 Ella Dubinsky
Ella Dubinsky Emily A. Wood
Emily A. Wood Gabriel Nespoli1
Gabriel Nespoli1 Frank A. Russo
Frank A. Russo- 1Department of Psychology, Ryerson University, Toronto, ON, Canada
- 2Toronto Rehabilitation Institute, Toronto, ON, Canada
Prior studies have demonstrated musicianship enhancements of various aspects of auditory and cognitive processing in older adults, but musical training has rarely been examined as an intervention for mitigating age-related declines in these abilities. The current study investigates whether 10 weeks of choir participation can improve aspects of auditory processing in older adults, particularly speech-in-noise (SIN) perception. A choir-singing group and an age- and audiometrically-matched do-nothing control group underwent pre- and post-testing over a 10-week period. Linear mixed effects modeling in a regression analysis showed that choir participants demonstrated improvements in speech-in-noise perception, pitch discrimination ability, and the strength of the neural representation of speech fundamental frequency. Choir participants’ gains in SIN perception were mediated by improvements in pitch discrimination, which was in turn predicted by the strength of the neural representation of speech stimuli (FFR), suggesting improvements in pitch processing as a possible mechanism for this SIN perceptual improvement. These findings support the hypothesis that short-term choir participation is an effective intervention for mitigating age-related hearing losses.
Introduction
As the population ages, and the expectation of longevity increases, a growing interest in healthcare is the promotion of healthy aging – the maintenance of mental, social, and physical wellbeing as one ages, in order to retain independence and lead a high-quality life. Aging is associated with declines in cognitive functioning (e.g., decreased working memory and attentional control; for review, see Fabiani, 2012), and deteriorating sensory-perceptual processes (e.g., Fozard, 1990). Declines in hearing can make it difficult for aging individuals to maintain personal relationships and engage socially, and have been linked to feelings of isolation and depression (Arlinger, 2003; Djernes, 2006). Although assistive technologies (e.g., hearing aids) can target aspects of peripheral hearing loss, persistent perceptual deficits are widely reported (e.g., Killion, 1997). One prevalent example is the loss of the ability to perceive speech in a noisy environment (Salomon, 1986; Chmiel and Jerger, 1996; Gomez and Madey, 2001; Ricketts and Hornsby, 2005; Betlejewski, 2006). Counseling programs may improve communication outcomes associated with age-related auditory declines, but they do not appear to influence speech-in-noise problems (Hickson et al., 2007, 2019). While some auditory rehabilitation programs have been shown to be moderately effective in mitigating speech-in-noise problems (Kricos and Holmest, 1996; Sweetow and Sabes, 2006; Song et al., 2012), they require a high level of motivation and are not appropriate for all cases (Sabes and Sweetow, 2007; Saunders et al., 2016). As such, there is presently a great demand for complementary interventions that target age-related auditory declines, particularly ones that are engaging and scalable, and that show efficacy with regard to speech-in-noise perception. Developing and evaluating an intervention – and its proposed mechanism(s) for change – involves consideration of biological and experiential contributors to these abilities, beginning with age-related hearing loss and the role it plays in speech-in-noise perception.
Hearing loss can occur at different stages in the auditory system. Peripheral hearing loss refers to the reduction in efficient sound transmission through the bones of the middle ear (conductive hearing loss), and the deterioration of the outer and inner hair cells (sensorineural hearing loss; Arlinger, 2003; Yueh et al., 2003; Wingfield et al., 2005). Central hearing loss refers to the degradation of neural mechanisms that relay sound information from the cochlea to the brain, resulting from long-term attenuation of neural input from the cochlea, as well as age-related changes in neuronal responses to sound (Syka, 2002; Frisina and Walton, 2006; Yamasoba et al., 2013). Although peripheral losses can be remediated to some degree through the use of assistive technologies such as hearing aids (or, in extreme cases, cochlear implants), central processing deficits seem to persist in spite of such interventions (Chmiel and Jerger, 1996; Killion, 1997). These central processing deficits – including age-related declines in the synchrony of neural firing (Pichora-Fuller and Schneider, 1992; Frisina and Frisina, 1997; Pichora-Fuller et al., 2007), length of recovery time (Walton et al., 1998), and numbers of neurons in auditory nuclei (Frisina and Walton, 2006) – have been associated with age-related losses in key auditory perceptual abilities, such as sound localization (Abel et al., 2000), pitch discrimination (Raz et al., 1989), duration judgments (Fitzgibbons and Gordon-Salant, 1994; Schneider et al., 1994), mistuned harmonic detection (Alain et al., 2001), and speech-in-noise perception (Pichora-Fuller et al., 1995; Russo and Pichora-Fuller, 2008; Schneider et al., 2010). Of the perceptual deficits, the loss of speech-in-noise perception seems to have the most severe impact on the aging adult’s quality of life (e.g., Pichora-Fuller et al., 1995, 2007; Anderson et al., 2011).
Speech-in-noise perception refers to the ability to track a voice in a complex acoustic environment, such as a crowded room with many people talking. Vital in social settings and everyday interactions, the loss of this skill can immensely impact an individual’s ability to maintain independence, emotional wellbeing, and quality of life as they age (Salomon, 1986; Gomez and Madey, 2001; Betlejewski, 2006). This age-related decline also appears to persist in spite of peripheral remediation, and can even occur in adults with normal audiometric thresholds (Cruickshanks et al., 1998; Schneider B. A. et al., 2002; Tremblay et al., 2003; Gordon-Salant, 2005; Souza et al., 2007; Vermiglio et al., 2012; Alain et al., 2014); in research studies involving older individuals, pure-tone thresholds tend to be a poor predictor of speech-in-noise perception (Dubno et al., 1984; Hargus and Gordon-Salant, 1995; Kim et al., 2006; Souza et al., 2007).
One way to elucidate the neural underpinnings of speech-in-noise perception is through the use of electroencephalography (EEG recordings) to study cortical and subcortical responses to acoustic stimuli (Tremblay et al., 2003; Musacchia et al., 2008; Anderson et al., 2011). Of particular interest here, the auditory brainstem – a collection of nuclei involved in afferent and efferent auditory processing – has been shown to encode spectral and temporal acoustic information with a high degree of precision (Clinard et al., 2010; Skoe and Kraus, 2010).
One component of the auditory brainstem response (ABR; Skoe and Kraus, 2010) that has been implicated in perceptual deficits – in particular, speech-in-noise perception – is the frequency following response (Johnson et al., 2005; Skoe and Kraus, 2010). This response consists of phase-locked neural activation, wherein the inter-spike intervals correspond to the fundamental frequency (F0) of the sound input (Hoormann et al., 1992). On the basis of animal work involving ablations, the primary source of the FFR appears to be the inferior colliculus (Smith et al., 1975), however recent work also suggests cortical contributions (Lehmann and Schönwiesner, 2014; Coffey et al., 2016, 2017a).
The FFR provides a useful index of the auditory nervous system’s representation of periodic sound – such as a vowel in speech – through sustained synchronous neural phase-locking. Spectral and temporal features of the FFR, obtained through signal analysis, are associated with different aspects of neural pitch encoding. A fast Fourier transform (FFT) of the signal yields a spectral analysis that can be used to assess the strength of the neural representation of periodic sound input (Skoe and Kraus, 2010). Another feature, the inter-trial phase coherence (ITPC), can be used to assess the extent of consistency in the neural response to periodic sound input – i.e., the extent of phase alignment (synchronization) in oscillatory responses (e.g., Delorme and Makeig, 2004).
In the perception of speech cues, the ability to discern and track changes in pitch over time gets significantly more difficult when the signal-to-noise ratio (SNR) decreases (e.g., Killion et al., 2004). By the time an acoustic signal reaches the auditory cortex of an aging adult, it is likely to have undergone both peripheral and neural distortion (due to age-related declines in sensorineural hearing, and neural noise introduced as the signal is relayed through the ascending auditory pathway, respectively), leading to diminished preservation of key temporal and spectral characteristics (e.g., Yueh et al., 2003; Clinard et al., 2010). This suggests a possible mechanism for age-related declines in speech-in-noise perception (and other auditory perceptual abilities which rely on pitch discrimination), whereby age-related central processing deficits (such as reduced FFR fidelity) result in downstream perceptual impairments which tend to persist in spite of peripheral remediation. In terms of mitigating and preventing these declines, one activity that appears to confer some benefits against certain age-related auditory losses is musical experience (e.g., Alain et al., 2014).
Musicianship is purported to have some benefits outside the musical domain, but the most convincing positive effects have been observed in regards to the auditory system (for review, see Herholz and Zatorre, 2012). Over the course of training, musicians are taught to attend to fine-grained acoustic features – including pitch, timing, and timbre – that contribute to human perception of sound (Kraus et al., 2009; Kraus and Chandrasekaran, 2010). This trained sensitivity to minute acoustic changes is thought to promote the enhancement of auditory perceptual abilities, including those which decline throughout the aging process (Musacchia et al., 2007; Parbery-Clark et al., 2012; Zendel and Alain, 2012; Alain et al., 2014). In studies comparing auditory perception in musicians and non-musicians, musical experience has been associated with a relative advantage in processing some of the same features that have been linked to age-related declines. These benefits include improved pitch discrimination (Kishon-Rabin et al., 2001; Micheyl et al., 2006; Schellenberg and Moreno, 2009; Bidelman et al., 2011b; Meha-Bettison et al., 2018), gap and duration judgments (Rammsayer and Altenmüller, 2006; Zendel and Alain, 2012; Habibi et al., 2014; Donai and Jennings, 2016), mistuned harmonic detection (Koelsch et al., 1999; Zendel and Alain, 2009), and perception of speech-in-noise (Parbery-Clark et al., 2009; for review see Coffey et al., 2017b).
Musicians also demonstrate structural and functional differences in the neural substrates of auditory, sensory-motor, and visuospatial processing (Musacchia et al., 2007; Kraus and Chandrasekaran, 2010; Schlaug, 2015). Among musicians, musical aptitude is correlated with an increase in gray matter volume in the primary auditory cortex, as well as somatosensory and motor areas, the inferior temporal gyrus, hippocampus, and corpus callosum regions (Schlaug et al., 1995; Schneider P. et al., 2002; Gaser and Schlaug, 2003; Herdener et al., 2010). In addition to structural changes in associated brain regions, musicians also demonstrate functional improvements in neural responses to sound, at cortical and subcortical levels in the auditory processing pathway. Compared with non-musicians, musicians demonstrate enhanced neural responses and activation in the auditory cortex (Koelsch et al., 1999; Schneider P. et al., 2002; Pantev et al., 2003; Shahin et al., 2003; Kuriki, 2006; Besson et al., 2007; Zendel et al., 2015; Habibi et al., 2016) and the auditory brainstem (Musacchia et al., 2007; Wong et al., 2007; Lee et al., 2009; Parbery-Clark et al., 2009; Strait et al., 2009; Bidelman and Krishnan, 2010). Notably, musicians demonstrate improvements in both FFR strength (Musacchia et al., 2007, 2008; Bidelman et al., 2011b; Slater et al., 2017) and consistency (Parbery-Clark et al., 2009; Strait et al., 2009; Bidelman et al., 2011a, b; Skoe and Kraus, 2013; Slater et al., 2017); these benefits appear largely resistant to normal age-related declines (Parbery-Clark et al., 2012; White-Schwoch et al., 2013). Because of the importance of pitch processing across auditory perceptual domains, FFR improvements have been suggested as one of the mechanisms through which musicianship enhances auditory perceptual abilities (Kraus and Chandrasekaran, 2010; Bidelman et al., 2011b; Coffey et al., 2017a).
While the aforementioned studies suggest that musical training can improve speech-in-noise perception, they are cross-sectional studies which should preclude causal inferences (Schellenberg, 2019); further, not all studies have found an effect (Ruggles et al., 2014; Boebinger et al., 2015; Madsen et al., 2017, 2019). One way to resolve these inconsistencies is through the evaluation of musical training outcomes in a controlled experimental design (i.e., a longitudinal context), which a handful of studies have sought to do. These studies essentially provided musical training to non-musicians (with the extent and nature of musical training varying between studies), and administered pre- and post-training assessments to determine whether changes occurred in outcomes of interest. In terms of neural changes, musical training has been found to enhance both structure (Hyde et al., 2009) and function (Fujioka et al., 2006; Lappe et al., 2008; Lappe et al., 2011; Habibi et al., 2016) of the auditory cortex in young children and adults who received musical training, compared to those who did not (control participants). Consistency of the FFR has also been found to be enhanced in adolescents following musical training (Tierney et al., 2015). Children who took part in instrumental music training showed improvements in speech-in-noise perception following 2 years of training (Slater et al., 2015), and younger adults who participated in singing training demonstrated improvements in speech-in-noise perception after only 8 days (Jain et al., 2015). Older adults with 6 months of piano training demonstrated improved cortical responses and speech-in-noise perception following training, suggesting that neural and perceptual benefits can be conferred to aging adults in an intervention context (Zendel et al., 2019).
In addition to improvements in auditory processing, musical training has been linked to enhancements in different aspects of cognitive functioning in older adults – including improvements in working memory and executive control processes – in both cross-sectional (Parbery-Clark et al., 2011; Slevc et al., 2016; Grassi et al., 2017; Mansens et al., 2017) and longitudinal studies (Bugos et al., 2007; Särkämö et al., 2014; Biasutti and Mangiacotti, 2018; Fu et al., 2018). Musical experience has also been shown to alter neural structure and function in regions associated with cognition (Schulze et al., 2011; West et al., 2017); improvements in shared neural substrates for music and non-music domains have been suggested as one possible mechanism for transfer from musical training to speech-in-noise perception (e.g., Kraus et al., 2012).
Taken together, cross-sectional and longitudinal findings suggest that musical training may be able to alter brain structure and function; moreover, it appears to have the capacity to promote enhancements in the same auditory abilities that decline as we age (Solé Resano et al., 2010; Hanna-Pladdy and MacKay, 2011; Zendel and Alain, 2012; Alain et al., 2014), suggesting its use as an intervention to mitigate declines in older adults. Of the forms of music making available, singing may be particularly suited to this purpose.
Singing emerges spontaneously in the first months of life (Papoušek, 1996), and appears to be a universal form of expression (Mithen et al., 2006). Although considerable variability in accuracy exists, the vast majority of adults appear to be able to carry a tune (Dalla Bella et al., 2007; Pfordresher and Brown, 2007; Dalla Bella and Berkowska, 2009). Group singing has been shown to lead to improvements in cooperation (Good and Russo, 2016), social and emotional wellbeing (Hillman, 2002; Bailey, 2005; Hays and Minichiello, 2005; Clift and Morrison, 2011; Creech et al., 2013), and physical and creative outcomes (Beck et al., 2000; Clift and Hancox, 2001; Cohen et al., 2006). Some of these benefits may be mediated by changes in hormonal levels that occur during choral singing: after choir practice, choristers demonstrate decreased cortisol (Beck et al., 2000) and enhanced immune system functioning more generally (Kreutz et al., 2004). Singing in a group can also be highly motivating for older adults (Hillman, 2002; Creech et al., 2013), which may promote intervention adherence. This is of particular import when singing is contrasted with existing auditory rehabilitation programs, which tend to be plagued by low compliance rates and high attrition (Sweetow and Sabes, 2010; Tye-Murray et al., 2012).
In addition to the social, cognitive, and emotional benefits, singing appears better positioned to confer near-transfer benefits to speech. All forms of vocal production involve the rapid integration of auditory and vocal-motor systems (Hickok, 2001; Zatorre et al., 2007; Pfordresher and Dalla Bella, 2011; Pruitt and Pfordresher, 2015); this integration requires feedback loops along the auditory dorsal stream that allow for real-time monitoring and adjustments (Houde and Jordan, 1998; Brainard and Doupe, 2000; Zheng et al., 2010). In a recent study that compared temporal lobe activations across perception of singing, instrumental music, and speech, it was found that compared with instrumental music, singing and speech both led to greater bilateral activations of the superior temporal sulcus (STS; Whitehead and Armony, 2018), a critical node in the auditory dorsal stream (Hickok et al., 2003).
In terms of perceptual processes, there is greater reliance on the vocal-motor system in more challenging listening environments, such as understanding speech-in-noise (Du et al., 2014); older adults rely on this to an even greater degree (Du et al., 2016). Training the vocal-motor system through singing could theoretically improve the resources upon which older adults draw to perceive degraded speech signals. An emphasis on pitch training, feedback, repetition, and the rewarding nature of improvements have been implicated as key components of successful auditory training paradigms, and in the transfer of musical experience to speech perceptual benefits (Besson et al., 2011; David et al., 2012; Herholz and Zatorre, 2012; Shepard et al., 2013; Patel, 2014; Pruitt and Pfordresher, 2015).
The current study investigated whether short-term choir participation and musical training could improve speech-in-noise perception in older adults, compared to an age- and audiometrically matched control group who were not taking part in musical training. Outcomes of interest included speech-in-noise perception (SIN) and pitch discrimination (FDL), strength and consistency of the neural response to sound (as indexed by features of the frequency following response [FFR] to a repeated speech stimulus), and exploratory cognitive measures of working memory (LSpan) and inhibitory control of attention (Flanker task). We hypothesized that older adults who took part in 10 weeks of group choral practice (2 hours weekly) and individual online musical training (up to 1 hour weekly) would demonstrate improved speech-in-noise perceptual abilities following training, which may be driven in part by enhancements in pitch processing and perception, as indexed by enhanced neural responses to sound (features of the FFR) and improved pitch discrimination thresholds. Exploratory cognitive measures of working memory and attention were assessed in relation to training outcomes, as potential dependent variables. We hypothesized that choir participants would experience greater post-training gains than an age- and audiometrically matched do-nothing control group.
Materials and Methods
Participants
The process of recruitment and participation is shown in Figure 1. Participants were recruited from the first class in a 10-week group singing course run through the 50+ Program at Ryerson University; interested participants came into the lab to undergo eligibility testing that week. Fifty three participants were screened (8 didn’t meet eligibility criteria), 45 participants enrolled (9 withdrew from the study), and 36 participants completed choral training and all test sessions. Two participants were rejected as audiometric outliers, so the final analysis included 34 choir singers.
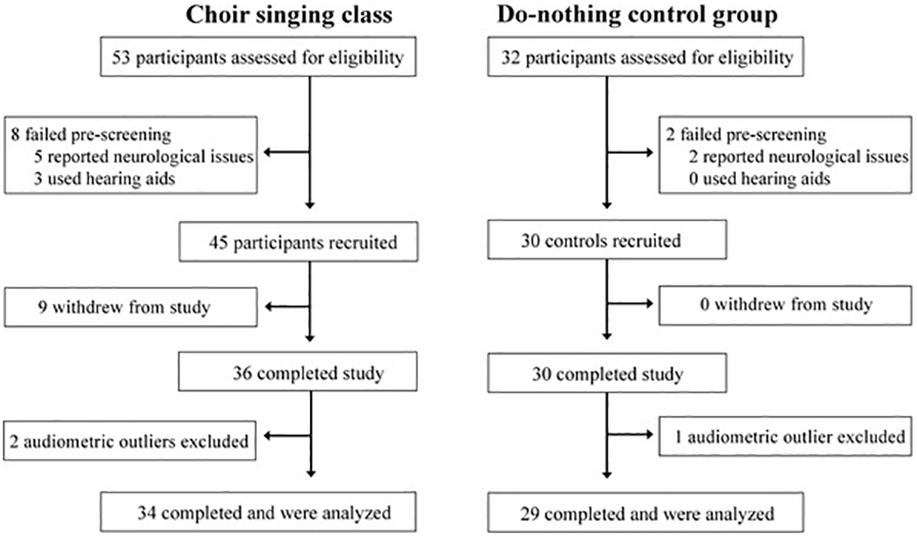
Figure 1. Flow chart showing recruitment and participation of study participants.
Thirty-four choir participants (31 female), aged 54–79 (mean age = 67.6, standard deviation [SD] = 6.1 years) underwent pre-testing data collection during the first week of the choir and post-testing data collection following the final choir class. Peripheral hearing loss was measured by an in-lab audiometric assessment at standard test frequencies between 0.25 and 8 kHz; average peripheral hearing loss ranged from 9.7 to 45.3 dB HL (mean = 23.1, SD = 9.9 dB HL). Participants were pre-screened to ensure that they did not have any neurological conditions and did not use assistive technology (e.g., hearing aids; see Figure 1). Twenty-nine age- and audiometrically matched do-nothing control participants (26 female) aged 60–76 (mean age = 67.7, SD = 4.9 years) were recruited through the Ryerson University Hearing Database. Control participants’ average peripheral hearing loss ranged from 10.6 to 47.5 dB HL (mean = 24.1, SD = 10.3 dB HL); average pure-tone thresholds for both groups are shown in Figure 2. Groups were matched for the duration of time between test sessions, and there were no group differences in previous musical experience, as indexed by years of formal musical training. Informed consent was obtained from each volunteer prior to their participation in the study, in accordance with the Ryerson Research Ethics Board guidelines (REB 2013-128).
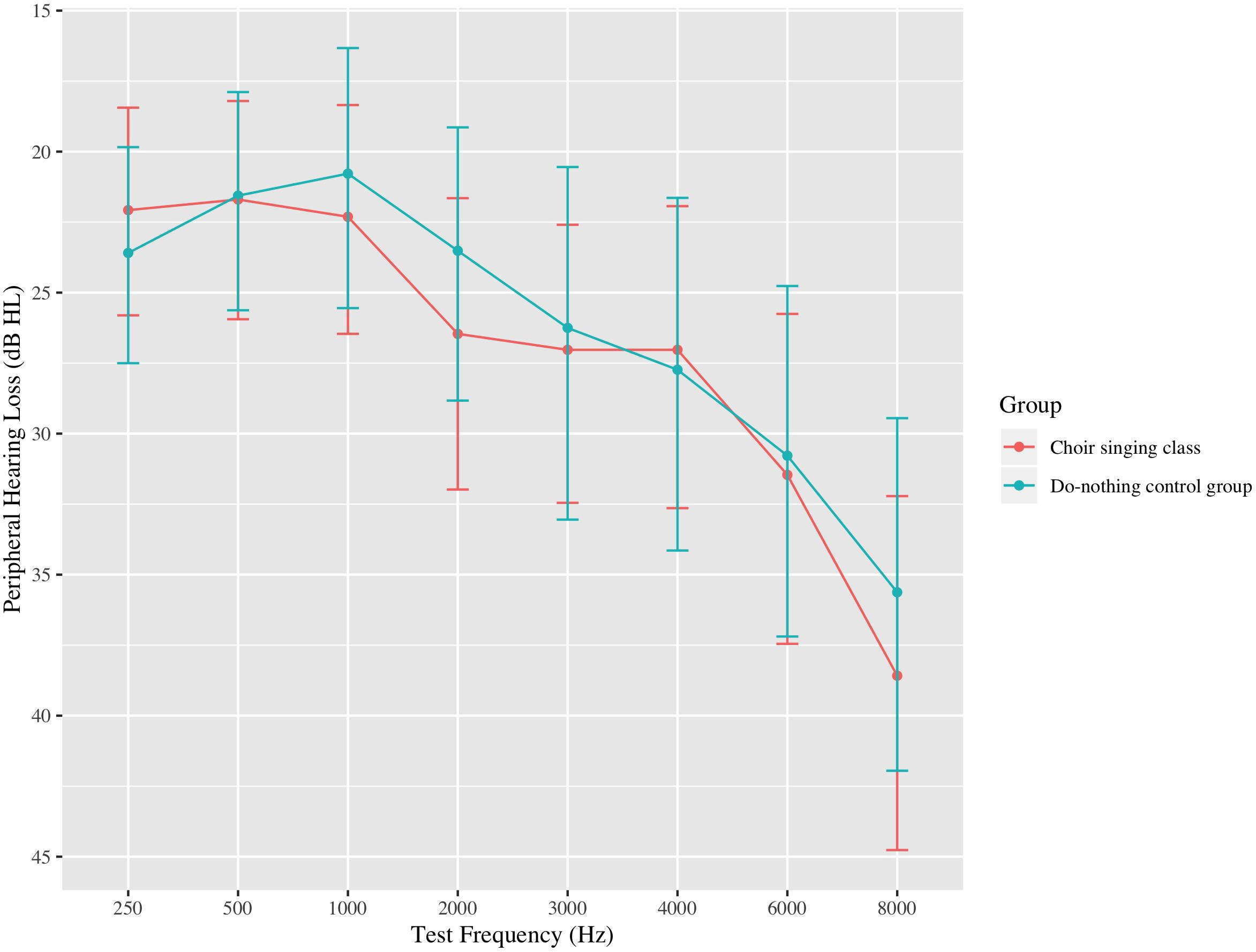
Figure 2. Average bilateral pure-tone thresholds at standard test frequencies up to 8 kHz for participants in the choir singing class and the do-nothing control group. Error bars represent 95% confidence intervals around the means.
Study Design
Each choir participant (n = 34) visited the lab for a pre-training assessment that took approximately three hours, during which time they completed several questionnaires and auditory and cognitive assessments, and underwent an EEG during presentation of repeated auditory stimuli.
Choir-singing participants took part in weekly 2-hour group choral sessions over the course of 10 weeks, during which time they received pitch training and vocal direction in an open and encouraging environment. In addition to the weekly group choir sessions, participants were assigned weekly individual online musical and vocal training exercises (up to 1 hour weekly). This training consisted of pitch discrimination and vocal production exercises designed to target and improve the participants’ abilities to perceive and produce small changes in pitch (Theta Music Trainer)1.
After 10 weeks of choir participation and online musical training, each choir participant returned to the lab for a post-training assessment that lasted approximately 2.5 hours. During this session, participants completed different versions of the original assessments, and underwent a post-training EEG of during auditory stimulus presentation. To account for possible differences in version difficulty within the matched behavioral tasks, participants were assigned one of four possible counterbalanced configurations of assessments.
The do-nothing control group (n = 29) underwent the same battery of pre- and post-testing, with 8–10 weeks between data collection sessions, but did not receive any active training during this time. The inclusion of this control group in the analysis intended to account for any practice effects within the repeated measures, enabling a controlled examination of the unique effects of the musical intervention on experimental outcomes.
Experimental Procedure
Apart from the questionnaires, all assessments were completed in an Industrial Acoustics Company (IAC) double-walled sound-attenuating booth. Computerized assessments were presented using a Mac mini (Apple, 2010), with visual components of the experiment presented on a 24′′ Acer LCD display (Acer X243w, 1920 × 1200) placed at eye level approximately 0.5 m in front of the participant. Audiometric testing and FFR auditory stimuli were administered through binaural foam insert headphones (Electro-Medical Instruments, 3A) connected to a GSI 61 Clinical Audiometer (VIASYS Healthcare). All other auditory assessments were administered binaurally through Koss SB40 headphones at approximately 70 dB SPL.
Before the experiment began, participants were familiarized with task requirements and response methods for each assessment. Participants were monitored throughout the data collection session.
Questionnaires
After signing the consent form and going over experimental expectations and volunteer rights, participants were given background and music history questionnaires. These elicited demographics and medical history, and years of formal musical training.
Auditory Measures
Speech-in-noise perception: signal-to-noise ratio (SNR)
Ability to track speech in a noisy environment was assessed using the QuickSIN test (Speech-In-Noise; Etymotic Research; Killion et al., 2004). Participants were presented with four sets of six pre-recorded sentences, with five key words per sentence embedded in four-talker babble noise. In this assessment, the sentences were presented binaurally with a decreasing SNR: the first sentence was presented with an SNR of 25 dB (i.e., the target sentence was twenty-five dB above the background noise; very easy), each subsequent sentence was presented with a −5 dB SNR reduction, to an SNR of 0 dB for the final sentence. Participants were asked to repeat back the target sentences as closely to what they heard as possible, and were awarded one point for each correctly repeated target word, for a possible total of 30 points per set. The sentences in the QuickSIN do not contain many semantic or contextual cues, despite being syntactically correct (Wilson et al., 2007). Out of the four sets of sentences presented, the first two lists were treated as practice sets, to familiarize participants with the task requirements, and the second two lists were scored as experimental data. Mean SNR loss (dB) for each list was calculated by subtracting the total number of correct words from 25.5; Mean SNR loss (dB) represents the increased SNR required to correctly repeat 50% of key words on the QuickSIN test (Etymotic), above 2 dB SNR (the level required for normal hearing individuals to achieve 50% test accuracy; Killion, 1997; Killion et al., 2004). Final scores were calculated by averaging the scores of the two experimental lists; since this is a threshold assessment, a more negative SNR score indicates better performance. Participants’ responses were scored online by a researcher, and were also recorded using Audacity software in case response ambiguity necessitated further review. The pre- and post-testing lists consisted of different sentence sets in order to avoid practice effects, and participants’ exposure to the sets were counterbalanced across experimental conditions.
Pitch discrimination: frequency difference limens (FDL)
Participants’ ability to distinguish different frequencies was measured using a computerized assessment of FDL. In this task, participants were presented with 3 pure tones, each lasting 200 ms, with amplitude envelopes of 20 ms rise and delay times. A three-alternative forced choice paradigm was used, in which each presented set contained two pure tones at the standard 500 Hz frequency, and one stimulus at a randomly selected higher frequency (Schneider, 1997; Parbery-Clark et al., 2009; Russo et al., 2012). The participant was instructed to identify which tone was higher than the other two by pressing the corresponding number on a computer keyboard (i.e., 1 = first tone is higher; 2 = second tone is higher; 3 = third tone is higher). An adaptive staircase procedure was used to determine the pitch discrimination threshold, whereby the difference between standard and comparison frequencies was halved after three correct responses, or doubled after one incorrect response. After five reversals, the step was changed, so that the frequency difference was divided by 1.414 after 3 correct responses or multiplied by 1.414 after one incorrect response. FDL was determined from the mean of the last 10 reversals.
EEG Measure: The Frequency Following Response (FFR)
Stimulus
Auditory presentation of a repeated/dα/syllable (F0 = 100 Hz) was used to elicit the FFR, following methodological conventions described by Skoe and Kraus (2010). This stimulus was selected because it is a speech sound that has been extensively used in this area of research, and robustly elicits clear FFRs (Russo et al., 2005; Parbery-Clark et al., 2009, 2012; Skoe and Kraus, 2010). Each participant heard 6000 repetitions of this 170 ms sound, presented at alternating polarities. Stimuli were presented binaurally through insert headphones; stimulus volume was set to 60 dB SPL for normal hearers. For individuals with hearing loss above 25 dB, presentation volume was set to 60 dB + (dB HL – 25 dB), controlling stimulus levels for sensory loss across all participants.
EEG administration and data collection
EEG data were collected using a vertical one-channel montage configuration, using three electrodes, in which active and reference electrodes were placed on the mastoids, and a ground electrode was placed on the forehead. A researcher applied 1′′ square cloth solid gel electrodes (EL504, BIOPAC Systems, Inc.) to the mastoids and forehead; electrodes were connected to a BIOPAC MP150 data acquisition system and ERS100C Evoked Response Amplifier (BIOPAC Systems, Inc.). Data were recorded at a sampling rate of 20 kHz, with an online low-pass filter of 10 kHz and a high-pass filter of 1 Hz; the signal was recorded using Acknowledge software (AcqKnowledge, version 4.1). Stimuli were presented for 25 minutes in total, during which time participants shown a silent film2, to promote relaxation and stillness during the EEG.
EEG data processing
EEG data were processed in MATLAB, using the PHZLAB toolbox (Nespoli, 2016). A 75 Hz high-pass filter was applied, and data were segmented according to individual stimulus responses (i.e., 6000 segments), with epoch windows extending 40 ms pre- and post-stimulus, and the steady-state component extending from 60 to 170 ms post-stimulus onset (Skoe and Kraus, 2010). The 40 ms signal preceding stimulus onset was used as a baseline of ambient EEG activity, against which to compare the response activation. Peak amplitudes in the response waveform were compared to the baseline; response peaks with absolute amplitudes that did not exceed the baseline were not considered ‘reliable’ (Skoe and Kraus, 2010). Myogenic artifacts, which are many times larger than the neural response, were accounted for by rejecting all trials with amplitudes that exceeded a threshold of 50 μV. Responses that remained after artifact rejection were averaged, using the addition method of inverse polarity processing in order to preserve the representation of the fundamental frequency while minimizing stimulus artifact in the signal. Peak amplitude of the fundamental frequency (a measure of the strength of the pitch representation in the signal, or FFR strength) was calculated by applying a FFT to the averaged signal, and inter-trial phase coherence (ITPC; a measure of response consistency or FFR consistency) was calculated by finding the latency variations across each participant’s un-averaged signal.
Exploratory Cognitive Measures
Cognitive assessments were administered electronically on the stimulus computer (see section Experimental Procedure). Assessment scripts, coded in HTML-5, were retrieved from the Millisecond online database3 (2016), adapted to have fewer blocks and runtime, and administered using Inquisit software (version 5.0.6). Working memory was assessed using a computerized version of the listening span task (LSpan), an auditory adaptation of the reading span task developed by Daneman and Carpenter (1980). Inhibitory control of attention was assessed using a computerized version of an adapted Flanker task (Ridderinkhof et al., 1997).
Statistical Analyses
Linear mixed effects analyses in a regression format were conducted on choir and control groups to examine the effects of choir participation on speech-in-noise perception (mean SNR loss; dB), pitch discrimination ability (FDL; Hz), and aspects of the FFR which represent the strength and consistency with which the speech fundamental frequency was represented. Exploratory cognitive measures of auditory working memory (LSpan) and inhibitory control of attention (Flanker effect) were also examined in the same format. In all models, measures were regressed on Session, Group, and the interaction between them (e.g., SNR ∼ Session × Group); contrasts were assigned such that the interaction effect represented the training effect of the choir group compared to the control group. Intercepts significantly varied across participants for all auditory measures; because the Session × Group interaction was the main effect of interest for each outcome measure, individual variability in baseline scores across all dependent variables were included as random effects in the multilevel models. Session × Group interactions are reported first in each section, and significant Session × Group interactions were plotted and broken down in separate multilevel models of the choir and control groups. In these separate regressions conducted on each group, the models specified were the same as the main model for each variable, but excluded the main effect and interaction term involving Group. This was done in order to elucidate differential effects of choir participation vs. do-nothing control participation, on all outcomes of interest. Statistical analyses were conducted in R; the nlme and lmer packages were used to conduct linear mixed effects modeling in a regression format (Bates et al., 2015; Pinheiro et al., 2019).
Results
Linear mixed effects models for key auditory measures are summarized in Table 1; pre- and post-testing group means, post hoc pairwise t-tests, and effect size calculations are reported in Table 2. Due to a computer error, FDL scores for 25 participants were spurious and removed from analyses.
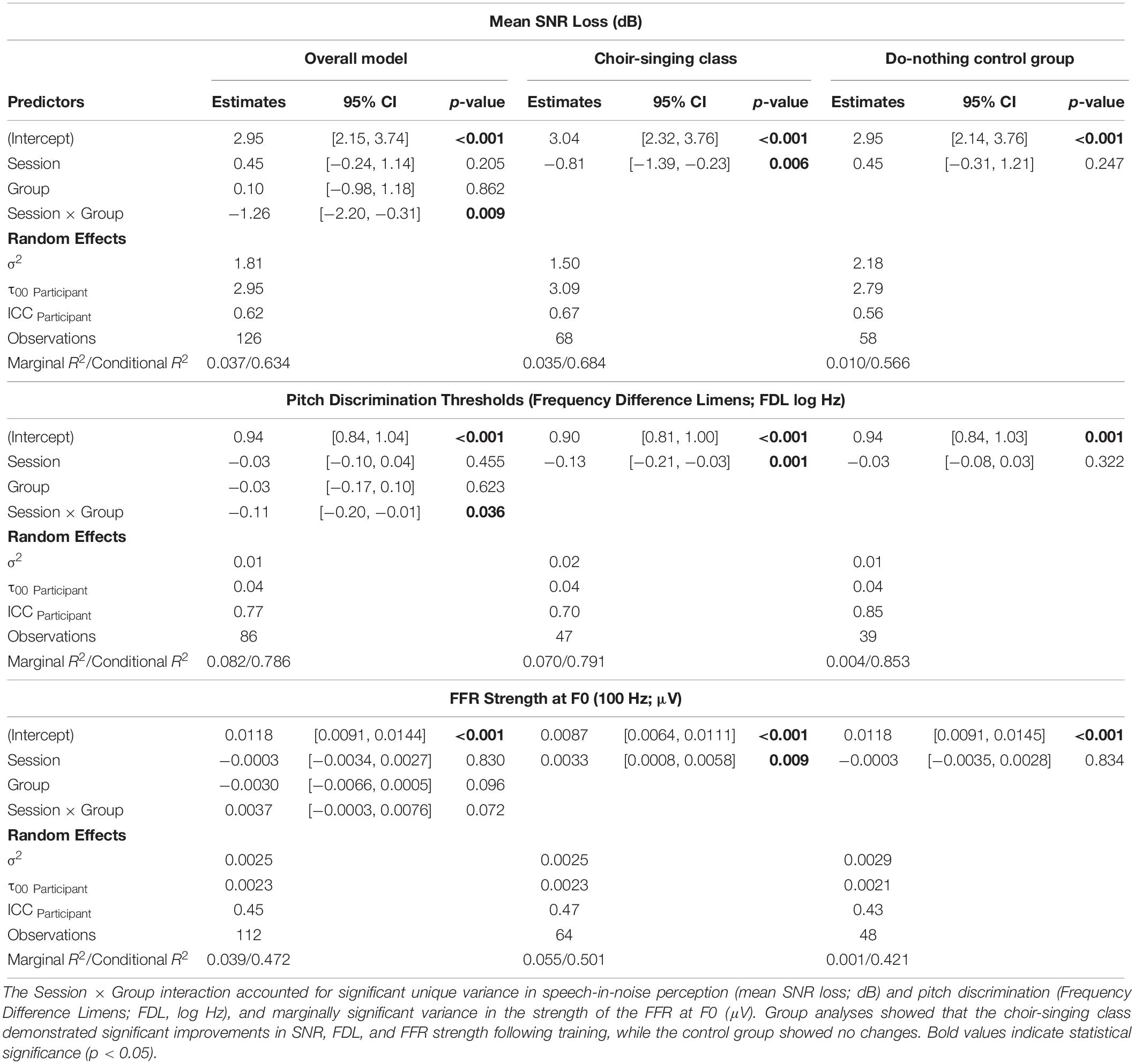
Table 1. Summary of linear mixed effects models for choir-singing and do-nothing control groups across key auditory measures.
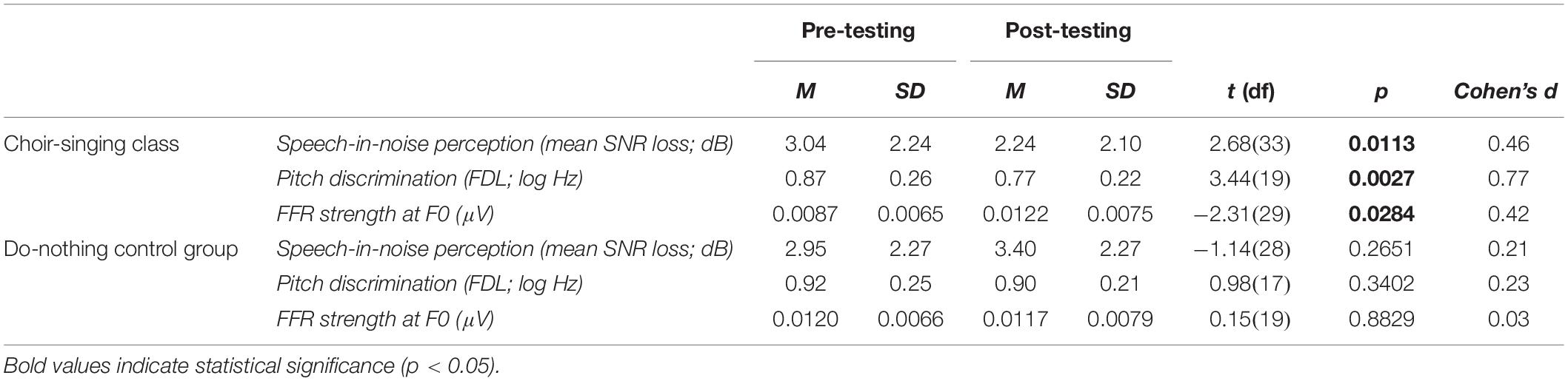
Table 2. Mean scores compared with post hoc pairwise t-tests and related effect sizes (Cohen’s d) for the choir-singing class (n = 34) and do-nothing control group (n = 29) at pre- and post-testing sessions, across auditory measures of interest.
Speech-in-Noise Perception
Pre-training and post-training SNR loss (dB) for choir singing and do-nothing control groups is plotted in Figure 3. The Session × Group interaction accounted for significant variance in dB SNR loss [b = −1.26, t(61) = −2.57, p = 0.009]. Regressions conducted on each group showed that choir participants demonstrated improvements of 0.81 dB SNR following training [b = −0.81, t(33) = −2.68, p = 0.006], while control participants showed no change [b = 0.45, t(28) = 1.14, p = 0.247; see Table 1].
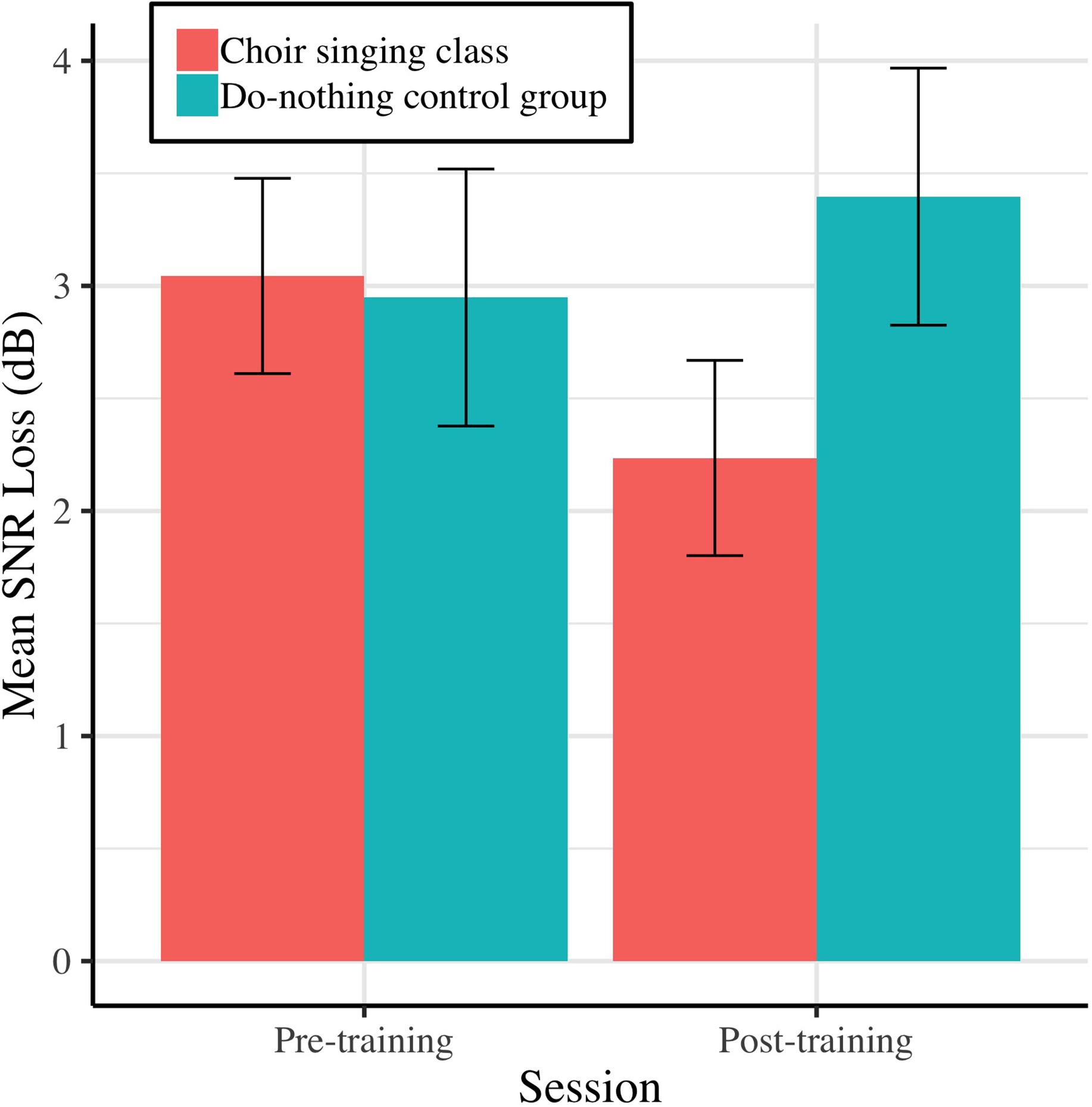
Figure 3. Mean SNR loss (dB) before and after 10 weeks of choir singing or do-nothing control participation, plotted with 95% CIs for repeated measures.
Pitch Discrimination and Neural Representation of Frequency
Figure 4 shows mean pitch discrimination thresholds (FDL, log Hz) before and after 10 weeks of choir singing and do-nothing control participation. The Session × Group interaction accounted for significant variance in frequency discrimination thresholds [log Hz; b = −0.11, t(36) = −2.10, p = 0.036]; regressions conducted on each group showed that choir participants demonstrated improved pitch discrimination thresholds following training [b = −0.13, t(19) = −3.21, p = 0.0013], while control participants showed no changes [b = −0.03, t(17) = −0.99, p = 0.322; see Table 1].
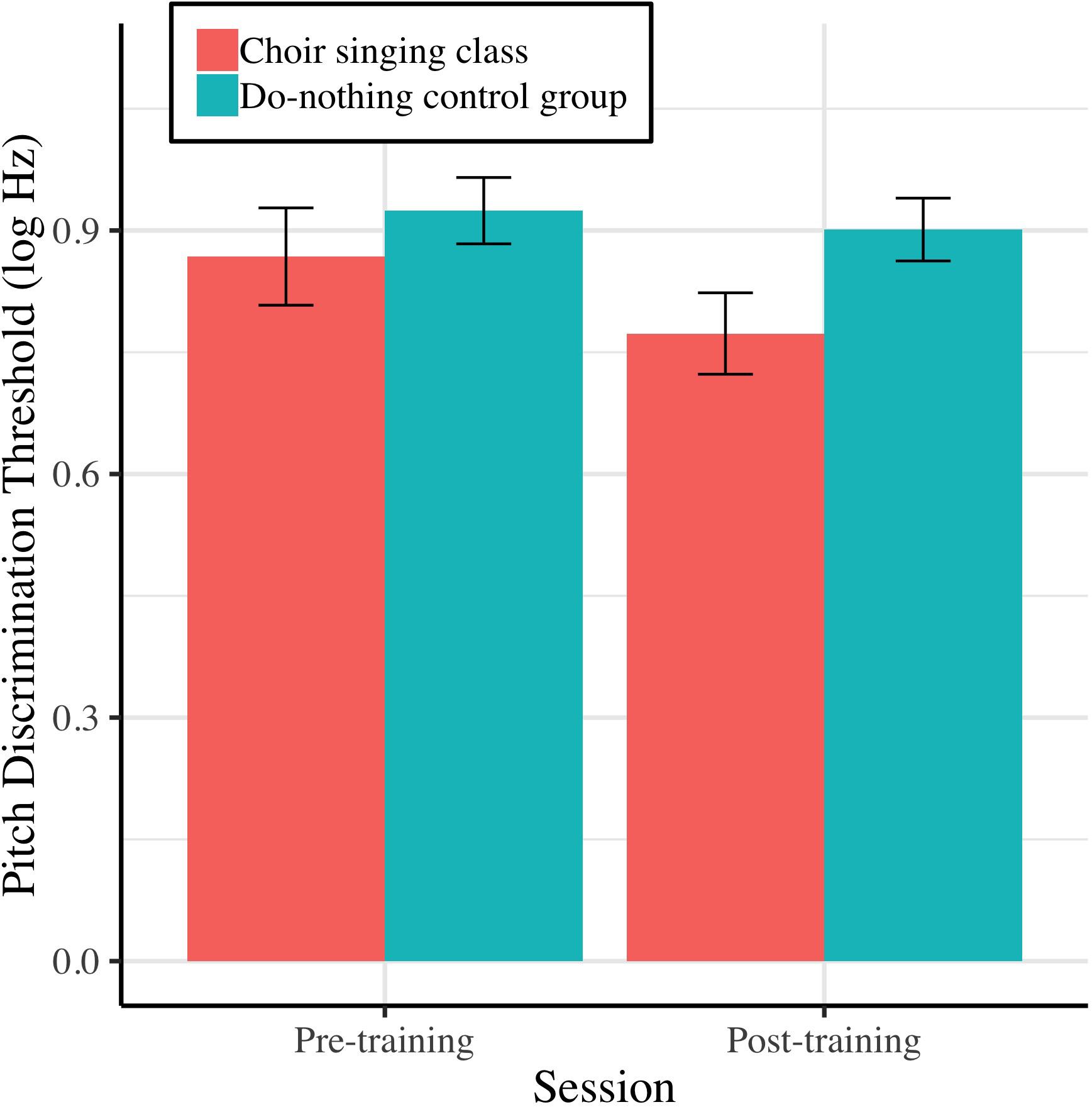
Figure 4. Older adults’ average pitch discrimination thresholds (frequency difference limens; FDL, log Hz) before and after 10 weeks of choir singing or do-nothing control participation, plotted with 95% CIs for repeated measures.
Figure 5 shows the strength of the neural representation of the fundamental frequency (F0) of the steady-state component of a complex sound (/da/; F0 = 100 Hz), before and after choir-singing or do-nothing control participation. The Session × Group interaction accounted for marginally significant variance in the FFR strength at F0 [μV; b = 0.0037, t(48) = 1.77, p = 0.0721]; regressions conducted on each group showed that following training, choir participants demonstrated improvements in the neural representation of pitch [b = 0.0033, t(29) = 2.60, p = 0.009], while control participants did not demonstrate significant changes [b = −0.00034, t(19) = −0.21, p = 0.8346; see Table 1]. The Session × Group interaction did not account for significant variance in the inter-trial phase coherence of the FFR [μV; b = 0.0025, t(50) = 0.38, p = 0.7066].
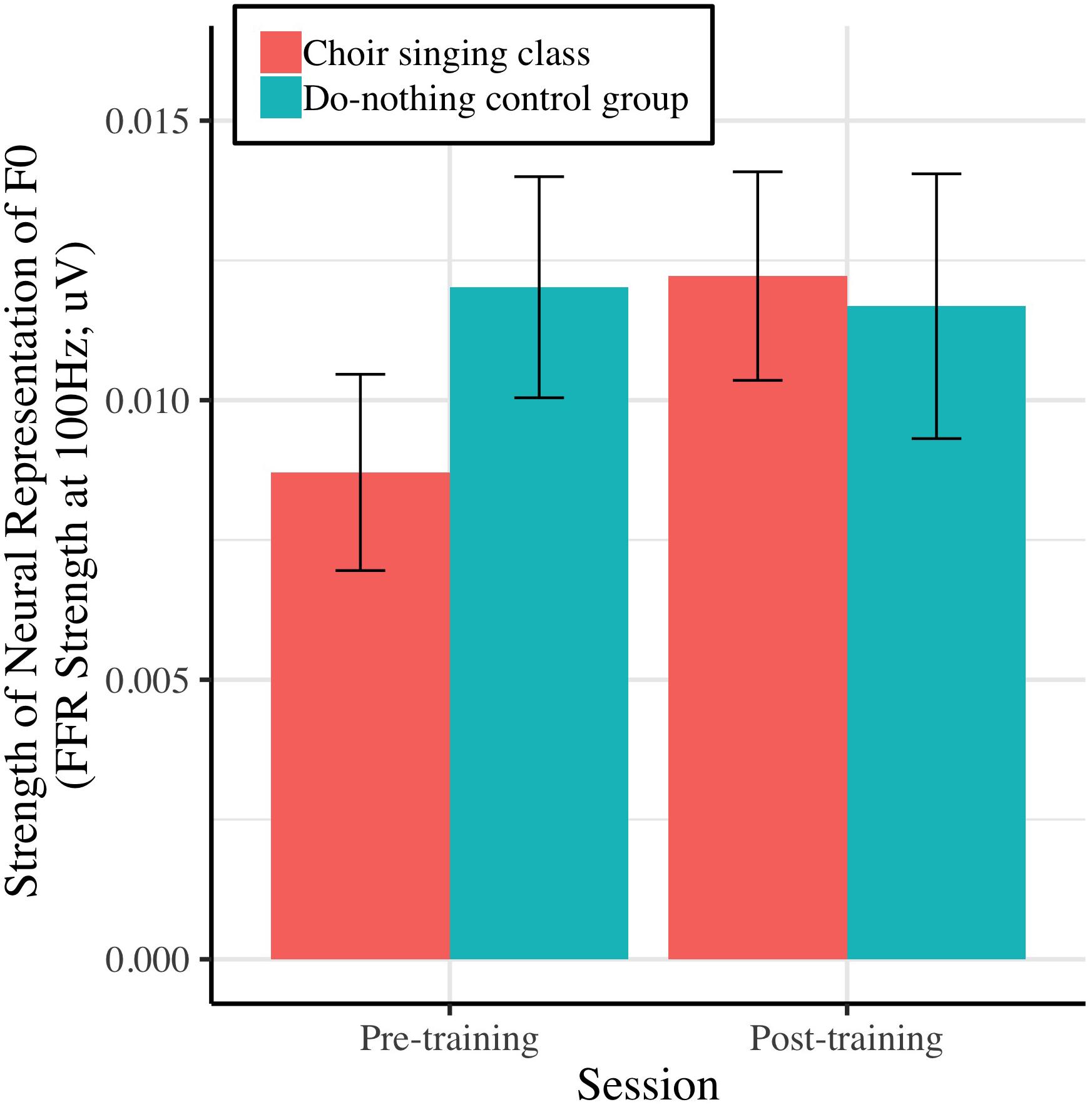
Figure 5. Strength of neural representation (μV) of the fundamental frequency of a speech stimulus (/da/; F0 = 100 Hz), as indexed by the spectral power of the fundamental in participants’ EEG signals (FFR strength at F0).
Exploratory Cognitive Measures
There were no Session × Group interaction effects on either listening span (auditory working memory) or the Flanker effect (inhibitory control of attention).
Possible Contributors to Choir-Driven Improvements in Speech-in-Noise Perception
Figure 6 shows the relationship between improvements in pitch discrimination ability, FFR strength at F0, and speech-in-noise perceptual gains. SNR scores of choir participants were analyzed in a multilevel model including Session (effect of training), FDL, and FFR strength as potential predictors of variance, in order to elucidate potential mechanisms for choir-related improvements in speech-in-noise perception. Predictors were added into the model hierarchically based on hypothesized contributions to speech-in-noise perception derived from previous research, and only predictors with significant Session × Group interactions were included in the model (i.e., FDL and FFR strength at F0). The final choir model is reported in Table 3; with Session included in the model, the interaction between FDL and FFR strength accounted significant unique variance in SNR scores [b = −239.74, t(21) = −3.18, p = 0.0045]; inclusion of FDL accounted for training-related variance in SNR loss previously accounted for by Session, suggesting a potential mediating effect of pitch discrimination on training-related improvements in speech-in-noise perception.
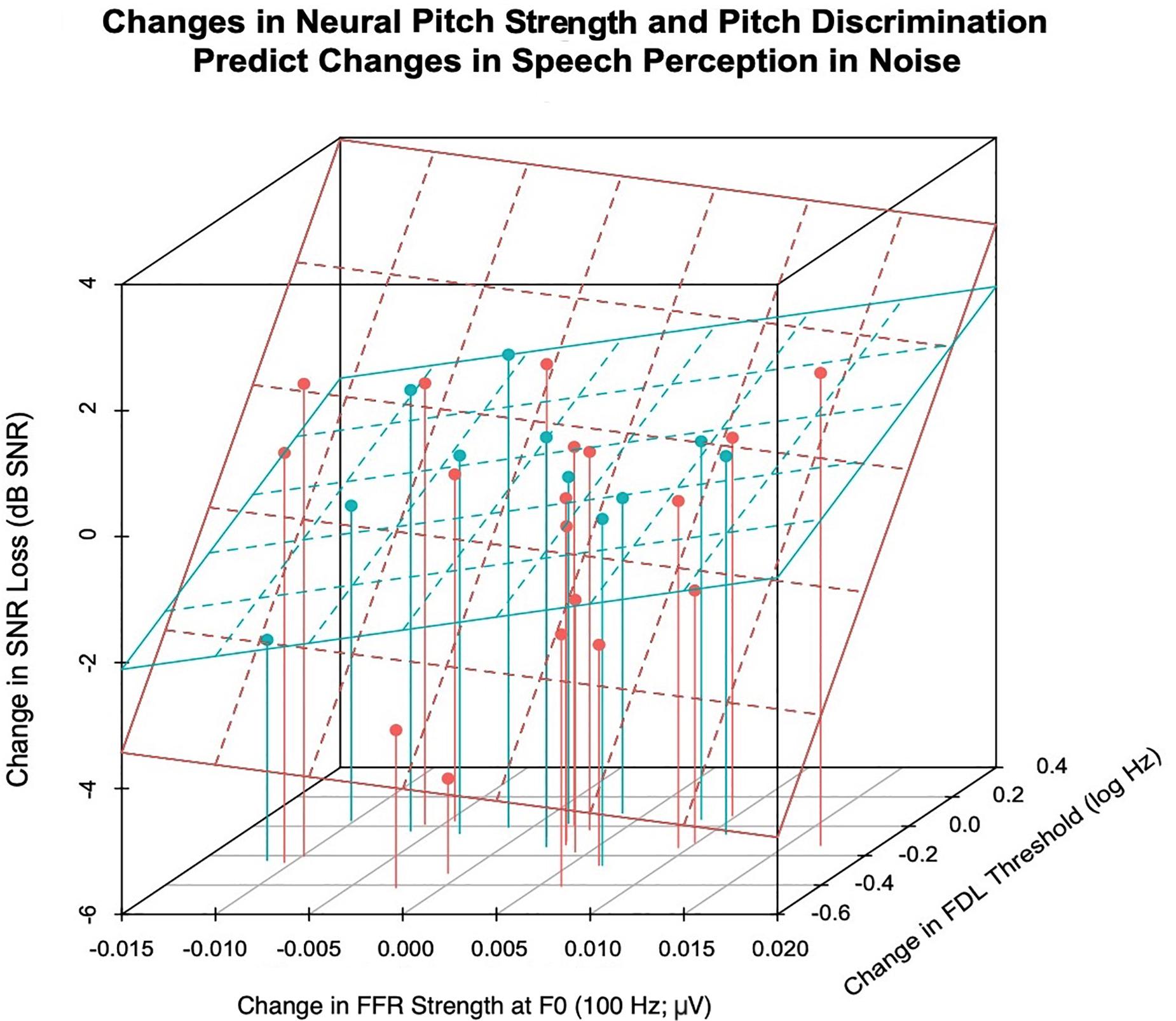
Figure 6. The relationship between improvements in speech-in-noise perception (Δ mean SNR loss; dB), pitch discrimination thresholds (Δ FDL; log Hz), and the strength of the neural representation of frequency (Δ FFR strength at 100 Hz; μV). Choir participants (red) who experienced greater improvements in the neural representation of F0 (more positive FFR strength) and pitch discrimination thresholds (more negative FDL) demonstrated greater improvements in speech-in-noise perception, as indexed by reduced SNR Loss (dB) following training. This relationship was non-significant for the control participants (blue).
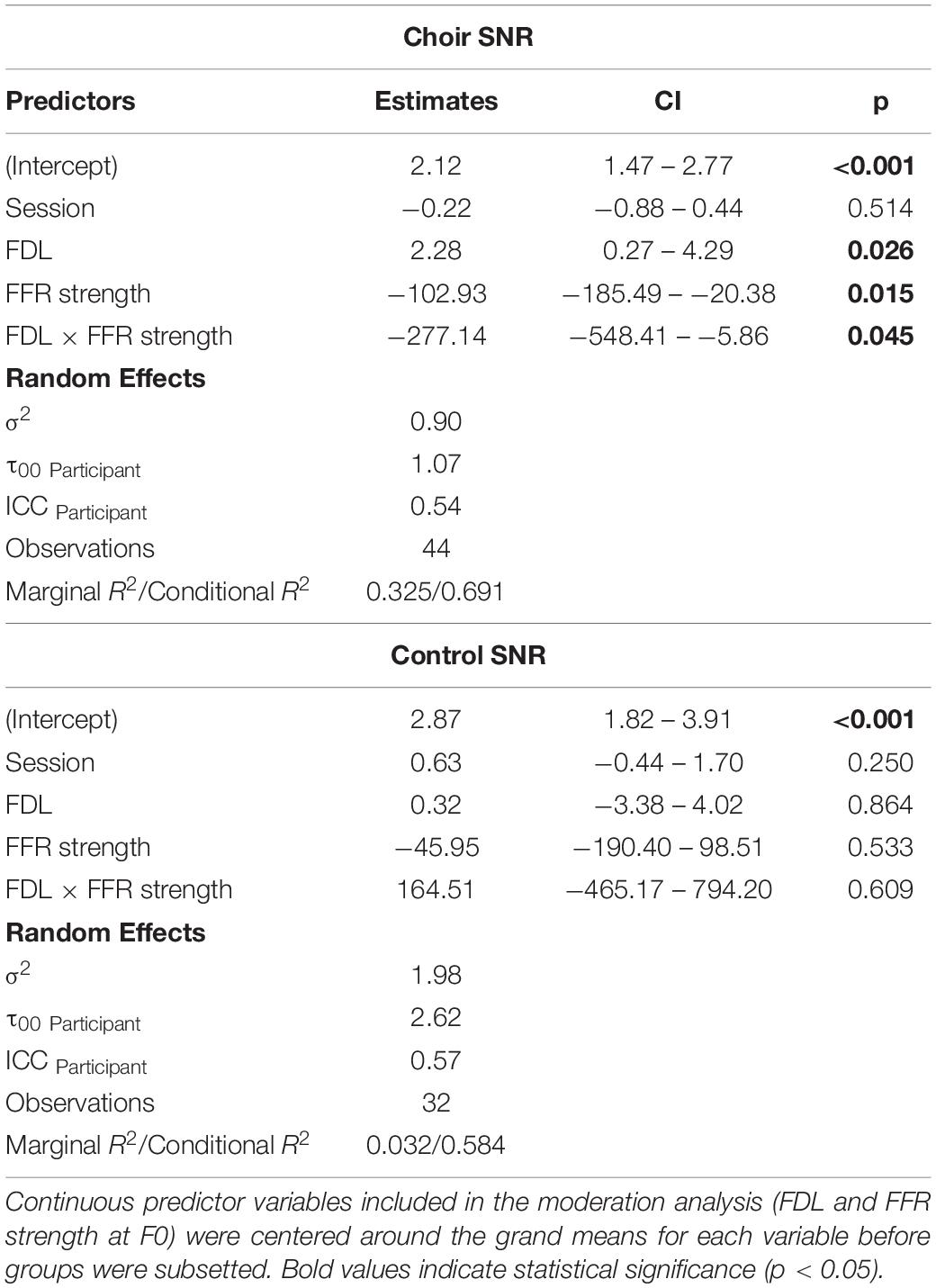
Table 3. Hierarchical regression of possible contributors to speech-in-noise perceptual gains following choir (vs. control group) participation; marginal R2 = 0.325, conditional R2 = 0.691.
Pitch Discrimination as a Potential Mechanism for Musicianship Improvements in Speech-in-Noise Perception: A Mediation Analysis
Figure 7 shows the distribution of the indirect effect of choir training on SNR, which shows that choir-related improvements in speech-in-noise perception were significantly mediated by improvements in pitch discrimination. The regression of mean SNR loss (dB) on Session, ignoring the mediator, was significant (see Table 1); when mean SNR loss (dB) was regressed on the mediator while controlling for Session, FDL significantly predicted SNR [b = 3.57, t(18) = 3.22, p = 0.0047], but training-specific effect was no longer a significant predictor of SNR [b = −0.23, t(18) = −0.605, p = 0.553]. Aroian’s test revealed a significant mediating effect of FDL on choir-related improvements in SNR (Aroian’s test statistic = −2.20, p = 0.0280), and a Monte Carlo resampling approach (n = 20000) confirmed that FDL fully mediated the relationship between choir participation and SNR improvements, 95% CI [−0.775, −0.0894]; Figure 7.
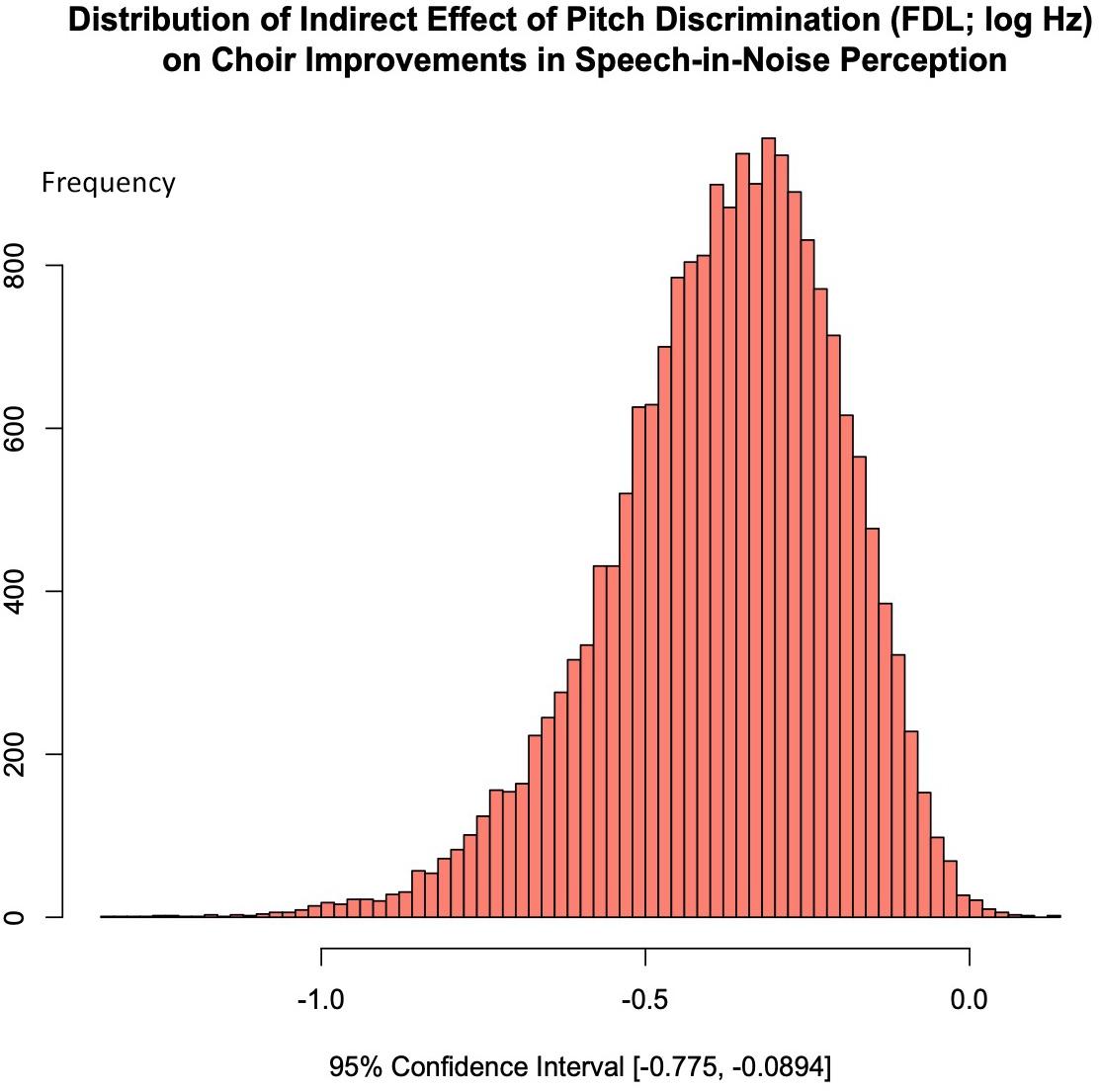
Figure 7. A mediation analyses was conducted using the Monte Carlo technique (20000 samples); choir related gains in SNR were fully mediated by improvements in pitch discrimination ability; 95% CI [–0.775, –0.0894].
The significant interaction effect of FDL × FFR strength on SNR (Table 3) suggested a potential moderating effect of FFR on the relationship between pitch discrimination and SNR, so a moderated mediation analysis was conducted to assess the statistical significance of this effect. This analysis revealed a marginally significant moderation of the mediation by changes in FFR strength [b = −277.14, t(14) = −1.885139, p = 0.0803]; the model of this relationship is shown in Figure 8.
Figure 8. Model of moderated mediation of choir-related improvements in speech-in-noise perception by pitch discrimination and strength of neural representation of pitch.
Exploratory analyses considered whether the relationship between choir-related improvements in pitch discrimination and speech-in-noise perception could be predicted by the strength of the representation of F0 in the FFR. Simple slopes analyses on low, average, and high FFR strength at F0 (centered variable ± SD) showed that the relationship between pitch discrimination and SNR was strongest in high FFR conditions [i.e., when F0 is strongly represented in the FFR; b = 4.28, t(14) = 3.29, p = 0.0054], weaker in average FFR conditions [b = 2.28, t(14) = 1.08, p = 0.0546], and non-significant in low FFR conditions [b = 0.28, t(14) = 0.16, p = 0.8714], suggesting that when controlling for session, the strength of the FFR at F0 is predictive of the strength of the relationship between pitch discrimination and speech-in-noise perception. These analyses suggest that neural and perceptual pitch processes play a role in speech-in-noise perceptual ability in older adults, and could mechanistically contribute to a potential musicianship advantage in this domain.
Effects of Peripheral Hearing Loss on Perceptual and Neural Auditory Outcomes
Figures 9–11 demonstrate the differential effects of peripheral hearing loss (dB HL) on the efficacy of the choir-singing intervention on: speech-in-noise perception (Figure 9); pitch discrimination (Figure 10); and FFR strength at F0 (Figure 11). There were significant main effects of Audiometry on SNR [b = 0.07, t(60) = 2.66, p = 0.0101] and FDL [b = 0.008, t(45) = 2.52, p = 0.0153]; across groups and sessions, worse peripheral impairments were predictive of worse performance on perceptual tasks. However, there were no significant effects of peripheral hearing loss on FFR strength at F0, indicating a potential differentiating effect of audiometry on neural vs. perceptual outcomes.
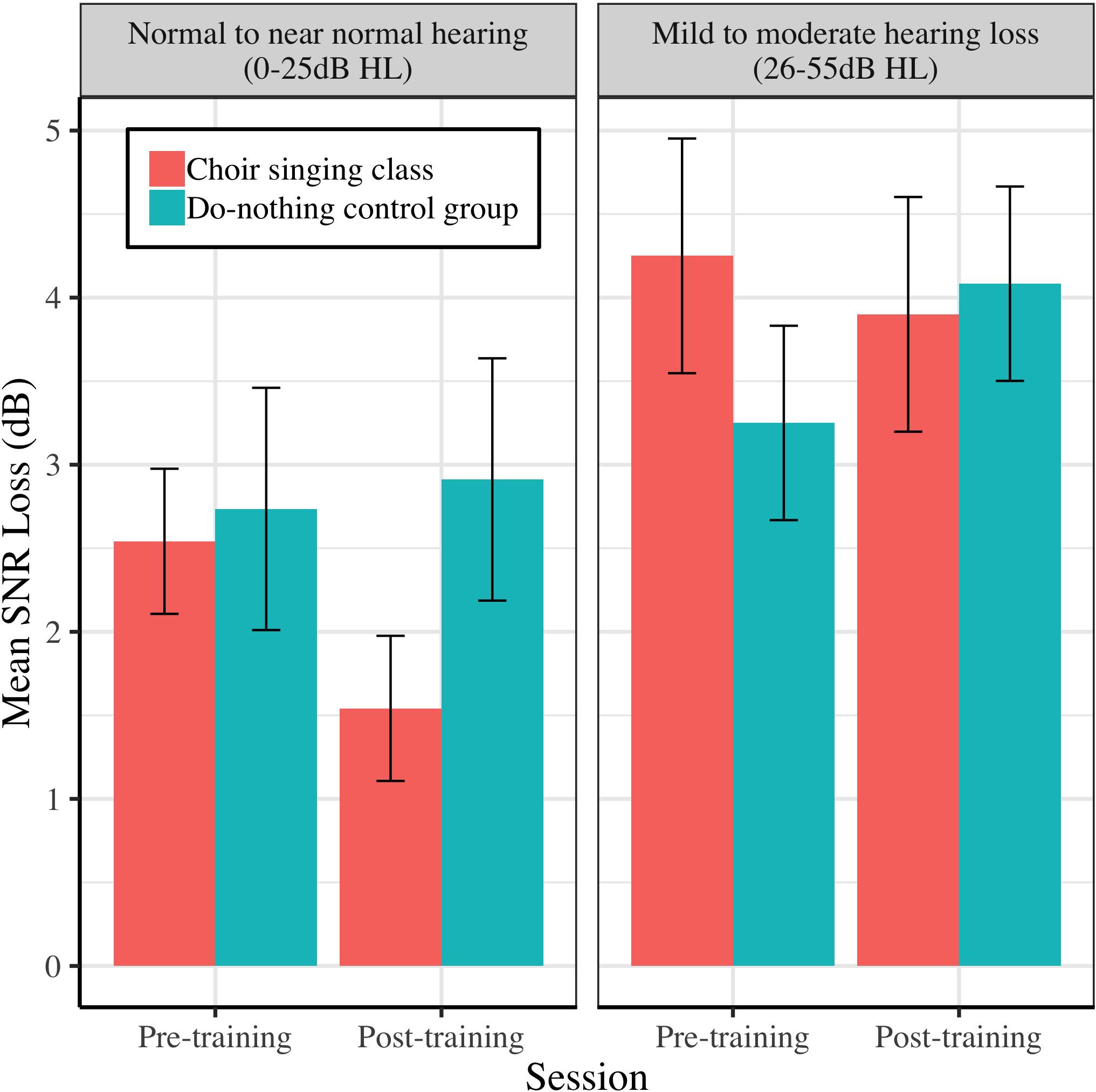
Figure 9. The relationship between peripheral hearing loss and pre-post changes in mean SNR loss (dB), for choir and control groups. Degree of impairment is categorized on clinical audiometric criteria, where normal to near normal hearing = 0–25 dB HL, and mild to moderate = 26–55 dB HL. Error bars are within subjects CIs (95%) plotted around Session × Group means.
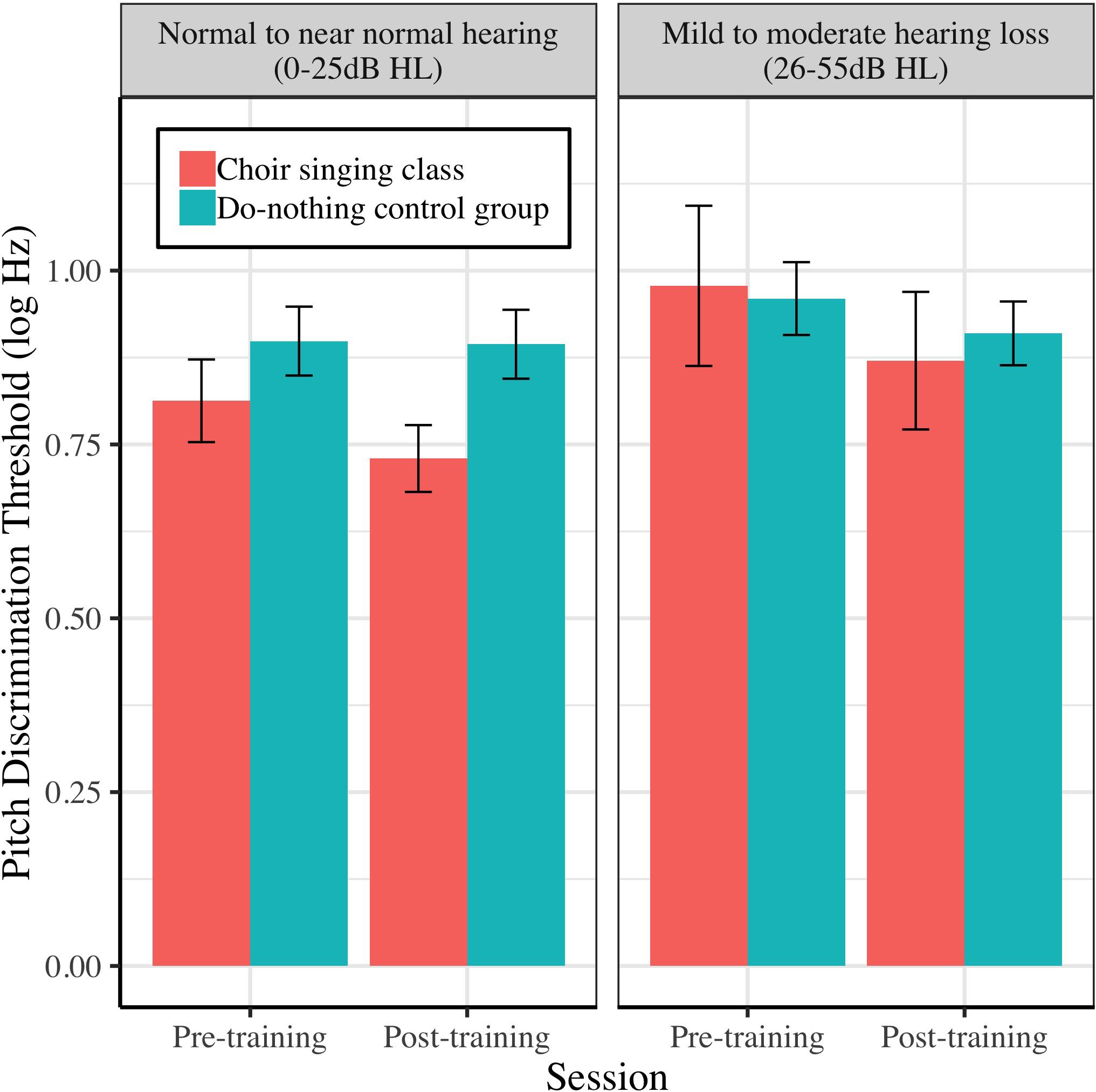
Figure 10. The relationship between peripheral hearing loss and pre-post changes in pitch discrimination thresholds (FDL; log Hz) for choir and control groups. Degree of impairment is categorized on clinical audiometric criteria, where normal to near normal hearing = 0–25 dB HL, and mild to moderate = 26–55 dB HL. Error bars are within subjects CIs (95%) plotted around Session × Group means.
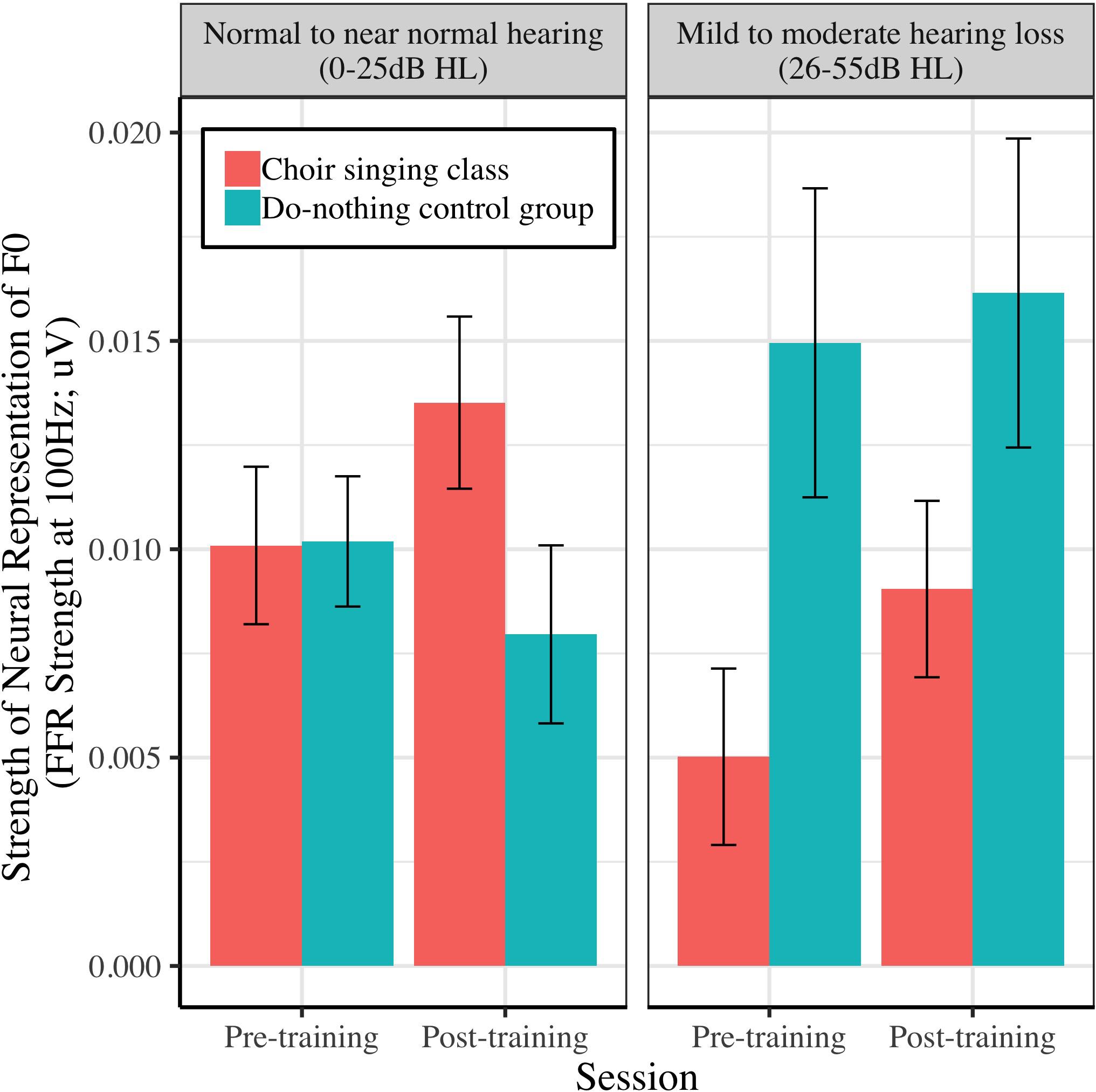
Figure 11. The relationship between peripheral hearing loss and pre-post changes in the strength of neural representation of fundamental frequency (FFR strength at 100 Hz) for choir and control groups. Degree of impairment is categorized on clinical audiometric criteria, where normal to near normal hearing = 0–25 dB HL, and mild to moderate = 26–55 dB HL. Error bars are within subjects CIs (95%) plotted around Session × Group means.
Discussion
This study demonstrated experimentally that short-term choir participation can be used as an intervention to target and improve speech-in-noise perception in older adults, supporting the hypotheses that: (1) the musicianship advantage in speech-in-noise perception can be conferred to older adults through a relatively short training period, using choir singing and vocal training; and (2) enhancements in pitch processing contribute to improvements in this domain. This study lays the groundwork for a highly scalable, cost-effective, and engaging intervention that can be used to mitigate declines in speech-in-noise perception in older adults, and importantly provides insight into potential neural and perceptual mechanisms underlying these changes. In particular, the relationship between auditory processing, pitch discrimination, and speech-in-noise perception suggested by this study elucidates one way in which musical experience – and specifically, singing and vocal training – can transfer to improvements in speech processing, through enhanced representation of pitch.
Compared with do-nothing control participants, choir singers demonstrated 1.26 dB improvements in mean SNR loss following training, a change that corresponds to a functional difference of 10–20% improvement in speech intelligibility (Middelweerd et al., 1990). Other forms of auditory rehabilitation for older adults yield similar improvements (1.5 dB with LACE training), require intensive practice in the target domain (30 min per day, 5 days per week for 4 weeks), which may account for the relatively poor compliance and high rates of attrition (Sweetow and Sabes, 2006; Song et al., 2012; Tye-Murray et al., 2012). In contrast, group singing is reported to be highly engaging and motivating, provides many benefits outside of the focus of training, and promotes ongoing social involvement and activity (Hillman, 2002; Creech et al., 2013). It is important to note that in the current study, while nine participants withdrew from data collection, almost all of the original 53 participants surveyed remained in the choir class (two withdrew due to health issues), and many participants reported joining other choirs and singing groups after the study ended. As a proof of concept, this makes a strong case for the engagement and enjoyment of participants in a group singing class, and the sustainability of this type of intervention, along with its efficacy at improving speech-in-noise perception.
In terms of possible mechanisms accounting for changes in speech-in-noise perception, improvements appeared to be driven at least in part by enhancements in pitch processing. In addition to improved speech-in-noise perceptual abilities, choir singers demonstrated improved pitch discrimination thresholds (as indexed by lower FDL) and stronger neural representations of the speech fundamental frequency (F0) following training as (stronger FFR representation of F0 of the/da/stimulus; 100 Hz). Analyses showed that training-related improvements in speech-in-noise perception were fully mediated by improvements in pitch discrimination, suggesting that the benefits afforded by choir-singing arose at least in part from enhancements in the perception of pitch. A moderated mediation analysis suggested that over the course of choir training, the strength of the neural representation of F0 was predictive of the strength of the relationship between pitch discrimination and speech-in-noise perception. This suggests that neural indices of pitch processing influence the extent to which older adults rely on pitch cues to support speech-in-noise perception. Taken together, these findings suggest that older adults who take part in 10 weeks of choir singing and vocal training demonstrate enhanced neural responses to and perception of subtle frequency cues, which lead to improved perception of speech-in-noise following training.
A number of previous studies have findings that converge with our mediation account of speech-in-noise via pitch perception. For example, musical experience has been correlated with improvements in speech-in-noise perception (Parbery-Clark et al., 2009; Zendel and Alain, 2012; Swaminathan et al., 2015; for review see Coffey et al., 2017a), pitch discrimination ability (Micheyl et al., 2006; Parbery-Clark et al., 2009; Schellenberg and Moreno, 2009; Bidelman et al., 2011a, b; Fuller et al., 2014; Boebinger et al., 2015; Yates et al., 2018), and subcortical encoding of F0 (Parbery-Clark et al., 2009, 2011; Bidelman et al., 2011a, b; Musacchia et al., 2017); relationships have also been demonstrated between pitch perception and subcortical encoding of F0 (Carcagno and Plack, 2011; Coffey et al., 2016; Bianchi et al., 2017), as well as between speech-in-noise perception and pitch processing (e.g., Coffey et al., 2017a). On the other hand, a number of correlational studies have not been able to replicate the musicianship advantage for speech-in-noise perception (e.g., Ruggles et al., 2014; Madsen et al., 2017). Some of this discrepancy may be based on methodological or sampling differences across studies. More generally, limited experimental work in this field has left the nature of these relationships somewhat uncertain (excepting some recent work by Zendel et al., 2019). Zendel et al. (2019) found that older adults (non-musicians) who took part in 6 months of piano training showed improvements in speech-in-noise perception compared with control and video game intervention groups showing no improvements in this domain. Importantly, these individuals were randomly assigned to the interventions in this study, lending credence to the use of musical training to support auditory abilities in older adults.
As a musical intervention, choir singing may be uniquely suited to hone pitch perceptual processes, through activation of existing vocal-motor systems, rapid integration of perceptual and productive processes, and shared neural architecture activated by speech and vocal song. Choir singers have the benefit of both intrinsic auditory and sensorimotor feedback, and can harness existing feedback loops between auditory perception and vocal production – which allow humans to monitor and dynamically alter speech – to rapidly alter and hone vocal output, including production of pitch. These integrative feedback loops and fine-tuned changes may allow choir singers to undergo rapid improvements in both productive and perceptual processes, in a short period of time. Singing is also an intuitive and innate form of music-making, and may be learned (and improved upon) more quickly than learning to play an instrument. This innate quality, along with intrinsic auditory and vocal motor feedback loops, and extrinsic feedback (from the choir director and other singers) create the ideal circumstances to quickly and effectively improve pitch processing and downstream perceptual abilities such as speech-in-noise perception.
While the current study found that improvements in pitch processing fully mediated choir enhancements in speech-in-noise perception, this does not preclude the role of other neural, perceptual, and cognitive contributors to this ability. Previous work suggests that musical training also leads to enhancements in attentional processes involved with speech encoding (e.g., Zendel et al., 2019); auditory working memory has also been implicated in this ability (e.g., Kraus et al., 2012). Further experimental research is necessary to determine the unique contributions of various auditory, cognitive, and neural processes to music-related improvements in speech-in-noise perception in older adults. In addition, the contribution of productive musical training (i.e., singing practice) vs. perceptual training (i.e., learning to listen to differences in pitch) to auditory processing improvements is not clear from the current study. Notably, a recent study found that non-musicians who received targeted pitch perceptual training achieved pitch discrimination thresholds comparable to musicians in 4–8 hours (Micheyl et al., 2006); it is unknown whether these pitch improvements would be sustained over time, or transfer to speech-in-noise perceptual benefits; it is also unclear whether the mechanism by which pitch discrimination is improved – i.e., through targeted psychoacoustic training, vs. through a more naturalistic singing or music listening paradigm – would alter the degree to which pitch perception mediates speech perceptual processes. This further underscores the need for targeted experimental study of musical (and non-musical) perceptual and productive training on auditory abilities, to elucidate the roles and contributions of each. It is also unclear from the current study whether the auditory benefits of choir participation would persist after cessation of training, and whether these benefits would accumulate with additional/long-term choir or musical involvement. These are rich avenues for future research projects, especially in an experimental/longitudinal context.
In addition to the role of pitch, the degree of peripheral hearing loss appeared to influence the amount of gains choir participants experienced as a function of training, whereby participants with lower levels of peripheral hearing loss appeared to experience greater training-related improvements in speech-in-noise perception. This could be suggestive of a possible limit on the efficacy of this intervention at improving perceptual processes in individuals with levels of hearing loss approaching the need for peripheral assistance (i.e., 26–55 dB HL). One potential explanation is that these individuals may not have been able to hear well enough in the classes to pitch-match with other voices, and thus did not receive equivalent experiential benefits from this activity.
Another explanation is that greater peripheral impairments may have led to more substantial central deficits that were recalcitrant to a behavioral intervention in this capacity, at least in the current dose of 10 weeks of choir singing (2 hours/week of group singing, plus 1 hour/week of individual online exercises). However, there were no effects of peripheral hearing loss on the strength of FFR responses, as individuals within the upper range of peripheral hearing loss still showed improvements in the FFR representation of F0. This suggests that while individuals with greater peripheral hearing loss may not receive perceptual benefits from 10 weeks of choir participation, their neural responses may still be enhanced through this experience. An interesting line of inquiry for a future study would be to address whether individuals with greater hearing loss may be able to obtain similar benefits by participating in choir training in conjunction with the use of hearing aids.
Overall, group choral singing appears to be uniquely well suited for this training paradigm, as it encourages singers to produce (and hopefully, perceive) fine-tuned adjustments in pitch structure, which seem to play a major role in improving speech-in-noise perceptual outcomes in this population. The intrinsic relationship with speech, rapid sensory-motor integration, instantaneous feedback afforded by vocal production and auditory perception, and the innate nature of this ability suggest singing as an ideal candidate for improving a speech-related perceptual issue. Group singing is highly motivating, social, and emotionally fulfilling; this is of immense import in developing interventions that will encourage engagement and promote active involvement, especially with older adults. Overall, running a choir is an immensely scalable intervention, requiring minimal cost and equipment (and which could be implemented anywhere), and this study demonstrated that training-related improvements in auditory perception can appear after a very short intervention period (10 weeks of choir singing). The efficacy of this intervention can easily be assessed through experimental manipulations of dose or duration (e.g., using longer periods of choir singing, or assessing persistence of effects post-training), different study populations (e.g., hearing aid users vs. unaided individuals), and with different emphases during the class (e.g., focusing on pitch matching/singing in unison vs. attending to different melodic or harmonic lines). The ease of implementation and scalability of the choir singing paradigm, efficacy at improving auditory abilities in aging adults, and rich opportunity for further investigation suggest choir singing as an ideal framework for examining musical training as an auditory rehabilitation for aging adults.
Conclusion
Group singing is an intuitive, engaging, and motivating form of music making, that has in previous studies been shown to contribute to social, emotional, cognitive, and physical well-being. The current findings suggest that choir singing can be used as an effective intervention to mitigate age-related losses in auditory perceptual abilities, in as short a time as 10 weeks. Importantly, these findings showed that this intervention improved older adults’ abilities to perceive speech in noisy environments, a key concern in promoting healthy aging. This work provides an empirical basis for a highly scalable and effective intervention that could significantly improve quality of life in older adults.
Data Availability Statement
The datasets generated for this study are available on request to the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by Ryerson University Ethics Board (REB). The patients/participants provided their written informed consent to participate in this study.
Author Contributions
ED and FR conceived and designed the study. ED recruited the participants, collected the data, analyzed the results, and wrote up findings as Master’s thesis with FR as supervisor. EW collected the data, revised the literature review, and contributed to the theoretical interpretation of findings. GN developed MATLAB toolbox for processing EEG data. All authors were involved in discussions about the interpretation of the results and the writing of the manuscript.
Funding
This work was supported by a Research Chair sponsored by Sonova Holding AG awarded to FR, as well as a grant from the Natural Sciences and Engineering Research Council of Canada (RGPIN-2017-06969).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Saul Moshe-Steinberg, James McGrath, and Paolo Ammirante for their work toward establishing a subset of the protocols implemented in the current investigation. We are also indebted to Sina Fallah for leading the singing classes and to the 50+ Program of the Chang School of Continuing Education (Ryerson University) for their partnership in all aspects of this research.
Footnotes
- ^ https://trainer.thetamusic.com
- ^ http://www.openculture.com/free-silent-films
- ^ http://www.millisecond.com/download/library/
References
Abel, S. M., Giguere, C., Consoli, A., and Papsin, B. C. (2000). The effect of aging on horizontal plane sound localization. J. Acoust. Soc. Am. 108, 743–752. doi: 10.1121/1.429607
Alain, C., McDonald, K. L., Ostroff, J. M., and Schneider, B. (2001). Age-related changes in detecting a mistuned harmonic. J. Acoust. Soc. Am. 109, 2211–2216. doi: 10.1121/1.1367243
Alain, C., Zendel, B. R., Hutka, S., and Bidelman, G. M. (2014). Turning down the noise: the benefit of musical training on the aging auditory brain. Hear. Res. 308, 162–173. doi: 10.1016/j.heares.2013.06.008
Anderson, S., Parbery-Clark, A., Yi, H.-G., and Kraus, N. (2011). A neural basis of speech-in-noise perception in older adults. Ear Hear. 32, 750–757. doi: 10.1097/AUD.0b013e31822229d3
Arlinger, S. (2003). Negative consequences of uncorrected hearing loss - a review. Int. J. Audiol. 42, S17–S20. doi: 10.3109/14992020309074639
Bailey, B. A. (2005). Effects of group singing and performance for marginalized and middle-class singers. Psychol. Music 33, 269–303. doi: 10.1177/0305735605053734
Bates, D., Mächler, M., Bolker, B. M., and Walker, S. C. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Beck, R. J., Cesario, T. C., Yousefi, A., and Enamoto, H. (2000). Choral singing, performance perception, and immune system changes in salivary immunoglobulin a and cortisol. Music Percep. 18, 87–106. doi: 10.2307/40285902
Besson, M., Chobert, J., and Marie, C. (2011). Transfer of training between music and speech: common processing, attention, and memory. Front. Psychol. 2:94. doi: 10.3389/fpsyg.2011.00094
Besson, M., Schön, D., Moreno, S., Santos, A., and Magne, C. (2007). Influence of musical expertise and musical training on pitch processing in music and language. Restorative Neurol. Neurosci. 25, 399–410. doi: 10.1162/jocn.2010.21585
Betlejewski, S. (2006). Age connected hearing disorders (presbyacusis) as a social problem. Otolaryngol. Polska Pol. Otolaryngol. 60, 883–886.
Bianchi, F., Hjortkjær, J., Santurette, S., Zatorre, R. J., Siebner, H. R., and Dau, T. (2017). Subcortical and cortical correlates of pitch discrimination: evidence for two levels of neuroplasticity in musicians. NeuroImage 163, 398–412. doi: 10.1016/j.neuroimage.2017.07.057
Biasutti, M., and Mangiacotti, A. (2018). Assessing a cognitive music training for older participants: a randomised controlled trial. Int. J. Geriatr. Psychiatr. 33, 271–278. doi: 10.1002/gps.4721
Bidelman, G. M., Gandour, J. T., and Krishnan, A. (2011a). Musicians and tone-language speakers share enhanced brainstem encoding but not perceptual benefits for musical pitch. Brain Cogn. 77, 1–10. doi: 10.1016/j.bandc.2011.07.006
Bidelman, G. M., Krishnan, A., and Gandour, J. T. (2011b). Enhanced brainstem encoding predicts musicians’ perceptual advantages with pitch. Eur. J. Neurosci. 33, 530–538. doi: 10.1111/j.1460-9568.2010.07527.x
Bidelman, G. M., and Krishnan, A. (2010). Effects of reverberation on brainstem representation of speech in musicians and non-musicians. Brain Res. 1355, 112–125. doi: 10.1016/j.brainres.2010.07.100
Boebinger, D., Evans, S., Rosen, S., Lima, C. F., Manly, T., and Scott, S. K. (2015). Musicians and non-musicians are equally adept at perceiving masked speech. J. Acoust. Soc. Am. 137, 378–387. doi: 10.1121/1.4904537
Brainard, M. S., and Doupe, A. J. (2000). Auditory feedback in learning and maintenance of vocal behaviour. Nat. Rev. Neurosci. 1, 31–40. doi: 10.1038/35036205
Bugos, J. A., Perlstein, W. M., McCrae, C. S., Brophy, T. S., and Bedenbaugh, P. H. (2007). Individualized piano instruction enhances executive functioning and working memory in older adults. Aging Men. Health 11, 464–471. doi: 10.1080/13607860601086504
Carcagno, S., and Plack, C. J. (2011). Subcortical plasticity following perceptual learning in a pitch discrimination task. J. Assoc. Res. Otolaryngol. 12, 89–100. doi: 10.1007/s10162-010-0236-1
Chmiel, R., and Jerger, J. (1996). Hearing aid use, central auditory disorder, and hearing handicap in elderly persons. J. Am. Acad. Audiol. 7, 190–202.
Clift, S., and Hancox, G. (2001). The perceived benefits of singing: findings from preliminary surveys of a university college choral society. J. R. Soc. Promot. Health 121, 248–256. doi: 10.1177/146642400112100409
Clift, S., and Morrison, I. (2011). Group singing fosters mental health and wellbeing: findings from the East Kent “singing for health” network project. Men. Health Soc. Inclusion 15, 88–97. doi: 10.1108/20428301111140930
Clinard, C. G., Tremblay, K. L., and Krishnan, A. R. (2010). Aging alters the perception and physiological representation of frequency: evidence from human frequency-following response recordings. Hear. Res. 264, 48–55. doi: 10.1016/j.heares.2009.11.010
Coffey, E. B. J., Chepesiuk, A. M. P., Herholz, S. C., Baillet, S., and Zatorre, R. J. (2017a). Neural correlates of early sound encoding and their relationship to speech-in-noise perception. Front. Neurosci. 11:1–14. doi: 10.3389/fnins.2017.00479
Coffey, E. B. J., Herholz, S. C., Chepesiuk, A. M. P., Baillet, S., and Zatorre, R. J. (2016). Cortical contributions to the auditory frequency-following response revealed by MEG. Nat. Commun. 7:11070. doi: 10.1038/ncomms11070
Coffey, E. B. J., Mogilever, N. B., and Zatorre, R. J. (2017b). Speech-in-noise perception in musicians: a review. Hear. Res. 352, 49–69. doi: 10.1016/j.heares.2017.02.006
Cohen, G. D., Perlstein, S., Chapline, J., Kelly, J., Firth, K. M., and Simmens, S. (2006). The impact of professionally conducted cultural programs on the physical health, mental health, and social functioning of older adults. Gerontologist 46, 726–734. doi: 10.1093/geront/46.6.726
Creech, A., Hallam, S., McQueen, H., and Varvarigou, M. (2013). The power of music in the lives of older adults. Res. Stud. Music Educ. 35, 87–102. doi: 10.1177/1321103X13478862
Cruickshanks, K. J., Wiley, T. L., Tweed, T. S., Klein, B. E. K., Klein, R., Mares-Perlman, J. A., et al. (1998). Prevalence of hearing loss in older adults in beaver dam, wisconsin. Am. J. Audiol. 148, 879–886. doi: 10.1093/oxfordjournals.aje.a009713
Dalla Bella, S., and Berkowska, M. (2009). Singing proficiency in the majority: normality and “phenotypes” of poor singing. Ann. N. Y. Acad. Sci. 1169, 99–107. doi: 10.1111/j.1749-6632.2009.04558.x
Dalla Bella, S., Giguère, J.-F., and Peretz, I. (2007). Singing proficiency in the general population. J. Acoust. Soc. Am. 121, 1182–1189. doi: 10.1121/1.2427111
Daneman, M., and Carpenter, P. A. (1980). Individual differences in working memory during reading. J. Verb. Learn. Verb. Behav. 19, 450–466. doi: 10.1016/S0022-5371(80)90312-6
David, S. V., Fritz, J. B., and Shamma, S. A. (2012). Task reward structure shapes rapid receptive field plasticity in auditory cortex. Proc. Natl. Acad. Sci. U.S.A. 109, 2144–2149. doi: 10.1073/pnas.1117717109
Delorme, A., and Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
Djernes, J. K. (2006). Prevalence and predictors of depression in populations of elderly: a review. Acta Psychiatr. Scand. 113, 372–387. doi: 10.1111/j.1600-0447.2006.00770.x
Donai, J. J., and Jennings, M. B. (2016). Gaps-in-noise detection and gender identification from noise-vocoded vowel segments: comparing performance of active musicians to non-musicians. J. Acoust. Soc. Am. 139, EL128–EL134. doi: 10.1121/1.4947070
Du, Y., Buchsbaum, B. R., Grady, C. L., and Alain, C. (2014). Noise differentially impacts phoneme representations in the auditory and speech motor systems. Proc. Natl. Acad. Sci. U.S.A. 111, 7126–7131. doi: 10.1073/pnas.1318738111
Du, Y., Buchsbaum, B. R., Grady, C. L., and Alain, C. (2016). Increased activity in frontal motor cortex compensates impaired speech perception in older adults. Nat. Commun. 7, 1–12. doi: 10.1038/ncomms12241
Dubno, J. R., Dirks, D. D., and Morgan, D. E. (1984). Effects of age and mild hearing loss on speech recognition in noise. J. Acoust. Soc. Am. 76, 87–96. doi: 10.1121/1.391011
Fabiani, M. (2012). It was the best of times, it was the worst of times: a psychophysiologist’s view of cognitive aging. Psychophysiology 49, 283–304. doi: 10.1111/j.1469-8986.2011.01331.x
Fitzgibbons, P. J., and Gordon-Salant, S. (1994). Age effects on measures of auditory duration discrimination. J. Speech Hear. Res. 37, 662–670. doi: 10.1044/jshr.3703.662
Fozard, J. L. (1990). “Vision and hearing in aging,” in The Handbooks of Aging. Handbook of the Psychology of Aging, eds J. E. Birren, and K. W. Schaie, (San Diego, CA: Academic Press), 150–170. doi: 10.1016/b978-0-12-101280-9.50015-2
Frisina, R. D., and Frisina, R. D. (1997). Speech recognition in noise and presbycusis: relations to possible neural mechanisms. Hear. Res. 106, 95–104. doi: 10.1016/S0378-5955(97)00006-3
Frisina, R. D., and Walton, J. P. (2006). Age-related structural and functional changes in the cochlear nucleus. Hear. Res. 216–217, 216–223. doi: 10.1016/j.heares.2006.02.003
Fu, M. C., Belza, B., Nguyen, H., Logsdon, R., and Demorest, S. (2018). Impact of group-singing on older adult health in senior living communities: a pilot study. Arch. Gerontol. Geriatr. 76, 138–146. doi: 10.1016/j.archger.2018.02.012
Fujioka, T., Ross, B., Kakigi, R., Pantev, C., and Trainor, L. J. (2006). One year of musical training affects development of auditory cortical-evoked fields in young children. Brain 129, 2593–2608. doi: 10.1093/brain/awl247
Fuller, C. D., Galvin, J. J., Maat, B., Free, R. H., and Başkent, D. (2014). The musician effect: does it persist under degraded pitch conditions of cochlear implant simulations? Front. Neurosci. 8:179. doi: 10.3389/fnins.2014.00179
Gaser, C., and Schlaug, G. (2003). Brain structures differ between musicians and non-musicians. J. Neurosci. 23, 9240–9245. doi: 10.1523/jneurosci.23-27-09240.2003
Gomez, R. G., and Madey, S. F. (2001). Coping-with-hearing-loss model for older adults. J. Gerontol. B Psychol. Sci. Soc. Sci. 56, 223–225.
Good, A., and Russo, F. A. (2016). Singing promotes cooperation in a diverse group of children. Soc. Psychol. 47, 1–5. doi: 10.1027/1864-9335/a000282
Gordon-Salant, S. (2005). Hearing loss and aging: new research findings and clinical implications. J. Rehabil. Res. Dev. 42(4 Suppl. 2), 9–24. doi: 10.1682/JRRD.2005.01.0006
Grassi, M., Meneghetti, C., Toffalini, E., and Borella, E. (2017). Auditory and cognitive performance in elderly musicians and nonmusicians. PLoS One 12:e0187881. doi: 10.1371/journal.pone.0187881
Habibi, A., Cahn, B. R., Damasio, A., and Damasio, H. (2016). Neural correlates of accelerated auditory processing in children engaged in music training. Dev. Cogn. Neurosci. 21, 1–14. doi: 10.1016/j.dcn.2016.04.003
Habibi, A., Wirantana, V., and Starr, A. (2014). Cortical activity during perception of musical rhythm: comparing musicians and nonmusicians. Psychomusicology 24, 125–135. doi: 10.1037/pmu0000046
Hanna-Pladdy, B., and MacKay, A. (2011). The relation between instrumental musical activity and cognitive aging. Neuropsychology 25, 378–386. doi: 10.1037/a0021895
Hargus, S. E., and Gordon-Salant, S. (1995). Accuracy of speech intelligibility index predictions for noise-masked young listeners with normal hearing and for elderly listeners with hearing impairment. J. Speech Hear. Res. 38, 234–243. doi: 10.1044/jshr.3801.234
Hays, T., and Minichiello, V. (2005). The meaning of music in the lives of older people: a qualitative study. Psychol. Music 33, 437–451. doi: 10.1177/0305735605056160
Herdener, M., Esposito, F., di Salle, F., Boller, C., Hilti, C. C., Habermeyer, B., et al. (2010). Musical training induces functional plasticity in human hippocampus. J. Neurosci. 30, 1377–1384. doi: 10.1523/JNEUROSCI.4513-09.2010
Herholz, S. C., and Zatorre, R. J. (2012). Musical training as a framework for brain plasticity: behavior, function, and structure. Neuron 76, 486–502. doi: 10.1016/j.neuron.2012.10.011
Hickok, G. (2001). Functional anatomy of speech perception and speech production: psycholinguistic implications. J. Psychol. Res. 30, 225–235. doi: 10.1023/A:1010486816667
Hickok, G., Buchsbaum, B., Humphries, C., and Muftuler, T. (2003). Auditory-motor interaction revealed by fMRI: speech, music, and working memory in area Spt. J. Cogn. Neurosci. 15, 673–682. doi: 10.1162/089892903322307393
Hickson, L., Worrall, L., and Scarinci, N. (2007). A randomized controlled trial evaluating the active communication education program for older people with hearing impairment. Ear Hear. 28, 212–230. doi: 10.1097/AUD.0b013e31803126c8
Hickson, L., Worrall, L., Scarinci, N., and Laplante-Lévesque, A. (2019). Individualised active communication education (I-ACE): another clinical option for adults with hearing impairment with a focus on problem solving and self-management. Int. J. Audiol. 0, 1–6. doi: 10.1080/14992027.2019.1587180
Hillman, S. (2002). Participatory singing for older people: a perception of benefit. Health Educ. 102, 163–171. doi: 10.1108/09654280210434237
Hoormann, J., Falkenstein, M., Hohnsbein, J., and Blanke, L. (1992). The human frequency-following response (FFR): normal variability and relation to the click-evoked brainstem response. Hear. Res. 59, 179–188. doi: 10.1016/0378-5955(92)90114-3
Houde, J. F., and Jordan, M. I. (1998). Sensorimotor adaptation in speech production. Science 279, 1213–1216. doi: 10.1126/science.279.5354.1213
Hyde, K. L., Lerch, J., Norton, A., Forgeard, M., Winner, E., Evans, A. C., et al. (2009). Musical training shapes structural brain development. J. Neurosci. 29, 3019–3025. doi: 10.1523/JNEUROSCI.5118-08.2009
Jain, C., Mohamed, H., and Kumar, U. A. (2015). The effect of short-term musical training on speech perception in noise. Audiol. Res. 5, 5–8. doi: 10.4081/audiores.2015.111
Johnson, K. L., Nicol, T. G., and Kraus, N. (2005). Brain stem response to speech: a biological marker of auditory processing. Ear Hear. 26, 424–434. doi: 10.1097/01.aud.0000179687.71662.6e
Killion, M. C. (1997). Hearing aids: past, present, future: moving toward normal conversation in noise. Br. J. Audiol. 31, 141–148. doi: 10.3109/03005364000000016
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., and Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 116:2395. doi: 10.1121/1.1784440
Kim, S. H., Frisina, R. D., Mapes, F. M., Hickman, E. D., and Frisina, D. R. (2006). Effect of age on binaural speech intelligibility in normal hearing adults. Speech Commun. 48, 591–597. doi: 10.1016/j.specom.2005.09.004
Kishon-Rabin, L., Amir, O., Vexler, Y., and Zaltz, Y. (2001). Pitch discrimination: are professional musicians better than non-musicians? J. Basic Clin. Physiol. Pharmacol. 12, 125–143.
Koelsch, S., Schröger, E., and Tervaniemi, M. (1999). Superior pre-attentive auditory processing in musicians. Neuroreport 10, 1309–1313. doi: 10.1097/00001756-199904260-00029
Kraus, N., and Chandrasekaran, B. (2010). Music training for the development of auditory skills. Nat. Rev. Neurosci. 11, 599–605. doi: 10.1038/nrn2882
Kraus, N., Skoe, E., Parbery-Clark, A., and Ashley, R. (2009). Experience-induced malleability in neural encoding of pitch, timbre, and timing: implications for language and music. Ann. N. Y. Acad. Sci. 1169, 543–557. doi: 10.1111/j.1749-6632.2009.04549.x
Kraus, N., Strait, D. L., and Parbery-Clark, A. (2012). Cognitive factors shape brain networks for auditory skills: spotlight on auditory working memory. Ann. N. Y. Acad. Sci. 1252, 100–107. doi: 10.1111/j.1749-6632.2012.06463.x
Kreutz, G., Bongard, S., Rohrmann, S., Hodapp, V., and Grebe, D. (2004). Effects of choir singing or listening on secretory immunoglobulin a, cortisol, and emotional state. J. Behav. Med. 27, 623–635. doi: 10.1007/s10865-004-0006-9
Kricos, P. B., and Holmest, A. E. (1996). Efficacy of audiologic rehabilitation for older adults. J. Am. Acad. Audiol. 7, 219–229.
Kuriki, S. (2006). Effects of musical experience on different components of MEG responses elicited by sequential piano-tones and chords. J. Neurosci. 26, 4046–4053. doi: 10.1523/JNEUROSCI.3907-05.2006
Lappe, C., Herholz, S. C., Trainor, L. J., and Pantev, C. (2008). Cortical plasticity induced by short-term unimodal and multimodal musical training. J. Neurosci. 28, 9632–9639. doi: 10.1523/JNEUROSCI.2254-08.2008
Lappe, C., Trainor, L. J., Herholz, S. C., and Pantev, C. (2011). Cortical plasticity induced by short-term multimodal musical rhythm training. PLoS One 6:e21493. doi: 10.1371/journal.pone.0021493
Lee, K. M., Skoe, E., Kraus, N., and Ashley, R. (2009). Selective subcortical enhancement of musical intervals in musicians. J. Neurosci. 29, 5832–5840. doi: 10.1523/JNEUROSCI.6133-08.2009
Lehmann, A., and Schönwiesner, M. (2014). Selective attention modulates human auditory brainstem responses: relative contributions of frequency and spatial cues. PLoS One 9:e85442. doi: 10.1371/journal.pone.0085442
Madsen, S. M. K., Marschall, M., Dau, T., and Oxenham, A. J. (2019). Speech perception is similar for musicians and non-musicians across a wide range of conditions. Sci. Rep. 9, 1–10. doi: 10.1038/s41598-019-46728-1
Madsen, S. M. K., Whiteford, K. L., and Oxenham, A. J. (2017). Musicians do not benefit from differences in fundamental frequency when listening to speech in competing speech backgrounds. Sci. Rep. 7, 1–10. doi: 10.1038/s41598-017-12937-9
Mansens, D., Deeg, D. J. H., and Comijs, H. C. (2017). The association between singing and/or playing a musical instrument and cognitive functions in older adults. Aging Men. Health 22, 1–8. doi: 10.1080/13607863.2017.1328481
Meha-Bettison, K., Sharma, M., Ibrahim, R. K., and Mandikal Vasuki, P. R. (2018). Enhanced speech perception in noise and cortical auditory evoked potentials in professional musicians. Int. J. Audiol. 57, 40–52. doi: 10.1080/14992027.2017.1380850
Micheyl, C., Delhommeau, K., Perrot, X., and Oxenham, A. J. (2006). Influence of musical and psychoacoustical training on pitch discrimination. Hear. Res. 219, 36–47. doi: 10.1016/j.heares.2006.05.004
Middelweerd, M. J., Festen, J. M., and Plomp, R. (1990). Difficulties with speech intelligibility in noise in spite of a normal pure-tone audiogram: original papers. Int. J. Audiol. 29, 1–7. doi: 10.3109/00206099009081640
Mithen, S., Morley, I., Wray, A., Tallerman, M., and Gamble, C. (2006). The singing neanderthals: the origins of music, language, mind and body. Cambridge Archaeol. J. 16, 97–112. doi: 10.1017/S0959774306000060
Musacchia, G., Ortiz-Mantilla, S., Choudhury, N., Realpe-Bonilla, T., Roesler, C., and Benasich, A. A. (2017). Active auditory experience in infancy promotes brain plasticity in theta and gamma oscillations. Dev. Cogn. Neurosci. 26, 9–19. doi: 10.1016/j.dcn.2017.04.004
Musacchia, G., Sams, M., Skoe, E., and Kraus, N. (2007). Musicians have enhanced subcortical auditory and audiovisual processing of speech and music. Proc. Natl. Acad. Sci. U. S. A. 104, 15894–15898. doi: 10.1073/pnas.0701498104
Musacchia, G., Strait, D., and Kraus, N. (2008). Relationships between behavior, brainstem and cortical encoding of seen and heard speech in musicians and non-musicians. Hear. Res. 241, 34–42. doi: 10.1016/j.heares.2008.04.013
Pantev, C., Ross, B., Fujioka, T., Trainor, L. J., Schulte, M., and Schulz, M. (2003). Music and learning-induced cortical plasticity. Ann. N. Y. Acad. Sci. 999, 438–450. doi: 10.1196/annals.1284.054
Papoušek, H. (1996). “Musicality in infancy research: biological and cultural origins of early musicality,” in Musical Beginnings, eds I. Deliège, and J. Sloboda (Oxford: Oxford University Press), 37–55. doi: 10.1093/acprof:oso/9780198523321.003.0002
Parbery-Clark, A., Anderson, S., Hittner, E., and Kraus, N. (2012). Musical experience offsets age-related delays in neural timing. Neurobiol. Aging 33, 1–4. doi: 10.1016/j.neurobiolaging.2011.12.015
Parbery-Clark, A., Skoe, E., Lam, C., and Kraus, N. (2009). Musician enhancement for speech-in-noise. Ear Hear. 30, 653–661. doi: 10.1097/AUD.0b013e3181b412e9
Parbery-Clark, A., Strait, D. L., Anderson, S., Hittner, E., and Kraus, N. (2011). Musical experience and the aging auditory system: implications for cognitive abilities and hearing speech in noise. PLoS One 6:e18082. doi: 10.1371/journal.pone.0018082
Patel, A. D. (2014). Can nonlinguistic musical training change the way the brain processes speech? the expanded OPERA hypothesis. Hear. Res. 308, 98–108. doi: 10.1016/j.heares.2013.08.011
Pfordresher, P. Q., and Brown, S. (2007). Poor-pitch singing in the absence of “tone deafness.”. Music Percep. 25, 95–115. doi: 10.1525/mp.2007.25.2.95
Pfordresher, P. Q., and Dalla Bella, S. (2011). Delayed auditory feedback and movement. J. Chem. Inform. Model. 53:160. doi: 10.1017/CBO9781107415324.004
Pichora-Fuller, M. K., and Schneider, B. (1992). The effect of interaural delay of the masker on masking-level differences in young and old adults. J. Acoust. Soc. Am. 91(4 Pt 1), 2129–2135. doi: 10.1121/1.403673
Pichora-Fuller, M. K., Schneider, B., MacDonald, E., Pass, H. E., and Brown, S. (2007). Temporal jitter disrupts speech intelligibility: a simulation of auditory aging. Hear. Res. 223, 114–121. doi: 10.1016/j.heares.2006.10.009
Pichora-Fuller, M. K., Schneider, B. A., and Daneman, M. (1995). How young and old adults listen to and remember speech in noise. J. Acoust. Soc. Am. 97, 593–608. doi: 10.1121/1.412282
Pinheiro, J., Bates, D., DebRoy, S., and Sarkar, D., and R Core Team, (2019). Nlme: Linear and Nonlinear Mixed Effects Models. R package Version 3.1-141. Available at: https://CRAN.R-project.org/package=nlme
Pruitt, T. A., and Pfordresher, P. Q. (2015). The role of auditory feedback in speech and song. J. Exp. Psychol. Hum. Percep. Perform. 41, 152–166. doi: 10.1037/a0038285
Rammsayer, T., and Altenmüller, E. (2006). Temporal information processing in musicians and nonmusicians. Music Percep. 24, 37–48. doi: 10.1525/mp.2006.24.1.37
Raz, N., Millman, D., and Moberg, P. J. (1989). Auditory memory and age-related differences in two-tone frequency discrimination: trace decay and interference. Exp. Aging Res. 15, 43–47. doi: 10.1080/03610738908259757
Ricketts, T. A., and Hornsby, B. W. Y. (2005). Sound quality measures for speech in noise through a commercial hearing aid implementing digital noise reduction. J. Am. Acad. Audiol. 16, 270–277. doi: 10.3766/jaaa.16.5.2
Ridderinkhof, K. R., van der Molen, M. W., Band, G. P., and Bashore, T. R. (1997). Sources of interference from irrelevant information: a developmental study. J. Exp. Child Psychol. 65, 315–341. doi: 10.1006/jecp.1997.2367
Ruggles, D. R., Freyman, R. L., and Oxenham, A. J. (2014). Influence of musical training on understanding voiced and whispered speech in noise. PLoS One 9:e86980. doi: 10.1371/journal.pone.0086980
Russo, F. A., Ives, D. T., Goy, H., Pichora-Fuller, M. K., and Patterson, R. D. (2012). Age-related difference in melodic pitch perception is probably mediated by temporal processing: empirical and computational evidence. Ear Hear. 33, 177–186. doi: 10.1097/AUD.0b013e318233acee
Russo, F. A., and Pichora-Fuller, M. K. (2008). Tune in or tune out: age-related differences in listening to speech in music. Ear Hear. 29, 746–760. doi: 10.1097/AUD.0b013e31817bdd1f
Russo, N. M., Nicol, T. G., Zecker, S. G., Hayes, E. A., and Kraus, N. (2005). Auditory training improves neural timing in the human brainstem. Behav. Brain Res. 156, 95–103. doi: 10.1016/j.bbr.2004.05.012
Sabes, J. H., and Sweetow, R. W. (2007). Variables predicting outcomes on listening and communication enhancement (LACETM) training. Int. J. Audiol. 46, 374–383. doi: 10.1080/14992020701297565
Särkämö, T., Tervaniemi, M., Laitinen, S., Numminen, A., Kurki, M., Johnson, J. K., et al. (2014). Cognitive, emotional, and social benefits of regular musical activities in early dementia: randomized controlled study. Gerontologist 54, 634–650. doi: 10.1093/geront/gnt100
Saunders, G. H., Smith, S. L., Chisolm, T. H., Frederick, M. T., McArdle, R. A., and Wilson, R. H. (2016). A randomized control trial: supplementing hearing aid use with listening and communication enhancement (LACE) auditory training. Ear Hear. 37, 381–396. doi: 10.1097/AUD.0000000000000283
Schellenberg, E. G. (2019). Music training, music aptitude, and speech perception. Proc. Natl. Acad. Sci. 116, 2783–2784. doi: 10.1073/pnas.1821109116
Schellenberg, E. G., and Moreno, S. (2009). Music lessons, pitch processing, and g. Psychol. Music 38, 209–221. doi: 10.1097/MAO.0000000000002123
Schlaug, G. (2015). Musicians and music making as a model for the study of brain plasticity. Prog. Brain Res. 217, 37–55. doi: 10.1016/bs.pbr.2014.11.020
Schlaug, G., Jäncke, L., Huang, Y. Y., and Steinmetz, H. (1995). In vivo evidence of structural brain asymmetry in musicians. Science 267, 699–701. doi: 10.1126/science.7839149
Schneider, B. (1997). Psychoacoustics and aging: implications for everyday listening. J. Speech Lang. Pathol. Audiol. 21, 111–124.
Schneider, B., Pichora-Fuller, K., and Daneman, M. (2010). Effects of senescent changes in audition and cognition on spoken language comprehension. Springer Handb. Auditory Res. 34, 167–210. doi: 10.1007/978-1-4419-0993-0
Schneider, B., Pichora-Fuller, M. K., Kowalchuk, D., and Lamb, M. (1994). Gap detection and the precedence effect in young and old adults. J. Acoust. Soc. Am. 95, 980–991. doi: 10.1121/1.408403
Schneider, B. A., Daneman, M., and Pichora-Fuller, M. K. (2002). Listening in aging adults: from discourse comprehension to psychoacoustics. Can. J. Exp. Psychol. 56, 139–152. doi: 10.1037/h0087392
Schneider, P., Scherg, M., Dosch, H. G., Specht, H. J., Gutschalk, A., and Rupp, A. (2002). Morphology of Heschl’s gyrus reflects enhanced activation in the auditory cortex of musicians. Nat. Neurosci. 5, 688–694. doi: 10.1038/nn871
Schulze, K., Zysset, S., Mueller, K., Friederici, A. D., and Koelsch, S. (2011). Neuroarchitecture of verbal and tonal working memory in nonmusicians and musicians. Hum. Brain Mapp. 32, 771–783. doi: 10.1002/hbm.21060
Shahin, A., Bosnyak, D. J., Trainor, L. J., and Roberts, L. E. (2003). Enhancement of neuroplastic P2 and N1c auditory evoked potentials in musicians. J. Neurosci. 23, 5545–5552. doi: 10.1523/jneurosci.23-13-05545.2003
Shepard, K. N., Kilgard, M. P., and Liu, R. C. (2013). “Experience-dependent plasticity and auditory cortex,” in Neural Correlates of Auditory Cognition, eds Y. E. Cohen, A. N. Popper, and R. R. Fay (Berlin: Springer), 293–327 doi: 10.1007/978-1-4614-2350-8_10
Skoe, E., and Kraus, N. (2010). Auditory brainstem response to complex sounds: a tutorial. Ear Hear. 31, 302–324. doi: 10.1097/AUD.0b013e3181cdb272.Auditory
Skoe, E., and Kraus, N. (2013). Musical training heightens auditory brainstem function during sensitive periods in development. Front. Psychol. 4:622. doi: 10.3389/fpsyg.2013.00622
Slater, J., Azem, A., Nicol, T., Swedenborg, B., and Kraus, N. (2017). Variations on the theme of musical expertise: cognitive and sensory processing in percussionists, vocalists and non-musicians. Eur. J. Neurosci. 45, 952–963. doi: 10.1111/ejn.13535
Slater, J., Skoe, E., Strait, D. L., O’Connell, S., Thompson, E., and Kraus, N. (2015). Music training improves speech-in-noise perception: longitudinal evidence from a community-based music program. Behav. Brain Res. 291, 244–252. doi: 10.1016/j.bbr.2015.05.026
Slevc, L. R., Davey, N. S., Buschkuehl, M., and Jaeggi, S. M. (2016). Tuning the mind: exploring the connections between musical ability and executive functions. Cognition 152, 199–211. doi: 10.1016/j.cognition.2016.03.017
Smith, J. C., Marsh, J. T., and Brown, W. S. (1975). Far-field recorded frequency-following responses: evidence for the locus of brainstem sources. Electroencephalogr. Clin. Neurophysiol. 39, 465–472. doi: 10.1016/0013-4694(75)90047-4
Solé Resano, C., Mercadal-Brotons, M., Gallego Matas, S., and Riera, M. (2010). Contribution of music to aging adults’ quality of life. J. Music Ther. 47:264. doi: 10.1093/jmt/47.3.264
Song, J. H., Skoe, E., Banai, K., and Kraus, N. (2012). Training to improve hearing speech in noise: biological mechanisms. Cereb. Cortex 22, 1180–1190. doi: 10.1093/cercor/bhr196
Souza, P. E., Boike, K. T., Witherell, K., and Tremblay, K. (2007). Prediction of speech recognition from audibility in older listeners with hearing loss: effects of age, amplification, and background noise. J. Am. Acad. Audiol. 18, 54–65. doi: 10.3766/jaaa.18.1.5
Strait, D. L., Kraus, N., Skoe, E., and Ashley, R. (2009). Musical experience and neural efficiency - Effects of training on subcortical processing of vocal expressions of emotion. Eur. J. Neurosci. 29, 661–668. doi: 10.1111/j.1460-9568.2009.06617.x
Swaminathan, J., Mason, C. R., Streeter, T. M., Best, V., Kidd, G., and Patel, A. D. (2015). Musical training, individual differences and the cocktail party problem. Sci. Rep. 5:11628. doi: 10.1038/srep11628
Sweetow, R. W., and Sabes, J. H. (2006). The need for and development of an adaptive listening and communication enhancement (LACETM) program. J. Am. Acad. Audiol. 17, 538–558. doi: 10.3766/jaaa.17.8.2
Sweetow, R. W., and Sabes, J. H. (2010). Auditory training and challenges associated with participation and compliance. J. Am. Acad. Audiol. 21, 586–593. doi: 10.3766/jaaa.21.9.4
Syka, J. (2002). Plastic changes in the central auditory system after hearing loss, restoration of function, and during learning. Physiol. Rev. 82, 601–636. doi: 10.1152/physrev.00002.2002
Tierney, A. T., Krizman, J., and Kraus, N. (2015). Music training alters the course of adolescent auditory development. Proc. Natl. Acad. Sci. U.S.A. 112, 10062–10067. doi: 10.1073/pnas.1505114112
Tremblay, K. L., Piskosz, M., and Souza, P. (2003). Effects of age and age-related hearing loss on the neural representation of speech cues. Clin. Neurophysiol 114, 1332–1343. doi: 10.1016/S1388-2457(03)00114-7
Tye-Murray, N., Sommers, M. S., Mauzé, E., Schroy, C., Barcroft, J., and Spehar, B. (2012). Using patient perceptions of relative benefit and enjoyment to assess auditory training. J. Am. Acad. Audiol 23, 623–634. doi: 10.3766/jaaa.23.8.7
Vermiglio, A. J., Soli, S. D., Freed, D. J., and Fisher, L. M. (2012). The relationship between high-frequency pure-tone hearing loss, hearing in noise test (HINT) thresholds, and the articulation index. J. Am. Acad. Audiol. 23, 779–788. doi: 10.3766/jaaa.23.10.4
Walton, J. P., Frisina, R. D., and O’Neill, W. E. (1998). Age-related alteration in processing of temporal sound features in the auditory midbrain of the CBA mouse. J. Neurosci. 18, 2764–2776. doi: 10.1523/jneurosci.18-07-02764.1998
West, G. L., Zendel, B. R., Konishi, K., Benady-Chorney, J., Bohbot, V. D., Peretz, I., et al. (2017). Playing super mario 64 increases hippocampal grey matter in older adults. PLoS One 12:e0187779. doi: 10.1371/journal.pone.0187779
Whitehead, J. C., and Armony, J. L. (2018). Singing in the brain: neural representation of music and voice as revealed by fMRI. Hum. Brain Mapp. 39, 4913–4924. doi: 10.1002/hbm.24333
White-Schwoch, T., Carr, K. W., Anderson, S., Strait, D. L., and Kraus, N. (2013). Older adults benefit from music training early in life: biological evidence for long-term training-driven plasticity. J. Neurosci. 33, 17667–17674. doi: 10.1523/JNEUROSCI.2560-13.2013
Wilson, R. H., McArdle, R. A., and Smith, S. L. (2007). An evaluation of the BKB-SIN, HINT, QuickSIN, and WIN materials on listeners with normal hearing and listeners with hearing loss. J. Speech Lang. Hear. Res. 50:844. doi: 10.1044/1092-4388(2007/059)
Wingfield, A., Tun, P. A., and McCoy, S. L. (2005). Hearing loss in older adulthood: what it is and how it interacts with cognitive performance. Curr. Direct. Psychol. Sci. 14, 144–148. doi: 10.1111/j.0963-7214.2005.00356.x
Wong, P. C. M., Skoe, E., Russo, N. M., Dees, T., and Kraus, N. (2007). Musical experience shapes human brainstem encoding of linguistic pitch patterns. Nat. Neurosci. 10, 420–422. doi: 10.1038/nn1872
Yamasoba, T., Lin, F. R., Someya, S., Kashio, A., Sakamoto, T., and Kondo, K. (2013). Current concepts in age-related hearing loss: epidemiology and mechanistic pathways. Hear. Res. 303, 30–38. doi: 10.1016/j.heares.2013.01.021
Yates, K., Moore, D., Amitay, S., and Barry, J. (2018). Sensitivity to melody, rhythm, and beat in supporting speech-in-noise perception in young adults. Ear Hear. 40, 358–367. doi: 10.1097/AUD.0000000000000621
Yueh, B., Shapiro, N., MacLean, C. H., and Shekelle, P. G. (2003). Screening and management of adult hearing loss in primary care: scientific review. JAMA 289, 1976–1985. doi: 10.1001/jama.289.15.1976
Zatorre, R. J., Chen, J. L., and Penhune, V. B. (2007). When the brain plays music: auditory–motor interactions in music perception and production. Nat. Rev. Neurosci. 8, 547–558. doi: 10.1038/nrn2152
Zendel, B. R., and Alain, C. (2009). Concurrent sound segregation is enhanced in musicians. J. Cogn. Neurosci. 21, 1488–1498. doi: 10.1162/jocn.2009.21140
Zendel, B. R., and Alain, C. (2012). Musicians experience less age-related decline in central auditory processing. Psychol. Aging 27, 410–417. doi: 10.1037/a0024816
Zendel, B. R., Tremblay, C.-D., Belleville, S., and Peretz, I. (2015). The impact of musicianship on the cortical mechanisms related to separating speech from background noise. J. Cogn. Neurosci. 27, 1044–1059. doi: 10.1162/jocn-a-00758
Zendel, B. R., West, G., Belleville, S., and Peretz, I. (2019). Music training improves the ability to understand speech-in-noise in older adults. Neurobiol. Aging 81, 102–115. doi: 10.1016/j.neurobiolaging.2019.05.015
Keywords: aging, musical training, speech-in-noise, frequency, hearing
Citation: Dubinsky E, Wood EA, Nespoli G and Russo FA (2019) Short-Term Choir Singing Supports Speech-in-Noise Perception and Neural Pitch Strength in Older Adults With Age-Related Hearing Loss. Front. Neurosci. 13:1153. doi: 10.3389/fnins.2019.01153
Received: 05 July 2019; Accepted: 11 October 2019;
Published: 28 November 2019.
Edited by:
Claude Alain, Rotman Research Institute (RRI), CanadaReviewed by:
Jeanette Tamplin, University of Melbourne, AustraliaEmily B. J. Coffey, Concordia University, Canada
Copyright © 2019 Dubinsky, Wood, Nespoli and Russo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ella Dubinsky, ZWxsYS5kdWJpbnNreUByeWVyc29uLmNh