 Xiaoliang Qian
Xiaoliang Qian Erkai Li
Erkai Li Jianwei Zhang
Jianwei Zhang- School of Electrical and Information Engineering, Zhengzhou University of Light Industry, Zhengzhou, China
The hardness recognition is of great significance to tactile sensing and robotic control. The hardness recognition methods based on deep learning have demonstrated a good performance, however, a huge amount of manually labeled samples which require lots of time and labor costs are necessary for the training of deep neural networks. In order to alleviate this problem, a semi-supervised generative adversarial network (GAN) which requires less manually labeled samples is proposed in this paper. First of all, a large number of unlabeled samples are made use of through the unsupervised training of GAN, which is used to provide a good initial state to the following model. Afterwards, the manually labeled samples corresponding to each hardness level are individually used to train the GAN, of which the architecture and initial parameter values are inherited from the unsupervised GAN, and augmented by the generator of trained GAN. Finally, the hardness recognition network (HRN), of which the main architecture and initial parameter values are inherited from the discriminator of unsupervised GAN, is pretrained by a large number of augmented labeled samples and fine-tuned by manually labeled samples. The hardness recognition result can be obtained online by importing the tactile data captured by the robotic forearm into the trained HRN. The experimental results demonstrate that the proposed method can significantly save the manual labeling work while providing an excellent recognition precision for hardness recognition.
Introduction
The tactile sensing is an important direction in artificial intelligence (AI) research, and is especially useful for the robotic arms to mimic human hands in grasping and other movements (Xiaonan, 2011). In order to achieve human-like robotic arms, two tactile recognition studies need to be carried out. One study focuses on using visual and tactile data together to recognize the object (Gao et al., 2016; Falco et al., 2017; Levine et al., 2017; Liu et al., 2017). The other study focuses on using the tactile sensing data to obtain the physical parameters of the object, such as texture, hardness (Ahmadi et al., 2010; Kaboli et al., 2014; Hoelscher et al., 2015; Yamazaki et al., 2016). The hardness is one typical parameter essential to the grasping force control for the robotic forearm (Schill et al., 2012; Huang et al., 2013; Lichao, 2016), which is the focus of this paper. The existing hardness recognition methods can be broadly classified into two categories: (1) non-machine learning based methods, (2) machine learning based methods.
A majority of previous hardness recognition methods can be classified into the first category. Huang et al. (2012) used the pressure data and the grasping position of the robotic hand to test the hardness of the object. Yussof et al. (2008) let the robotic hand touch the object several times using various small forces, obtaining the hardness based on the force feedback. Boonvisut and Cavusoglu (2014) used the shape change of the object to recognize the hardness. The non-machine learning based methods usually did not use the complex algorithms but require sophisticated hardware and complex testing procedures.
The hardness recognition works belonging to the second category can be further classified into two types according to whether or not the deep learning techniques are employed. The first type is based on traditional machine learning approaches. Chu et al. (2015) used BioTac sensors to obtain tactile data. Then, the hidden markov model (HMM) is used to extract the feature vectors of tactile data. Finally, the support vector machine (SVM) is trained and used to recognize the hardness. Other methods based on traditional machine learning include: decision tree based method (Bandyopadhyaya et al., 2014), k-nearest neighbors (KNN) based method (Drimus et al., 2011), and SVM based method (Kaboli et al., 2014), etc. Recently, the deep learning technique has made great progress and has been successfully applied in many fields (Han et al., 2013, 2015; Wu et al., 2015, 2017; Li et al., 2016; Zhang et al., 2017; Hou et al., 2018). Some hardness recognition works based on deep learning included are as follows: Yuan et al. (2017) used a GelSight sensor to obtain the tactile data sequence, and adopted the long short-term memory (LSTM) algorithm to recognize the hardness of the object. Bhattacharjee et al. (2018) also used LSTM to process the time-variant tactile sensing data to classify the hardness of the object. The visual and tactile features are extracted by convolution neural network (CNN), and combined for hardness recognition (Gao et al., 2016).
The deep learning based methods have shown their superiority among aforementioned methods, however, the existing deep learning based methods require a large number of manually labeled samples which need significant time and labor costs. In order to alleviate this problem, a hardness recognition method based on semi-supervised GAN is proposed in this paper. The proposed method not only makes use of a large number of unlabeled samples, but also augments the labeled samples.
The framework of the proposed method is shown in Figure 1. In the training stage of GAN, first of all a large number of unlabeled samples are used to train a GAN which is denoted as USTGAN (unsupervised training GAN). Secondly, the manually labeled samples corresponding to each hardness level are separately used to train L (number of hardness level) GANs which are denoted as STGAN (supervised training GAN), where the architecture and initial parameter values of STGAN are inherited from USTGAN. The L levels manually labeled samples are separately augmented by the L trained STGANs. In the training stage of HRN, a large number of augmented samples are used to pretrain the HRN of which the main architecture and initial parameter values are inherited from the discriminator of USTGAN, and then the manually labeled samples are used to fine-tune the HRN. In the testing stage, the captured tactile data obtained by the robotic forearm are directly imported into the HRN to obtain the hardness recognition results. The DeLiGAN (Gurumurthy et al., 2017) is used as the GAN model in this paper because it requires less labeled samples. It's worth noting that the other published GAN models, such as GM-GAN (Ben-Yosef and Weinshall, 2018), can also be adopted and the selection of GAN model is not the focus of this paper.
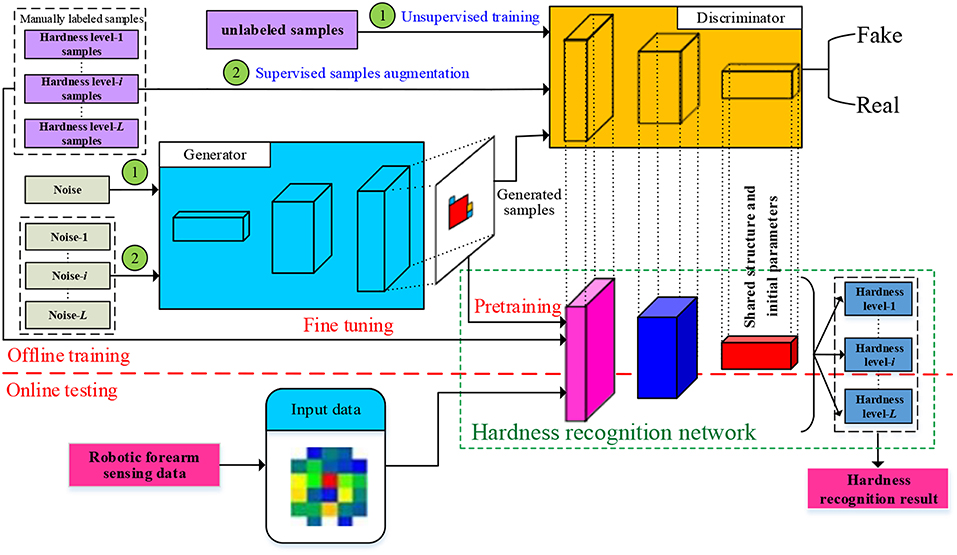
Figure 1. Framework of proposed method.
As a matter of fact, some semi-supervised GANs have been proposed (Odena, 2016; Salimans et al., 2016), however, the role of the proposed semi-supervised GAN is different in previous methods. The discriminator of previous semi-supervised GANs is used as the classifier which outputs L+1 probabilities (L probabilities for the L real classes and one probability for the fake classes), therefore, the trained discriminator can be directly used to recognize the hardness level. However, the proposed semi-supervised GAN is used to augment the manually labeled samples rather than classification of hardness level. As mentioned before, after the unsupervised training of USTGAN which is used to provide initial model parameters to STGAN and HRN, L level manually labeled samples are used to train L STGANs and are subsequently augmented by the L trained generators of STGANs. As a matter of fact, the discriminator of STGAN is the traditional real-fake binary classifier which is not used for the classification of hardness level, and the classification of hardness level is implemented by the HRN which outputs L probabilities. A large number of samples augmented by STGANs are used to pretrain the HRN, which is the key contribution of STGAN.
The major contributions of the proposed method can be summarized as follows:
(1) A semi-supervised scheme is proposed for hardness recognition in order to save the time and labor cost of human labeling. A large number of unlabeled samples are made use of through the unsupervised training of USTGAN, of which the main architecture and parameter values are shared with the following STGAN and HRN, and the manually labeled samples are used to train STGAN and automatically augmented by the trained STGAN.
(2) A HRN of which the main architecture and initial parameter values are inherited from the discriminator of USTGAN is employed to recognize the hardness level of objects touched by robotic forearm online. The large amount of augmented samples and manually labeled samples are separately used to pretrain and fine-tune the HRN.
Proposed Method
The proposed method can be classified into three steps. Firstly, the USTGAN is trained by a large number of unlabeled samples in order to provide a good initial state to the following STGAN and HRN. Secondly, L STGANs of which the generators are used to augment the labeled samples are individually trained by L-level manually labeled samples. Finally, the HRN which is pretrained by augmented samples and fine-tuned by manually labeled samples is employed to recognize the hardness level of captured tactile data obtained from the robotic forearm.
As mentioned before, the architecture of DeLiGAN is adopted by STGAN and USTGAN in this paper, therefore, some of the details of DeLiGAN will be presented in the following section for the completeness of description. The details of above three steps are given as follows.
Unsupervised Training of USTGAN
In order to alleviate the shortage of labeled samples, the large number of unlabeled samples are made use of by sharing the architecture and parameter values of trained USTGAN with the following STGAN and HRN.
The architecture and training scheme of USTGAN is similar to DeLiGAN, the only difference is the training samples. Therefore, the details of the training scheme of USTGAN is no longer presented in this section.
Labeled Samples Augmentation Based on STGAN
The architecture of STGAN is the same as USTGAN and the initial parameter values are also given by the trained USTGAN, however, the training of STGAN is supervised. As shown in Figure 1, the probability density of input noises of ith STGAN which is used to augment the ith hardness level samples is defined as follows (Gurumurthy et al., 2017):
where, denotes the input noises corresponding to ith hardness level, n is the dimension of the input noises, K denotes the number of Gaussian component contained in GMM, denotes the Gaussian distribution, and denotes the mean vector and covariance matrix of the kth Gaussian component of zi, respectively, denotes the weight of kth Gaussian component of zi, which can be quantified by ratio of the number of noisy signals generated from kth Gaussian component to all noisy signals.
To obtain the zi, the “reparameterization trick” introduced by Kingma and Welling (2014) is employed to sample from each Gaussian component. We assume that is a diagonal covariance matrix which is denoted as = diag (), then the input noise derived from the kth Gaussian component which is denoted as can be obtained by:
where, η is an auxiliary noise variable following normal distribution, denotes the diagonal elements of . As shown in Equation (2), obtaining the will translates to sampling if the values of and are obtained. Finally, the zi can be obtained by repeating the above processing of each k ∈ [1, K].
Obviously, the values of and should be determined in order to obtain the input noise. The and are learned along with the training of ith STGAN of which the details are as follows.
Training of STGAN
A total of L STGANs are trained by L level manually labeled samples, respectively. The loss function of discriminator of ith STGAN is as follows (Goodfellow et al., 2014; Radford et al., 2016):
where, and denote the model parameters of discriminator and generator of ith STGAN, xi denotes the manually labeled samples of ith hardness level, pdata(xi) denotes the probability density distribution of xi,G(·) denotes the samples generated from zi, D(·) ∈ [0, 1] denotes the probability that the input samples belong to the real labeled samples. As shown in Equation (3), is regarded as constants when discriminator is trained using Equation (3).
The loss function of generator is as follows (Goodfellow et al., 2014; Radford et al., 2016):
Similarly, is regarded as constants when the generator is trained using Equation (4).
As shown in Equation (2), is the function of and , therefore, the and will be trained simultaneously along with . According to Equation (2), the Equations (3, 4) can be respectively reformulated as:
It's worth noting that generator tries to decrease the in order to obtain more noisy signals from the high probability regions which are around the , consequently, the will collapse to zero. Therefore, a L2 penalty terms is added to the loss function of generator in order to prevent this from happening:
Finally, the discriminator and generator of STGAN is trained alternatively according to Equations (5) and (7) for obtaining the , , , and .
Samples Generation
According to Equation (2), noise signals can be generated from the kth Gaussian component when and have been learned in the last section. Subsequently, the generated samples are obtained by sending the noise signals to the generator of ith STGAN. Finally, the generated samples corresponding to the ith hardness level are obtained and denoted as gxi.
Hardness Recognition
As shown in Figure 1, the architecture of HRN is the same as the discriminator of USTGAN except for the classification layer. Specifically, the classification layer of USTGAN and HRN is the real-fake binary classifier and L-class softmax classifier, respectively. The HRN is firstly pretrained using GX and is subsequently fine-tuned using X, where, and denote the assemble of gxi and xi, respectively.
As mentioned before, the initial model parameters of HRN are inherited from the discriminator of trained USTGAN. The rationality of the parameters sharing can be analyzed in terms of loss function. In fact, the discriminator of USTGAN can be regarded as a combination of real-fake classifier and CNN which is used to extract the deep feature of generated data and real data. Consequently, the loss function of discriminator of USTGAN can be reformulated as:
where, ε denotes the input noise of generator of USTGAN, xu denotes unlabeled samples, and βG and βD denote the model parameters of discriminator and generator, respectively. f(ε, βG) and f(xu) denote the extracted features of generated samples and unlabeled samples, respectively. As shown in Equation (8), the traditional formulation of probability distribution can be reformulated as the probability that extracted features belong to a real class. Considering the fact that the xu includes a large number of unlabeled samples with various hardness levels, the CNN contained in discriminator can extract the common feature of tactile data with different hardness levels after the unsupervised training of USTGAN.
Similarly, the HRN can be regarded as the combination of L-class classifier and CNN which is inherited from the discriminator of USTGAN, and the loss function of HRN can be formulated as:
where, and denote the training samples and corresponding labels, respectively, (,) ∈ X or GX, NTR denotes the number of training samples, θ denotes the model parameters of HRN, denotes the extracted features of . Similar to equation (8), denotes the probability that belongs to ith class. Obviously, on the basis of the capability to extract common features, the CNN can also extract discriminative features after the supervised training of HRN.
In summary, the HRN and discriminator of USTGAN can be regarded as the combination of CNN and classifier. The CNN can extract the common features of tactile data with different hardness levels through the unsupervised training of USTGAN, and the capability is inherited by the CNN contained in HRN through the parameters sharing. Furthermore, the CNN contained in HRN can extract the discriminative features of tactile data with different hardness levels through the supervised training of HRN. In other words, the unsupervised and supervised training are jointly used to improve the capability of feature extraction of HRN through the parameters sharing.
After the training of HRN, the hardness recognition is implemented as following:
where, y denotes the tactile data which is captured online by robotic forearm, HL(y) denotes the hardness level of y, Y denotes the output of HRN when y is imported into the trained HRN, Y(i) denotes the probability that y belong to ith hardness level.
The whole procedure of hardness recognition can be summarized in Algorithm 1.

Algorithm 1. Hardness recognition.
Experiment
Experiment Setting
Acquisition of Tactile Data
Tactile sensor
A tactile sensor JX255N manufactured by I-Motion is a thin film pressure sensor which has an array of 28 × 28 sensing elements, and is integrated in the robotic forearm. The size of the tactile sensor is 98 × 98 mm, and consequently the spatial resolution of the sensor is 3.5 × 3.5 mm. The minimum discrimination of the tactile sensor is 0.2 N. The maximum scanning rate of the sensor is 100 frames/s while a rate of 5 frames/s is used in our experiments.
Data acquisition
The tactile sensor assembled at the end of the robotic forearm is used to press the testing objects which are placed on the flat experimental table to obtain a sequence of tactile data frame. We directly place the testing objects below the sensor, and the sensor moves vertically to touch the objects. The moving speed of the sensor is set to 5 mm/s. The sensor surface is always parallel to the surface of experimental table during the pressing process. The testing objects are placed on the experimental table with at least six postures and pressed by the sensor with at least eight forces (1~25 N). The number of times that each object is pressed is set to 50 in our experiment. The tactile data frame of which the contact area is maximum is selected as the final input data.
Dataset for Evaluation
As shown in Table 1, the hardness is divided into four levels according to Shore hardness. Two kinds of material with similar hardness are selected as the reference materials for each hardness level. One is used to generate samples for training and another one is used for testing, which can avoid unfair evaluation caused by same reference material. Specifically, the wood, rubber, plasticine, and sponge which separately correspond to the hardness level-1, level-2, level-3, and level-4 are selected as the reference material for collecting training samples. Similarly, hard plastic, foam, soft candy, yoga matt are used to obtain testing samples. There are 50 (5) sampled objects are selected for each training (testing) reference material, and the number of times that each object is pressed is set to 50, as mentioned before. Therefore, 2,500 (250) samples can be obtained for each training (testing) reference material. Consequently, the dataset is consisted of 11,000 manually labeled samples, where 10,000 samples are used for training and 1,000 samples are for testing.

Table 1. Details of proposed dataset.
As shown in Figure 2, eight samples are selected from the proposed dataset and shown in the form of pressure image, each sample belongs to different hardness levels of training (testing) set. Due to the high hardness, the wood blocks and hard plastics are not easy to deform, therefore, their pressure images seem to be scattered since their surface is not seriously flat. The pressure image of hardness level-2 ~4 can be approximately considered as a Gaussian distribution with the increasing standard deviation.
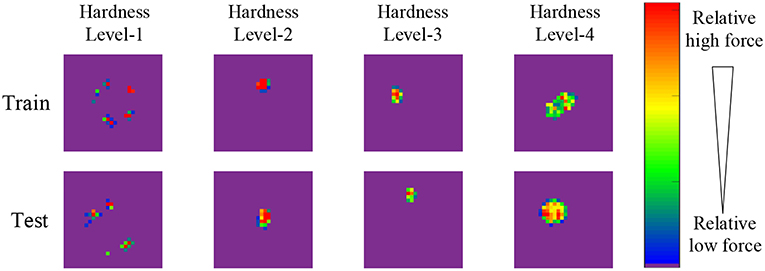
Figure 2. Illustration of eight samples of proposed dataset. Each sample belongs to different hardness level of training (testing) set, and is shown in the form of pressure image. The color bar indicates the relative force values, where red denotes the maximum force value of pressure image, blue denotes the minimum force value except zero value, purple denotes zero value.
Implementation Details
Training of STGAN and USTGAN
Following the setting of dataset, the number of hardness levels L is four. The is initialized by sampling from a uniform distribution U(−1, 1), is assigned to a fixed initial value 0.15 in this paper, n = 30, K = 50, which indicates that all of the Gaussian components are equally important and the number of noises generated from each Gaussian component is equal. In Equation (7), λ = 0.1. The optimization algorithm for training the STGAN is Adam (Kingma and Ba, 2015). The learning rate of STGAN is 0.001, the number of iterations is 500, the batch size is 100. The parameter setting of USTGAN is same as STGAN.
In order to demonstrate the effectiveness of the proposed method, only 1,500 labeled samples (375 samples per hardness level) among 10,000 samples are used to train the STGAN for samples augmentation, the other 8,500 samples are regarded as the unlabeled samples for training of USTGAN.
Training of HRN
The learning rate is 0.001, the number of iterations is 200, and the batch size is 100. The optimization algorithm for training of HRN is stochastic gradient descent (SGD). The samples augmentation is implemented following the scheme introduced in section Labeled samples augmentation based on STGAN. The expansion ratio is 1:30, in other words, 45,000 labeled samples are generated (375*30 = 11,250 samples per hardness level) and employed to pretrain the HRN, aforementioned 1,500 labeled samples are used to fine-tune the HRN.
Comparison Methods
First of all, three full supervised HRNs separately trained by 1,500, 5,000, and 10,000 manually labeled samples are denoted as HRN15, HRN50, HRN100, respectively, and are used to compared with proposed method in order to evaluate the capability of proposed method relative to fully supervised methods. Secondly, two existing semi-supervised GANs which are separately denoted as SGAN (Odena, 2016) and IGAN (Salimans et al., 2016) are compared with our method to evaluate the effectiveness of proposed semi-supervised GAN. The unlabeled samples and manually labeled samples used by SGAN and IGAN are same as proposed method for fair comparison. Thirdly, two variants of proposed methods which are separately denoted as NAHRN and NIHRN are employed for comparison in order to validate the effectiveness of samples augmentation and model initialization based on USTGAN. Specifically, the samples augmentation is not involved in NAHRN, NIHRN adopts random initialization for HRN, the rest of NAHRN and NIHRN is same as proposed method except aforementioned changes.
Evaluation Metrics
Four evaluation metrics are employed to evaluate the effective of propose method: category accuracy, overall accuracy, confusion matrix, and Kappa coefficients.
The category accuracy is defined as:
where, Pi denotes the category accuracy of ith hardness level, Ni denotes the number of all the testing samples of ith hardness level, Zi denotes the number of correctly identified testing samples of ith hardness level. The Pi is proportional to the recognition accuracy of each hardness level.
The overall accuracy is defined as:
where, Poverall denotes overall accuracy, N denotes the total number of testing samples, Z denotes the total number of correctly identified testing samples. The Poverall is proportional to the overall recognition accuracy.
The yhw which denotes the element located in hth row and wth column of confusion matrix is defined as:
where, Nh denotes the total number of testing samples of hth hardness level, Nhw denotes the number of samples which belong to hth hardness level and are falsely recognized as wth hardness level. The yhw is inversely proportional to the degree of confusion between each hardness level.
The Kappa coefficient which is denoted as Ka can be obtained from confusion matrix:
where, yjj denotes the jth diagonal element of confusion matrix, aj denotes the sum of elements located in jth row, bj denotes the sum of elements located in jth column. The Kappa coefficient is inversely proportional to the overall degree of confusion.
Experimental Results
Comparison in Terms of Category Accuracy and Overall Accuracy
The comparison results between the proposed method and other methods in terms of category accuracy and overall accuracy is shown in Table 2.

Table 2. Comparison results in terms of category accuracy and overall accuracy.
Compared with three full supervised methods, the performance of the proposed method is apparently superior to HRN15 and HRN50, and is comparable with the HRN100. As a matter of fact, the architecture of the hardness recognition model adopted by the proposed method is the same as HRN100, and the number of original training samples used by proposed method is also equal to HRN100, the only difference being the composition of samples. As mentioned before, only 1,500 manually labeled samples are used by the proposed method and the other 8,500 samples are unlabeled, while the 10,000 samples used by HRN100 are all manually labeled. Therefore, the performance of HRN100 can be considered as the upper bound of proposed method. As shown in Table 2, the performance of proposed is comparable with HRN100, which can validate the effectiveness of proposed semi-supervised scheme.
Compared with two existing semi-supervised methods, the performance of the proposed method is superior to SGAN and IGAN. As described in section Comparison methods, the unlabeled samples and manually labeled samples used by SGAN and IGAN are the same as the proposed method for fair comparison, and the key difference is the samples augmentation. To some extent, the comparison between the proposed method and SGAN, IGAN, can validate the effectiveness of the proposed samples augmentation scheme.
Compared with two variants of the proposed method, the performance of proposed method is superior to the NAHRN and NIHRN. The comparison between NAHRN and the proposed method indicates that the samples augmentation can apparently improve the performance of hardness recognition. As a matter of fact, the training samples used by SGAN and IGAN are completely identical with NAHRN which do not adopt samples augmentation, and consequently the overall accuracy of NAHRN is close to SGAN and IGAN. The comparison between NIHRN and the proposed method indicates that the initialization based on USTGAN can improve the accuracy of hardness recognition. In fact, the comparison between NAHRN and HRN15 can demonstrate the effectiveness of initialization based on USTGAN more clearly. The architecture of NAHRN and HRN15 is identical, the same 1,500 manually labeled samples are used for the training of two models, and the only difference is the model initialization based on USTGAN which is trained by 8,500 unlabeled samples. The reason why the gap between NIHRN and proposed method is not obvious may be that a large number of augmented samples are used by NIHRN for model pretraining.
Comparison in Terms of Confusion Matrixes and Kappa Coefficients
The confusion matrixes and Kappa coefficients of various models are shown in Table 3, and similar conclusions to the previous section can be drawn from the Table 3. The overall degree of confusion of the proposed method is better than the other six methods and is comparable with the HRN100 in terms of kappa coefficients. It can be seen that the probability of confusion between hardness level-2 and level-3 is higher than others, as shown in the confusion matrixes. The reason may be that the difference of Shore hardness of reference materials between hardness level-2 and level-3 is smaller than other adjacent hardness levels, as shown in Table 1, therefore, the degree of deformation between hardness level-2 and level-3 is closer than other adjacent hardness levels.
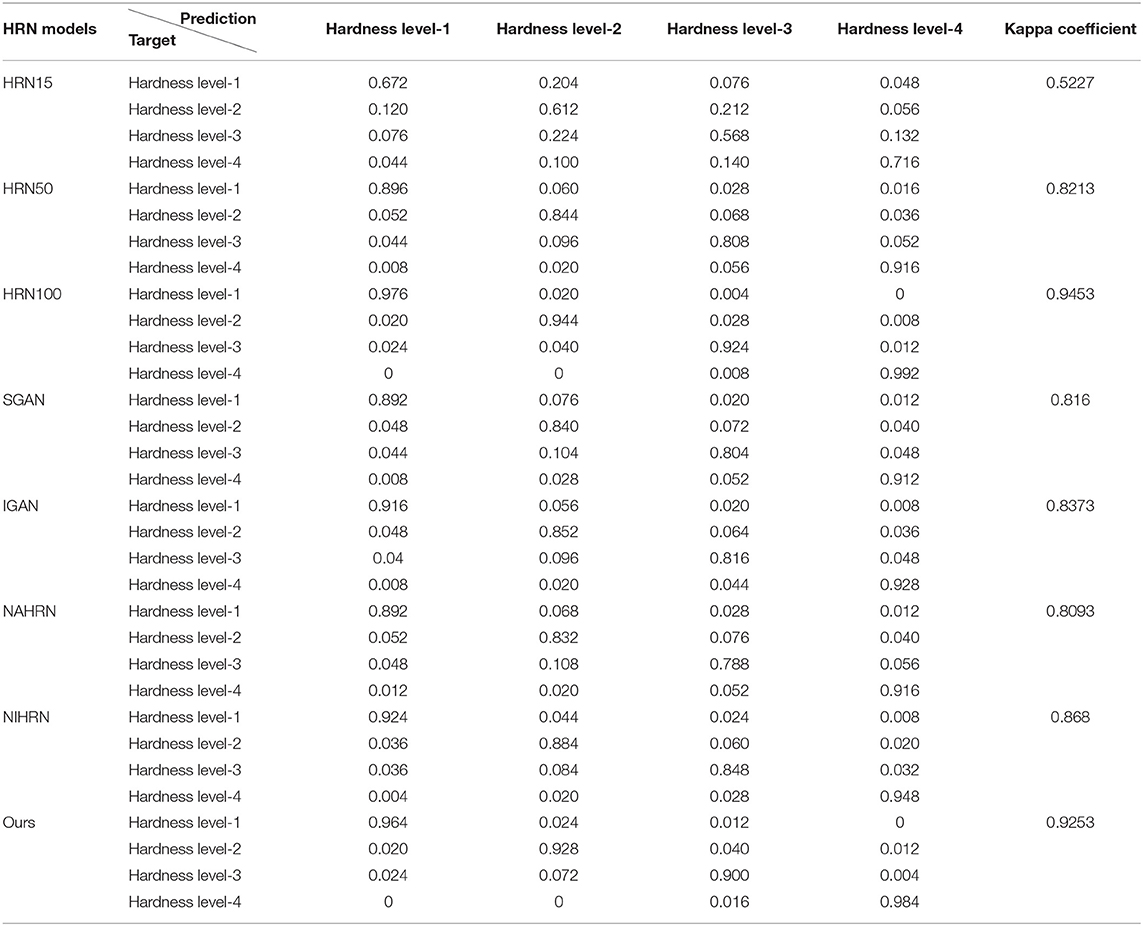
Table 3. Comparison results in terms of confusion matrixes and Kappa coefficients.
In summary, the performance of proposed method is superior to other six methods and is comparable with HRN100, the effectiveness of samples augmentation and initialization based on USTGAN is also validated through the comparison.
Conclusion
A semi-supervised scheme which only need a small amount of training samples is proposed for hardness recognition of a robotic forearm. The proposed method can make use of a large number of unlabeled samples through unsupervised training of GAN of which the architecture is shared with following model. The proposed method can also augment the manually labeled samples through the supervised training of GAN of which the initial state is inherited from the unsupervised GAN. The HRN of which the initial state is also inherited from the unsupervised GAN are pretrained by the large number of augmented labeled samples and fine-tuned by small amount of labeled samples. The experimental results on the proposed dataset demonstrate that the proposed samples augmentation and model initialization schemes are effective.
The GAN model adopted in this paper is DeLiGAN, in principle, any other GAN which can generate 2D data from the noise can be adopted in our semi-supervised scheme, however, some weakness of existing GAN models has not been overcome, e.g., model collapsing, therefore, the performance may be improved by applying a more powerful GAN model. In addition, it's worth noting that the proposed semi-supervised scheme can be applied in other tactile AI applications based on machine learning methods.
Data Availability
The datasets generated for this study are available on request to the corresponding author.
Author Contributions
XQ contributed to the key innovation and wrote this paper. EL designed and debugged the codes of proposed method. JZ designed the scheme of experiments. S-NZ responsible for the tactile data acquisition. Q-EW designed the flowchart of source code. HZ designed training scheme of HRN. WW as the team leader, was responsible for the arrangement of overall work. YW contributed to revision of paper.
Funding
This work was supported by the National Science Foundation of China under Grants (No: 61501407, 61603350, 61672471, 61873246), Key research project of Henan Province Universities (No: 19A413014), Plan For Scientific Innovation Talent of Henan Province (No: 184200510010), Center Plain Science and Technology Innovation Talents (No. 194200510016), Science and Technology Innovation Team Project of Henan Province University (No. 19IRTSTHN013), Doctor fund project of Zhengzhou University of Light Industry (No: 2014BSJJ016).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Ahmadi, R., Ashtaputre, P., Ziki, J. D. A., Dargahi, J., and Packirisamy, M. (2010). Relative hardness measurement of soft objects by a new fiber optic sensor. Photonics N. 7750:77500D. doi: 10.1117/12.873106
Bandyopadhyaya, I., Babu, D., Kumar, A., and Roychowdhury, J. (2014). “Tactile sensing based softness classification using machine learning,” in IEEE IACC (Gurgaon), 1231–1236. doi: 10.1109/IAdCC.2014.6779503
Ben-Yosef, M., and Weinshall, D. (2018). Gaussian mixture generative adversarial networks for diverse datasets, and the unsupervised clustering of images. arxiv [Preprint] arxiv:1808.10356.
Bhattacharjee, T., Rehg, J. M., and Kemp, C. C. (2018). Inferring object properties with a tactile-sensing array given varying joint stiffness and velocity. Int. J. Humanoid Robot. 15:1750024. doi: 10.1142/S0219843617500244
Boonvisut, P., and Cavusoglu, M. C. (2014). Identification and active exploration of deformable object boundary constraints through robotic manipulation. Int. J. Rob. Res. 33, 1446–1461. doi: 10.1177/0278364914536939
Chu, V., Mcmahon, I., Riano, L., Mcdonald, C. G., He, Q., Pereztejada, J. M., et al. (2015). Robotic learning of haptic adjectives through physical interaction. Rob. Auton. Syst. 63, 279–292. doi: 10.1016/j.robot.2014.09.021
Drimus, A., Kootstra, G., Bilberg, A., and Kragic, D. (2011). “Classification of rigid and deformable objects using a novel tactile sensor,” in IEEE ICAR (Tallinn), 427–434. doi: 10.1109/ICAR.2011.6088622
Falco, P., Lu, S., Cirillo, A., Natale, C., Pirozzi, S., and Lee, D. (2017). “Cross-modal visuo-tactile object recognition using robotic active exploration,” in IEEE ICRA (Singapore), 5273–5280. doi: 10.1109/ICRA.2017.7989619
Gao, Y., Hendricks, L. A., Kuchenbecker, K. J., and Darrell, T. (2016). “Deep dearning for tactile understanding from visual and haptic data,” in IEEE ICRA (Stockholm), 536–543. doi: 10.1109/ICRA.2016.7487176
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). “Generative Adversarial Networks,” in NIPS (Montreal), 2672–2680.
Gurumurthy, S., Sarvadevabhatla, R. K., and Babu, R. V. (2017). “DeLiGAN: generative adversarial networks for diverse and limited data,” in IEEE CVPR (Hawaii, HI), 4941–4949. doi: 10.1109/CVPR.2017.525
Han, J., Ji, X., Hu, X., Zhu, D., Li, K., Jiang, X., et al. (2013). Representing and retrieving video shots in human-centric brain imaging space. IEEE Trans. Image Process. 22, 2723–2736. doi: 10.1109/TIP.2013.2256919
Han, J., Zhang, D., Hu, X., Guo, L., Ren, J., and Wu, F. (2015). Background prior-based salient object detection via deep reconstruction residual. IEEE Trans. Circuits Syst. Video Technol. 25, 1309–1321. doi: 10.1109/TCSVT.2014.2381471
Hoelscher, J., Peters, J., and Hermans, T. (2015). “Evaluation of tactile feature extraction for interactive object recognition,” in IEEE Humanoids (Seoul), 310–317. doi: 10.1109/HUMANOIDS.2015.7363560
Hou, K., Shao, G., Wang, H., Zheng, L., Zhang, Q., Wu, S., et al. (2018). Research on practical power system stability analysis algorithm based on modified SVM. Prot. Control Mod. Power Syst. 3:11. doi: 10.1186/s41601-018-0086-0
Huang, L., Kawamura, T., and Yamada, H. (2012). Construction robot operation system with object's hardness recognition using force feedback and virtual reality. J. Robot. Mechatron. 24, 958–966. doi: 10.20965/jrm.2012.p0958
Huang, S. J., Chang, W. H., and Su, J. Y. (2013). Intelligent robotic gripper control strategy. Adv. Mat. Res. 753–755, 2006–2009. doi: 10.4028/www.scientific.net/AMR.753-755.2006
Kaboli, M., Mittendorfer, P., Hugel, V., and Cheng, G. (2014). “Humanoids learn object properties from robust tactile feature descriptors via multi-modal artificial skin,” in IEEE Humanoids (Madrid), 187–192. doi: 10.1109/HUMANOIDS.2014.7041358
Kingma, D. P., and Ba, J. (2015). “Adam: a method for stochastic optimization,” in ICLR (San Diego, CA), 1–15.
Kingma, D. P., and Welling, M. (2014). “Auto-encoding variational bayes,” in ICLR (Banff, AB), 1–14.
Levine, S., Pastor, P., Krizhevsky, A., and Quillen, D. (2017). Learning hand-eye coordination for robotic grasping with large-scale data collection. Int. Symp. Exp. Robot. 1, 173–184. doi: 10.1007/978-3-319-50115-4_16
Li, Z., Ye, L., Zhao, Y., Song, X., Teng, J., and Jin, J. (2016). Short-term wind power prediction based on extreme learning machine with error correction. Prot. Control Mod. Power Syst. 1:1. doi: 10.1186/s41601-016-0016-y
Lichao, W. (2016). Recognition of object's softness and hardness based on tactile information of robotic hand (Master thesis), Zhejiang University, Hangzhou, China.
Liu, H., Yu, Y., Sun, F., and Gu, J. (2017). Visual-tactile fusion for object recognition. IEEE Trans. Autom. Sci. Eng. 14, 996–1008. doi: 10.1109/TASE.2016.2549552
Odena, A. (2016). Semi-supervised learning with generative adversarial networks. arxiv [Preprint] arxiv:1606.01583.
Radford, A., Metz, L., and Chintala, S. (2016). “Unsupervised representation learning with deep convolutional generative adversarial networks,” in ICLR (San Juan), 1–16.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. (2016). “Improved techniques for training GANs,” in NIPS (Barcelona), 2234–2242.
Schill, J., Laaksonen, J., Przybylski, M., Kyrki, V., Asfour, T., and Dillmann, R. (2012). “Learning continuous grasp stability for a humanoid robot hand based on tactile sensing,” in IEEE BioRob (Rome), 1901–1906. doi: 10.1109/BioRob.2012.6290749
Wu, Y., Cao, J., Alofi, A., Abdullah, A.-M., and Elaiw, A. (2015). Finite-time boundedness and stabilization of uncertain switched neural networks with time-varying delay. Neural Netw. 69, 135–143. doi: 10.1016/j.neunet.2015.05.006
Wu, Y., Cao, J., Li, Q., Alsaedi, A., and Alsaadi, F. E. (2017). Finite-time synchronization of uncertain coupled switched neural networks under asynchronous switching. Neural Netw. 85, 128–139. doi: 10.1016/j.neunet.2016.10.007
Xiaonan, W. (2011). On contradictory issues in the technology development of robot (Master thesis), Dalian University of Technology, Dalian, China.
Yamazaki, H., Nishiyama, M., and Watanabe, K. (2016). A hemispheric hetero-core fiber optic tactile sensor for texture and hardness detection. Photonic Instrum. Eng. III 9754:97540X. doi: 10.1117/12.2212146
Yuan, W., Zhu, C., Owens, A. H., Srinivasan, M. A., and Adelson, E. H. (2017). “Shape-independent hardness estimation using deep learning and a GelSight tactile sensor,” in IEEE ICRA (Singapore), 951–958. doi: 10.1109/ICRA.2017.7989116
Yussof, H., Ohka, M., Takata, J., Nasu, Y., and Yamano, M. (2008). “Low force control scheme for object hardness distinction in robot manipulation based on tactile sensing,” in IEEE ICRA (Pasadena, CA), 3443–3448. doi: 10.1109/ROBOT.2008.4543737
Keywords: tactile sensing, hardness recognition, deep learning, semi-supervised, generative adversarial networks
Citation: Qian X, Li E, Zhang J, Zhao S-N, Wu Q-E, Zhang H, Wang W and Wu Y (2019) Hardness Recognition of Robotic Forearm Based on Semi-supervised Generative Adversarial Networks. Front. Neurorobot. 13:73. doi: 10.3389/fnbot.2019.00073
Received: 30 April 2019; Accepted: 23 August 2019;
Published: 06 September 2019.
Edited by:
Ganesh R. Naik, Western Sydney University, AustraliaReviewed by:
Eiji Uchibe, Advanced Telecommunications Research Institute International (ATR), JapanFarong Gao, Hangzhou Dianzi University, China
Copyright © 2019 Qian, Li, Zhang, Zhao, Wu, Zhang, Wang and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei Wang, MTg5MDA2MTYwMjlAMTg5LmNu; Yuanyuan Wu, d3l1YW55dWFuODJAMTYzLmNvbQ==