zeros by repeated self-transitions of the hidden state A → A. With probability p = 0.5, the state A can switch to B and hereby emit a 1, which is followed by another 1 with probability p = 1. Thus, ones are always generated in pairs, i.e., in blocks of even length. The procedure generates dependencies that in theory reach into the infinite past and can therefore not be reduced to a Markov process.
Two different implementations of the Golden-mean process are used. First, a 2-state first-order Markovian implementation using two hidden states ({A, B}) and two observable states ({0, 1}) (Ara et al., 2016), and second, a fourth-order Markov implementation using seven hidden ({A−G}) and two observable states ({0, 1}) (Mahoney et al., 2016). The scheme of the 2-state process (Figure 4B) is structurally similar to the even process, but dynamically different. Ones are never emitted repeatedly, i.e., they are always preceded and followed by a zero, in contrast to the even process. The 7-state golden mean process is a so-called R, k-Markov process with Markov order R = 4 and cryptic order k = 3, in our case (Mahoney et al., 2016).
The Ising model is a widely used discrete model from statistical physics (Hohenberg and Halperin, 1977). The model describes the ferromagnetic interaction of elementary spin variables, with two possible values ±1, as a function of temperature and the coupling coefficients between spins. The model can be realized with different geometries and in many cases, shows a phase transition at a critical temperature. We use a 2D square lattice geometry (L = 50) and run the system for 106 time steps. Sample paths are generated by Monte Carlo simulation using a standard Gibbs sampling scheme (Bortz et al., 1975).
The dynamics of a simple ion channel with one open and one closed state is modeled as a motion of a particle in the double-well potential , which shows two stable local minima at and one unstable local maximum at x0 = 0 (Liebovitch and Czegledy, 1992; von Wegner et al., 2014). The system is excited by thermal noise, as implemented by iid Gaussian pseudo-random numbers ξn. The system is described by von Wegner et al. (2014)
and integrated with an Euler scheme and dt = 10−3.
A resting state EEG data set from a 21 year old, healthy right-handed female during wakeful rest was selected and analyzed. The data set is part of a larger database for which we have reported the detailed pre-processing pipeline before (von Wegner et al., 2016, 2017). The 30 channel EEG raw data was sampled at 5 kHz using the standard 10−10 electrode configuration, band-pass filtered to the 1−30 Hz range using a zero-phase Butterworth filter with a slope of 24 dB/octave, down-sampled to 250 Hz and re-referenced to an average reference. Written informed consent was obtained from the subject and the study was approved by the ethics committee of the Goethe University, Frankfurt, Germany. EEG microstates were identified using the first four principal components (PCA analysis) of the data set and the symbolic microstate sequence was obtained by competitively fitting the microstate maps back into the EEG data set as detailed in (von Wegner et al., 2016, 2017).
Using the time index n + k as a reference, the partial autoinformation coefficients can be related to the entropy rate and to active information storage as follows.
The entropy rate hX(n + k − 1, k) can be written as the difference of two joint entropies of different lengths (Equation 9), .
Next, active information storage can be expressed as the difference of a joint entropy and the entropy rate:
In the stationary case, we have
Similar to the case presented for the 2-state Markov process, it is observed that also in the general case, the entropy H(Xn+k) is conserved, being the sum of active information storage and the entropy rate. In words, the information about the future state Xn+k is the sum of the actively stored information from time step n up to time step n + k − 1, and the entropy rate between time steps n + k − 1 to n + k.
Finally, the PAIF coefficient πX(n, k) can be written as the difference of entropy rates for different history lengths:
Alternatively, πX(n, k) can also be decomposed into a difference of AIS terms for two different history lengths:
Going from line 3 to line 4, we simply added and subtracted H(Xn+k). In words, the PAIF at time lag k is the difference between two AIF terms with history lengths k and k−1, respectively.
The results can be summarized in a more compact form using the stationary expressions:
For stationary Markov processes, the joint Shannon entropy Hk exists and the k-order entropy rate estimates hk converge in the limit of k → ∞ (Cover and Thomas, 2006). Using Equation 24, it follows that the AIS coefficients ak also converge. Thus, and . Using Equation 25, we deduce that the PACF coefficients πk also vanish in the large k limit:
Using the Markov property defined in Equation 21, it is straightforward to prove that for a stationary Markov process of order M, the PAIF coefficients vanish (πX(n, k) = 0) for k > M:
Let the first- and second-order finite differences of an arbitrary discrete function fk of integer parameter k be defined as δk fk = fk − fk − 1, and , then we get
Thus, the Markovianity test proposed in (van der Heyden et al., 1998) addresses a sequence of entropy rates hk, for different history lengths k, which is the negative first-order difference of the sequence of Shannon entropies Hk. PAIF analysis uses the second-order difference of the sequence of Shannon entropies . The advantage of the PAIF analysis is the visual exploration of the coefficients, that are equal to zero for k > M, exactly like in visual PACF diagnostics for metric time series.
The results for the two third-order Markov processes are shown in Figures 3A–D. The AIF and PAIF for the third-order Markov processes MC1…M = 3 is shown in Figures 3A,B, respectively. The shape of the AIF does not reveal the third-order dependencies by visual inspection. The PAIF, however, clearly reflects the construction of the process, showing significant PAIF coefficients only up to time lag k = 3.
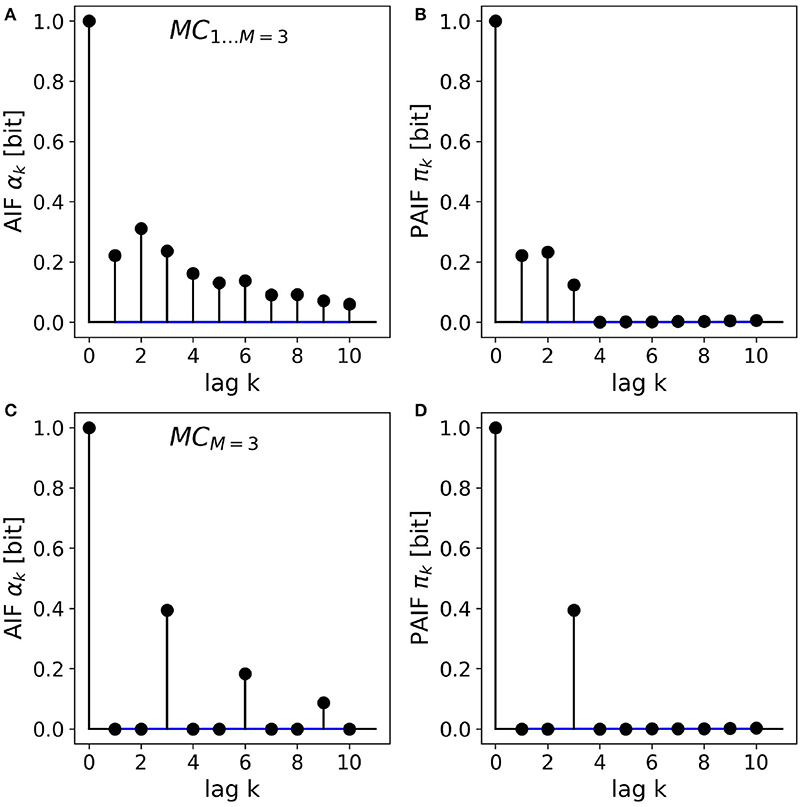
Figure 3. AIF/PAIF analysis of two third-order Markov process samples. (A) The AIF of the MC1…M = 3 process slowly decays toward zero and does not reveal the Markov order of the process. (B) The PAIF of MC1…M = 3 shows a cutoff after k = 3 coefficients, in accordance with the nominal Markov order. (C) The AIF of the MCM = 3 process has period 3 and thus hints at the memory structure of the process. (D) The PAIF of the MCM = 3 process clearly identifies the Markov order of the process by a distinct peak at the time lag corresponding to the correct model order M = k = 3.
For the second process, MCM = 3, the entropy dynamics can already be estimated by visual inspection of the AIF, which shows a clear periodicity (Figure 3C). Significant PAIF coefficients only occur at time lags that are multiples of the Markov order, M = 3. The PAIF (Figure 3D) however, demonstrates the Markov structure of the process in a single significant coefficient π3.
Kullback's Markovianity tests of order 0-2 rejected the Markovian null hypotheses for both processes, as expected for Markov processes of order three, by construction. The conditional entropy test correctly identified the Markov order M = 3 in both cases.
Confidence intervals (α = 0.05) constructed from uncorrelated surrogate time series are shown in blue. Due to their small magnitude, they visually appear as lines.
Figure 4 shows the results obtained from HMM data. First, the non-Markovian even process is analyzed. To the right of the HMM scheme, Figure 4A shows the PAIF of a single sample path of length n = 106. The inset shows that for all tested time lags the PAIF coefficients lie above the iid confidence interval (blue lines). Thus, PAIF analysis suggests that we are observing a non-Markov process with extended memory effects.
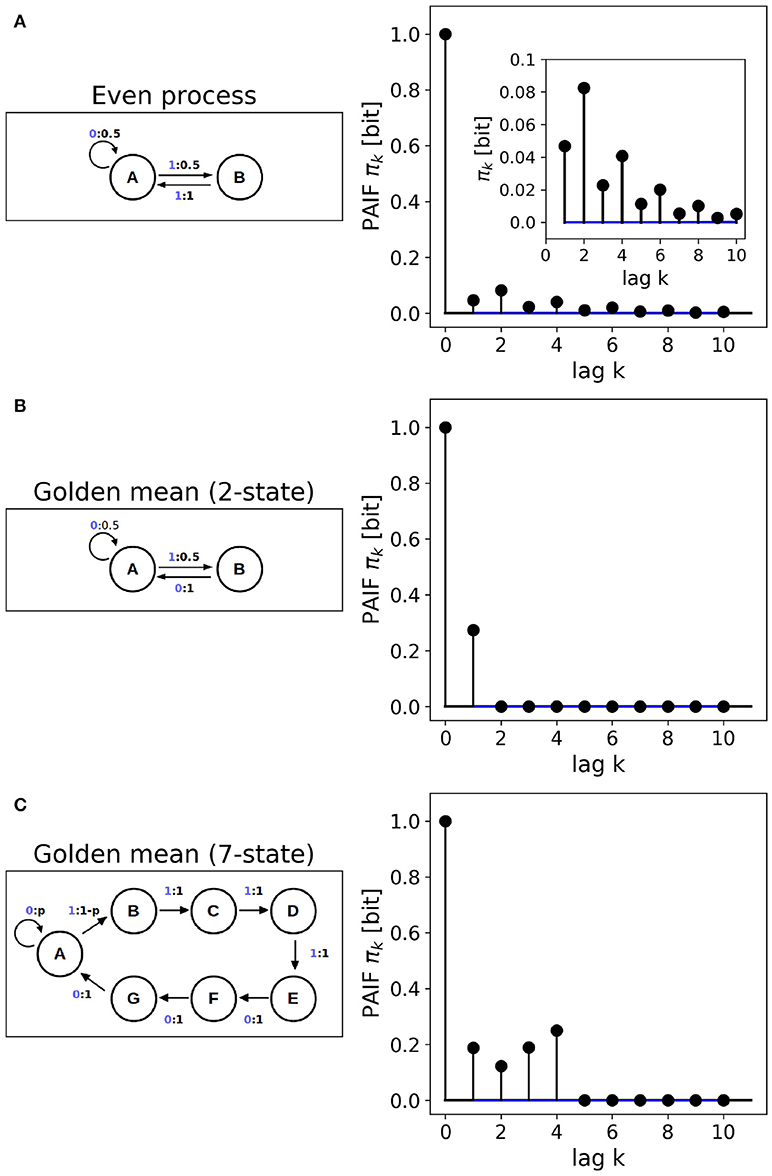
Figure 4. Finite state machines. (A) Non-Markovian even process, Markov order M = ∞. (B) 2-state implementation of the golden-mean process, Markov order M = 1. (C) 7-state implementation of the golden-mean process, Markov order M = 4. The Markov orders are correctly identified by the PAIF approach.
Figure 4B shows the PAIF of the 2-state golden mean process. The PAIF has two significant coefficients π0, π1 and decays to zero for all other time lags. The PAIF thus classifies the process correctly as a first-order Markov process, despite the hidden Markov implementation. Due to the Markov property, the process can also be represented by a transition matrix and an equilibrium distribution. The associated transition matrix T is
with stationary distribution . Using these quantities, the theoretical results from Section 2.5 can be applied. Using finite histories (k = 2…10), entropy conservation (Equation 24) is fulfilled with a maximum error of 7.25 × 10−4, where the error was calculated as . Based on this analysis, the Shannon entropy of a single symbol is H1 = 0.919 bit, and consists of an entropy rate of hX = 0.669 bit and active information storage of aX = 0.253 bit.
The 7-state HMM of the golden mean process is analyzed in Figure 4C. The fourth-order Markov structure of the implementation is clearly reflected by the PAIF that shows four positive coefficients. The PAIF captures the correct Markov order although the model contains seven hidden states and emits two observable symbols.
Kullback's Markovianity tests of order 0–2 correctly classified the 2-state golden mean process as first-order Markovian. The p-values for orders 0-2 were p0 = 0.000, p1 = 0.697, and p = 0.990, respectively. For the non-Markovian even process and the fourth-order Markovian 7-state golden mean process, low-order (0-2) Markovianity was correctly rejected. The conditional entropy test correctly identified the Markov properties of all three processes, i.e., found first- and fourth-order properties for the 2-state and 7-state golden mean processes, respectively, and an order M>5 for the even process.
We simulated an Ising model on a 2D lattice (50 × 50 elements) at two temperatures, (i) around the critical temperature , and (ii) at a higher temperature T = 5.00. From statistical physics, it is known that the system's autocorrelation function shows a slow, power-law decay at the critical point, and an exponential decay far from the critical point where dynamics are dominated by thermal fluctuations. AIF/PAIF analysis was performed on time series of 106 samples of a randomly selected lattice site. The results are shown in Figure 5.
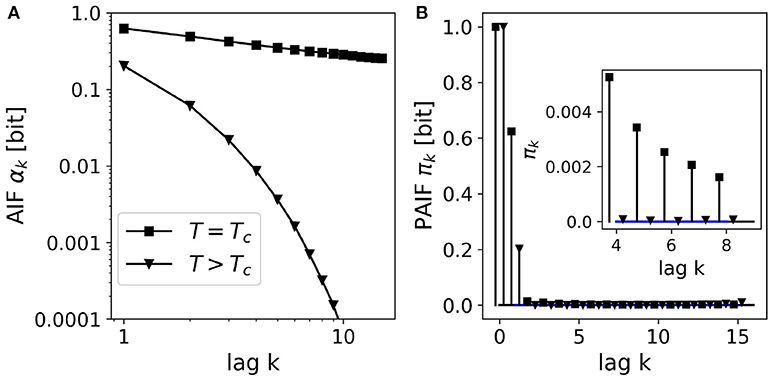
Figure 5. AIF/PAIF analysis of 2D-Ising model data: Results for single lattice site time series (n = 106 samples) at two temperatures are shown, close to the critical temperature Tc≈2.27 (black squares), and at a higher temperature far from the critical point, T = 5.00 (black triangles). (A) The AIF is shown in log-log coordinates to better visualize the qualitative difference between the power-law decay (linear in log-log coordinates) at the critical temperature (T = Tc), and the exponential decay at higher temperatures (T = 3.00). (B) The PAIF for both temperatures illustrates a dominant coefficient π1. However, the inset shows significant positive PAIF coefficients and thus, non-Markovian behavior close at the critical temperature (squares).
In contrast to the other figures in this manuscript, the AIF in Figure 5A is shown in log-log coordinates, to better visualize the difference between exponential and power-law behavior. The AIF at the critical point Tc shows an almost linear behavior in log-log coordinates (black squares), indicating very slow relaxation dynamics, as expected. For the higher temperature, far from the critical point (T = 5.0, black triangles), however, we observe a quickly decaying autoinformation trace, in accordance with results from classical time series analysis. Figure 5B shows the PAIF in linear coordinates, as in all other figures. It is observed that in both cases, T = Tc, T = 5.0, the PAIF profiles seem to be similar. We find two positive PAIF coefficients π0, π1, and significantly smaller PAIF coefficients for larger time lags. The inset, however, shows that at the critical temperature (squares), the PAIF coefficients lie above the confidence interval, demonstrating non-Markovian, long-range memory effects where the system undergoes a phase transition.
Simplified ion channel dynamics were generated by integration of Equation 23, representing the motion of a particle in a bistable potential, for instance an ion channel with two metastable states corresponding to the open (O) and close (C) state, respectively. To obtain a symbolic time series of O- and C-states, the continuous variable Xn is thresholded at a value of zero. Thereby, all positive values Xn>0 are assigned to the open state (O), and all negative values (Xn < 0) are mapped to the close state. The AIF/PAIF analysis of the thresholded signal simulating electrophysiological ion channel data is shown in Figure 6. We observe a slowly decaying AIF (Figure 6A) without any information about the Markov order of the signal. The PAIF profile shows large coefficients π0 and π1, followed by vanishing PAIF coefficients for k>1. Though Markovian dynamics are expected for the continuous dynamics, it is not obvious that the Markov property could be detected after thresholding.
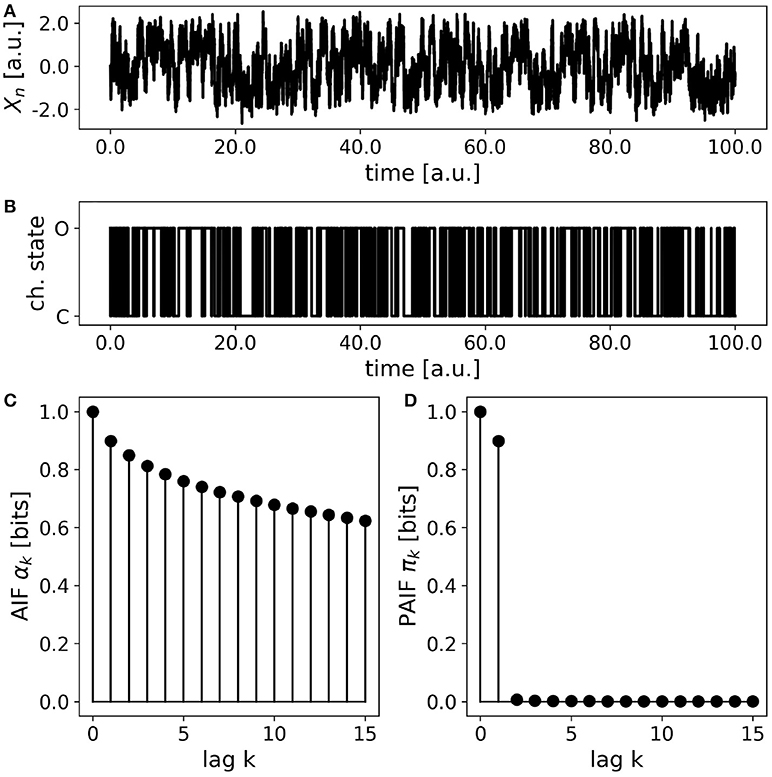
Figure 6. Simulated ion channel data. (A) A continuous stochastic process Xn is obtained from a simulation of a double-well potential. A bistable behavior resembling ion channel recordings is observed. (B) Thresholding the continuous variable Xn into an open state (O, Xn>0) and a close state (C, Xn < 0) yields a symbolic, binary process. (C) The AIF of the binary process shows a slow decay without revealing the Markov order of the process. (D) The PAIF suggests first-order Markov dynamics by vanishing PAIF coefficients πk for k>1.
The EEG microstate sequence shows a more complex behavior than the other presented examples. Figure 7A shows the AIF of the 4-state sequence, which seems to decay monotonously. The inset shows further information for longer time lags up to k = 40. We observe several periodic peaks at these time lags, an effect that we have discussed in detail in a recent publication (von Wegner et al., 2017). The PAIF in Figure 7B shows a dominant coefficient π1. This finding suggests a mainly first-order Markov mechanism, and does not hint at the periodic behavior found in the AIF. Moreover, we observe increasing PAIF coefficients for larger time lags (k > 8). This effect is caused by finite joint entropy estimates, which suffer from an insufficient sample size, given the history length k, and the size of the state space, here L = 4.
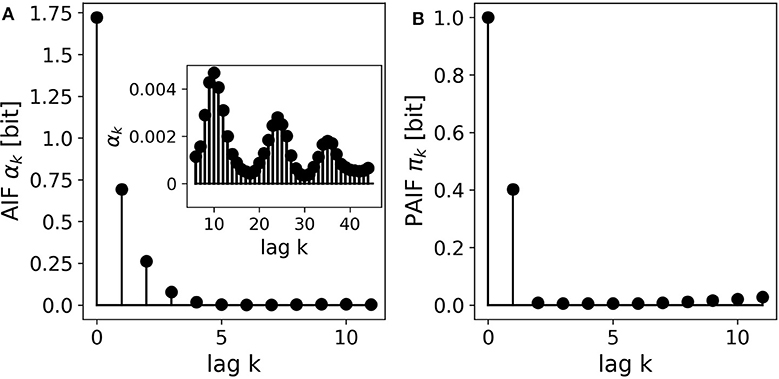
Figure 7. A 4-state resting state EEG microstate sequence. (A) The AIF shows a monotonous decay for smaller time lags k < 10. The inset shows the AIF for larger time lags (kmax = 50) and reveals periodicities that could not be predicted at shorter time scales. (B) The PAIF indicates a mainly first-order Markovian structure but does not allow the computation of time lags as large as the AIF due to the exponentially growing size of the associated distributions.
In the present article, an information-theoretical approach for the early diagnostic steps in symbolic time series analysis is established. In close analogy to classical time series analysis of continuous-valued random variables, a combined approach using two different measures that estimate the dependency between two time points is used. While autoinformation measures the statistical dependence between Xn and Xn+k directly, partial autoinformation removes the influence of the segment between both time points. The names AIF and PAIF were chosen to represent the close connection with the ACF/PACF approach. We have recently used the AIF to characterize stochastic processes and experimental EEG data (von Wegner et al., 2017, 2018), and the underlying functional can be found under the name of time-lagged mutual information in the literature. Partial autoinformation, however, is not found in the literature, to the best of the author's knowledge. Close connections to the entropy rate and the active information storage of the process, two well-studied information-theoretical quantities (Cover and Thomas, 2006; Lizier et al., 2012), are found and detailed. In particular, the newly introduced PAIF can be expressed either as the difference of two entropy rates with history lengths k − 1 and k, respectively, or as the difference of two active information storage terms with different history lengths. These relationships also assure that the PAIF coefficients approach zero in the large k limit.
The ability of the PAIF to identify the order of a stationary Markov process is shown analytically by re-writing the PAIF in terms of conditional entropies. A short proof shows that the PAIF coefficients of a stationary Markov process of order M are zero (πk = 0) for k > M. The practical performance of the method is validated numerically, using test data with known Markov orders, and by comparison with the results of two other tests (Kullback et al., 1962; van der Heyden et al., 1998). All test examples used in this article are correctly classified by the PAIF approach, in the same way the PACF performs for continuous autoregressive processes. A close relationship between the PAIF and the conditional entropy test (van der Heyden et al., 1998) is established by re-writing both in terms of joint entropies Hk. We found that while the conditional entropy test addresses the first-order discrete difference of Hk with respect to k, the PAIF actually tests the corresponding second-order discrete derivative. This completes the goal of establishing an information-theoretical tool analogous to classical PACF analysis.
Our experimental data examples also reveal some important limitations of the approach. The PAIF coefficients for the 4-state EEG microstate sequence (n = 153, 225 samples) increase for time lags above approximately k > 8. Comparison with Markov surrogate samples shows that this increase is due to the limited sample size, and is not a feature of the EEG data set (data not shown). The effect is easily understood by a simple numerical example. If for the same data set, we wanted to compute the PAIF coefficients for the same time lags as used in the AIF (Figure 7), joint probability distributions with Lk bins will occur. Thus, to extend the PAIF analysis of a L = 4-state process to k = 50, distributions with 450 > 1030 elements have to be estimated, clearly exceeding the length of the data sample numerous times. The example also shows that this is an intrinsic limitation of the approach, as it always occurs for information-theoretical quantities involving joint entropies, and is not specific to the PAIF introduced here.
Finally, the present article exclusively deals with discrete stochastic processes. Future investigations should include the corresponding quantities for continuous random variables, and Gaussian processes in particular. For example, it has been shown in the past that for Gaussian random variables, Granger causality is equivalent to transfer entropy (Barnett et al., 2009). By analogy, it can be conjectured that the PAIF and PACF approaches are likely to be related, if not equivalent, for Gaussian processes.
It will be interesting to see further applications of the presented approach to theoretical and experimental data and to investigate further theoretical connections to other quantities already in use.
FvW designed the study, performed all presented analyses, and wrote the manuscript.
This work was funded by the Bundesministerium für Bildung und Forschung (grant 01 EV 0703) and LOEWE Neuronale Koordination Forschungsschwerpunkt Frankfurt (NeFF) as well as by the LOEWE program CePTER.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author thanks Helmut Laufs for permission to use the EEG data set used in this article. The author also thanks the Reviewers for valuable input and suggestions, in particular the work by van der Heyden et al.
Anderson, T. W., and Goodman, L. A. (1957). Statistical inference about Markov chains. Ann. Math. Stat. 28, 89–110.
Ara, P. M., James, R. G., and Crutchfield, J. P. (2016). Elusive present: hidden past and future dependency and why we build models. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 93:022143. doi: 10.1103/PhysRevE.93.022143
Barnett, L., Barrett, A. B., and Seth, A. K. (2009). Granger causality and transfer entropy are equivalent for Gaussian variables. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 103:238701. doi: 10.1103/PhysRevLett.103.238701
Barnett, L., and Seth, A. K. (2015). Granger causality for state-space models. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 91:040101. doi: 10.1103/PhysRevE.91.040101
Bartlett, M. S. (1951). The frequency goodness of fit test for probability chains. Math. Proc. Cambridge Philos. Soc. 47, 86–95.
Bortz, A. B., Kalos, M. H., and Lebowitz, J. L. (1975). A new algorithm for Monte Carlo simulation of Ising spin systems. J. Comput. Phys. 17, 10–18.
Box, G. E. P., and Jenkins, G. M. (1976). Time Series Analysis: Forecasting and Control. Holden-Day. Hoboken, NJ: Wiley.
Cover, T. M., and Thomas, J. A. (2006). Elements of Information Theory. New York, NY: Wiley-Interscience.
Crutchfield, J. P., and Young, K. (1989). Inferring statistical complexity. Phys. Rev. Lett. 63, 105–108.
Daw, C. S., Finney, C. E. A., and Tracy, E. R. (2003). A review of symbolic analysis of experimental data. Rev. Sci. Instrum. 74, 915–930. doi: 10.1063/1.1531823
Faes, L., Porta, A., and Nollo, G. (2015). Information decomposition in bivariate systems: theory and application to cardiorespiratory dynamics. Entropy 17, 277–303. doi: 10.3390/e17010277
Goodman, L. A. (1958). Exact probabilities and asymptotic relationships for some statistics from m-th order Markov chains. Ann. Math. Stat. 29, 476–490.
Häggström, O. (2002). Finite Markov Chains and Algorithmic Applications. Cambridge, UK: Cambridge University Press.
Hohenberg, P. C., and Halperin, B. I. (1977). Theory of dynamic critical phenomena. Rev. Mod. Phys. 49, 435–479.
Kullback, S., Kupperman, M., and Ku, H. H. (1962). Tests for contingency tables and Markov chains. Technometrics 4, 573–608.
Liebovitch, L. S., and Czegledy, F. P. (1992). A model of ion channel kinetics based on deterministic, chaotic motion in a potential with two local minima. Ann. Biomed. Eng. 20, 517–531.
Lizier, J. T., Prokopenko, M., and Zomaya, A. Y. (2012). Local measures of information storage in complex distributed computation. Inform. Sci. 208, 39–54. doi: 10.1016/j.ins.2012.04.016
Mahoney, J. R., Aghamohammadi, C., and Crutchfield, J. P. (2016). Occam's quantum strop: synchronizing and compressing classical cryptic processes via a quantum channel. Sci. Rep. 6:20495. doi: 10.1038/srep20495
Merhav, N., Gutman, M., and Ziv, J. (1989). On the estimation of the order of a markov chain and universal data compression. IEEE Trans. Info Theor. 35, 1014–1019.
Mézard, M., and Montanari, A. (2009). Information, Physics, and Computation. Oxford University Press, Oxford, UK.
Pethel, S. D., and Hahs, D. W. (2014). Exact significance test for Markov order. Phys. D 269, 42–47. doi: 10.1016/j.physd.2013.11.014
Runge, J., Heitzig, J., Petoukhov, V., and Kurths, J. (2012). Escaping the curse of dimensionality in estimating multivariate transfer entropy. Phys. Rev. Lett. 108:258701. doi: 10.1103/PhysRevLett.108.258701
Tong, H. (1975). Determination of the order of a markov chain by akaike's information criterion. J. Appl. Probabil. 12, 488–497.
van der Heyden, M. J., Diks, C. G. C., Hoekstra, B. P. T., and DeGoede, J. (1998). Testing the order of discrete markov chains using surrogate data. Phys. D 117, 299–313.
von Wegner, F., and Laufs, H. (2018). Information-theoretical analysis of EEG microstate sequences in Python. Front. Neuroinform. 10:30. doi: 10.3389/fninf.2018.00030
von Wegner, F., Laufs, H., and Tagliazucchi, E. (2018). Mutual information identifies spurious Hurst phenomena in resting state EEG and fMRI data. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 97:022415. doi: 10.1103/PhysRevE.97.022415
von Wegner, F., Tagliazucchi, E., Brodbeck, V., and Laufs, H. (2016). Analytical and empirical fluctuation functions of the EEG microstate random walk - short-range vs. long-range correlations. Neuroimage 141, 442–451. doi: 10.1016/j.neuroimage.2016.07.050
von Wegner, F., Tagliazucchi, E., and Laufs, H. (2017). Information-theoretical analysis of resting state EEG microstate sequences - non-Markovity, non-stationarity and periodicities. Neuroimage 158, 99–111. doi: 10.1016/j.neuroimage.2017.06.062
von Wegner, F., Wieder, N., and Fink, R. H. A. (2014). Microdomain calcium fluctuations as a colored noise process. Front. Genet. 5:376. doi: 10.3389/fgene.2014.00376
Keywords: EEG microstates, information theory, entropy, mutual information, Markovianity, stationarity
Citation: von Wegner F (2018) Partial Autoinformation to Characterize Symbolic Sequences. Front. Physiol. 9:1382. doi: 10.3389/fphys.2018.01382
Received: 30 May 2018; Accepted: 11 September 2018;
Published: 11 October 2018.
Edited by:
Srdjan Kesić, University of Belgrade, SerbiaReviewed by:
Hussein M. Yahia, Institut National de Recherche en Informatique et en Automatique (INRIA), FranceCopyright © 2018 von Wegner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Frederic von Wegner, dm9uV2VnbmVyQG1lZC51bmktZnJhbmtmdXJ0LmRl
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.