 Chaoyu Yang
Chaoyu Yang Jie Yang2†
Jie Yang2†- 1School of Economics and Management, Anhui University of Science and Technology, Huainan, China
- 2Faculty of Engineering and Information Sciences, School of Computing and Information Technology, University of Wollongong, Wollongong, NSW, Australia
- 3School of Mathematics and Physics, Anhui University of Science and Technology, Huainan, China
The problem of cancer risk analysis is of great importance to health-service providers and medical researchers. In this study, we propose a novel Artificial Neural Network (ANN) algorithm based on the probabilistic framework, which aims to investigate patient patterns associated with their disease development. Compared to the traditional ANN where input features are directly extracted from raw data, the proposed probabilistic ANN manipulates original inputs according to their probability distribution. More precisely, the Naïve Bayes and Markov chain models are used to approximate the posterior distribution of the raw inputs, which provides a useful estimation of subsequent disease development. Later, this distribution information is further leveraged as additional input to train ANN. Additionally, to reduce the training cost and to boost the generalization capability, a sparse training strategy is also introduced. Experimentally, one of the largest cancer-related datasets is employed in this study. Compared to state-of-the-art methods, the proposed algorithm achieves a much better outcome, in terms of the prediction accuracy of subsequent disease development. The result also reveals the potential impact of patients' disease sequence on their future risk management.
1. Introduction
Cancer is a complex health problem worldwide, which is closely monitored by scientists and authorities due to its high mortality rate. In the past decades, the pressure of cancer in public health sectors has gradually increased. A lot of effort has been put into cancer-related studies (Loud and Murphy, 2017), such as patient status monitoring, medical resource allocation, and survivability prediction, to name a few. According to the GLOBOCAN project (Sasikala et al., 2019), there will be more than 14.1 million new cancer-related cases (excluding skin cancer and melanoma) annually, accounting for ~14.6% of global deaths. Even within developed countries, such as the United States, there are more than 1.68 million new patients and 600,000 deaths per year. In particular, Table 1 shows the top eight cancer types from the United States in 2016, while the number of new cases and relevant deaths are also illustrated. For instance, there are about 150,000 new cases diagnosed with breast cancer and around 41,000 deaths, which contribute to a 16.4% ratio between new cases and death numbers. On the other hand, there are ~24,000 new patients and 16,000 deaths related to brain and nervous system cancers, which leads to a significantly high ratio of 67.5%.
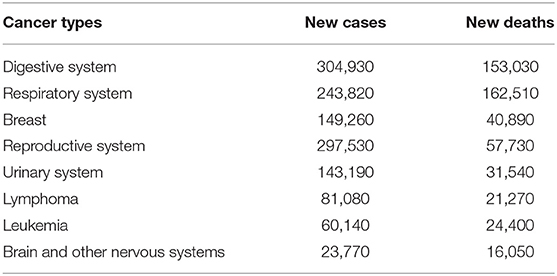
Table 1. Number of new cancer-related patients and deaths from the United States in 2016.
As such, the problem of how to monitor and predict cancer-disease development (to reduce its incidence rate) has attracted a lot of attention from different public and private sectors, and has become a major challenge and research focus. The last two decades have witnessed a huge development of computer science and information technologies, which have already taken on an important role in the cancer-related domain. In particular, data mining and machine learning approaches are more regularly employed due to their high performance in simulation and modeling. For example, the work in Heidari et al. (2018) proposed a machine learning based model to identify mammographic image features for short-term breast cancer prediction. Locally preserving projection (LPP) based features were considered, and the experiment was performed using a mammographic dataset collected from 500 women. The result further showed a huge improvement from their work compared to standard methods, such as the Liner Regression and Decision Tree methods. Additionally, a comparison between the Naïve Bayes and K-Nearest Neighbor (KNN) algorithms was provided in Amrane et al. (2018) for breast cancer classification. The experiment was performed using the Wisconsin dataset, while the result showed that KNN outperforms Naïve Bayes with the higher accuracy of 97.51% compared to that of 96.19%. Another breast cancer prediction work has been reported in Jamal et al. (2018), in which authors utilized the hybrid technique of Extreme Gradient Boosting technique and Support Vector Machine. Furthermore, they also applied the Principle Component Analysis (PCA) and K-Means Clustering method to reduce the problem dimensionality. Experimental results illustrated that the hybrid algorithm with a reduced-scale problem indeed improved the prediction performance of diagnosing breast cancer.
However, the majority of the existing research did not address the sequential nature of the disease's development. In other words, less work has been performed to explore the relationship between patients' previous disease and sequential ones. As a result, in this study our research aims to provide new insight into how disease development can be influenced or predicted based on patients' previous medical information. In particular, the Artificial Neural Network (ANN) algorithm is investigated as the optimization tool in our study. ANN is one of the most widely-used techniques for simulation and modeling, due to its ability to learn from complex inputs and to produce accurate outputs. Not surprisingly, we have observed a great number of ANN-based applications in the medical domain. For example, the work from Fakoor et al. (2013) developed a hybrid method by combining ANN with the Support Vector Machine and it was tested on several gene-expression datasets for cancer detection. The results revealed that the ANN-based work outperformed traditional methods via discovering intricate relationships behind risk factors. More recently, a convolutional neural network improvement for breast cancer classification was proposed in Ting et al. (2019). To classify incoming medical images into malignant, benign, and healthy patients, their work performed effectively to localize and identify breast cancer tissue. Other successful implementations of ANN-based models can be found in the survey of Siddiqui et al. (2020).
Despite the general interest in developing the ANN applications, several drawbacks still exist. Specifically, in the context of the disease development, we aim to explore the disease correlation and to identify related risk factors. The majority of traditional ANN applications, however, consider network inputs from the original data directly, while less work has been offered in terms of the input amendment or augment. On the other hand, the standard network training process is usually time consuming, in particular with a large number of inputs. Additionally, as for some real-world scenarios, the generalization performance of the standard ANN is far from being satisfactory.
To this end, in this study we propose a novel hybrid algorithm, based on the idea of Artificial Neural Network, Naïve Bayes, and Markov chain, to address the issue of predicting patients' disease development. In the proposed study, the methods of Naïve Bayes and Markov chain are first applied to estimate posterior possibilities of subsequent development, according to the patient's historical data. The estimation of subsequent possibility is able to establish a relationship model via capturing the underlying correlation of the disease development. Next, estimated possibilities are further leveraged as the input to the neural network, in addition to original inputs. Lastly, we also consider adopting a sparse training strategy for the network training, which is able to optimize the network structure and minimize the training error simultaneously. To the best of our knowledge, this is the first investigation combining the models of Bayesian Network and Markov chain to amend the input of the Artificial Neural Network. The proposed algorithm is further applied to one of the largest cancer-related datasets worldwide, and the comparison with state-of-the-art approaches is also considered.
The rest of this paper is organized as follows. Section 2 provides a review of literature in which several existing research topics are examined, including applications of data-mining techniques on the domain of cancer risk analysis, Artificial Neural Network, Naïve Bayes and Markov chain model. Section 3 provides the basic information about the research background, such as the description of the target dataset used in this study. Section 4 describes the proposed hybrid approach, including the input augment and sparse training. Then, section 5 discusses experiments and comparison results, and finally section 6 concludes the study.
2. Literature Review
In this section, we will provide a brief review about existing cancer-related research. Then the fundamental work of Artificial Neural Network, Naïve Bayes and Markov chain model is also provided.
2.1. Cancer Risk Analysis
Cancer risk analysis is of great significance to healthcare providers and medical researchers. Several research works have attempted to provide a diverse range of the management and/or prediction strategies for cancer risk analysis. The ultimate goal is to provide precaution for people with a risk, as well as to monitor the disease development (or survivability prediction).
For the risk prediction, the work from Hart et al. (2018) employed a multi-parameterized neural network for lung cancer risk prediction, based on putative risk factors as well as clinical and demographic information. A comparison among Decision Tree, Support Vector Machine, Naïve Bayes, and K-Nearest Neighbors was conducted for a liver-cancer assessment. On the other hand, cancer survivability prediction is also an interesting topic that has been fervently researched throughout the years. The prediction task of cancer survivability is to monitor the possible survivability (the time span) based on the patient's status. For instance, Mayur et al. conducted a study on spinal cord cancer survivability by performing statistical analyses and fitting a Random Forest model (Mayur et al., 2019). The work from Wang et al. (2019) investigated the use of a tree ensemble-based two-stage regression model for advanced-stage lung cancer survival prediction. In addition, a comparison among multiple techniques, including Linear Regression, Decision Tree, Random Forest and Generalized Boosting Machines, and Support Vector Machine, was considered in Sharaf et al. (2015) to predict lung-cancer patient survival.
Despite the great interest in the work of cancer risk and survivability analysis, little research has been done in terms of the relationship between patients' past and current diagnoses. In other words, existing studies fail to address the possibility of subsequent diagnosis, given patients' previous medical conditions. Yet, this research question is of great importance, as it helps in providing prior knowledge of patients' future disease development. To gain an in-depth understanding of potential risk for subsequent diseases also works in increasing the healthcare quality and treatment services (Gupta et al., 2012; Aolin and Maxim, 2017). To bridge this gap, we propose a probabilistic model that takes into account the techniques of the Artificial Neural Network, Naïve Bayes, and Markov chain model.
2.2. Artificial Neural Network
The Artificial Neural Network (ANN) is one of the most popular data-mining algorithms, which is capable of responding to complex inputs and generating desired outputs. Due to its satisfactory performance and high accuracy, ANN has found its wide applications in numerous areas, such as pattern recognition, prediction, and statistical simulation, and so on. The most basic computing unit from ANN is the artificial neuron. Those neurons are designed in a similar way to biological neurons within the human brain. In general, input signals are transferred to biological neurons, and then inputs are further processed within their cell bodies. If a certain threshold is reached, neurons are activated to transfer output signals to other neurons. Accordingly, the artificial neuron follows the same procedure of biological neurons: input receiving, threshold activation, and output transferring. Mathematically, suppose the input signal to the i-th neuron is a vector of xi, the connection strength to the output is the weight wi, and its bias input is represented as b. Given the activation function f(·), the output for this i-th neuron can be expressed as follows:
In real-world applications, the selection of activation function and network structure (the number of hidden layers and/or neurons) is problematic. In general, there is no commonly-accepted formula giving clear insight into how to choose the activation function and/or to determine the network structure. This is usually decided by trial-and-error experiments or cross validation methods. Additionally, after deciding the activation function and network structure, a training process is required to update the internal network weights to minimize the error between the actual network and desired output. Some typical learning algorithms are Back Propagation, Resilient Propagation, and so on.
2.3. Naïve Bayes and Markov Chain
Bayesian theory offers a computational framework for estimating the conditional probability, which has proven to be effective for a wide range of applications. Text classification, spam detection, and sentiment analysis are just a few of their popular use cases. Assume that we have one training sample x and n possible class labels ci (∀i∈n). Then the posterior probability (for x) of belonging to the i-th class [or prob(ci|x)] can be expressed as:
where prob(ci) stands for the class prior probability, prob(x) is the prior probability of x, and prob(x|ci) denotes the posterior probability of x given the condition of the ci class.
Compared with other classification modes, Naïve Bayes (NB) consumes much less training time, and it can effectively solve small-scale learning problems. For instance, Kim et al. (2018) introduced a Naïve Bayes based text classification in a semantic tensor space model for document representation. URL classification is another classification application of Native Bayes, which is currently of research interest (Rajalakshmi and Aravindan, 2018). In addition, evaluation of a hot-engine test (Fan et al., 2018) and classification of impact damage on a rubber-textile conveyor belt (Andrejiova and Grincova, 2018) are just other use cases that have been investigated using the Naïve Bayes method, respectively.
On the other hand, the Markov chain model is usually utilized to calculate the transition probability from one state to another. In particular, the first order Markov chain operates under the assumption that future states for one particular object (or event) only depend on the current state, but not on other states that occurred before. In other words, let xi (i = 1, 2, ⋯ , n) represent a sequence of random variables. Then the probability of moving to the next state (or xn+1) is estimated as:
The Markov chain model proves to be effective in factoring the sequential characteristics of events. Existing applications of the Markov chain model are primarily in the domain of recommendation, speech recognition, and so on. For instance, Ye et al. (2015) and Lassoued et al. (2017) both discussed the use of Markov models in driving route and destination predictions, respectively. Krause and Zhang (2019) proposed a different approach by employing a hierarchical Markov model for short-term behavior prediction. Kurashima et al. (2013) had a slightly different approach when employing not only the Markov Chain model but also a topic model to represent the user interest.
2.4. Summary
In this section, we briefly review some existing research on applying the data-mining techniques in the medical domain. Additionally, we also offer a fundamental discussion on three popular methods, including the Artificial Neural Network, Naïve Bayes, and Markov chain model. Based on these three methods, we will then propose a novel prediction algorithm to monitor and predict patients' disease development, which is discussed in the coming sections.
3. Study Background
The National Cancer Institute (NCI) established the Surveillance, Epidemiology and End Results (SEER) database in 19731. This incidence database consists of de-identified patient data with different types of cancer diseases. Additionally, for each patient record, there are in total 124 features. These features cover both the demographical and clinical information. For example, demographics information include gender, ethnicity, year of birth, month, and year of diagnosis, age, and marital status of patients at diagnosis. Clinical information includes tumor primary site, tumor marker, tumor size, the types of treatment received, behavior codes, laterality, and histology. In addition, the cancer types involved in the database can be divided into nine categories: breast, colon and rectum, other digestive systems, female reproduction, lymphoid and leukemia, male reproduction, respiratory system, urinary system and other unspecified types. By November 2013, there were more than 1 million data records in the SEER database. Currently, it is the authoritative data source that provides reliable data support for clinical research. A huge number of research efforts have been conducted to utilize this database for different work, such as cancer survival prediction, correlation of medical factors, management of diseases recurrence, and etc.
Again, the main purpose of this study is to investigate the possibility of being diagnosed with cancers given a previous medical condition. To model such a disease development, in this study we focus on three types of cancer data from SEER, including lung and bronchus cancer (C1), liver and intrahepatic bile duct cancer (C2), and stomach cancer (C3), respectively. Figure 1 shows the percentage of selected patient samples from three types of cancers.
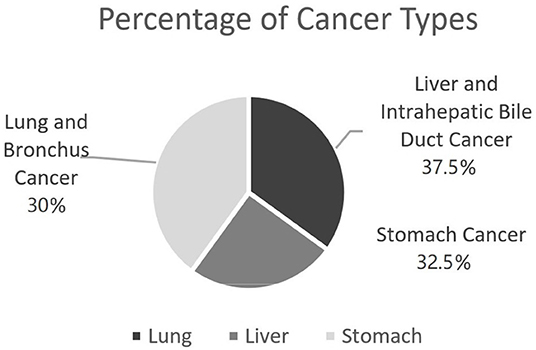
Figure 1. Percentage of selected patients from three cancer types in SEER.
4. Proposed Approach
In this section, we propose a novel prediction algorithm by combining three different methods, including the Bayesian and Markov models, as well as the artificial neural network. Our approach is based on the assumption that the occurrence of a new type of cancer incidence is affiliated with the most recently (or previously) diagnosed cancer incidence, as well as patients' previous clinical details. Toward this end, Naïve Bayesian and Markov chain models are first used to establish the connection between the previous and current incidence, which offers a useful estimation of patient's future status. Then, the output from the two probabilistic models will be cast as the network input for the training process. Additionally, to improve the accuracy and learning efficiency, we further leverage a sparse training strategy for the target network. The pipeline of the proposed algorithm is then illustrated in Figure 2. Next, we will discuss different stages within our proposed algorithm.
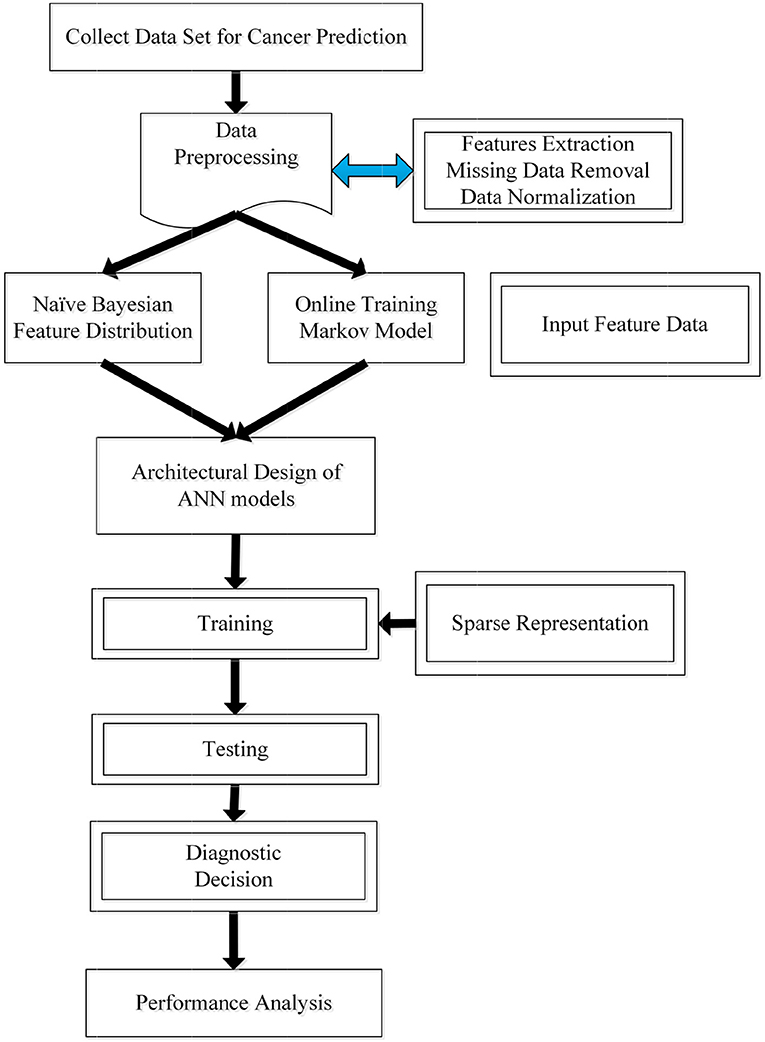
Figure 2. The workflow of the proposed algorithm for predicting patients' disease development.
4.1. Data Pre-processing
To begin with, the first stage is to preprocess the original SEER data to meet certain criteria, such as removal of missing values and data normalization. Among all 124 features, 19 independent features that may have an impact on the cancer prediction tasks were selected, including: gender, race, status, age, primary site, etc. The detail description and value distribution of selected attributes are provided in Table 2.
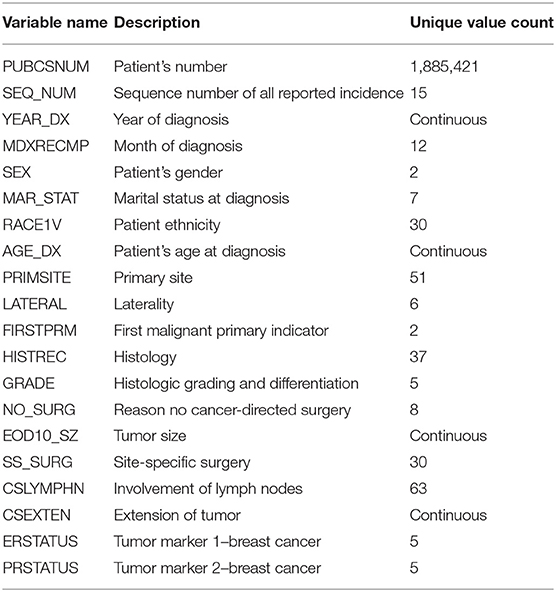
Table 2. Variable descriptions and unique values.
Among these features, four of them, namely SS_SURG, CSLYMPHN, EOD10_SZ, and CSEXTEN, contain massive amounts of missing values, ~50% on average. One plausible reason could be the patients' refusal to provide adequate information. On the other hand, due to the evolution of SEER over time, some clinical features have only been collected in recent years. This makes it very impractical to backtrack those new features from previous records. For simplicity, patients' records with missing values will be removed in this study. That is, only completed data samples will be considered.
Next, we find that selected attributes can be divided into discrete and continuous attributes. For discrete attributes, it is easy to process compared to continuous ones. For example, the marital status attribute is divided into seven categories, while the gender one is cast into two categories. By contrast, for continuous data, the minimum-maximum normalization is employed in a way that the values from continuous features will be limited within the range of [0, 1]. Mathematically, let be the value from the p-th sample and the j-th continuous feature, min(vj) and max(vj) is the minimal and maximal value of this j-th feature from all samples. Accordingly, the normalized value will be estimated as follows:
4.2. Estimation of Subsequent Disease-Development
In this section, we will discuss the second stage of calculating the possibility of the subsequent disease-development, using the concept of Naïve Bayes and Markov chain model. Suppose we have a set of cancer diagnoses , where is the i-th new type of cancer disease of patient p, and is the jth feature of the i-th new cancer diagnosis of patient p, K is the number of attributes of the set , and τp is the total number of cancer types occurring for patient p. Then the research question can be reformulated as follows: given a patient's most-recent cancer diagnosis and the set of patient health profile information at the time of diagnosis , the task is to predict the next most likely type of cancer to occur for that patient . For example, patient P had been diagnosed with liver cancer before. In this case, we will investigate the following likelihood of patient P having other types of cancers (such as lung or stomach cancer). As a result, mathematically, our goal is to estimate the probability that patient P with the i-th disease Di will also develop the (i + 1)-th disease Di+1, or the probability .
To address the aforementioned problem, we introduce a novel estimation method to calculate the posterior probability based on Naïve Bayes and Markov chain models. More precisely, with Naïve Bayes, we can investigate the dependence of the target variable on a patient's medical condition at the time they are diagnosed with . Let be the attribute list of the p-th patient. Accordingly, in the Bayes theory, we will have:
where K is the number of attributes. Alternatively, we have
The conditional probability can be calculated using the Laplace smoothing while avoiding the zero probability:
On the other hand, we assume that the next disease relies primarily on the precedent disease, as well as the patient's current status. As such, the Markov chain model is accordingly employed to capture the probabilistic information conveyed by the sequence of diseases, that is identified from patients' medical history. In this study, we consider the first-order Markov model, and accordingly we can estimate the probability of the next disease as follows:
Furthermore, the probability of is calculated as follows:
where is the number of patients with a disease Di+1 occurring right after the disease of Di, and similarly is the total number of patients with the disease .
To incorporate both most-recent diagnosis and the patient's health condition into our proposed model, the above Markov and Naïve Bayes models are combined. Operating under the assumption that the patient's health condition set and are independently conditioned on , the combination of the two models can be performed using the following approximation:
where and can be estimated by the Markov and Naïve Bayes models, respectively, and is the normalization factor to ensure all probabilities summed to 1.
4.3. ANN Training
The previous section describes the details about the estimation of subsequent disease development. In the third stage of our proposed algorithm, the output from the previous stage will be cast as the input to feed into a neural network. Figure 3 illustrates the structured input for ANN, while the probability estimation, together with the patient's profile, such as gender and age, are considered as a whole to train the network.
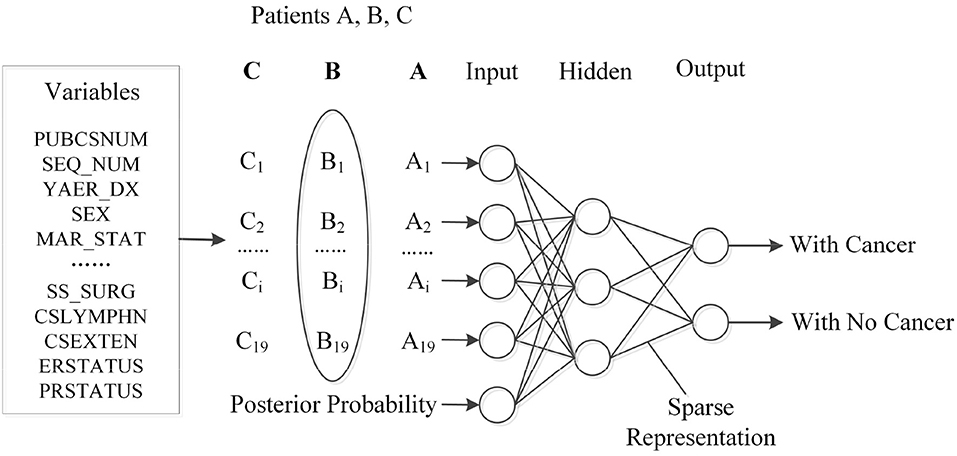
Figure 3. Input structured data for ANN training.
As for the network training process, internal weights will be optimized in a way that the actual network output fits the desired outputs well. Taken as an example, the backpropagation (BP)-based method is a typical way to train ANN via calculating gradients of the output error in relation to network weights. However, the BP-based training could suffer from some drawbacks, such as low convergence and poor generalization capability, in particular with a huge number of input features. In the context of our study, the network has 20 input features, which could be time-consuming for implementing the BP-based training.
To improve the training stability and the fast training speed, we adopt a sparse training strategy in this study, similar to our preliminary work in Yang and Ma (2016, 2019). The general idea is to generate a sparse network structure and to minimize the training error simultaneously. The concept of sparse representation, on the other hand, is under the assumption that a signal can be decomposed into a linear combination of few elementary signals. Consequently, given the target matrix Y ∈ ℝM × L and a known dictionary matrix that contains N columns, the sparse representation aims to minimize the solution sparsity and the reconstruction error:
where is a measure of the matrix sparsity, denotes the reconstruction error, and ϵ is the bound on the error. One simple strategy for estimating is to consider the l2, 1-norm of X, or , where Xq denotes the q-th row of X.
Suppose there are L pairs (xi, yi) of inputs xi and desired outputs yi, while X = [x1, x2, ..., xL] represents the entire input matrix and Y = [y1, y2, ..., yL] is the desired output matrix. Additionally, assume that the target network is with a three-layer structure, which consists of Q-input, N-hidden and M-output neurons, respectively. Let and denote the weight matrices from the hidden and output layer, respectively. As such, the output matrix from the hidden layer (Z) can be expressed as:
where f1(·) is the activation function of the hidden layer, and the i-th column from Z is in relation to the output of the i-th hidden neuron. Furthermore, the actual output from the entire network Ŷ can be written as:
where f2(·) is the activation function for the output layers.
The proposed sparse training is then used to optimize the network structure, by selecting the most-important hidden neurons, while minimizing the output error simultaneously. Therefore, the neuron selection process is equivalent to finding a sparse representation for all hidden neurons. Consequently, the sparse training process is then cast as solving the following problem:
where ||W2||2, 1 is the l2, 1-norm of the W2 matrix, , and ϵ is the bound on the network error. Note that in the proposed sparse training, we only consider optimizing or sparsifying the weight matrix W2 between the hidden and output layer. As for the weight matrix W1 in the previous input-and-hidden layer, we only randomly initialize once during the training and fix them in the subsequent process. The reason is 2-fold: (1) the training performance heavily depends on the output layer, so we focus on the W2 optimization, instead of both layers; (2) W2 is trained or adjusted based on the given W1, as such a random W1 matrix has a minimal impact on the final output.
4.4. Summary
In previous sections, we discuss three different stages from the proposed algorithm. Overall, we apply the Naïve Bayes and Markov chain model to estimate the probability of potential disease development. We then consider this probability result as the additional input, together with other original features, for training a network. At last, to minimize the impact from the huge number of input features, a sparse training strategy is further leveraged to optimize the network structure and minimize the training error simultaneously. Toward this end, Algorithm 1 summarizes the proposed method for investigating the cancer-risk analysis.

Algorithm 1. Proposed algorithm for cancer-risk prediction, based on an improved probabilistic neural network.
5. Experimental Results
This section describes experimental results by applying the proposed algorithm to explore a patient's disease development. The experimental setup and evaluation metrics are presented in section 5.1. In section 5.2, we discuss the probabilities based on their historical information and individual profiles, while the performance of the proposed method is then evaluated in section 5.3.
5.1. Experimental Setup
The target dataset includes 10,500 patients with lung cancer, 13,500 with liver cancer, and 12,000 with stomach cancer, respectively, which is a total of 36,000 samples. Each original sample has 19 features, while the majority of chosen features are categorical (or discrete), except for four attributes, such as the patient's age at diagnosis, year of diagnosis, tumor size, and extension of tumor. Again, continuous features will be normalized as described in section 4.1 during the pre-processing stage. We further applied the 3-fold cross validation method to randomly partition the entire dataset into two independent sets: a training and testing set. The size of the training and testing sets in all cases is 75 and 25%, respectively. The training set is used for training the network while the testing set is for evaluation purposes.
Additionally, for the employed neural network, we consider the activation function of the hidden and output layer as the Sigmoid function, which can be expressed as (z is an arbitrary input). The layer between the input-and-hidden is initialized with random weights in the range [-1, +1]. The number of hidden neurons is set as 64. To solve the optimization problem in Equation (14), the orthogonal matching pursuit (OMP) algorithm is employed2, which first measures the similarity between the residual error and the neuron outputs, and then selects the neuron that minimizes the residual error at each iteration. To halt the OMP solver, the termination criterion is set either when the maximal iteration (K) is reached or when the value of is less than a threshold α, where ϵk is the output error at the k-th iteration, and α is a user-defined value. Lastly, the following metrics are employed to evaluate the performance:
where TP denotes the true positive rate, FN is false negative rate, and FP represents the false positive, respectively.
5.2. Probabilities for Disease Prediction
In this section, we discuss the result of patients' disease probabilities using their previous medical information. As mentioned before, this temporary result, obtained from Naïve Bayes and Markov chain model, will be cast as the input to the subsequent network training. Therefore, an accurate estimation of posterior probabilities will certainly enhance the network performance. Before we discuss the result, the detail of forming the patients' historical information is provided first. Again, we are interested in three types of cancers in this study: lung, liver, and stomach cancer. As such, the entire dataset is grouped by the patient ID. These records are further sorted based on the date of disease diagnosis, while records are indexed from 0, and the maximum number of incidences from a patient is five. Note that some patients could have the problem of recurrence, thereby leading to more than three records. Next, the following procedure is considered:
1. If the patient only has one type of cancer, then her/his record is added directly to the final dataset;
2. If the patient has a recurrence, then records with same type are merged by maintaining only one sample with the latest date of diagnosis.
Through the aforementioned process, redundant patients' records are removed, and the sequence of disease development is accordingly established for the following calculation. Lastly, the estimation result of posterior probabilities, given the patients' previous information, is presented in Table 3.
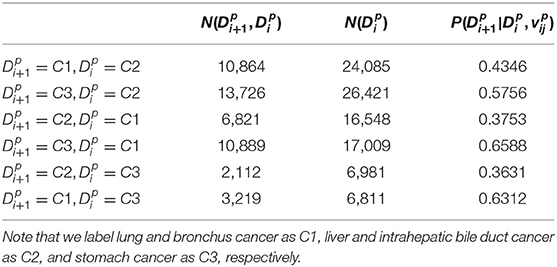
Table 3. Patient's conditional probabilities.
From the results presented in Table 3, there indeed exists some connection between patients' disease development. For instance, we observe that the probabilities from 50% of cases (three out of six) have exceed 57%, which indicates a potential correlation among different diseases. The highest value is found from patients with a type of lung cancer (C1), who have more than a 65% possibility to develop stomach cancer (C3). On the other hand, for patients who had stomach cancer (C3) previously, the chance is much lower (only about 36%) to develop liver cancer (C2). This preliminary result will then be cast as the input for the subsequent network training, while the comparison with other methods is discussed in the next section.
5.3. Comparison With Other Training Algorithms
Note that again in our proposed algorithm, the main contribution is 2-fold: (1) introducing the technique of Naïve Bayes and Markov chain models to estimate the posterior possibilities; (2) employing the sparse training strategy for the network training. As such, the following experiments are designed to evaluate the effectiveness of both the possibility result and the sparse training.
To begin, we consider comparing the performance of the standard ANN, combination model with Bayes and Markov (labeled as CBM), and the proposed models on the training and test set, respectively. Note that in the standard ANN, original features are directly fed into the network, while no additional input is considered. In the CBM method, the estimation for potential disease is considered but no additional neural network is attached. We run the experiments 10 times, and average results are summarized and presented in Tables 4, 5, respectively.
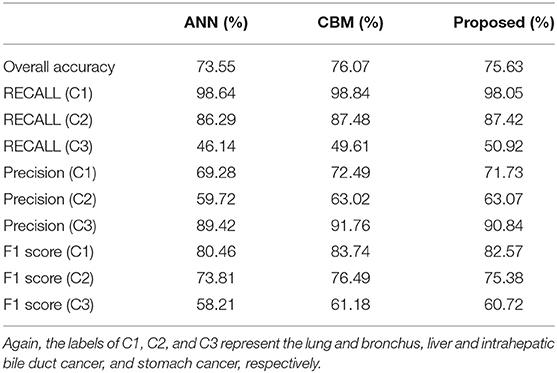
Table 4. Comparison of evaluation metrics from the training dataset.
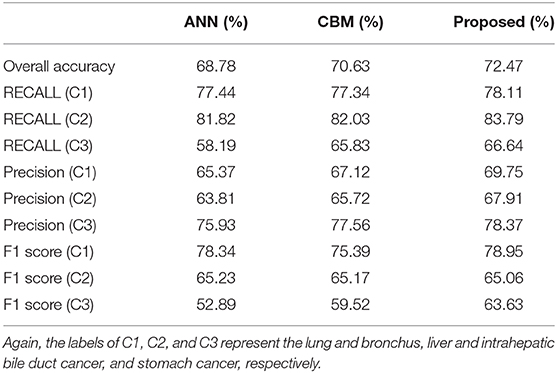
Table 5. Comparison of evaluation metrics from the test dataset.
When it comes to the training performance, we realize that the probability estimation for patients' status indeed helps in boosting the accuracy. For instance, both the CBM and proposed algorithms achieve better training outcome compared to that of the standard ANN method. Again, the major difference among the three methods lie in the input; the results suggest that the additional estimation of patients' status (based on their previous information) is capable of providing useful information that facilitates the subsequent ANN training.
On the other hand, we also observe the best generalization performance of the proposed algorithm from Table 5. The results from the test dataset indicate that the ANN performs the worst, while the CBM method comes second. However, we also notice that the training performance of the proposed algorithm (75.63%) is slightly lower than that of CBM (76.07%) from Table 4. The reason could be the overfitting of CBM to the training data, while the employed sparse neural network helps in improving the testing accuracy while avoiding the overfitting. As a result, the experimental results confirm the advantage of both the additional input from posterior probability and the sparse training in the proposed algorithm.
Next, the performance of our algorithm is compared with conventional methods, and the aim is to evaluate the effectiveness of the proposed method. More precisely, the Support Vector Machine and Random Forest algorithms are included in this paper for comparison purposes:
1. Support Vector Machine (SVM) is one of the most popular kernel-based approaches, which has been demonstrated to perform well in various applications (Sharaf et al., 2015). Usually, the decision boundary formed by SVM is constructed by finding a hyperplane that achieves the maximum separation between classes. In this study, the implemented SVM is with the radial basis function (RBF) kernel, while the penalty parameter C of the error term is set as C = 0.01, and the Kernel coefficient γ is set as γ = 0.1;
2. Random Forest (RF) is one typical ensemble method, which establishes a forest by constructing a collection of element decision trees (Mayur et al., 2019). For each element tree, RF allows them to randomly choose a subset of features from the entire set, which enhances its flexibility and stability. Key hyperparameters within RF include the number of trees in the forest (n_estimators), the maximum depth of a tree (max_depth), and the number of features for splitting (max_features). In this study, we adopt the following: max_depth = 5, n_estimators = 10, and (where n_features is the number of total features).
3. Extreme Learning Machine (ELM) is one typical network training algorithm, which initializes the network weights randomly and then update the weight matrix in the output layer based on a least-square model (Wang et al., 2020). Experiments have shown the advantage of ELM to have easy implementation and better generalization ability, compared to the traditional backpropagation training algorithm. As such, ELM is introduced to make a comparison with the proposed algorithm with a typical three-layer network, while the number of hidden neurons is set as 64.
4. The weighted association rules algorithm (WCBA) aims to generate association rules by combining a new attribute evaluation and prioritization techniques (Alwidian et al., 2018). More precisely, domain knowledge was employed to identify attributes with high significance. Then the statistical harmonic mean (HM) measurement was introduced to prioritize generated rules at the pruning and generation phases. Experimental results show its effectiveness by comparing existing rule-based classification methods.
Note that for SVM, RF, ELM, and WCBA, their inputs are from original data directly, without the additional posterior possibility information. We ran the experiments 10 times to obtain the average performance. As a result, both the training and test classification accuracy from different methods are shown in Figure 4, and the relevant ROC curves are also shown in Figure 5. Although the SVM and RF method have performed better in the training cases, they seem to have problems with overfitting. In particular, the RF method leads to the highest accuracy of 78.93% from training, but with a poor testing accuracy of 55.62%. A similar problem was observed in the SVM method. By contrast, compared to those standard algorithms, the proposed approach achieves a notable improvement in terms of testing accuracy. For instance, our method leads to the best testing result of 72.47%, which is significantly better than the accuracy of SVM (69.70%), RF (55.62%), ELM (65.31%), and WCBA (61.25%), respectively. Overall, it is empirically confirmed that the proposed method outperforms existing training methods by improving the generalization capability.
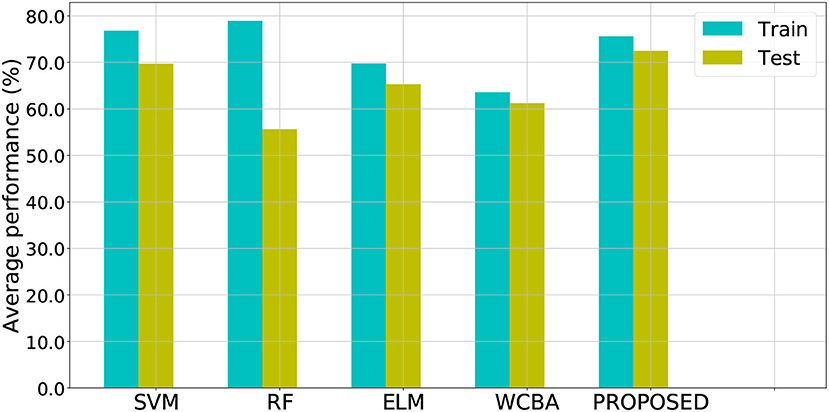
Figure 4. Average training and testing accuracy obtained from different algorithms for prediction.
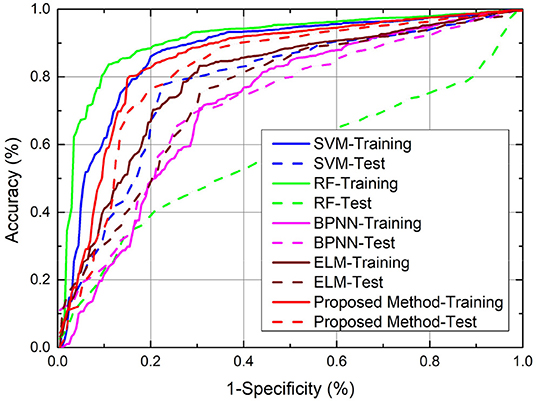
Figure 5. Comparison of classification accuracy (ROC curves) from various methods.
6. Conclusions
Understanding patients' cancer risks, using their historical medical information, is of significant interest in healthcare management. There are still many challenges that remain, including high dimensionality and the heterogeneous structure of data. In this study, a novel algorithm based on the improved probabilistic neural network is proposed, with the ultimate aim of providing decision support for cancer-risk management. The main contribution of our work is 2-fold: (1) we factor the sequential state information with the first-order Markov chain and Naïve Bayes models; this sequential information is then represented as the posterior probability and cast as the additional input for training the neural network; (2) we consider adopting the sparse training strategy to boost the network performance, which is able to optimize the network structure and minimize the training error simultaneously. We test our method using one of the largest cancer-related datasets worldwide. Experimental results suggest that our proposed algorithm exhibits some potential for accurate predictions, compared to other conventional methods. Future work can then apply our method in a broader range of applications, or to develop more sophisticated probability-based neural networks.
Data Availability Statement
The datasets analyzed for this study can be found in the link of https://seer.cancer.gov/.
Author Contributions
CY: conceptualization, methodology, software, validation, investigation, visualization, and writing original draft. JY: software, writing—review and editing, and supervision. YL: software, visualization, and writing—original draft. XG: writing—review and editing, validation, and visualization. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (Grant Nos. 61873004, 51874003), the Humanities and Social Sciences Foundation of Anhui Department of Education, China (Grant No. SK2017A0098).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^Available online at: https://seer.cancer.gov.
2. ^Available online at: https://scikit-learn.org.
References
Alwidian, J., Hammo, B. H., and Obeid, N. (2018). WCBA: weighted classification based on association rules algorithm for breast cancer disease. Appl. Soft Comput. 62, 536–549. doi: 10.1016/j.asoc.2017.11.013
Amrane, M., Oukid, S., Gagaoua, I., and Ensarl, T. (2018). “Breast cancer classification using machine learning,” in 2018 Electric Electronics, Computer Science, Biomedical Engineerings' Meeting (EBBT) (Istanbul: IEEE), 1–4. doi: 10.1109/EBBT.2018.8391453
Andrejiova, M., and Grincova, A. (2018). Classification of impact damage on a rubber-textile conveyor belt using nave-bayes methodology. Wear 414–415, 59–67. doi: 10.1016/j.wear.2018.08.001
Aolin, X., and Maxim, R. (2017). Information-theoretic lower bounds on bayes risk in decentralized estimation. IEEE Trans. Inform. Theory 63, 1580–1600. doi: 10.1109/TIT.2016.2646342
Fakoor, R., Ladhak, F., Nazi, A., and Huber, M. (2013). “Using deep learning to enhance cancer diagnosis and classification,” in The 30th International Conference on Machine Learning (ICML 2013) (Atlanta, GA), 1–7.
Fan, B., Feng, S., Che, Y., Mao, J., and Xie, Y. (2018). An oil monitoring method of wear evaluation for engine hot tests. Int. J. Adv. Manuf. Technol. 94, 3199–3207. doi: 10.1007/s00170-016-9473-8
Gupta, S., Kumar, D., and Sharma, A. (2012). Data mining classification techniques applied for breast cancer diagnosis and prognosis. Indian J. Comput. Sci. Eng. 2, 188–195.
Hart, G. R., Roffman, D. A., Decker, R., and Deng, J. (2018). A multi-parameterized artificial neural network for lung cancer risk prediction. PLoS ONE 13:e205264. doi: 10.1371/journal.pone.0205264
Heidari, M., Khuzani, A. Z., Hollingsworth, A. B., Danala, G., Mirniaharikandehei, S., Qiu, Y., et al. (2018). Prediction of breast cancer risk using a machine learning approach embedded with a locality preserving projection algorithm. Phys. Med. Biol. 63:035020. doi: 10.1088/1361-6560/aaa1ca
Jamal, A., Handayani, A., Septiandri, A. A., Ripmiatin, E., and Effendi, Y. (2018). Dimensionality reduction using pca and k-means clustering for breast cancer prediction. Lontar Komput. 09, 192–201. doi: 10.24843/LKJITI.2018.v09.i03.p08
Kim, H. J., Kim, J., and Lim, P. (2018). Towards perfect text classification with wikipedia-based semantic naïve bayes learning. Neurocomputing 315, 128–134. doi: 10.1016/j.neucom.2018.07.002
Krause, C. M., and Zhang, L. (2019). Short-term travel behavior prediction with gps, land use, and point of interest data. Transport. Res. B Methodol. 123, 349–361. doi: 10.1016/j.trb.2018.06.012
Kurashima, T., Iwata, T., Irie, G., and Fujimura, K. (2013). Travel route recommendation using geotagged photos. Knowl. Inform. Syst. 37, 37–60. doi: 10.1007/s10115-012-0580-z
Lassoued, Y., Monteil, J., Gu, Y., Russo, G., Shorten, R., and Mevissen, M. (2017). “A hidden markov model for route and destination prediction,” in IEEE 20th International Conference on Intelligent Transportation Systems (IEEE) (Yokohama), 1–6. doi: 10.1109/ITSC.2017.8317888
Loud, J., and Murphy, J. (2017). Cancer screening and early detection in the 21st century. Semin. Oncol. Nurs. 33, 121–128. doi: 10.1016/j.soncn.2017.02.002
Mayur, S., Zaid, A., Jared, W. C., Richard, R., and Thomas, A. (2019). Sacroiliac joint fusion system for high-grade spondylolisthesis using ‘reverse Bohlman technique': a technical report and overview of the literature. World Neurosurg. 124, 331–339. doi: 10.1016/j.wneu.2019.01.041
Rajalakshmi, R., and Aravindan, C. (2018). A naïve bayes approach for url classification with supervised feature selection and rejection framework. Comput. Intell. 34, 363–396. doi: 10.1111/coin.12158
Sasikala, S., Bharathi, M., Ezhilarasi, M., Senthil, S., and Reddy, M. (2019). Particle swarm optimization based fusion of ultrasound echographic and elastographic texture features for improved breast cancer detection. Australas. Phys. Eng. Sci. Med. 42, 677–688. doi: 10.1007/s13246-019-00765-2
Sharaf, H., Naveen, Z. Q., Samita, B., and Shakeel, K. (2015). “Reduction of variables for predicting breast cancer survivability using principal component analysis,” in 2015 IEEE 28th International Symposium on Computer-Based Medical Systems (Sao Carlos: IEEE Computer Society), 131–134.
Siddiqui, S., Athar, A., Khan, M., Abbas, S., Saeed, Y., Khan, M., et al. (2020). Modelling, simulation and optimization of diagnosis cardiovascular disease using computational intelligence approaches. J. Med. Imaging Health Inform. 10, 1005–1022. doi: 10.1166/jmihi.2020.2996
Ting, F. F., Tan, Y. J., and Sim, K. S. (2019). Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 120, 103–115. doi: 10.1016/j.eswa.2018.11.008
Wang, P., Song, Q., Li, Y., Lv, S., Wang, J., Li, L., et al. (2020). Cross-task extreme learning machine for breast cancer image classification with deep convolutional features. Biomed. Signal Process. Control 57:101789. doi: 10.1016/j.bspc.2019.101789
Wang, Y., Wang, D., Ye, X., Wang, Y., Yin, Y., and Jin, Y. (2019). A tree ensemble-based two-stage model for advanced-stage colorectal cancer survival prediction. Inform. Sci. 474, 106–124. doi: 10.1016/j.ins.2018.09.046
Yang, J., and Ma, J. (2016). A structure optimization framework for feed-forward neural networks using sparse representation. Knowl. Based Syst. 109, 61–70. doi: 10.1016/j.knosys.2016.06.026
Yang, J., and Ma, J. (2019). Feed-forward neural network training using sparse representation. Expert Syst. Appl. 116, 255–264. doi: 10.1016/j.eswa.2018.08.038
Keywords: cancer risk analysis, artificial neural network, Naïve Bayes, Markov chain, sparse training
Citation: Yang C, Yang J, Liu Y and Geng X (2020) Cancer Risk Analysis Based on Improved Probabilistic Neural Network. Front. Comput. Neurosci. 14:58. doi: 10.3389/fncom.2020.00058
Received: 17 April 2020; Accepted: 22 May 2020;
Published: 21 July 2020.
Edited by:
Jinde Cao, Southeast University, ChinaReviewed by:
Minjie Zhang, Hubei University of Arts and Science, ChinaJun Li, Xi'an University of Science and Technology, China
Yongming Xia, Aalborg University, Denmark
Copyright © 2020 Yang, Yang, Liu and Geng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chaoyu Yang, eWFuZ2NoeSYjeDAwMDQwO2F1c3QuZWR1LmNu
†These authors have contributed equally to this work