 Madalena Chaves
Madalena Chaves Laurent Tournier
Laurent Tournier
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Physiol. , 29 May 2018
Sec. Systems Biology Archive
Volume 9 - 2018 | https://doi.org/10.3389/fphys.2018.00586
This article is part of the Research Topic Logical Modeling of Cellular Processes: From Software Development to Network Dynamics View all 23 articles
Boolean networks with asynchronous updates are a class of logical models particularly well adapted to describe the dynamics of biological networks with uncertain measures. The state space of these models can be described by an asynchronous state transition graph, which represents all the possible exits from every single state, and gives a global image of all the possible trajectories of the system. In addition, the asynchronous state transition graph can be associated with an absorbing Markov chain, further providing a semi-quantitative framework where it becomes possible to compute probabilities for the different trajectories. For large networks, however, such direct analyses become computationally untractable, given the exponential dimension of the graph. Exploiting the general modularity of biological systems, we have introduced the novel concept of asymptotic graph, computed as an interconnection of several asynchronous transition graphs and recovering all asymptotic behaviors of a large interconnected system from the behavior of its smaller modules. From a modeling point of view, the interconnection of networks is very useful to address for instance the interplay between known biological modules and to test different hypotheses on the nature of their mutual regulatory links. This paper develops two new features of this general methodology: a quantitative dimension is added to the asymptotic graph, through the computation of relative probabilities for each final attractor and a companion cross-graph is introduced to complement the method on a theoretical point of view.
An intuitive representation of system interactions, an algorithmic description of state transitions, and the capacity to capture the global dynamics of the system, list some of the advantages of Boolean models, which remain a powerful tool in the modeling and analysis of biological networks (Wang et al., 2012; Abou-Jaoudé et al., 2016). Successfully predictive examples of Boolean models cover complex networks across many different organisms, from cell cycle (Li et al., 2004; Fauré et al., 2006), to fly or plant morphogenesis (Albert and Othmer, 2003; García-Gómez et al., 2017), and highly complex networks such as T-cell induction (Mendoza and Xenarios, 2006; Saez-Rodriguez et al., 2007), leukemia (Zhang et al., 2008) or apoptosis (Calzone et al., 2010).
In a modular view of a biological organism, each task is executed by a specific set of interactions among an ensemble of biological components; in other words, it can be said that there is a specifc network, or module, for each specific task (signaling, metabolic, physiological, etc.). These modules often interact with each other, one task triggering the next in a chain of events or cyclic phenomena. Examples include chains of signaling networks such as MAPK cascades, genetic-metabolic interactions (Baldazzi et al., 2010), or coupled oscillations (Gérard and Goldbeter, 2012). However, in many cases, while experimental evidence supports the existence of links between two modules, their modes of interaction are still unclear (as in the case of mammalian cell cycle and circadian clock, see Feillet et al., 2015). In this context, mathematical tools are necessary to facilitate the analysis of the complex behavior obtained from the interconnection of two or more known modules.
One of the challenges in the analysis of Boolean networks is attractor computation, particularly for high-dimensional networks. For a network of dimension n, the size of the state transition graph is 2n. A direct analysis of such a graph may become computationally costly, in terms of space and time, when n ≥ 20. This is especially true with asynchronous updating, which includes numerous dynamical trajectories. Two very efficient methods have recently been developed: Zañudo and Albert (2013) compute all attractors of a network (up to n ≈ 100), by isolating special properties of the state transition graph's components; Veliz-Cuba et al. (2014) compute all singletons (attractors containing a single state) for networks up to n = 1,000, by using a computational algebra approach.
In this paper, we propose a methodology aimed specifically at analyzing the interconnection between several known Boolean modules. The interconnection between two biological networks can be very hard to test in vivo: our methodology provides a platform for hypothesis testing, confirming or disproving assumptions regarding mutual regulatory effects, simulating and comparing various forms of interconnection schemes and corresponding emergent dynamical behavior. Our method relies on the construction of a new object, the asymptotic graph, introduced by Tournier and Chaves (2013), which is a directed graph constructed only from the set of attractors of each module and that captures all the asymptotic behaviors of the interconnected network.
After a brief review of Boolean network interconnections, two improvements to the asymptotic graph are introduced in this paper, to mitigate two of its known limitations. First, it was observed that the asymptotic graph may also recover spurious attractors, in addition to the true attractors of the full network (Tournier and Chaves, 2013); we introduce an extension, called the cross graph that solves this issue from a theoretical point of view. The cross graph is constructed from the set of strongly connected components of each separate module, while the asymptotic graph is constructed from terminal strongly connected components only. Second, to enrich the traditional ON/OFF representation inherent to Boolean models, we propose a method to assign probabilities to the edges of the asymptotic graph, thereby allowing a probabilistic representation of the various possible trajectories of the composed network. Our methodology is applied first to a class of general randomly generated Boolean models and then to two state-of-the-art biological models in two different organisms: (i) to explore the interplay between mammalian cell cycle and circadian clock oscillators and (ii) to test hypotheses on the regulatory links between budding yeast cell cycle and cell size, where our analysis suggests that the START signal should come from mitosis phase.
Throughout this paper, we will consider Boolean networks under asynchronous updates. An interconnected Boolean network is, briefly, the combined network formed by linking together, in an approriately prescribed way, two or more separate Boolean modules. In previous works (Chaves and Tournier, 2011; Tournier and Chaves, 2013) we have introduced a new object, the asymptotic graph, that characterizes the attractors of the combined Boolean network in terms only of the attractors of the separate modules—hence with no need to compute the larger state transition graph. In the following, the definition of the main objects needed to introduce the asymptotic graph are briefly reviewed.
Let us start by a brief recall of the definition of an input-output asynchronous Boolean network (IO ABN), reprising the notation introduced by Tournier and Chaves (2013). An IO ABN ΣA is characterized by three integers nA, pA, qA (nA > 0 is the dimension of the system, pA, qA ≥ 0 are respectively the numbers of inputs and outputs) and by two Boolean maps: (the transition function) and (the output function). For any given input profile , the asynchronous dynamics of the network are given by the asynchronous transition graph GA, u, which is a digraph over the vertex set defined as follows: for any state , the set of its successors are the states (x1, …, ¬xi, …, xn), for all i ∈ {1, …, n} such that . The number of vertices of such a graph is and its number of arcs, denoted by mA, verifies . It is therefore relatively sparse and can thus be efficiently stored by a adjacency matrix. In the following, we will consider that GA, u designates this matrix. Given two integers , the (i, j) entry of the adjacency matrix equals 1 if state j is a successor of state i and 0 otherwise. In a classical abuse of notation, we associate each integer with its binary representation in lexicographic order, with the left-most bit being the most significant one; in other words: . Thus, we will indifferently call state either an integer or its Boolean representation .
EXAMPLE 1. Consider the bidimensional single-input, single-output (SISO) network defined by: and . Graphically, this network can be represented as a simple cascade u → x1 → x2. Its dynamics are characterized by the two graphs GA,0 and GA, 1, represented below in graphical and matricial forms:
In adjacency matrices, by convention the (i, j) entry equals 1 iff state j is a successor of state i. Here, the four states (rows and columns of the matrix) are intended in the following order: 00, 01, 10, 11. In GA,0, state 00 does not have any successor, implying the first row of its adjacency matrix is zero: 00 is a steady state of the network. Similarly, 11 is a steady state of GA,1. □
Classically, an asynchronous transition graph GA, u is analyzed by first computing its decomposition into strongly connected components (SCCs), denoted by , where . The set of all SCCs forms a partition of the state space and their computation can be efficiently achieved in . By contracting each SCC to a single vertex, a directed acyclic graph (dag) is constructed, sometimes called condensation graph or simply SCC graph. This dag provides a useful description of key dynamical behaviors of the network; in particular terminal SCCs (the leafs of the dag) correspond to the attractors of the network. More details about these graph theoretical tools can be found, for instance, in the textbook by Cormen et al. (2001).
Consider now two IO ABN ΣA and ΣB, of respective dimensions (nA, pA, qA) and (nB, pB, qB) and state variables and . Note that all the methods presented in this paper generalize to more than two modules; however, in order to maintain a clear exposition of the results, the definitions are given for interconnections of two modules. An interconnection scheme of ΣA and ΣB consists in two interconnecting functions and mapping the outputs of each module to the inputs of the other module. For convenience, throughout this paper we will make the assumption that qB = pA and qA = pB and that the interconnecting functions are simply identity maps. Following Tournier and Chaves (2013), with this assumption the resulting interconnected network is the ABN of dimension nA + nB, with no input and no output, defined by the following transition function:
One can then consider the interconnection as a standalone network: its transition graph G can be constructed from this transition function f. Alternatively, one can also build the graph G directly from the set of transition graphs and as follows. Let (x, y) and (x′, y′) be two Boolean vectors in , then (x′, y′) is a (asynchronous) successor of (x, y) if
• either x = x′ and y′ is a successor of y in GB,hA(x),
• or y = y′ and x′ is a successor of x in GA,hB(y).
It is possible to summarize this definition in a simple matricial form. First, for each , introduce the diagonal Boolean matrix ΔA,α such that if the output of state i is equal to α and 0 otherwise. Similarly, for module ΣB introduce the diagonal Boolean matrices ΔB,β, with . Then, G can be reconstructed by the formula:
where ⊗ designates the classical Kronecker product. By replacing matrices Δ with identity matrices, one may recognize in this definition of G the notion of Cartesian product of graphs, first introduced by Sabidussi (1959). To be more precise, (2) generalizes the notion of Cartesian product to interconnections, by including only transitions that are consistent with the input-output scheme.
EXAMPLE 2. Consider module ΣA defined in Example 1 and let the one-dimensional SISO module ΣB defined by and . Its dynamics are given by
The interconnected network can be reconstructed by using (1), leading to the 3-dimensional transition function f(x1, x2, y1) = (y1, x1, ¬x2). Alternatively, the transition graph G can also be computed directly as the interconnection of the dynamics of the two separated modules by using (2):
In graphical form, this transition graph G of the interconnected network can be represented as:
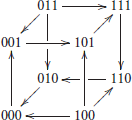
This graph has a unique attractor, composed of six states: {001, 101, 111, 110, 010, 000}. □
In the present paper, note that we assume the modules and the interconnection scheme are given. It is also possible to consider interconnections as a general model reduction technique, where a large network is first decomposed into a priori unknown sub-networks. The identification of an efficient decomposition, with the corresponding interconnecting scheme, would then become critical. This problem is related to the general problem of graph partitioning and is addressed elsewhere (Tournier and Chaves, 2013).
We can now give the definition of the asymptotic graph (Tournier and Chaves, 2013). First, list all the terminal SCCs of module ΣA: and cut them with respect to their outputs, ie. define, for each output profile , the set . For some α such a set may be empty, in that case we will simply omit it. Similarly, define for module ΣB. The asymptotic graph of the interconnection is then defined as the directed graph Gas = (Vas, Eas) such that the vertex set Vas is composed of all the cross products and the arc set Eas is constructed as follows:
• iff there exist , such that there exists a path from x to x′ in GA,β,
• iff there exist , such that there exists a path from y to y′ in GB,α.
Finally, introduce the function π as follows: if , and if R⊆Vas, π(R): = ⋃V ∈ R π(V). The interest of the asymptotic graph lies in the following theorem, a proof of which can be found in Tournier and Chaves (2013).
THEOREM 1. If Q is an attractor of the interconnected network, then there exists a terminal SCC R of Gas such that π(R) ⊆ Q.
EXAMPLE 3. Consider the interconnection of Example 2 above. The asymptotic graph is given by
Therefore, Gas is composed of a single terminal SCC R, and π(R) = {001, 111, 000, 110} is actually included into the (unique) attractor of the interconnected network. □
Thanks to Theorem 1, the asymptotic graph is a powerful analytic tool as it recovers all the attractors of an interconnection (without missing any), by constructing a graph significantly smaller than the full interconnected graph G (section 4 below provides numerical results for random interconnections). However, it may happen that some terminal SCC of Gas does not correspond to an actual attractor of the interconnection. Such terminal SCCs, called spurious attractors, appear very rarely and there exist some sufficient conditions to detect a priori spurious attractors in certain cases. The most simple one, particularly useful for biological applications is the fact that when R is a singleton then it cannot be a spurious attractor. The proof, along with additional conditions are provided elsewhere (Tournier and Chaves, 2013; Chaves and Carta, 2015).
This section describes our new contributions. Our first goal is to improve the asymptotic graph construction to avoid the generation of spurious attractors (section 3.1) and our second goal is to update the asymptotic graph by adding quantitative information (probabilistic) on the state transitions (section 3.2).
The asymptotic graph of an interconnection is constructed only from the modules' attractors, generally implying a relatively manageable size allowing to analyze a wide range of practical examples of interconnections (see sections 4 and 5). Nevertheless, ignoring transient dynamical behaviors of the modules also implies two drawbacks for Theorem 1. First, spurious attractors may appear, although this phenomenon seems to be relatively rare as illustrated in section 4. Second, when a terminal SCC of Gas corresponds to an actual attractor, Theorem 1 only ensures an inclusion, meaning the predicted attractor may contain only a small proportion of states that are in the real attractor. We now propose a new graph, called the cross-graph, overcoming those two issues and ensuring, at the price of a higher computational cost, a one-to-one recovery of all the attractors of the interconnected network. Note that Tournier and Chaves (2013) already introduced a notion of cross-graph, however the cross-graph described in the following is significantly improved. In particular, its size is bounded by the size of the full interconnected graph, which was not the case for the older version.
Let ΣA and ΣB be two IO ABN of respective dimensions (nA, pA, qA) and (nB, pB, qB). As before, suppose for convenience that pA = qB, pB = qA and the interconnecting maps are simply identity maps. We also assume that each module has been separately analyzed: the transition graphs GA,u, u ∈ {0, 1}pA and GB,υ, υ ∈ {0, 1}pB have been constructed and decomposed into strongly connected components for each u ∈ {0, 1}pA and for each υ ∈ {0, 1}pB. Let G denote the full transition graph of the interconnected network, of size 2nA+nB. It can be computed thanks to (2), by interconnecting the modules' transition graphs. The idea behind the cross-graph is to generalize formula (2) in order to interconnect directly the SCCs of those graphs instead of the whole graphs themselves, thus potentially saving a significant amount of space when constructing the dynamics of the interconnection.
First, observe that the strongly connected components form a partition of the state space {0, 1}nA of module ΣA ( are integers verifying ). Therefore, for u varying in {0, 1}pA we obtain 2pA partitions of the same finite set Ω = {0, 1}nA. Let 𝔓Ω denote the set of all partitions of Ω. Given two partitions P1, P2 ∈ 𝔓Ω, P1 is said finer than P2, denoted by P1 ≤ P2 if, for each element p in P1 there is an element q in P2 such that p ⊆ q (in other words, partition P1 is a fragmentation of partition P2). The set (𝔓Ω, ≤) has the structure of a geometric lattice (see eg. Birkhoff, 1940). Consequently, for any set S ⊆ 𝔓Ω, there exists a (unique) greatest lower bound of S denoted by ∧ S ∈ 𝔓Ω. Coming back to the SCC decompositions, introduce the following partition:
which is the coarsest partition of {0, 1}nA that is finer than every SCC decomposition of all the transition graphs GA,u. Once this partition is constructed, following the same idea as before it is further refined by cutting each set Ai according to their outputs: , with the convention that such sets are simply omitted when they are empty. Therefore, we finally obtain a partition of the state space {0, 1}nA that is compatible with every SCC decompositions of the dynamics of modules ΣA. By construction, the number of elements in this partition, denoted by MA, verifies 1 ≤ MA ≤ 2nA. Applying the exact same procedure for module ΣB, one obtains a similar partition of the state space {0, 1}nB, containing MB elements.
Once partitions and are defined, the construction of the cross graph closely resembles the one of the asymptotic graph. The cross graph is the digraph Gcr = (Vcr, Ecr), where the vertex set Vcr is composed of all cross-products × and the arc set is constructed as follows:
• iff there exist a ∈ , such that there is a transition from a to a′ in graph GA,β,
• iff there exist b ∈ , such that there is a transition from b to b′ in graph GB,α.
There is also a matricial form for the definition of Gcr. First, project each transition graph GA,u onto , leading to 2pA graphs, represented by their MA × MA adjacency matrices HA,u, u ∈ {0, 1}pA. These projections can be rather straightforwardly achieved since is a fragmentation of the SCC decomposition of GA,u. Second, for each α ∈ {0, 1}qA, introduce the MA × MA diagonal matrix such that entry if the output of the i-th element of is equal to α and 0 otherwise. Once similar objects HB,υ and have been constructed for module ΣB, the cross-graph is simply defined by a generalization of formula (2):
EXAMPLE 4. To illustrate this definition, let us consider two 2-dimensional, single-input single-output modules ΣA and ΣB, defined by their transition graphs given in Figure 1A and their output functions hA(x) = x2, hB(y) = y1. The full transition graph of the interconnection, built from (2), is depicted in Figure 1B and the cross-graph is depicted in Figure 1C: it is constructed from the two partitions and . □
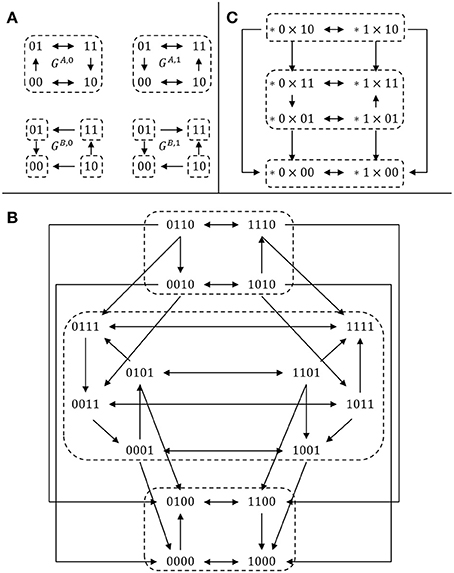
Figure 1. Comparison between the cross graph of an interconnection and the full transition graph. (A) Transition graphs of two SISO modules (see Example 4); (B) full transition graph G of the interconnection; (C) cross graph Gcr of the interconnection. For each graph, dotted regions denote strongly connected components. There is a bijection between the SCC decomposition of the two graphs G (16 vertices) and Gcr (8 vertices), illustrating Theorem 2.
The interest of the cross-graph lies in the following theorem, establishing the one-to-one correspondence between the terminal SCCs of Gcr and the attractors of the interconnected network.
THEOREM 2. Graphs G and Gcr have the same decomposition into strongly connected components. Furthermore, terminal SCCs of Gcr fully recover the attractors of the interconnected network.
A proof of Theorem 2 is given in appendix. The size of the cross-graph is MA × MB, which by construction is always less or equal than 2nA+nB, the size of the full interconnected graph G. The difference in size between the two graphs may vary greatly, and strongly depends on (i) the SCC decompositions of the two modules and (ii) as for the asymptotic graph, the numbers of inputs and outputs (and therefore the general modularity of the initial network). Part 4 proposes a brief evaluation of the performance of the method for a set of randomly generated interconnections. Although the interest of the cross-graph is mainly theoretical, in certain practical cases the full graph G can be too big to be stored easily while Gcr could.
Two possible extensions of the cross-graph method are noted here. First, Bérenguier et al. (2013) proposed a compression of the SCC graph of a network, called the hierarchical transition graph (HTG). As the cross-graph is constructed from a combination of the modules' SCC decompositions, it would be possible to consider similarly a combination of the modules' HTG decompositions. Benefiting from the compactness of HTGs, such a construction would be even more compact than the cross-graph. Second, note that both the cross graph and the asymptotic graph methods require prior analysis of the modules' dynamics and the computation of their attractors, implicitly implying the dimensions of the modules are manageable. For a large network, Zañudo and Albert (2013) proposed an efficient characterization of attractors with the notion of “stable motifs,” based on the network's interaction graph (see also Klarner et al., 2015). When considering interconnections of large modules, the investigation of the stable motifs of an interconnection would therefore constitute an interesting extension of Theorem 2.
One of the limitations of Boolean models is the lack of quantitative details: while the state transition graph describes all possible dynamical behaviors, it gives no indication as to which trajectory is more likely to be observed under a given set of initial conditions. To circumvent this problem, Boolean models can be combined with probabilistic frameworks that account for biological perturbations and variability in the logical rules (Shmulevich et al., 2002; Mori et al., 2015). Another approach is to exploit the Markov chain description of the transition graph associated to the asynchronous Boolean model (Calzone et al., 2010; Stoll et al., 2017). Based on this description, Stoll et al. (2017) developed the MaBoSS software, which then applies Gillespie algorithm to produce continuous time trajectories.
We also use the Markov chain description to assign probabilities to the edges of the asymptotic graph, an approach which will lead to a more quantitative analysis of the interconnected network's dynamics. The output of our probabilistic asymptotic graph is thus the set of attractors of the full network, under a particular interconnection scheme, together with a relative probability for each of them (e.g., “there is a probability p1 that phenotype Q1 is the outcome of this experiment”).
The originality of our approach consists in assigning incidence probabilities to the attractors of each separate module, which can be obtained through the biological observations and measurements available for each module. The goal is to include biological information as an input and provide predictions that can be confronted to biological observations and therefore lead to validate or disprove the given interconnecting scheme.
Each transition in the asymptotic graph depends on two factors: which module is first “updated” (A or B) and, in response to an input change, how frequently does a switch occur from to (or from to ). These quantities may be represented by probabilities, defined a priori, from known data, experimental observations, or other modeling considerations.
Define
Assume Boolean module ΣA has a total of LA same-output attractor-sets and ΣB a total of LB same-output attractor-sets,
and each of these has a given incidence probability (meaning that it is observed with a certain frequency) defined as
The probabilities and may be assigned in different ways, for instance using experimental observations, or setting uniform probabilities ( for all i), or else from the size of their respective basin of attraction
but in any case they should satisfy Using these initial probabilities, a joint incidence probability may similarly be defined for each product of attractor-sets:
The probability of switching between two attractor-sets of the same module, but different inputs, can be defined in terms of conditional probabilities: define to be the probability that attractor A[k] is reached, conditional to the fact that the initial state is some ai ∈ A[i]. In other words, must be weighted by the probability of ai reaching any attractor in GA,uk:
where = {j : uj = uk and ai ⇝ A[j]} means that there exists a path in GA,uk leading from ai to A[j], where A[j] is an attractor of GA,uk. A similar definition holds for .
Next, we can define the probability associated to an edge of Vas as:
with an “effective” probability , computed based on the set of all ougoing edges from node A[i] × B[j]:
In other words, if all outgoing edges have a fixed A-attractor, A[i] × B[j] → A[i] × B[k]; , if all outgoing edges have a fixed B-attractor A[i] × B[j] → A[k] × B[j]; if outgoing edges may be of both types.
Note that these definitions ensure that the probabilistic asymptotic graph matrix has the property that all rows add up to 1:
since both and .
If the asymptotic graph Gas has two or more attractors, in addition to the transition probabilities, another useful information is the frequency of observing a given attractor, or in other words the relative probability of each attractor of the interconnection. This probability can be computed from the SCC graph GSd = (VSd, ESd) corresponding to Gas, which is an acyclic graph and can be represented by an absorbing Markov chain. By definition, VSd is composed of the strongly connected components of Gas. Let C ∈ VSd contain LC elements of Vas. Define the incidence probability of observing C as:
Moreover, a probability of transition can also be associated to each edge of ESd, P(Ci → Cj), computed by adding all the probabilities of the edges in Eas that link elements of Ci to elements of Cj. Suppose there are m strongly connected components, |VSd| = m, and let the m × m matrix M with Mij = P(Ci → Cj), be the absorbing Markov chain associated with the graph GSd. Suppose M has r absorbing states, , these are also the attractors of GSd. Matrix M can be written in the following canonical form (Feller, 1970):
where Ir is the r×r identity matrix, Q is the (m − r) × (m − r) matrix of transitions between transient states and R is the (m − r) × r matrix of transitions from transient states to absorbing states. Since M is irreducible, it follows that (I−Q) has an inverse (where I is the (m−r) × (m−r) identity matrix). Then the probability that there exists a path from a given state to one of the r absorbing states is given by the probability of being absorbed by r:
where Mabsorp(i, k) is the probability that transient state i converges to absorbing state k.
If, in addition, we wish to weigh these absorption probabilities by the incidence probabilities of observing , we can define the relative probability of an attractor of the asymptotic graph:
where denotes each attractor and is the incidence probability of .
In this part we propose a series of computational experiments to assess the efficiency of the asymptotic graph and the cross graph to recover the attractors of random interconnected Boolean networks. Following the general idea of inputs/outputs at the core of this paper, we start with a brief description of the algorithm used to generate random IO modules. We then present numerical results computed on random interconnections with varying connectivity, showing the respective advantages and limitations of the two methods in practice.
The NK-model, introduced by Kauffman (1969), is a general statistical model to represent random Boolean networks by controlling their dimension N and their inner connectivity K. It is used for instance by Zañudo and Albert (2013) and Veliz-Cuba et al. (2014). Here it is slightly adapted to include inputs and outputs. Let Σ be an IO Boolean network of dimension (n, p, q), of transition function f : {0, 1}p × {0, 1}n → {0, 1}n and output function h:{0, 1}n → {0, 1}q. A usual way to depict such a network is by its wiring diagram, showing the dependencies between the different variables of the network. Equivalently, the wiring diagram can be represented by a (n + q) × (p + n) Boolean matrix
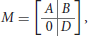
where submatrices A (n × p), B (n × n) and D (q × n) are defined as follows:
Let C designate the matrix [A|B]. The sum of the i-th row of C is the number of essential variables of logical function fi, also called the connectivity of fi. Given integers n > 0, p, q ≥ 0 and a real number Kmean ∈ [1, n], we construct a random IO network of dimension (n, p, q) and of average connectivity Kmean by applying the following procedure, which generates a dependency matrix M:
1. Let D: = 0. For each 1 ≤ i ≤ q, pick at random j ∈ {1, …, n} and set dij: = 1.
2. Generate n integers ki in {0, …, n+p} according to a binomial distribution of parameters n + p (number of trials) and (probability of success).
3. Let C = [A|B]: = 0. For each 1 ≤ i ≤ n, pick a random combination (j1, …, jki) ∈ {1, …, n + p}ki (without replacement) and set ci,jl: = 1 for all 1 ≤ l ≤ ki.
4. Check that each column of A is non-zero; while it is not the case, repeat step 3.
5. Set .
Step 4 ensures the generated module actually depends of every inputs. Once the dependency matrix M is obtained, the last step consists in generating the n+q Boolean functions according to M. A Boolean function of k variables is picked randomly among the 22k possibilities; in case it is degenerate (i.e., at least one of the k variables is not essential), another one is chosen so as to ensure exact compatibility with M.
With this algorithm, it is possible to generate a IO module by controlling its inner connectivity, that is the number of actual dependencies in the wiring diagram. Thus, it becomes possible to generate random interconnections with varying degrees of modularity, according to the average connectivity of each module. We used this algorithm to generate 2,000 interconnections of two modules ΣA and ΣB of dimensions (nA, pA, qA) = (nB, pB, qB) = (10, 2, 2):

where the mean connectivity of ΣA and ΣB varies in {1, …, 10}. For each interconnection, both 10-dimensional modules were analyzed separately (including the computation of the transition graphs, their SCC decompositions and the computation of their attractors), then the cross graph and the asymptotic graph were computed and compared. The main results are presented in Figure 2 and summarized below. All computations were made with Matlab R2016b, The MathWorks, Inc.
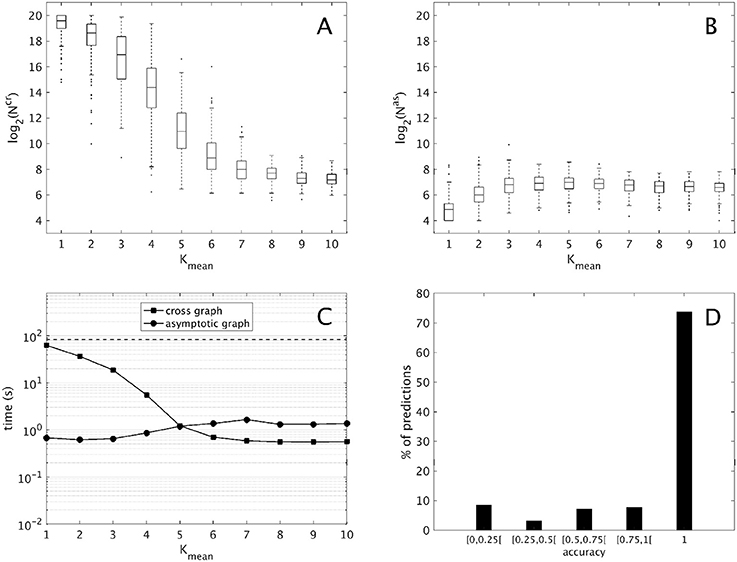
Figure 2. Computational results for 2,000 interconnections of two 10-dimensional modules [according to (9)], split into ten groups of 200 sorted along Kmean, the mean connectivity of the modules. (A,B) Evolution of the sizes of the cross graph and of the asymptotic graph, log2(Ncr) and log2(Nas) with respect to the modules' connectivity (obtained with the routine boxplot of Matlab's Statistics toolbox). (C) Mean execution time in seconds of the cross and asymptotic graph methods (logarithmic scale). The dotted line represents the average time of the direct method (analysis of the full interconnected network). (D) Histogram of the accuracies of all the attractors predicted by the asymptotic graph (3,693 attractors in total).
First, we compare the respective sizes Ncr and Nas of the cross and the asymptotic graphs (ie. their number of vertices). Figures 2A,B show respectively the evolution of log2(Ncr) and log2(Nas) with respect to the connectivity of the two modules. Obviously, both Ncr and Nas are below N = 220, which is the size of the full transition graph of the interconnected network. The cross graph, which captures both the transient and the asymptotic dynamics of the interconnection is relatively large, however its size seems to vary greatly with the modules' connectivity. When the connectivity increases, implying a highly modular interconnection, the ratio Ncr/N can reach very small values, emphasizing the interest of the cross graph to efficiently store the dynamics of large, modular interconnected networks. On the other hand, the asymptotic graph is always much smaller, several orders of magnitude under the size of the full transition graph. Contrary to the cross graph, it is particularly small when the modules have lower connectivity, making it particularly well adapted for biological networks. Interestingly, its size seems to reach a plateau when the mean connectivity is above .
Another way to compare the two approaches is by studying their average execution times. The times shown in Figure 2C include the analysis of the two 10-d modules and of the cross and asymptotic graph methods. The latter comprise the construction of Gcr (respectively, of Gas), the SCC decomposition of Gcr (respectively, of Gas) and the reconstruction of the attractors (respectively, of π(R) for all terminal SCCs R of Gas). For the cross graph, the majority of the time is taken by the SCC decomposition of Gcr while for the asymptotic graph, the most time-consuming step is the construction of Gas itself (data not shown). For comparison, we also computed the complete dynamics of the 20-d interconnected network by using formula (2); on average, such direct method amounted to around 83 seconds (dotted line). Therefore, both methods are faster than the direct analysis of the full interconnected network. As before, the asymptotic graph is particularly efficient for low connectivity modules, while the cross graph is more efficient when the modules have high connectivity. Interestingly, for connectivity Kmean = 5 and higher, when both graphs have roughly the same size, the cross graph method becomes even more rapid than the asymptotic graph.
Finally, since both graphs were computed it was possible to evaluate the quality of the asymptotic graph predictions. Recall that according to Theorem 1, the asymptotic graph has two drawbacks. First, it may predict spurious attractors and second, when it identifies a true attractor it only predicts a subset π(R) of the states lying in the attractor Q. The ratio is called the accuracy of the prediction. Among the 2,000 interconnections, 11 presented spurious attractors that is only 0.55% of the total. In all but one case, only one spurious attractor was detected. This result confirms the rarity of the appearance of spurious attractors. In total, we identified 3,693 true attractors. Among them more than 73% were completely recovered (see Figure 2D); overall, the mean accuracy is about 0.86, exhibiting the excellent predictive power of the asymptotic graph when it comes to uncover the asymptotic behaviors of an interconnection.
According to the previous results, the asymptotic graph seems particularly well adapted when the mean connectivity of the modules is low (≤ 5), which is arguably where biological networks generally operate (Zañudo and Albert, 2013; Veliz-Cuba et al., 2014). Therefore we decided to test it further with higher dimensional interconnections, including four modules ΣA, ΣB, ΣC, ΣD of dimension n = 15, with Kmean ∈ {1, …, 5}, pA = qA = pD = qD = 1 and pB = qB = pC = qC = 2:
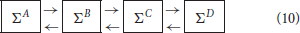
When Ncr < 107, the cross graph was also constructed and analyzed, in order to check the existence of spurious attractors. Since the global state space is 260 > 1018, we skipped the last treatment (identification of the attractors in {0, 1}60) to avoid possible explosions. Therefore, we only computed the terminal SCCs of Gas and, when available, the terminal SCCs of Gcr. The results are presented in Table 1. When Gcr could be analyzed, we were able to detect spurious attractors in Gas: none were found. If the cross graph method is not practical for small Kmean, the asymptotic graph was always manageable, confirming its practical interest to analyze large biological networks, as long as they can be expressed as interconnections of modules with a reasonable number of inputs and outputs.
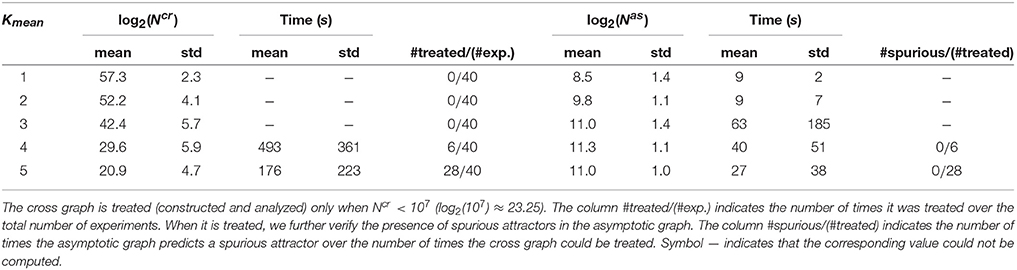
Table 1. Computational results for 200 interconnections of four 15-dimensional modules [according to (10)], split into five groups of 40, sorted along the mean connectivity of the modules.
The asymptotic graph construction and its probabilistic interpretation are now applied to two biological examples, centered on the mammalian and yeast cell cycles. Both cases illustrate the asymptotic graph concept, its informative description of a composite system, and its usefulness for testing biological hypotheses.
There are two basic cellular oscillators in mammalian cells: cell cycle describes the different phases of cellular growth and division, while circadian clock decribes the mechanism responsible for anticipating environmental changes and adapting the organism to deal with these changes (most notably, day-night differences). The interactions between these two oscillators are still not fully understood, but recent works by Feillet et al. (2014) and Bieler et al. (2014) have uncovered unexpected bi-directional links between the two modules. Successful mathematical models for the cell cycle and clock have been developed, as well as some studies on their interactions (Gérard and Goldbeter, 2012), but many questions remain (Feillet et al., 2015).
At the discrete level, a reference model of the cell cycle was developed and discussed by Fauré et al. (2006) (see Figure 3). It comprises 10 variables:
where CycX (X ∈ {A, B, D, E}) represent four cyclins, each roughly corresponding to one of the four phases of the cell cycle. This constitutes our module ΣA, and its rules can be found in the Supplementary Material. The clock model (module ΣB) has 7 variables and is based on the work of Comet et al. (2012). To account for transcription shutdown during mitosis, the input v negatively affects all mRNAs:
In the clock model, mX and pX denote mRNA and protein coded by gene X, while PC denotes the complex formed by the proteins PER and CRY, and PCnuc denotes this complex in the nucleus.
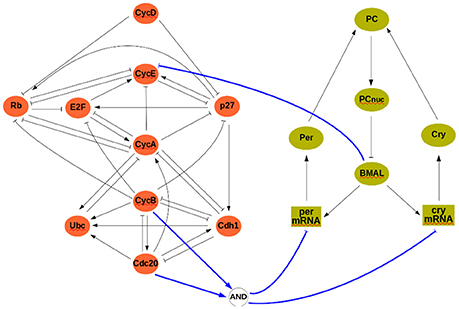
Figure 3. The interconnected mammalian cell cycle (Left, adapted from Fauré et al., 2006) and clock (Right, adapted from Comet et al., 2012). Square symbols represent messenger RNAs. Solid blue arrows denote input/output connections.
A well established link between these two oscillators is that protein BMAL acts on the cell cycle, possibly at different stages (Feillet et al., 2015). In our analysis, we will consider BMAL acting during G1 phase. Although no conclusive evidence exists on how the cell cycle may affect the clock, we have considered that during cell division (or mitosis phase) gene expression is stopped (in the model, mitosis can be modeled as Cdc20∧CycB, see Figure 3). The interconnection between modules is thus given by:
so that u = 0 (resp., u = 1) represents absence (resp., presence) of BMAL and υ = 1 represents mitosis. In the cell cycle model, BMAL affects negatively the G1 phase, leading to a logical equation for cyclin E of the form cycE+ = ¬u∧(E2F∧¬Rb) (see Figure 3 and Supplementary Material).
Module ΣA has a total of six, and module ΣB has a total of three, same-output attractor sets. For algorithmic convenience, these are labeled using the lexicographic convention, that is for , where “decimal 1 = logical 0” and “decimal 2 = logical 1.” The attractors for both modules are as follows:
In the case u = 0, module ΣA becomes exactly the original model constructed by Fauré et al. (2006). Therefore, as expected, the attractors found for GA,u=0 correspond exactly to those listed by Fauré et al. (2006). Attractors and correspond to a steady state where the only expressed proteins are Rb, p27, and Cdh1, hence representing the quiescent cell state. The (full) attractor is a cyclic attractor containing 112 distinct states and corresponds to the known G1/S/G2/M cell cycle progression (Fauré et al., 2006). Similarly, is a cyclic attractor of the graph GA,u=1, with 56 states. It tends to describe the cell cycle progression, with the difference that u = 1 implies CycE ≡ 0. In either of the cyclic attractors, the attractor-sets and contain states representing mitosis, that is, the output of any state satisfies hA(a) = Cdc20 ∧ CycB = 1.
The clock mechanism admits a cyclic attractor with 120 states, , which corresponds to regular circadian oscillations in the case υ = 0. At mitosis, represented by υ = 1, the clock network admits a single steady state attractor (), where all gene expression is arrested.
The asymptotic graph for the interconnection of the two mammalian oscillators has 18 nodes and two attractors, with separate basins of attraction (Figure 4):
The cross graph contains 54,272 nodes (compare to the full size of the interconnection, 217 = 131072) and confirms the existence of exactly two cyclic attractors for the interconnected system and returns all their elements: attractor R1 is composed of 120 states and R2 is composed of 13,552 states.
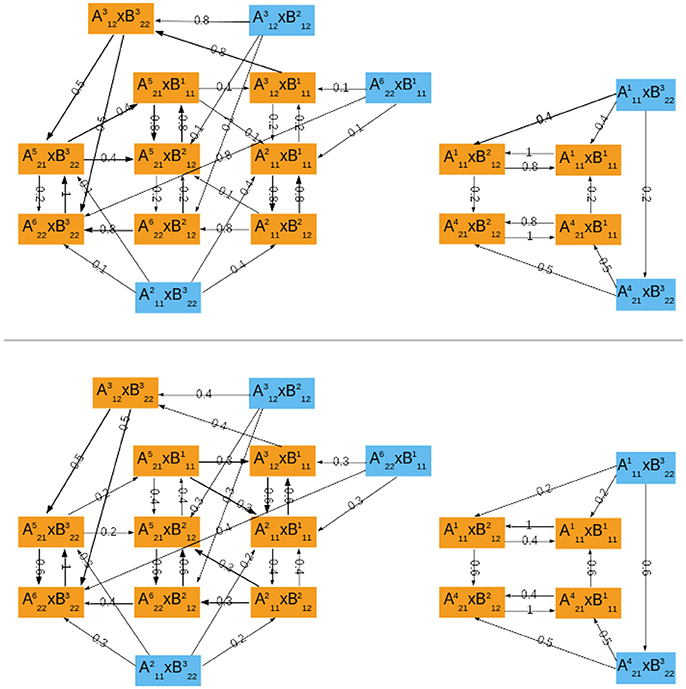
Figure 4. The probabilistic asymptotic graph for the interconnected mammalian oscillators. Orange colored nodes belong to an attractor: R1 at right and R2 at left. Bold arrows represent transitions with probability ≥ 0.5. (Top) ϱA = 0.2. (Bottom) ϱA = 0.6.
Our methodology predicts two distinct operating modes for the coupled oscillators: R1 corresponds to a quiescent cell with oscillatory clock, since it is the product of state 0100010100 representing a quiescent cell in module ΣA and of cyclic attractor representing regular clock oscillations. The attractor R1 is thus in agreement with observations by Plikus et al. (2013) (hair cells in quiescent phase seem to have a running clock). In contrast, R2 represents joint oscillations of the cell progression cycle () and clock () (see Figure 4 for the dynamics within R2). The cell cycle and clock may jointly oscillate and alternate states with a regular cycle of cyclin E (which is present mostly through S phase and mitosis) or eventually switch to a joint cycle with absence of cyclin E (). However, at mitosis (), the clock may switch to its arrested steady state (), which leads directly to a full degradation of cyclin E in the cell cycle ().
To assign transition probabilities to the asymptotic graph, there are essentially two elements to define: ϱA which is the probability of updating first the component from module ΣA; and the incidence probability of each attractor from each module, and . To compute the incidence probabilities and , we have used the size of the original basins of attraction of in ΣA and in ΣB, as in (4). However, for both modules, each attractor can be reached from any state, implying that the joint incidence probabilities, , are equal for all nodes of the asymptotic graph with: (i = 1, …6) and (j = 1, …3).
Figure 4 shows the transition probabilities obtained for two different values of the updating probability ϱA. These two graphs are very similar, differing only on the most frequent transitions (bold arrows, above 0.5). As should be expected, whenever the probability of first updating components from ΣA is larger (ϱA = 0.6), the cell cycle oscillations dominate the global dynamics: most of the bold transitions in Figure 4 (bottom) concern switches between attractor-sets of ΣA. In contrast, circadian clock oscillations are dominant for ϱA = 0.2 (Figure 4, top). The evolution from mitosis phase toward cell cycle progression () is equally probable for either ϱA.
Computation of the relative probabilities (8) of reaching one of the attractors of the interconnected network yields
independently of the updating probability ϱA. An interpretation of these relative probabilities is that, in a typical population of cells, about one third are arrested in quiescent G0 state while the other two thirds follow the normal cell cycle progression G1/S/G2/M.
Cell cycle and division is intimately linked with cell growth: a cell cannot divide into two daugther cells if its size is too small. There are many other factors that play a role in cell division (concentration of certain proteins, volume), but it remains unclear how a cell is able to perceive its own size and evaluate whether all conditions are in place for cell division (Turner et al., 2012).
In budding yeast, cell cycle is triggered by a START signal which is dependent on cell size. Li et al. (2004) propose a Boolean model that accurately describes cell cycle progression, taking START as an external input and stopping at a G1 phase steady state. One of the most important proteins involved in START is cyclin Cln3, which in involved in the G1-S phase transition and initiates cell cycle in the model of Li et al. (2004). Cyclin Cln3 forms a complex with another protein Whi3 but, in order to initiate cell cycle, Cln3 must be folded and released from this complex, which is achieved with the help of a chaperon protein Ydj1. Recent work by Aldea et al. (2017) suggests that cell size is growth rate dependent and that Ydj1 is one of the most important factors relating growth rate to cell size at START.
A reference discrete model for the cell cycle was developed by Li et al. (2004). It comprises 11 variables:
with START given by Cln3 (see Figure 5; the Boolean rules can be found in the Supplementary Material).
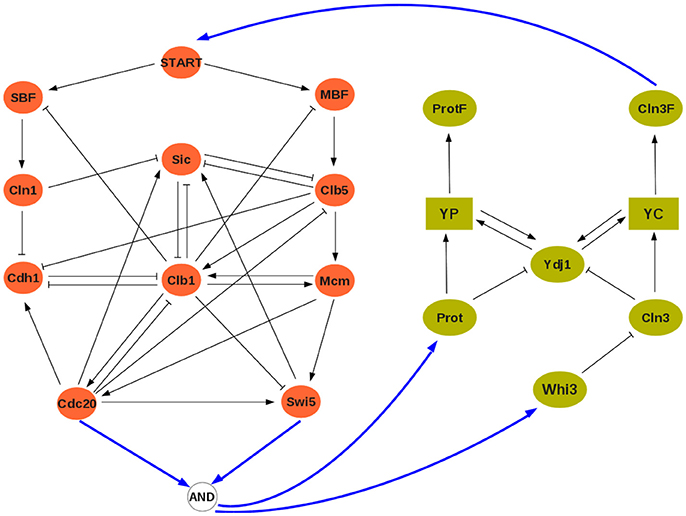
Figure 5. The interconnected yeast cell cycle (Left, adapted from Li et al., 2004) and cell size network (Right, adapted from Aldea et al., 2017). Square symbols represent messenger RNAs. Solid blue arrows denote input/output connections.
To describe cell size dependence on growth rate Aldea et al. (2017) proposes a model where Cln3 competes with a second hypothetical protein Prot for binding with Ydj1 for folding:
and Prot would be a growth rate dependent protein. Here, we propose a basic Boolean network of this model, where the dependence on growth rate is modeled by an input υ:
The competition of Prot and Cln3 for Ydj1 is represented by the term ¬(Prot ∧ Cln3) in the rule for Ydj1 meaning that, in the absence of both Prot and Cln3, “free” protein Ydj1 will be available. Both Prot and Whi3 depend on growth rate, here given by input υ. Later on, υ will be computed as an output from the cell cycle model.
Computation of the graphs GA,u and GB,v yields the following attractors:
The symbol * in or means that the output of this attractor depends on the function hA(a): three different forms for hA(a) will be tested (see 13–15 below). For instance, we have whenever hA(a) is given by (15), so we should write ; but in the other two cases, hence .
In the case u = 0, the yeast cell cycle model is exactly the one studied by Li et al. (2004) hence, as expected, the seven attractors of GA,u=0 are those listed in Table 1 of this reference. According to Li et al. (2004), attractor represents the G1 steady state and has the largest attraction basin. Attractor is also close to G1 phase and has the second largest attraction basin. Using the size of the attractions basins, the incidence probabilities have been computed according to Equation (4) and they are listed in Table 2.
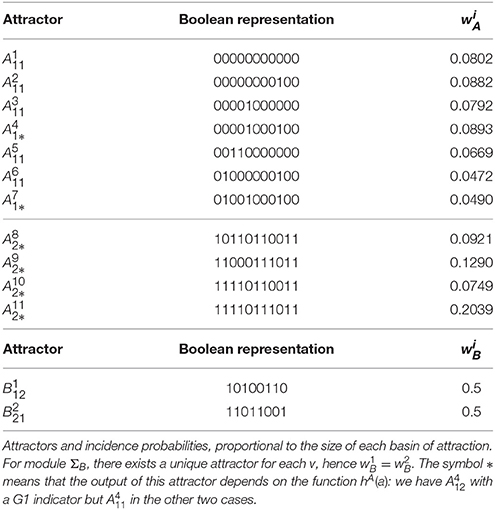
Table 2. Interconnection of yeast models.
To establish a scheme of interconnection, observe that the cell size model acts on the cell cycle by triggering the start signal, that is START is given by (folded/free) protein Cln3F. Conversely, the input of the cell cycle to the cell size module is still unknown, the combination of variables and/or quantities used by the cell to detect its own size is a question for further analysis. As an hypothesis, we will assume that growth rate is detected through cell phase, since the cell cycle model provides this information. To explore the plausibility of this hypothesis, we will thus consider three different indicators of the cell cycle phase (M, S, and G1 phases) and compare the asymptotic graphs of the three corresponding interconnection schemes:
In the case of growth measured by M phase (hA(a) = Swi5∧Cdc20), the asymptotic graph has a unique, cyclic, attractor (Figure 6, top):
This information is confirmed and complemented by computation of the cross graph, which has 524,288 nodes (= 219). Attractor is composed of 116,520 states.
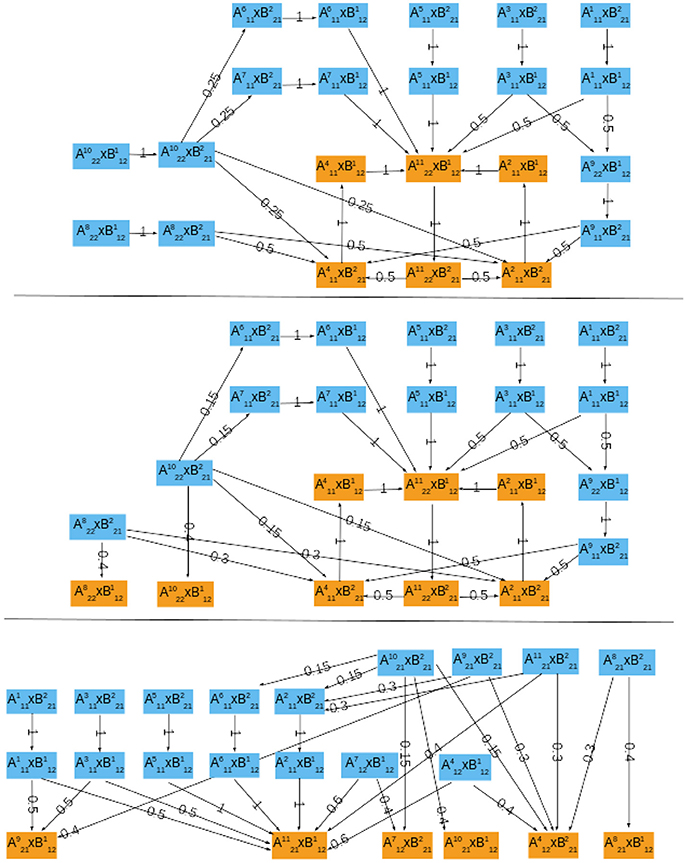
Figure 6. The probabilistic asymptotic graphs for the interconnected yeast network, with growth rate measured by different indicators of the cell cycle. Orange colored nodes belong to an attractor. (Top) M phase indicator, there is exactly one (cyclic) attractor. (Middle) S/G2 phase indicator, there are two single state attractors and one cyclic attractor. (Bottom) G1 phase indicator, there are six single state attractors.
Interestingly, although neither ΣA nor ΣB have periodic orbits, in this case the interconnected network does exhibit an oscillatory orbit: at stationary G1 () the START signal () is received and the module ΣA performs one cell cycle:
setting Cln3 back to its OFF state () and ending “near” M phase (). At this point, the system returns to stationary G1 and repeats the cycle, waiting for cell to grow and again send the start signal. Two alternative paths are proposed for the cell cycle, with G1-phase described either by or similar state . Since Gas contains a unique attractor, its relative probability Prel is necessarily 1.
In the case of growth rate measured by S phase (hA(a) = Clb5), the asymptotic graph (Figure 6, middle) has three attractors, two single steady state and one cyclic attractor:
In this case, however, computation of the cross graph shows that is a spurious attractor, implying that the asymptotic graph has lost some information on transient pathways. In practice, the full graph contains pathways eventually leading from to either or . This example shows the importance of verifying whether any of the asymptotic graph's attractors is spurious, and hence the usefulness of a complementary method as the cross graph. In this situation, the probabilistic interpretation of the asymptotic graph is unclear. The relative probabilities computed according to (8) yield equal probabilities for reaching attractors and (see Table 3). In contrast, must now be interpreted as a transient set of states.
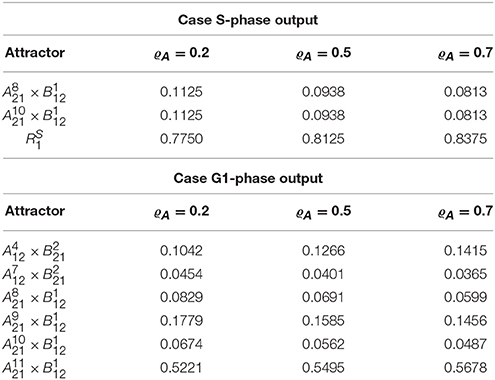
Table 3. Attractors of the yeast interconnected system and their relative probabilities, Prel(Ri), for different updating probabilities ϱA.
In the case G1 is used as measure of growth rate, we have hA(a) = Cdh1∧Sic and the asymptotic graph (Figure 6, bottom) has six single state attractors but no cyclic attractor:
All these attractors are confirmed by the cross graph. Computation of relative probabilities shows that the single steady state is more frequently observed (with a percentage of around 54%, see Table 3). In this state all proteins of the cell cycle are expressed except for Cdh1 and Sic1, which characterize stationary G1 phase. The cell growth module is in a state where Cln3F is available, thus setting START to 1. The interconnected system is thus locked in a steady state where the interaction links are fixed: = 11110111011 × 10100110, since the output of each attractor is equal to the input of the other.
These results appear to support a model for START signal of the form (12), as suggested by Aldea et al. (2017). Indeed, if cell size triggers START, then it can be assumed that there is a “critical size” which will be attained most probably at the end of G2 phase. And, in fact, the interconnected system exhibits an oscillatory cycle only in the case of M phase used as cell size indicator. This cycle is in agreement with cell cycle progression, meaning that the cell size module is able to trigger the START signal.
In contrast, when G1 or S phases are used as cell size indicator, the interconnected system has no oscillatory behavior. For the G1 case, the most frequent steady state () represents a configuration where the cell size module permanently sets Cln3F = 1, and does not admit cell size to reset to zero. Note that G1 is the beginning of the cell cycle and a misleading indicator of “critical” size; in this case, the “critical” size is so small that the cell size module sets START permanently to 1 thus preventing the cell cycle to reset to zero and initiate a new cycle. Cells are locked in a steady state near mitosis and before early G1.
In conclusion, our analysis shows that neither G1 nor S phases are reliable cell growth indicators, but components from M phase are plausible candidates for detecting cell growth. We point out that the cell size Boolean network and the feedback interconnection points may admit several improvements, which are outside the scope of our paper. Nevertheless, we believe this first approach provides useful hints on how to further investigate and model the START signal in yeast.
Our work illustrates a new concept for the analysis of an interconnection of Boolean networks: the goal is to study the coupled behavior of two or more modules, using only the dynamics of each separate module. A new methodology has been discussed, based on construction of the asymptotic and cross graphs both representative of the full network transition graph and guaranteed to compute all attractors of the interconnected network. The two graphs have different properties but also complement each other. The cross graph provides exact results, in the sense that it contains all transient and asymptotic behaviors of the interconnected network. The asymptotic graph is a lighter construction containing a minimal number of nodes while recovering all attractors. In contrast to the cross graph, no bijection with the full network transition graph is guaranteed, implying that spurious attractors may appear; however, this happens at an extremely low rate (less than 1%).
Construction of the two graphs for random input/output networks with varying connectivity reveals their complementarity in terms of modules' connectivity: for low connectivity (Kmean ≤ 5), the asymptotic graph is much smaller (on average 0.01% of the full graph, against 28% for the cross graph; Figure 2B) and faster to compute; in contrast, for high connectivity (Kmean > 5), the size of the cross graph drastically reduces to 0.04% of the full graph (Figure 2A) becoming even faster to analyze than the asymptotic graph (Figure 2C). In addition, even though the asymptotic graph involves a drastic simplification of the state space, it has an unexpectedly high rate of accuracy, as shown in Figure 2D.
The practical advantages of our methodology are illustrated by the study of two well known biological networks. Among other useful characteristics, the asymptotic graph can greatly reduce the size of the state space, especially in the case of single-input single-output modules. For instance the mammalian and yeast interconnected networks, with an average connectivity of K = 2.76 and K = 2.68 respectively, have asymptotic graphs of only 18 and 22 nodes (compared to 217 or 219).
The analysis of the coupling between cell cycle and circadian clock shows that, according to experimental observations (for instance by Plikus et al., 2013), the asymptotic graph predicts that mammalian cells in the quiescent state may have a working clock. Furthermore, under general hypotheses, the probabilistic approach predicts that one third of cells are arrested in the quiescent state but still have circadian oscillations, while the other two thirds follow a normal cell cycle progression intertwined with circadian oscillations. In the budding yeast example, we have explored a recent hypothesis by Aldea et al. (2017) for a mechanism to trigger the START signal and initiate cell cycle. The mechanism is based on cell size detection through cell growth rate. Our analysis supports such a mechanism as a possible START trigger, and suggests that cell size indicator should come from an element during M phase.
The advantages of our analysis tools are multiple and particularly suited to the modeling of biological regulatory networks: by manipulating existing models as building blocks, the presented tools allow to rapidly simulate, compare, and test different coupling schemes or hypotheses on mutual regulatory effects, and therefore advance in the understanding of highly modular regulatory networks. The probabilistic interpretation and the analysis of transient behaviors emerge as two noteworthy directions for future developments in logical models.
MC and LT: equally contributed to conception, analysis and design of the study; MC and LT: wrote and revised the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
MC and LT are partly supported by the French agency for research through project ICycle ANR-16-CE33-0016-01. MC is partly funded by Labex Signalife ANR-11-LABX-0028-01.
The Boolean models used for mammalian and budding yeast cell cycles are provided as Supplementary Material.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2018.00586/full#supplementary-material
Abou-Jaoudé, W., Traynard, P., Monteiro, P. T., Saez-Rodriguez, J., Helikar, T., Thieffry, D., et al. (2016). Logical modeling and dynamical analysis of cellular networks. Front. Genet. 7:94. doi: 10.3389/fgene.2016.00094
Albert, R., and Othmer, H. G. (2003). The topology of the regulatory interactions predicts the expression pattern of the Drosophila segment polarity genes. J. Theor. Biol. 223, 1–18. doi: 10.1016/S0022-5193(03)00035-3
Aldea, M., Jenkins, K., and Csikász-Nagy, A. (2017). Growth rate as a direct regulator of the start network to set cell size. Front. Cell Dev. Biol. 5:57. doi: 10.3389/fcell.2017.00057
Baldazzi, V., Ropers, D., Markowicz, Y., Kahn, D., Geiselmann, J., and de Jong, H. (2010). The carbon assimilation network in Escherichia coli is densely connected and largely sign-determined by directions of metabolic fluxes. PLoS Comput. Biol. 6:e1000812. doi: 10.1371/journal.pcbi.1000812
Bérenguier, D., Chaouiya, C., Monteiro, P. T., Naldi, A., Remy, E., Thieffry, D., et al. (2013). Dynamical modeling and analysis of large cellular regulatory networks. Chaos 23:025114. doi: 10.1063/1.4809783
Bieler, J., Cannavo, R., Gustafson, K., Gobet, C., Gatfield, D., and Naef, F. (2014). Robust synchronization of coupled circadian and cell cycle oscillators in single mammalian cells. Mol. Syst. Biol. 10:739. doi: 10.15252/msb.20145218
Calzone, L., Tournier, L., Fourquet, S., Thieffry, D., Zhivotovsky, B., Barillot, E., et al. (2010). Mathematical modelling of cell-fate decision in response to death receptor engagement. PLoS Comput. Biol. 6:e1000702. doi: 10.1371/journal.pcbi.1000702
Chaves, M., and Carta, A. (2015). Attractor computation using interconnected boolean networks: testing growth rate models in E. coli. Theor. Comput. Sci. 599, 47–63. doi: 10.1016/j.tcs.2014.06.021
Chaves, M., and Tournier, L. (2011). “Predicting the asymptotic dynamics of large biological networks by interconnections of Boolean modules,” in Proceedings of the 50th conference Decision and Control and European Control conference (Orlando, FL), 3026–3031.
Comet, J.-P., Bernot, G., Das, A., Diener, F., Massot, C., and Cessieux, A. (2012). Simplified models for the mammalian circadian clock. Proc. Comput. Sci. 11, 127–138. doi: 10.1016/j.procs.2012.09.014
Cormen, T., Leiserson, C., Rivest, R., and Stein, C. (2001). Introduction to Algorithms. Providence, RI: MIT Press, McGraw-Hill.
Fauré, A., Naldi, A., Chaouiya, C., and Thieffry, D. (2006). Dynamical analysis of a generic boolean model for the control of the mammalian cell cycle. Bioinformatics 22, 124–131. doi: 10.1093/bioinformatics/btl210
Feillet, C., Krusche, P., Tamanini, F., Janssens, R. C., Downey, M. J., Martin, P., et al. (2014). Phase locking and multiple oscillating attractors for the coupled mammalian clock and cell cycle. Proc. Natl. Acad. Sci. U.S.A. 111, 9828–9833. doi: 10.1073/pnas.1320474111
Feillet, C., van der Horst, G. T., Lévi, F., Rand, D. A., and Delaunay, F. (2015). Coupling between the circadian clock and cell cycle oscillators: implication for healthy cells and malignant growth. Front. Neurol. 6:96. doi: 10.3389/fneur.2015.00096
García-Gómez, M., Azpeitia, E., and Álvarez-Buylla, E. (2017). A dynamic genetic-hormonal regulatory network model explains multiple cellular behaviors of the root apical meristem of Arabidopsis thaliana. PLoS Comput. Biol. 13:e1005488. doi: 10.1371/journal.pcbi.1005488
Gérard, C., and Goldbeter, A. (2012). Entrainmemt of the mammalian cell cycle by the circadian clock: modeling two coupled cellular rhythms. PLoS Comput. Biol. 8:e1002516. doi: 10.1371/journal.pcbi.1002516
Kauffman, S. (1969). Metabolic stability and epigenesis in randomly constructed genetic nets. J. Theor. Biol. 22, 437–467. doi: 10.1016/0022-5193(69)90015-0
Klarner, H., Bockmayr, A., and Siebert, H. (2015). Computing maximal and minimal trap spaces of Boolean networks. Nat. Comput. 14, 535–544. doi: 10.1007/s11047-015-9520-7
Li, F., Long, T., Lu, Y., Ouyang, Q., and Tang, C. (2004). The yeast cell cycle is robustly designed. Proc. Natl. Acad. Sci. U.S.A. 101, 4781–4786. doi: 10.1073/pnas.0305937101
Mendoza, L., and Xenarios, I. (2006). A method for the generation of standardized qualitative dynamical systems of regulatory networks. Theor. Biol. Med. Model. 3, 1–18. doi: 10.1186/1742-4682-3-13
Mori, T., Flöttmann, M., Krantz, M., Akutsu, T., and Klipp, E. (2015). Stochastic simulation of boolean rxncon models: towards quantitative analysis of large signaling networks. BMC Syst. Biol. 9:45. doi: 10.1186/s12918-015-0193-8
Plikus, M. V., Vollmers, C., de la Cruz, D., Chaix, A., Ramos, R., Panda, S., et al. (2013). Local circadian clock gates cell cycle progression of transient amplifying cells during regenerative hair cycling. Proc. Natl. Acad. Sci. U.S.A. 110, E2106–E2115. doi: 10.1073/pnas.1215935110
Sabidussi, G. (1959). Graph multiplication. Mathematische Zeitschrift 72, 446–457. doi: 10.1007/BF01162967
Saez-Rodriguez, J., Simeoni, L., Lindquist, J. A., Hemenway, R., Bommhardt, U., Arndt, B., et al. (2007). A logical model provides insights into T cell receptor signaling. PLoS Comput. Biol. 3:e163. doi: 10.1371/journal.pcbi.0030163
Shmulevich, I., Dougherty, E. R., Kim, S., and Zhang, W. (2002). Probabilistic boolean networks: a rule-based uncertainty model for gene regulatory networks. Bioinformatics 18, 261–274. doi: 10.1093/bioinformatics/18.2.261
Stoll, G., Caron, B., Viara, E., Dugourd, A., Zinovyev, A., Naldi, A., et al. (2017). Maboss 2.0: an environment for stochastic boolean modeling. Bioinformatics 33, 2226–2228. doi: 10.1093/bioinformatics/btx123
Tournier, L., and Chaves, M. (2013). Interconnection of asynchronous Boolean networks, asymptotic and transient dynamics. Automatica 49, 884–893. doi: 10.1016/j.automatica.2013.01.015
Turner, J., Ewald, J. C., and Skotheim, J. M. (2012). Cell size control in yeast. Curr. Biol. 22, R350–R359. doi: 10.1016/j.cub.2012.02.041
Veliz-Cuba, A., Aguilar, B., Hinkelmann, F., and Laubenbacher, R. (2014). Steady state analysis of boolean molecular network models via model reduction and computational algebra. BMC Bioinformatics 15:221. doi: 10.1186/1471-2105-15-221
Wang, R. S., Saadatpour, A., and Albert, R. (2012). Boolean modeling in systems biology: an overview of methodology and applications. Phys. Biol. 9:055001. doi: 10.1088/1478-3975/9/5/055001
Zañudo, J., and Albert, R. (2013). An effective network reduction approach to find the dynamical repertoire of discrete dynamic networks. Chaos 23:025111. doi: 10.1063/1.4809777
Zhang, R., Shah, M. V., Yang, J., Nyland, S. B., Liu, X., Yun, J. K., et al. (2008). Network model of survival signaling in large granular lymphocyte leukemia. Proc. Natl. Acad. Sci. U.S.A. 105, 16308–16313. doi: 10.1073/pnas.0806447105
Let = (, ) be a digraph and let ν, ν′ ∈ be any two vertices of . Introduce the following notation:
• ν → ν′ means that there is an edge from ν to ν′ in , i.e., (ν, ν′) ∈ (ν′ is a successor of ν).
• ν ▹ ν′ means that there exists a path from ν to ν′ in , i.e., there exist k ≥ 0 vertices ν1, …, νk such that ν = ν1 → ν2 → … → G νk = ν′ (ν′ is a descendant of ν).
• ν ~ ν′ means that there exists a path from ν to ν′ and a path from ν′ to ν in (ν and ν′ are mutually reachable from each other). The relation ~ is an equivalence over × .
Remark that according to the definition of partition , any is included in a SCC of each graph GA,u, in other words:
For convenience, we introduce the two following maps π and ψ, establishing relationships between the two vertex sets Vcr and Ω = {0, 1}nA + nB.
• For V = × ∈ Vcr, let π(V): = {(a, b)|a ∈ , b ∈ } ⊆ Ω; and for Q = {V1, …, Vk} ⊆ Vcr, define .
• For x = (a, b) ∈ Ω, by definition of there is a unique and a unique such that ∋ a, ∋ b. Let ψ(x): = × ; by extension, for S ⊆ Ω, define ψ(S): = {ψ(x)|x ∈ S} ⊆ Vcr.
Theorem 2 is a consequence of the two following lemmas.
LEMMA 1. Let x, y ∈ Ω such that x ▹ G y, then either ψ(x) = ψ(y), or ψ(x) ▹ Gcr ψ (y).
PROOF. Suppose first that x → G y, that is to say either (i): x = (a, b) → G (a′, b) = y where a → GA,hB(b) a′ or (ii): x = (a, b) → G (a, b′) = y where b → GB,hA(a) b′. These two cases being perfectly symmetrical, consider for instance case (i). Let and be respectively the (unique) sets such that and . Two cases are to be considered.
Case 1: suppose , then ψ(x) = × = ψ(y).
Case 2: suppose . Then according to the definition of Gcr, from a → GA,β a′ we deduce that .
Suppose now that x ▹ G y, ie., x = x1 → G x2 → G … → G xk = y. By applying successively the previous result along that path, we deduce that either ψ(x) = ψ(y) or ψ(x) ▹ Gcr ψ (y), which concludes the proof. □
LEMMA 1. Let V, V′ ∈ Vcr be two vertices of the cross graph.
(i) ∀x, y ∈ π(V), x ~ G y.
(ii) If V ▹ Gcr V′, then for all x ∈ π(V) and y ∈ π(V′), x ▹ G y.
PROOF. Let start with assertion (i). Let V = × , x = (a, b) ∈ π(V) and y = (a′, b′) ∈ π(V). Since a and a′ both belong to the same . In the same way, b ~ GB,α b′. From there it is easy to verify that (a, b) ~ G (a′, b) ~ G (a′, b′), so x ~ G y. Let us prove the second assertion. Suppose first that V → Gcr V′. For instance, let and with (the symmetrical case can be treated completely analogously). Let x = (a, b) ∈ π(V) and y = (a′, b′) ∈ π(V′). Since a and a1 both belong to the same , we have a ~ GA,β a1. Similarly , implying a′ ~ GA,β a2. Therefore we have a ~ GA,β a1 → GA,β a2 ~ GA,β a′, hence (a, b)▹G (a′, b). Now, since b and b′ both belong to the same b ~ GB,α′ b′, which proves that (a′, b)▹G (a′, b′), therefore x▹ G y.
Suppose now that V ▹ Gcr V′, ie., V = V1 → Gcr V2 → Gcr … → Gcr Vk = V′. By applying successively the previous result along that path, we deduce that x▹ G y for any x ∈ π(V) and y ∈ π(V′).
Lemmas 1 and 2 establish an exact correspondence between the paths in G and the paths in Gcr. The proof of the theorem becomes rather straightforward. Indeed, suppose Q = {V1, …, Vk} is a SCC of Gcr. Then Lemma 2 implies that π(Q) is included in a SCC S of G. Suppose now that π(Q) ⊊ S, ie. there exists y ∈ S\ π (Q) such that ψ(y) ∉ Q. For any x ∈ π(V) ⊂ S, we have x ~ G y (with Lemma 1), implying ψ(y) ∈ Q which is a contradiction. Therefore, π(Q) = S. Reciprocally, suppose S ⊆ Ω is a SCC of G. Then lemma 1 implies that ψ(S) is included in a SCC Q of Gcr. Lemma 2 further yields ψ(S) = Q. By using a similar kind of reasoning, it is easy to show that there is an exact one-to-one correspondence between the terminal SCCs of Gcr and the attractors of G.
Keywords: asynchronous Boolean networks, module interconnection, state transition graph, attractor computation, biological regulatory networks
Citation: Chaves M and Tournier L (2018) Analysis Tools for Interconnected Boolean Networks With Biological Applications. Front. Physiol. 9:586. doi: 10.3389/fphys.2018.00586
Received: 01 February 2018; Accepted: 02 May 2018;
Published: 29 May 2018.
Edited by:
Matteo Barberis, University of Amsterdam, NetherlandsReviewed by:
Laurence Calzone, Institut Curie, FranceCopyright © 2018 Chaves and Tournier. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Madalena Chaves, bWFkYWxlbmEuY2hhdmVzQGlucmlhLmZy
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.