 Abhronil Sengupta
Abhronil Sengupta Yuting Ye
Yuting Ye Robert Wang2
Robert Wang2 Kaushik Roy
Kaushik Roy- 1Department of Electrical and Computer Engineering, Purdue University, West Lafayette, IN, United States
- 2Facebook Reality Labs, Facebook Research, Redmond, WA, United States
Over the past few years, Spiking Neural Networks (SNNs) have become popular as a possible pathway to enable low-power event-driven neuromorphic hardware. However, their application in machine learning have largely been limited to very shallow neural network architectures for simple problems. In this paper, we propose a novel algorithmic technique for generating an SNN with a deep architecture, and demonstrate its effectiveness on complex visual recognition problems such as CIFAR-10 and ImageNet. Our technique applies to both VGG and Residual network architectures, with significantly better accuracy than the state-of-the-art. Finally, we present analysis of the sparse event-driven computations to demonstrate reduced hardware overhead when operating in the spiking domain.
1. Introduction
Spiking Neural Networks (SNNs) are a significant shift from the standard way of operation of Artificial Neural Networks (Farabet et al., 2012). Most of the success of deep learning models of neural networks in complex pattern recognition tasks are based on neural units that receive, process and transmit analog information. Such Analog Neural Networks (ANNs), however, disregard the fact that the biological neurons in the brain (the computing framework after which it is inspired) processes binary spike-based information. Driven by this observation, the past few years have witnessed significant progress in the modeling and formulation of training schemes for SNNs as a new computing paradigm that can potentially replace ANNs as the next generation of Neural Networks. In addition to the fact that SNNs are inherently more biologically plausible, they offer the prospect of event-driven hardware operation. Spiking Neurons process input information only on the receipt of incoming binary spike signals. Given a sparsely-distributed input spike train, the hardware overhead (power consumption) for such a spike or event-based hardware would be significantly reduced since large sections of the network that are not driven by incoming spikes can be power-gated (Chen et al., 1998). However, the vast majority of research on SNNs have been limited to very simple and shallow network architectures on relatively simple digit recognition datasets like MNIST (LeCun et al., 1998) while only few works report their performance on more complex standard vision datasets like CIFAR-10 (Krizhevsky and Hinton, 2009) and ImageNet (Russakovsky et al., 2015). The main reason behind their limited performance stems from the fact that SNNs are a significant shift from the operation of ANNs due to their temporal information processing capability. This has necessitated a rethinking of training mechanisms for SNNs.
2. Related Work
Broadly, there are two main categories for training SNNs—supervised and unsupervised. Although unsupervised learning mechanisms like Spike-Timing Dependent Plasticity (STDP) are attractive for the implementation of low-power on-chip local learning, their performance is still outperformed by supervised networks on even simple digit recognition platforms like the MNIST dataset (Diehl and Cook, 2015). Driven by this fact, a particular category of supervised SNN learning algorithms attempts to train ANNs using standard training schemes like backpropagation (to leverage the superior performance of standard training techniques for ANNs) and subsequently convert to event-driven SNNs for network operation (Pérez-Carrasco et al., 2013; Cao et al., 2015; Diehl et al., 2015; Zhao et al., 2015). This can be particularly appealing for NN implementations in low-power neuromorphic hardware specialized for SNNs (Merolla et al., 2014; Akopyan et al., 2015) or interfacing with silicon cochleas or event-driven sensors (Posch et al., 2011, 2014). Our work falls in this category and is based on the ANN-SNN conversion scheme proposed by authors in Diehl et al. (2015). However, while prior work considers the ANN operation only during the conversion process, we show that considering the actual SNN operation during the conversion step is crucial for achieving minimal loss in classification accuracy. To that effect, we propose a novel weight-normalization technique that ensures that the actual SNN operation is in the loop during the conversion phase. Note that this work tries to exploit neural activation sparsity by converting networks to the spiking domain for power-efficient hardware implementation and are complementary to efforts aimed at exploring sparsity in synaptic connections (Han et al., 2015a).
3. Main Contributions
The specific contributions of our work are as follows:
(i) As will be explained in later sections, there are various architectural constraints involved for training ANNs that can be converted to SNNs in a near-lossless manner. Hence, it is unclear whether the proposed techniques would scale to larger and deeper architectures for more complicated tasks. We provide proof of concept experiments that deep SNNs (extending from 16 to 34 layers) can provide competitive accuracies over complex datasets like CIFAR-10 and ImageNet.
(ii) We propose a new ANN-SNN conversion technique that statistically outperforms state-of-the-art techniques. We report a classification error of 8.45% on the CIFAR-10 dataset which is the best-performing result reported for any SNN network, till date. For the first time, we report an SNN performance on the entire ImageNet 2012 validation set. We achieve a 30.04% top-1 error rate and 10.99% top-5 error rate for VGG-16 architectures.
(iii) We explore Residual Network (ResNet) architectures as a potential pathway to enable deeper SNNs. We present insights and design constraints that are required to ensure ANN-SNN conversion for ResNets. We report a classification error of 12.54% on the CIFAR-10 dataset and a 34.53% top-1 error rate and 13.67% top-5 error rate on the ImageNet validation set. This is the first work that attempts to explore SNNs with residual network architectures.
(iv) We demonstrate that SNN network sparsity significantly increases as the network depth increases. This further motivates the exploration of converting ANNs to SNNs for event-driven operation to reduce compute overhead.
4. Preliminaries
4.1. Input and Output Representation
The main difference between ANN and SNN operation is the notion of time. While ANN inputs are static, SNNs operate based on dynamic binary spiking inputs as a function of time. The neural nodes also receive and transmit binary spike input signals in SNNs, unlike in ANNs, where the inputs and outputs of the neural nodes are analog values. In this work, we consider a rate-encoded network operation where the average number of spikes transmitted as input to the network over a large enough time window is approximately proportional to the magnitude of the original ANN inputs (pixel intensity in this case). The duration of the time window is dictated by the desired network performance (for instance, classification accuracy) at the output layer of the network. A Poisson event-generation process is used to produce the input spike train to the network. Every time-step of SNN operation is associated with the generation of a random number whose value is compared against the magnitude of the corresponding input. A spike event is triggered if the generated random number is less than the value of the corresponding pixel intensity. This process ensures that the average number of input spikes in the SNN is proportional to the magnitude of the corresponding ANN inputs and is typically used to simulate an SNN for recognition tasks based on datasets for static images (Diehl et al., 2015). Figure 1 depicts a particular timed-snapshot of the input spikes transmitted to the SNN for a particular image from the CIFAR-10 dataset. Note that since we are considering per pixel mean subtracted images, the input layer receives spikes whose rate is proportional to the input magnitude with sign equal to the input sign. However, for subsequent layers all spikes are positive in sign since there are generated by spiking neurons in the network. SNN operation of such networks are “pseudo-simultaneous,” i.e., a particular layer operates immediately on the incoming spikes from the previous layer and does not have to wait for multiple time-steps for information from the previous layer neurons to get accumulated. Given a Poisson-generated spike train being fed to the network, spikes will be produced at the network outputs. Inference is based on the cumulative spike count of neurons at the output layer of the network over a given time-window.
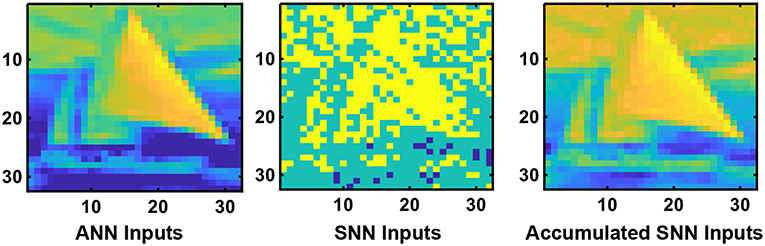
Figure 1. The extreme left panel depicts a particular input image from the CIFAR-10 dataset with per pixel mean (over the training set) subtracted that is provided as input to the original ANN. The middle panel represents a particular instance of the Poisson spike train generated from the analog input image. The accumulated events provided to the SNN over 1,000 timesteps is depicted in the extreme right panel. This justifies the fact that the input image is being rate encoded over time for SNN operation.
4.2. ANN and SNN Neural Operation
ANN to SNN conversion schemes usually consider Rectified Linear Unit (ReLU) as the ANN activation function. For a neuron receiving inputs xi through synaptic weights wi, the ReLU neuron output y is given by,
Although ReLU neurons are typically used in a large number of machine learning tasks at present, the main reason behind their usage for ANN-SNN conversion schemes is that they bear functional equivalence to an Integrate-Fire (IF) Spiking Neuron without any leak and refractory period (Cao et al., 2015; Diehl et al., 2015). Note that this is a particular type of Spiking Neuron model (Izhikevich, 2003). Let us consider the ANN inputs xi encoded in time as a spike train 𝕏i(t), where the average value of 𝕏i(t), E[𝕏i(t)] ∝ xi (for the rate encoding network being considered in this work). The IF Spiking Neuron keeps track of its membrane potential, vmem, which integrates incoming spikes and generates an output spike whenever the membrane potential cross a particular threshold vth. The membrane potential is reset to zero at the generation of an output spike. All neurons are reset whenever a spike train corresponding to a new image/pattern in presented. The IF Spiking Neuron dynamics as a function of time-step, t, can be described by the following equation,
Note that the neuron dynamics is independent of the actual magnitude of the time-step. Let us first consider the simple case of a neuron being driven by a single input 𝕏(t) and a positive synaptic weight w. Due to the absence of any leak term in the neural dynamics, it is intuitive to show that the corresponding output spiking rate of the neuron is given by E[Y(t)] ∝ E[𝕏(t)], with the proportionality factor being dependent on the ratio of w and vth. In the case when the synaptic weight is negative, the output spiking activity of the IF neuron is zero since the neuron is never able to cross the firing potential vth, mirroring the functionality of a ReLU. The higher the ratio of the threshold with respect to the weight, the more time is required for the neuron to spike, thereby reducing the neuron spiking rate, E[Y(t)], or equivalently increasing the time-delay for the neuron to generate a spike. A relatively high firing threshold can cause a huge delay for neurons to generate output spikes. For deep architectures, such a delay can quickly accumulate and cause the network to not produce any spiking outputs for relatively long periods of time. On the other hand, a relatively low threshold causes the SNN to lose any ability to distinguish between different magnitudes of the spike inputs being accumulated to the membrane potential (the term in Equation 2) of the Spiking Neuron, causing it to lose evidence during the membrane potential integration process. This, in turn, results in accuracy degradation of the converted network. Hence, an appropriate choice of the ratio of the neuron threshold to the synaptic weights is essential to ensure minimal loss in classification accuracy during the ANN-SNN conversion process (Diehl et al., 2015). Consequently, most of the research work in this field has been concentrated on outlining appropriate algorithms for threshold-balancing, or equivalently, weight normalizing different layers of a network to achieve near-lossless ANN-SNN conversion.
4.3. Architectural Constraints
4.3.1. Bias in Neural Units
Typically neural units used for ANN-SNN conversion schemes are trained without any bias term (Diehl et al., 2015). This is due to the fact that optimization of the bias term in addition to the spiking neuron threshold expands the parameter space exploration, thereby causing the ANN-SNN conversion process to be more difficult. Requirement of bias less neural units also entails that Batch Normalization technique (Ioffe and Szegedy, 2015) cannot be used as a regularizer during the training process since it biases the inputs to each layer of the network to ensure each layer is provided with inputs having zero mean. Instead, we use dropout (Srivastava et al., 2014) as the regularization technique. This technique simply masks portions of the input to each layer by utilizing samples from a Bernoulli distribution where each input to the layer has a specified probability of being dropped.
4.3.2. Pooling Operation
Deep convolutional neural network architectures typically consist of intermediate pooling layers to reduce the size of the convolution output maps. While various choices exist for performing the pooling mechanism, the two popular choices are either max-pooling (maximum neuron output over the pooling window) or spatial-averaging (two-dimensional average pooling operation over the pooling window). Since the neuron activations are binary in SNNs instead of analog values, performing max-pooling would result in significant information loss for the next layer. Consequently, we consider spatial-averaging as the pooling mechanism in this work (Diehl et al., 2015).
5. Deep Convolutional SNN Architectures: VGG
As mentioned previously, our work is based on the proposal outlined by authors in Diehl et al. (2015) wherein the neuron threshold of a particular layer is set equal to the maximum activation of all ReLUs in the corresponding layer (by passing the entire training set through the trained ANN once after training is completed). Such a “Data-Based Normalization” technique was evaluated for three-layered fully connected and convolutional architectures on the MNIST dataset (Diehl et al., 2015). Note that, this process is referred to as “weight-normalization” and “threshold-balancing” interchangeably in this text. As mentioned before, the goal of this work is to optimize the ratio of the synaptic weights with respect to the neuron firing threshold, vth. Hence, either all the synaptic weights preceding a neural layer are scaled by a normalization factor wnorm equal to the maximum neural activation and the threshold is set equal to 1 (“weight-normalization"), or the threshold vth is set equal to the maximum neuron activation for the corresponding layer with the synaptic weights remaining unchanged (“threshold-balancing"). Both operations are exactly equivalent mathematically.
5.1. Proposed Algorithm: Spike-Norm
However, the above algorithm leads us to the question: Are ANN activations representative of SNN activations? Let us consider a particular example for the case of maximum activation for a single ReLU. The neuron receives two inputs, namely 0.5 and 1. Let us consider unity synaptic weights in this scenario. Since the maximum ReLU activation is 1.5, the neuron threshold would be set equal to 1.5. However, when this network is converted to the SNN mode, both the inputs would be propagating binary spike signals. The ANN input, equal to 1, would be converted to spikes transmitting at every time-step while the other input would transmit spikes 50% of the duration of a large enough time-window. Hence, the actual summation of spike inputs received by the neuron per time-step would be 2 for a large number of samples, which is higher than the spiking threshold (1.5). Clearly, some information loss would take place due to the lack of this evidence integration.
Driven by this observation, we propose a weight-normalization technique that balances the threshold of each layer by considering the actual operation of the SNN in the loop during the ANN-SNN conversion process. The algorithm normalizes the weights of the network sequentially for each layer. Given a particular trained ANN, the first step is to generate the input Poisson spike train for the network over the training set for a large enough time-window. The Poisson spike train allows us to record the maximum summation of weighted spike-input (the term in Equation 2, and hereafter referred to maximum SNN activation in this text) that would be received by the first neural layer of the network. In order to minimize the temporal delay of the neuron and simultaneously ensure that the neuron firing threshold is not too low, we weight-normalize the first layer depending on the maximum spike-based input received by the first layer. After the threshold of the first layer is set, we are provided with a representative spike train at the output of the first layer which enables us to generate the input spike-stream for the next layer. The process is continued sequentially for all the layers of the network. The main difference between our proposal and prior work (Diehl et al., 2015) is the fact that the proposed weight-normalization scheme accounts for the actual SNN operation during the conversion process. As we will show in the Results section, this scheme is crucial to ensure near-lossless ANN-SNN conversion for significantly deep architectures and for complex recognition problems. We evaluate our proposal for VGG-16 network (Simonyan and Zisserman, 2014), a standard deep convolutional network architecture which consists of a 16 layer deep network composed of 3 × 3 convolution filters (with intermediate pooling layers to reduce the output map dimensionality with increasing number of maps). The pseudo-code of the algorithm is given below.

Algorithm 1: SPIKE-NORM
6. Extension to Residual Architectures
Residual network architectures were proposed as an attempt to scale convolutional neural networks to very deep layered stacks (He et al., 2016a). Although different variants of the basic functional unit have been explored, we will only consider identity shortcut connections in this text (shortcut type-A according to the paper; He et al., 2016a). Each unit consists of two parallel paths. The non-identity path consists of two spatial convolution layers with an intermediate ReLU layer. While the original ResNet formulation considers ReLUs at the junction of the parallel non-identity and identity paths (He et al., 2016a), recent formulations do not consider junction ReLUs in the network architecture (He et al., 2016b). Absence of ReLUs at the junction point of the non-identity and identity paths was observed to produce a slight improvement in classification accuracy on the CIFAR-10 dataset1. Due to the presence of the shortcut connections, important design considerations need to be accounted for to ensure near-lossless ANN-SNN conversion. We start with the basic unit, as shown in Figure 2A, and point-wise impose various architectural constraints with justifications. Note the discussion in this section is based on threshold-balancing (with synaptic weights remaining unscaled), i.e., the threshold of the neurons are adjusted to minimize ANN-SNN conversion loss.
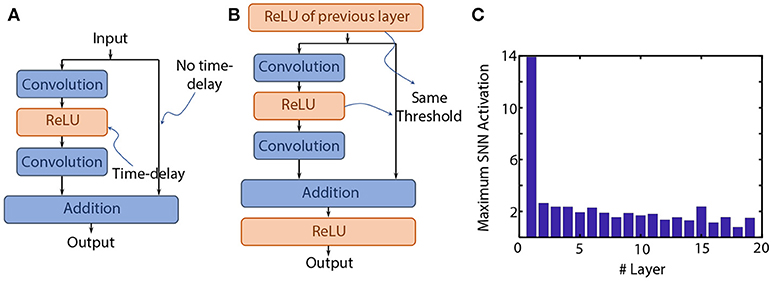
Figure 2. (A) The basic ResNet functional unit. (B) Design constraints introduced in the functional unit to ensure near-lossless ANN-SNN conversion. (C) Typical maximum SNN activations for a ResNet having junction ReLU layers but the non-identity and identity input paths not having the same spiking threshold. While this is not representative of the case with equal thresholds in the two paths, it does justify the claim that after a few initial layers, the maximum SNN activations decay to values close to unity due to the identity mapping.
6.1. ReLUs at Each Junction Point
As we will show in the Results section, application of our proposed SPIKE-NORM algorithm on such a residual architecture resulted in a converted SNN that exhibited accuracy degradation in comparison to the original trained ANN. We hypothesize that this degradation is attributed mainly to the absence of any ReLUs at the junction points. Each ReLU when converted to an IF Spiking Neuron imposes a particular amount of characteristic temporal delay (time interval between an incoming spike and the outgoing spike due to evidence integration). Due to the shortcut connections, spike information from the initial layers gets instantaneously propagated to later layers. The unbalanced temporal delay in the two parallel paths of the network can result in distortion of the spike information being propagated through the network. Consequently, as shown in Figure 2B, we include ReLUs at each junction point to provide a temporal balancing effect to the parallel paths (when converted to IF Spiking Neurons). An ideal solution would be to include a ReLU in the parallel path, but that would destroy the advantage of the identity mapping.
6.2. Same Threshold of All Fan-In Layers
As shown in the next section, direct application of our proposed threshold-balancing scheme still resulted in some amount of accuracy loss in comparison to the baseline ANN accuracy. However, note that the junction neuron layer receives inputs from the previous junction neuron layer as well as the non-identity neuron path. Since the output spiking activity of a particular neuron is also dependent on the threshold-balancing factor, all the fan-in neuron layers should be threshold-balanced by the same amount to ensure that input spike information to the next layer is rate-encoded appropriately. However, the spiking threshold of the neuron layer in the non-identity path is dependent on the activity of the neuron layer at the previous junction. An observation of the typical threshold-balancing factors for the network without using this constraint (shown in Figure 2C) reveal that the threshold-balancing factors mostly lie around unity after a few initial layers. This occurs mainly due to the identity mapping. The maximum summation of spike inputs received by the neurons in the junction layers are dominated by the identity mapping (close to unity). From this observation, we heuristically choose both the thresholds of the non-identity ReLU layer and the identity-ReLU layer equal to 1. However, the accuracy is still unable to approach the baseline ANN accuracy, which leads us to the third design constraint.
6.3. Initial Non-residual Pre-processing Layers
An observation of Figure 2C reveals that the threshold-balancing factors of the initial junction neuron layers are significantly higher than unity. This can be a primary reason for the degradation in classification accuracy of the converted SNN. We note that the residual architectures used by authors in He et al. (2016a) use an initial convolution layer with a very wide receptive field (7 × 7 with a stride of 2) on the ImageNet dataset. The main motive behind such an architecture was to show the impact of increasing depth in their residual architectures on the classification accuracy. Inspired by the VGG-architecture, we replace the first 7 × 7 convolutional layer by a series of three 3 × 3 convolutions where the first two layers do not exhibit any shortcut connections. Addition of such initial non-residual pre-processing layers allows us to apply our proposed threshold-balancing scheme in the initial layers while using a unity threshold-balancing factor for the later residual layers. As shown in the Results section, this scheme significantly assists in achieving classification accuracies close to the baseline ANN accuracy since after the initial layers, the maximum neuron activations decay to values close to unity because of the identity mapping.
7. Experiments
7.1. Datasets and Implementation
We evaluate our proposals on standard visual object recognition benchmarks, namely the CIFAR-10 and ImageNet datasets. Experiments performed on networks for the CIFAR-10 dataset are trained on the training set images with per-pixel mean subtracted and evaluated on the testing set. We also present results on the much more complex ImageNet 2012 dataset that contains 1.28 million training images and report evaluation (top-1 and top-5 error rates) on the 50,000 validation set. 224 × 224 crops from the input images are used for this experiment.
We use VGG-16 architecture (Simonyan and Zisserman, 2014) for both the datasets. ResNet-20 configuration outlined in He et al. (2016a) is used for the CIFAR-10 dataset while ResNet-34 is used for experiments on the ImageNet dataset. As mentioned previously, we do not utilize any batch-normalization layers. For VGG networks, a dropout layer is used after every ReLU layer except for those layers which are followed by a pooling layer. For Residual networks, we use dropout only for the ReLUs at the non-identity parallel paths but not at the junction layers. We found this crucial for achieving training convergence. Note that we have tested our framework only for the above mentioned architectures and datasets. There is no selection bias in the reported results.
Our implementation is derived from the Facebook ResNet implementation code for CIFAR and ImageNet datasets available publicly1. We use same image pre-processing steps and scale and aspect-ratio augmentation techniques as used in2 (for instance, random crop, horizontal flip and color normalization transforms for the CIFAR-10 dataset). We report single-crop testing results while the error rates can be further reduced with 10-crop testing (Krizhevsky et al., 2012). Networks used for the CIFAR-10 dataset are trained on 2 GPUs with a batchsize of 256 for 200 epochs, while ImageNet training is performed on 8 GPUs for 100 epochs with a similar batchsize. The initial learning rate is 0.05. The learning rate is divided by 10 twice, at 81 and 122 epochs for CIFAR-10 dataset and at 30 and 60 epochs for ImageNet dataset. A weight decay of 0.0001 and a momentum of 0.9 is used for all the experiments. Proper weight initialization is crucial to achieve convergence in such deep networks without batch-normalization. For a non-residual convolutional layer (for both VGG and ResNet architectures) having kernel size k × k with n output channels, the weights are initialized from a normal distribution and standard deviation . However, for residual convolutional layers, the standard deviation used for the normal distribution was . We observed this to be important for achieving training convergence and a similar observation was also outlined in Hardt and Ma (2016) although their networks were trained without both dropout and batch-normalization.
7.2. Experiments for VGG Architectures
Our VGG-16 model architecture follows the implementation outlined in3 except that we do not utilize the batch-normalization layers. We used a randomly chosen mini-batch of size 256 from the training set for the weight-normalization process on the CIFAR-10 dataset. While the entire training set can be used for the weight-normalization process, using a representative subset did not impact the results. We confirmed this by running multiple independent runs for both the CIFAR and ImageNet datasets. The standard deviation of the final classification error rate after 2,500 time-steps was ~ 0.01%. All results reported in this section represent the average of 5 independent runs of the spiking network (since the input to the network is a random process). No notable difference in the classification error rate was observed at the end of 2, 500 time-steps and the network outputs converged to deterministic values despite being driven by stochastic inputs. For the SNN model based weight-normalization scheme (SPIKE-NORM algorithm) we used 2,500 time-steps for each layer sequentially to normalize the weights.
Table 1 summarizes our results for the CIFAR-10 dataset. The baseline ANN error rate on the testing set was 8.3%. Since the main contribution of this work is to minimize the loss in accuracy during conversion from ANN to SNN for deep-layered networks and not in pushing state-of-the-art results in ANN training, we did not perform any hyper-parameter optimization. However, note that despite several architectural constraints being present in our ANN architecture, we are able to train deep networks that provide competitive classification accuracies using the training mechanisms described in the previous subsection. Further reduction in the baseline ANN error rate is possible by appropriately tuning the learning parameters. For the VGG-16 architecture, our implementation of the ANN-model based weight-normalization technique, proposed by Diehl et al. (2015), yielded an average SNN error rate of 8.54% leading to an error increment of 0.24%. The error increment was minimized to 0.15% on applying our proposed SPIKE-NORM algorithm. Note that we consider a strict model-based weight-normalization scheme to isolate the impact of considering the effect of an ANN vs. our SNN model for threshold-balancing. Further optimizations of considering the maximum synaptic weight during the weight-normalization process (Diehl et al., 2015) is still possible.
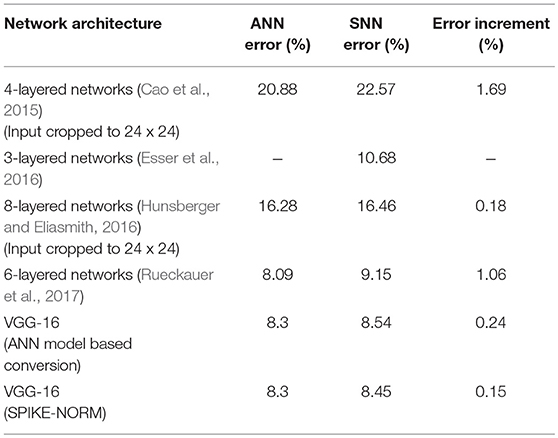
Table 1. Results for CIFAR-10 dataset.
Previous works have mainly focused on much shallower convolutional neural network architectures. Although Hunsberger and Eliasmith (2016) reports results with an accuracy loss of 0.18%, their baseline ANN suffers from some amount of accuracy degradation since their networks are trained with noise (in addition to architectural constraints mentioned before) to account for neuronal response variability due to incoming spike trains (Hunsberger and Eliasmith, 2016). It is also unclear whether the training mechanism with noise would scale up to deeper layered networks. Our work reports the best performance of a Spiking Neural Network on the CIFAR-10 dataset till date.
The impact of our proposed algorithm is much more apparent on the more complex ImageNet dataset. The rates for the top-1 (top-5) error on the ImageNet validation set are summarized in Table 2. Note that these are single-crop results. The accuracy loss during the ANN-SNN conversion process is minimized by a margin of 0.57% by considering SNN-model based weight-normalization scheme. It is therefore expected that our proposed SPIKE-NORM algorithm would significantly perform better than an ANN-model based conversion scheme as the pattern recognition problem becomes more complex since it accounts for the actual SNN operation during the conversion process. Note that Hunsberger and Eliasmith (2016) reports a performance of 48.2%(23.8%) on the first 3072-image test batch of the ImageNet 2012 dataset.
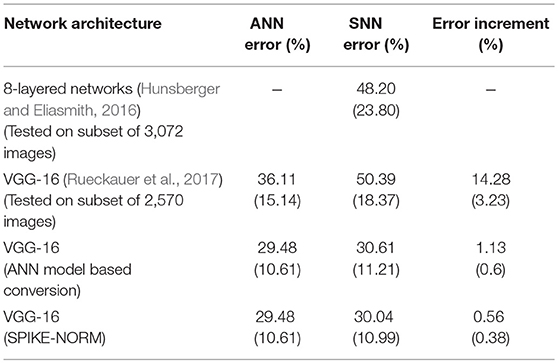
Table 2. Results for ImageNet dataset.
At the time we developed this work, we were unaware of a parallel effort to scale up the performance of SNNs to deeper networks and large-scale machine learning tasks. The work was recently published in Rueckauer et al. (2017). However, their work differs from our approach in the following aspects: (i) Their work improves on prior approach outlined in Diehl et al. (2015) by proposing conversion methods for removing the constraints involved in ANN training (discussed in section 4.3). We are improving on prior art by scaling up the methodology outlined in Diehl et al. (2015) for ANN-SNN conversion by including the constraints. (ii) We are demonstrating that considering SNN operation in the conversion process helps to minimize the conversion loss. Rueckauer et al. (2017) uses ANN based normalization scheme used in Diehl et al. (2015). While removing the constraints in ANN training allows authors in Rueckauer et al. (2017) to train ANNs with better accuracy, they suffer significant accuracy loss in the conversion process. This occurs due to a non-optimal ratio of biases/batch-normalization factors and weights Rueckauer et al. (2017). This is the primary reason for our exploration of ANN-SNN conversion without bias and batch-normalization. For instance, their best performing network on CIFAR-10 dataset incurs a conversion loss of 1.06% in contrast to 0.15% reported by our proposal for a much deeper network. The accuracy loss is much larger for their VGG-16 network on the ImageNet dataset—14.28% in contrast to 0.56% for our proposal. Although Rueckauer et al. (2017) reports a top-1 SNN error rate of 25.40% for an Inception-V3 network, their ANN is trained with an error rate of 23.88%. The resulting conversion loss is 1.52% and much higher than our proposals. The Inception-V3 network conversion was also optimized by a voltage clamping method, that was found to be specific for the Inception network and did not apply to the VGG network Rueckauer et al. (2017). Note that the results reported on ImageNet in Rueckauer et al. (2017) are on a subset of 1, 382 image samples for Inception-V3 network and 2,570 samples for VGG-16 network. Hence, the performance on the entire dataset is unclear. Our contribution lies in the fact that we are demonstrating ANNs can be trained with the above-mentioned constraints with competitive accuracies on large-scale tasks and converted to SNNs in a near-lossless manner.
This is the first work that reports competitive performance of a Spiking Neural Network on the entire 50,000 ImageNet 2012 validation set.
7.3. Experiments for Residual Architectures
Our residual networks for CIFAR-10 and ImageNet datasets follow the implementation in He et al. (2016a). We first attempt to explain our design choices for ResNets by sequentially imposing each constraint on the network and showing their corresponding impact on network performance in Figure 3. The “Basic Architecture” involves a residual network without any junction ReLUs. “Constraint 1” involves junction ReLUs without having equal spiking thresholds for all fan-in neural layers. “Constraint 2” imposes an equal threshold of unity for all the layers while “Constraint 3” performs best with two pre-processing plain convolutional layers (3 × 3) at the beginning of the network. The baseline ANN ResNet-20 was trained with an error of 10.9% on the CIFAR-10 dataset. Note that although we are using terminology consistent with He et al. (2016a) for the network architectures, our ResNets contain two extra plain pre-processing layers. The converted SNN according to our proposal yielded a classification error rate of 12.54%. Weight-normalizing the initial two layers using the ANN-model based weight-normalization scheme produced an average error of 12.87%, further validating the efficiency of our weight-normalization technique.
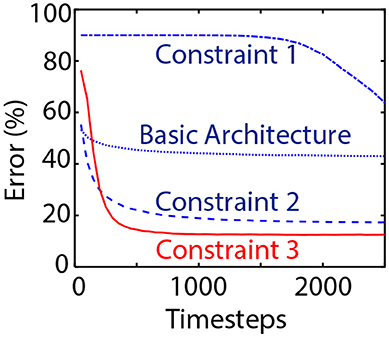
Figure 3. Impact of the architectural constraints for Residual Networks. “Basic Architecture” does not involve any junction ReLU layers. “Constraint 1” involves junction ReLUs while “Constraint 2” imposes equal unity threshold for all residual units. Network accuracy is significantly improved with the inclusion of “Constraint 3” that involves pre-processing weight-normalized plain convolutional layers at the network input stage.
On the ImageNet dataset, we use the deeper ResNet-34 model outlined in He et al. (2016a). The initial 7 × 7 convolutional layer is replaced by three 3 × 3 convolutional layers where the initial two layers are non-residual plain units. The baseline ANN is trained with an error of 29.31% while the converted SNN error is 34.53% at the end of 2,500 timesteps. The results are summarized in Table 3 and convergence plots for all our networks are provided in Figure 4. It is worth noting here that the main motivation of exploring Residual Networks is to go deeper in Spiking Neural Networks. We explore relatively simple ResNet architectures, as the ones used in He et al. (2016a), which have an order of magnitude fewer parameters than standard VGG-architectures. Further hyper-parameter optimizations or more complex architectures are still possible. While the accuracy loss in the ANN-SNN conversion process is more for ResNets than plain convolutional architectures, yet further optimizations like including more pre-processing initial layers or better threshold-balancing schemes for the residual units can still be explored. This work serves as the first work to explore ANN-SNN conversion schemes for Residual Networks and attempts to highlight important design constraints required for minimal loss in the conversion process.
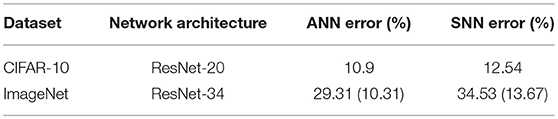
Table 3. Results for residual networks.
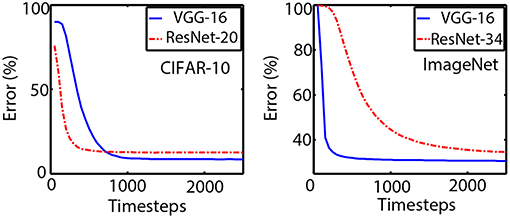
Figure 4. Convergence plots for the VGG and ResNet SNN architectures for CIFAR-10 and ImageNet datasets are shown above. The classification error reduces as more evidence is integrated in the Spiking Neurons with increasing time-steps. Note that although the network depths are similar for CIFAR-10 dataset, the ResNet-20 converges much faster than the VGG architecture. The delay for inferencing is higher for ResNet-34 on the ImageNet dataset due to twice the number of layers as the VGG network.
7.4. Computation Reduction Due to Sparse Neural Events
ANN operation for prediction of the output class of a particular input requires a single feed-forward pass per image. For SNN operation, the network has to be evaluated over a number of time-steps. However, specialized hardware that accounts for the event-driven neural operation and “computes only when required” can potentially exploit such alternative mechanisms of network operation. For instance, Figure 5 represents the average total number of output spikes produced by neurons in VGG and ResNet architectures as a function of the layer for ImageNet dataset. A randomly chosen minibatch was used for the averaging process. We used 500 timesteps for accumulating the spike-counts for VGG networks while 2,000 time-steps were used for ResNet architectures. This is in accordance to the convergence plots shown in Figure 4. An important insight obtained from Figure 5 is the fact that neuron spiking activity becomes sparser as the network depth increases. Hence, benefits from event-driven hardware is expected to increase as the network depth increases. While an estimate of the actual energy consumption reduction for SNN mode of operation is outside the scope of this current work, we provide an intuitive insight by providing the number of computations per synaptic operation being performed in the ANN vs. the SNN.
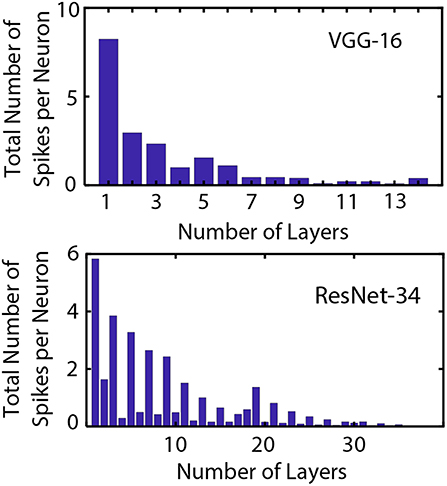
Figure 5. Average cumulative spike count generated by neurons in VGG and ResNet architectures on the ImageNet dataset as a function of the layer number. Five hundred timesteps were used for accumulating the spike-counts for VGG networks while 2,000 time-steps were used for ResNet architectures. The neural spiking sparsity increases significantly as network depth increases.
The number of synaptic operations per layer of the network can be easily estimated for an ANN from the architecture for the convolutional and linear layers. For the ANN, a multiply-accumulate (MAC) computation takes place per synaptic operation. On the other hand, a specialized SNN hardware would perform an accumulate computation (AC) per synaptic operation only upon the receipt of an incoming spike. Hence, the total number of AC operations occurring in the SNN would be represented by the dot-product of the average cumulative neural spike count for a particular layer and the corresponding number of synaptic operations. Calculation of this metric reveal that for the VGG network, the ratio of SNN AC operations to ANN MAC operations is 1.975 while the ratio is 2.4 for the ResNet (the metric includes only ReLU/IF spiking neuron activations in the network). However, note the fact that a MAC operation involves an order of magnitude more energy consumption than an AC operation Han et al. (2015b). Hence, the energy consumption reduction for our SNN implementation is expected to be significantly lower in comparison to the original ANN implementation. It is worth noting here that the real metric governing the energy requirement of SNN vs. ANN is the number of spikes per neuron. Energy benefits are obtained only when the average number of spikes per neuron over the inference timing window is <1 (since in the SNN the synaptic operation is conditional based on spike generation by neurons in the previous layer). Hence, to get benefits for energy reductions in SNNs, one should target deeper networks due to neuron spiking sparsity.
While the SNN operation requires a number of time-steps in contrast to a single feed-forward pass for an ANN, the actual time required to implement a single time-step of the SNN in a neuromorphic architecture might be significantly lower than a feedforward pass for an ANN implementation (due to event-driven hardware operation). An exact estimate of the delay comparison is outside the scope of this article. Nevertheless, despite the delay overhead, as highlighted above, the power benefits of event-driven SNNs can significantly increase the energy (power x delay) efficiency of deep SNNs in contrast to ANNs.
8. Conclusions and Future Work
This work serves to provide evidence for the fact that SNNs exhibit similar computing power as their ANN counterparts. This can potentially pave the way for the usage of SNNs in large scale visual recognition tasks, which can be enabled by low-power neuromorphic hardware. However, there are still open areas of exploration for improving SNN performance. A significant contribution to the present success of deep NNs is attributed to Batch-Normalization (Ioffe and Szegedy, 2015). While using bias less neural units constrain us to train networks without Batch-Normalization, algorithmic techniques to implement Spiking Neurons with a bias term should be explored. Further, it is desirable to train ANNs and convert to SNNs without any accuracy loss. Although the proposed conversion technique attempts to minimize the conversion loss to a large extent, yet other variants of neural functionalities apart from ReLU-IF Spiking Neurons could be potentially explored to further reduce this gap. Additionally, further optimizations to minimize the accuracy loss in ANN-SNN conversion for ResNet architectures should be explored to scale SNN performance to even deeper architectures.
Author Contributions
AS developed the main concepts, performed the simulations, and wrote the paper. All authors assisted in the writing of the paper and developing the concepts.
Conflict of Interest Statement
AS was employed by Facebook through a summer internship. YY, RW, and CL were employed by company Facebook.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
References
Akopyan, F., Sawada, J., Cassidy, A., Alvarez-Icaza, R., Arthur, J., Merolla, P., et al. (2015). TrueNorth: design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip. IEEE Trans. Comp. Aided Design Integr. Circ. Syst. 34, 1537–1557. doi: 10.1109/TCAD.2015.2474396
Cao, Y., Chen, Y., and Khosla, D. (2015). Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comp. Vision 113, 54–66. doi: 10.1007/s11263-014-0788-3
Chen, Z., Johnson, M., Wei, L., and Roy, W. (1998). “Estimation of standby leakage power in CMOS circuit considering accurate modeling of transistor stacks,” in Proceedings, International Symposium on Low Power Electronics and Design, 1998 (Monterey, CA: IEEE), 239–244.
Diehl, P. U., and Cook, M. (2015). Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 9:99. doi: 10.3389/fncom.2015.00099
Diehl, P. U., Neil, D., Binas, J., Cook, M., Liu, S.-C., and Pfeiffer, M. (2015). “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney: IEEE), 1–8.
Esser, S. K., Merolla, P. A., Arthur, J. V., Cassidy, A. S., Appuswamy, R., Andreopoulos, A., et al. (2016). Convolutional networks for fast, energy-efficient neuromorphic computing. Proc. Natl. Acad. Sci. U.S.A. 113, 11441–11446. doi: 10.1073/pnas.1604850113
Farabet, C., Paz, R., Pérez-Carrasco, J., Zamarreño-Ramos, C., Linares-Barranco, A., LeCun, Y., et al. (2012). Comparison between frame-constrained fix-pixel-value and frame-free spiking-dynamic-pixel ConvNets for visual processing. Front. Neurosci. 6:32. doi: 10.3389/fnins.2012.00032
Han, S., Mao, H., and Dally, W. J. (2015a). Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
Han, S., Pool, J., Tran, J., and Dally, W. (2015b). “Learning both weights and connections for efficient neural network,” in Advances in Neural Information Processing Systems (Montreal, QC), 1135–1143.
He, K., Zhang, X., Ren, S., and Sun, J. (2016a). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV), 770–778.
He, K., Zhang, X., Ren, S., and Sun, J. (2016b). “Identity mappings in deep residual networks,” in European Conference on Computer Vision (Springer), 630–645.
Hunsberger, E., and Eliasmith, C. (2016). Training spiking deep networks for neuromorphic hardware. arXiv preprint arXiv:1611.05141.
Ioffe, S., and Szegedy, C. (2015). “Batch normalization: accelerating deep network training by reducing internal covariate shift,” in International Conference on Machine Learning (Lille), 448–456.
Izhikevich, E. M. (2003). Simple model of spiking neurons. IEEE Trans. Neural Netw. 14, 1569–1572. doi: 10.1109/TNN.2003.820440
Krizhevsky, A., and Hinton, G. (2009). Learning multiple layers of features from tiny images. Available online at: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). “ImageNet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems (Lake Tahoe, NV), 1097–1105.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceed. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Merolla, P. A., Arthur, J. V., Alvarez-Icaza, R., Cassidy, A. S., Sawada, J., Akopyan, F., et al. (2014). A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 345, 668–673. doi: 10.1126/science.1254642
Pérez-Carrasco, J. A., Zhao, B., Serrano, C., Acha, B., Serrano-Gotarredona, T., Chen, S., et al. (2013). Mapping from frame-driven to frame-free event-driven vision systems by low-Rate rate coding and coincidence processing–application to feedforward convNets. IEEE Trans. Pattern Anal. Mach. Intelligence 35, 2706–2719. doi: 10.1109/TPAMI.2013.71
Posch, C., Matolin, D., and Wohlgenannt, R. (2011). A QVGA 143 dB dynamic range frame-free PWM image sensor with lossless pixel-level video compression and time-domain CDS. IEEE J. Solid-State Circ. 46, 259–275. doi: 10.1109/JSSC.2010.2085952
Posch, C., Serrano-Gotarredona, T., Linares-Barranco, B., and Delbruck, T. (2014). Retinomorphic event-based vision sensors: bioinspired cameras with spiking output. Proc. IEEE 102, 1470–1484. doi: 10.1109/JPROC.2014.2346153
Rueckauer, B., Hu, Y., Lungu, I.-A., Pfeiffer, M., and Liu, S.-C. (2017). Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 11:682. doi: 10.3389/fnins.2017.00682
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet large scale visual recognition challenge. Int. J. Comp. Visi. 115, 211–252. doi: 10.1007/s11263-015-0816-y
Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
Srivastava, N., Hinton, G. E., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958. Available online at: http://dl.acm.org/citation.cfm?id=2627435.2670313
Keywords: spiking neural networks, event-driven neural networks, sparsity, neuromorphic computing, visual recognition
Citation: Sengupta A, Ye Y, Wang R, Liu C and Roy K (2019) Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 13:95. doi: 10.3389/fnins.2019.00095
Received: 14 September 2018; Accepted: 25 January 2019;
Published: 07 March 2019.
Edited by:
Mark D. McDonnell, University of South Australia, AustraliaReviewed by:
Sacha Jennifer van Albada, Forschungszentrum Jülich, GermanySadique Sheik, AiCTX AG, Switzerland
Copyright © 2019 Sengupta, Ye, Wang, Liu and Roy. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Abhronil Sengupta, YXNlbmd1cEBwdXJkdWUuZWR1