
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 07 April 2020
Sec. Genomic Assay Technology
Volume 11 - 2020 | https://doi.org/10.3389/fgene.2020.00285
This article is part of the Research Topic The Algorithm Developments and Applications of Third-Generation Sequencing View all 27 articles
 Fuqiang Ye1†
Fuqiang Ye1† Yifang Han1†Juanjuan Zhu2†
Yifang Han1†Juanjuan Zhu2† Peng Li3
Peng Li3 Qi Zhang1
Qi Zhang1 Yanfeng Lin3Taiwu Wang1Heng Lv1
Yanfeng Lin3Taiwu Wang1Heng Lv1 Changjun Wang3Chunhui Wang1*Jinhai Zhang1*
Changjun Wang3Chunhui Wang1*Jinhai Zhang1*Human adenoviruses (HAdVs) have been demonstrated to cause a diversity of diseases among children and adults. The circulation of human adenovirus type 21 (HAdV21) has been mainly documented within closed environments in several countries. Nonetheless, respiratory infections or outbreaks due to HAdV21 have never been reported in China. MinION and Illumina platforms were employed to identify the potential pathogen from a throat swab. Discrepancies between MinION and Illumina sequencing were validated and corrected via polymerase chain reaction (PCR). Genomic characterization and recombinant event detection were then performed. Among the 35,466 high-quality MinION reads, a total of 5,999 reads (16.91%) could be aligned to HAdV21 reference genomes (genome sizes ≈35.3 kb), among which 20 had a length of >30 kb. A genome sequence assembled from MinION reads was further classified as HAdV subtype 21a. Random downsampling revealed as few as 500 nanopore reads could cover ≥96.49% of current genome. Illumina sequencing displayed good consistency (pairwise nucleotide identity = 99.91%) with MinION sequencing but with 31 discrepancies that were further validated and confirmed by PCR coupled with Sanger sequencing. Restriction enzymes such as BamHI and KpnI were able to distinguish the present genome from HAdV21 prototype and HAdV21b. Phylogenetic analysis employing whole-genome sequences placed our genome with members only from subtype 21a. Common features among HAdV21a strains were identified, including polymorphisms discovered in penton and 100 kDa hexon assembly–associated proteins and a recombinant event in the E4 gene. Using MinION and Illumina sequencers, we identified the first HAdV21a strain from China, which could provide key genomic data for disease control and epidemiological investigations.
Since the first discovery by Rowe et al. (1953), human adenoviruses (HAdVs) have been found to cause a diversity of diseases in children and adults (Radke and Cook, 2018; Prusinkiewicz and Mymryk, 2019; Yao et al., 2019). Belonging to the Mastadenovirus genus in the Adenoviridae family, HAdVs are double-stranded DNA viruses with 35–36 kb pairs in their genomes (Radke and Cook, 2018). At present, almost 90 Adv subtypes distributed across seven species (termed as A through G) have been classified, among which 55 could lead to human infections (Prusinkiewicz and Mymryk, 2019; Yao et al., 2019). A variety of tissue tropisms are observed in these HAdVs, with preferred infections of species B/C/E in the respiratory tracts, species B/C/D/E in the conjunctiva, species A/F/G in the gastrointestinal tract, and species B in the kidney (Lenaerts et al., 2008; Lion, 2014; Prusinkiewicz and Mymryk, 2019). Human adenovirus types 3, 4, 7, 11, 14, 21, and 55 are common AdV pathogens responsible for human respiratory tract infections or respiratory outbreaks in many regions (Lewis et al., 2009; Kajon et al., 2010; Li et al., 2014; Scott et al., 2016; Bautista-Gogel et al., 2019; Prusinkiewicz and Mymryk, 2019; Sammons et al., 2019; Zhang et al., 2019). Clinical symptoms caused by HAdVs are usually mild and self-limiting in healthy people; however, immunologically compromised individuals such as young children, elderly persons, and immunosuppressed patients might have a higher risk of severe disease and even death (Ison, 2006; Kandel et al., 2010; Lee et al., 2010; Scott et al., 2016; Pfortmueller et al., 2019). Notably, HAdV-associated respiratory outbreaks are commonly seen in closed population clusters, including schools and hospitals (Scott et al., 2016; Radke and Cook, 2018).
The circulation of human adenovirus type 21 (HAdV21) has been mainly documented in care facilities, military hospitals, or military recruit training centers (Hage et al., 2014; Kajon et al., 2015; Scott et al., 2016; Philo et al., 2018; Pfortmueller et al., 2019). Human adenovirus type 21 can cause upper respiratory tract infection, pneumonia, hemorrhagic cystitis, myocarditis, and encephalitis. There are currently three HAdV21 subtypes according to the restriction enzyme analysis (REA), HAdV subtype 21a (HAdV21a), HAdV21b, and HAdV21p (Kajon et al., 2015). As noted above, HAdV21 commonly leads to mild clinical symptoms such as fever, cough, shortness of breath, fatigue, nausea, rhinorrhea, and myalgia (Scott et al., 2016). However, HAdV21a is linked to severe pneumonia or acute respiratory distress syndrome, with some fatal outcomes (Hage et al., 2014; Pfortmueller et al., 2019).
Nanopore sequencing technology was made public by Oxford Nanopore Technologies (ONT) in 2014. When DNA or RNA module translocates through a nanopore, an ionic current will be produced from a constant voltage bias, and then a change in the ionic current can be observed (van Dijk et al., 2018). Nucleic acid bases can then be basecalled by built-in or the third-party basecallers. When compared to the next-generation sequencing (NGS) methods, nanopore sequencing technology has advantages such as real time, long reads, short turnaround time, and simple sample preparation procedures (van Dijk et al., 2018; Ameur et al., 2019). In particular, the ONT platform MinION, also characterized by portability and low cost in addition to the above advantages, can well handle rapid pathogen detection in the field (McIntyre et al., 2016; Castro-Wallace et al., 2017; Johnson et al., 2017; Edwards et al., 2019). MinION has been widely employed in pathogen identification from human clinical samples to identify Chikungunya virus, hepatitis C virus, and enterovirus (Wang et al., 2017; Imai et al., 2018; Xu et al., 2018). It has also played a vital role in rapid pathogen confirmation in recent epidemic outbreaks caused by Ebola virus (Quick et al., 2016), Zika virus (Faria et al., 2017; Quick et al., 2017), yellow fever virus (Faria et al., 2018), and Lassa virus (Kafetzopoulou et al., 2019), highlighting the value of MinION in microbial investigation and disease control.
Human adenovirus type 21 infections or respiratory outbreaks have been reported in Germany (Hage et al., 2014), Denmark (Barnadas et al., 2018), Switzerland (Pfortmueller et al., 2019), Argentina (Barrero et al., 2012), and the United States (Kajon et al., 2015; Scott et al., 2016). However, respiratory infections due to HAdV21 or related strains have rarely been reported in China to date. In this study, MinION and Illumina sequencers were used to obtain HAdV21 genome sequences from viral cultures of a swab sample from a patient with respiratory tract infection. Polymerase chain reaction (PCR) products were then used to validate and correct discrepancies between MinION and Illumina sequencing. The genomic characterization and phylogenetic analysis were further performed with the corrected HAdV21a genome.
A throat swab sample was collected from a 20-year-old male outpatient with fever and sore throat in March 2019. The swab sample was immediately placed into preservation solution (Yocon, Beijing, China) and stored at -80°C until further processing. Initial real-time PCR tests of viral respiratory pathogens including HAdV, coronavirus, and influenza A/B viruses obtained a positive result for HAdV by using universal primers. However, PCR primers for epidemic HAdV subtypes in China, including HAdV1, HAdV3, HAdV4, HAdV7, HAdV14, and HAdV55, displayed negative results. The sample was cultivated in HEp-2 cell lines (ATCC, Manassas, VA, United States) supplemented with Dulbecco modified eagle medium (Life Technologies, Carlsbad, CA, United States) containing 2% fetal bovine serum (Life Technologies) until 90% cytopathic effects were visible. The patient provided written informed consent upon enrollment. The study conformed to the ethical guidelines of the 1975 Declaration of Helsinki and was approved by the Institutional Review Board of the Center for Disease Control and Prevention of Eastern Theater Command.
Viral DNA was extracted from the cell culture supernatant by using a QIAamp® MinElute® Virus Spin Kit (QIAGEN, Germantown, MD, United States) following the manufacturer’s protocols. Viral DNA was subsequently cleaned up and concentrated with AMPureTM XP beads (Beckman Coulter, Indianapolis, IN, United States). The purified DNA was further tested by quantitative PCR for detection of the target virus.
A total of 452 ng viral DNA was used for MinION sequencing. The MinION library was constructed with the Rapid Sequencing Kit (SQK-RAD004) according to the manufacturer’s instructions. The library was loaded to a SpotON Flow Cell (FLO-MIN106). Then the control software MinKNOW (v3.1.19, downloaded from the ONT website with a custom account) was set up with a run time of 48 h. The basecalling of fast5 files to fastq files during sequencing was also turned on.
Total DNA was sheared into ∼350 bp fragments by the Covaris ultrasonicator (Covaris, Woburn, MA, United States). A-tailed, ligated to paired-end adaptors and PCR amplified with a 350 bp insert were used for the library construction. Qubit 2.0 (Life Technologies) was then used to quantify the concentration of the library, and the insert size was tested with Agilent Bioanalyzer 2100 (Agilent, Santa Clara, CA, United States). Illumina NovaSeq 6000 platform (Illumina, San Diego, CA, United States) was used to generate 2 × 150 bp pair-end reads.
To validate and correct the genomic discrepancies between MinION and Illumina sequencing, we designed seven pairs of PCR primers covering these discrepant sites via Primer Premier 5.0 software. The PCR reaction was carried out in a total volume of 50 μL that contained 5 units Taq DNA polymerase (TakaRa, Dalian, China), 0.2 μM of each sense and antisense primer, 2.0 mM MgCl2, 200 μM dNTP, and 2 μL of template (2 ng/μL). Thermal cycling conditions involved an initial denaturation step at 95°C for 5 min, followed by 30 cycles of 95°C for 40 s, 40°C for 40 s, and 72°C for 3 min, and a final extension step at 72°C for 10 min. Polymerase chain reaction–amplified products were electrophoresed on a 1% agarose-gel, stained with ethidium bromide, and visualized under UV light to compare their lengths with DNA markers. Polymerase chain reaction products approximately covering their target regions were then sent out for Sanger sequencing (Sangon, Shanghai, China). The primers were listed as follows:
HAdV21-1-F: 5′-GTCATATCATAGTAGCCTGTCG-3′
HAdV21-1-R: 5′-GGAAGTTACGCTTGTTGG-3′
HAdV21-2-F: 5′-CCCTTGCTACCAAAGACC-3′
HAdV21-2-R: 5′-GCACTACAGCCATCATAAGC-3′
HAdV21-3-F: 5′-GGAGGCTCCCTTTGTACC-3′
HAdV21-3-R: 5′-ACCGCCACGGAAGCTATG-3′
HAdV21-4-F: 5′-GCATGGCTGGCAGTGGTA-3′
HAdV21-4-R: 5′-TGCATCTGGGCAACAAAA-3′
HAdV21-5-F: 5′-TTTCCCAGGCTTTCAGTT-3′
HAdV21-5-R: 5′-CAAGGCAGTCAATCAGTTCTA-3′
HAdV21-6-F: 5′-AATGGCATTGTATTTATGG-3′
HAdV21-6-R: 5′-TTTAGACTTTGCTGTGGC-3′
HAdV21-7-F: 5′-TTGGACACGGAAGTAGACAG-3′
HAdV21-7-R: 5′-CTAGCAGCATAGAATCAGTAAA-3′
During MinION sequencing, Guppy embedded in MinKNOW (v3.3.2) performed the basecalling of raw signal event files to fastq reads. Reads with an average quality score ≥7 were labeled as “pass” files and were used for downstream analysis. Nanoplot (v1.22.0) (De Coster et al., 2018) was used to get an overview of the sequencing data including distributions of quality score and length. To calculate the percentages of reads belonging to the host, virus, bacteria, and archaea at the level of superkingdom, we employed Minimap2 (v2.16) (Li, 2018) and BLASTN (v2.8.1) to align the reads against reference genomes downloaded from National Center for Biotechnology Information (NCBI) RefSeq database as of March 21, 2019, including the human genome (Grch38.p12), virus genomes (n = 8,588), bacteria genomes (n = 12,668), and archaea genomes (n = 283). The parameters of Minimap2 in aligning to human and viral genomes were “-ax map-ont -k 15” and “-ax map-ont -k 7,” respectively. Samtools (v1.9) (Li, 2011) was used to handle the sam or bam files to extract aligned or unaligned reads for next-step alignment. Read depth across a reference genome was obtained by the “samtools depth” function.
Centrifuge (v1.0.4) (Kim et al., 2016) aligned the MinION reads to a database composed of human and viral reference genomes to obtain a preliminary summary of target viruses. Minimap2 and Samtools were then used to extract reads aligned to corresponding reference genomes. Canu (v1.8) (Koren et al., 2017) performed de novo assembly of selected reads to generate a draft genome sequence and Nanopolish (v0.11.0) (Loman et al., 2015) was then used to polish the draft sequence. Online BLASTN analysis was conducted to get the best hit of the draft genome sequence.
In order to investigate the minimal read number sufficient to identify present isolate, we downsampled the nanopore reads by randomly extracting reads at specific sequencing depths of 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500, 1,000, 5,000, 10,000, 15,000, 20,000, 25,000, 30,000, and 35,000 for 1,000 times. The reads were aligned to the MinION genome sequence by Minimap2, and the alignment statistics were summarized by using Samtools and Perl scripts.
Raw sequencing data were filtered with the following criteria: (1) reads having ≥40 bp with a quality score of less than 38 were removed; (2) reads having ≥10 N bases were removed; (3) reads having an overlap of ≥10 bp with adapters were removed; (4) reads aligning to human reference genome were removed. The clean data were then de novo assembled with SOAP denovo (v2.04) (Li et al., 2010) and SPAdes (Bankevich et al., 2012). CISA (Lin and Liao, 2013) was employed to integrate the contigs and scaffolds. The gaps in the scaffolds were filled with gapclose (v1.12).
The virtual REA was performed with CisSERS (Sharpe et al., 2016). Multiple genomes including the current genome, two independently reported HAdV21a genomes [HAdV21a LRTI-7 (GenBank accession no. KY307857.1) (Hage et al., 2014) and HAdV21a NHRC 10030 (KJ364586.1) (Kajon et al., 2015)], two independently reported HAdV21b genomes [HAdV21b OHT-006 (MF502426.1) (Philo et al., 2018), and HAdV21b NHRC 32389 (KJ364573.1) (Kajon et al., 2015)], and the HAdV21 prototype (KF528688.1) were selected as inputs. Four restriction enzymes BamHI, KpnI, XhoI, and PstI were chosen to recognize the restriction sites of each genome with default parameters. Gel images containing restriction sites and molecular weights were generated by CisSERS.
Hexon and fiber gene sequences of HAdV species B were first downloaded from NCBI, and repetitive sequences were then removed by USEARCH (V11.0.667).1 E4 sequences were extracted from the corresponding reference genomes. Multiple alignment was conducted using the ClustalW method in MEGA X (v10.0.5) (Kumar et al., 2018). Phylogenetic trees were then constructed by using the neighbor-joining algorithm with a bootstrap value of 1,000.
The multiple alignments of genome sequences of HAdV21p (KF528688.1), HAdV3 (AY599834.1), HAdV66 (JN860676.1), and current genome were performed using ClustalW method in MEGA X. The alignment file in fasta format was used as the input of bootscan analysis of SimPlot (V3.5.1)2 with the following parameters: window = 1,000 bp, step = 20 bp, GapStrip = on, reps = 500, distance model = Kimura, T/t = 2.0, and tree model = neighbor-joining. To detect a subtype-wide recombinant event related to E4 gene, multiple alignment of gene sequences belonging to all available HAdV21a, HAdV21b, and HAdV21p, as well as HAdV3, was performed.
After a ∼27.5 h run, MinION generated 55,135 reads, among which 35,466 (64.33%) passed quality control (average base quality = 9.8, mean read length = 997.6 bp, total length = 35,382,056 bp). The first read was produced after 6 s upon the initialization of the sequencing. The top five longest reads all had a length >34.1 kb (34,927, 34,775, 34,209, 34,208, and 34,141 bp, respectively). Preliminary taxonomic analysis revealed that 60.30% (n = 21,387) and 19.32% (n = 6,852) of reads could be aligned to human and viral genomes separately, with 2.61% of reads aligning to bacterial genomes and the rest (17.77%) defined as unclassified sequences.
As the universal PCR primers for HAdV rather than other respiratory pathogens were tested positive, we mainly focused on viral detection from the nanopore reads. A rapid taxonomic analysis revealed that the top four taxonomic ranks with the highest number of unique reads against the NCBI refseq genomes were Homo sapiens (Taxonomy ID = 9606), human adenovirus 7 (Taxonomy ID = 10519), human mastadenovirus B (Taxonomy ID = 108098), and simian adenovirus 21 (Taxonomy ID = 198503). As the three identified AdVs all belong to the AdV species B, we speculated that the target virus should have high homology with members from this species.
A total of 5,887 reads could be aligned to the genomes of the above three AdVs and were then de novo assembled into a draft sequence containing 35,180 bp. BLASTN analysis revealed that this sequence had 99.53% identity against HAdV21 strain CDC V2148A (GenBank accession no. KJ364588.1, length = 35,371 bp) with a 100% query coverage. Moreover, among the reads longer than 10 kb (n = 637), 20 kb (n = 115), and 30 kb (n = 21), 94.82, 94.78, and 95.24% of reads could be aligned to this strain with a genome coverage ≥73.10, 75.93, and 82.27%, respectively. We then extracted 5,999 reads aligned to this specific strain and obtained a draft genome containing 35,364 bp, with the read depth across the draft genome ranging from 65 X to 737 X (Supplementary Figure S1). Online BLASTN analysis showed that the draft sequence had the highest identity of 99.88% (query coverage = 100%) against five HAdV21a strains (GenBank accession no. KY307857.1, KF802425.1, KY307859.1, KF577598.1, KF577597.1). The corresponding reference genome coverages were separately 99.98, 99.98, 99.98, 99.98, and 99.97%. As expected, PCR targeting the HAdV21 hexon gene was tested positive. We finally named this isolate as HAdV21a isolate human/CHN/BB/201903/21.
We further investigated the minimal read number sufficient to identify this isolate via a downsampling procedure. With respect to reference genome coverage (Figure 1A), a sequencing depth of 5 would generate an average genome coverage of 7.83% (standard deviation = 13.05%). When the depth gradually increased from 10 to 400, the minimal genome coverage ranged from 0 to 92.43%. A minimum of 500 reads could cover at least 96.49% of the reference genome as the sequencing depth increased. Notably, if more than 5,000 reads were randomly selected each time, the genome coverage was always 100% (Supplementary Figure S2). When decoding the genome coverage in the view of aligned read length, a downsampling procedure owning aligned reads with a maximal read length ≥25kb always had a genome coverage of ≥69.10% regardless of the sampling depth (Figure 1B). When sequencing depth was set to 500, aligned reads with a maximal read length ≥25 or <25 kb, respectively, obtained a ≥99.31% or ≥96.49% genome coverage. Moreover, 16.93%, on average, ranging from 16.69 to 17.32% for each sequencing depth, of reads could be aligned to the reference. Regardless of the maximal aligned read length, larger or smaller than 25 kb, the hit ratios (number of aligned reads divided by the corresponding sequencing depth) fluctuated around but finally converged to 16.93% (Figure 1C), which is close to the actual hit ratio of 16.92% (6,002/35,466).
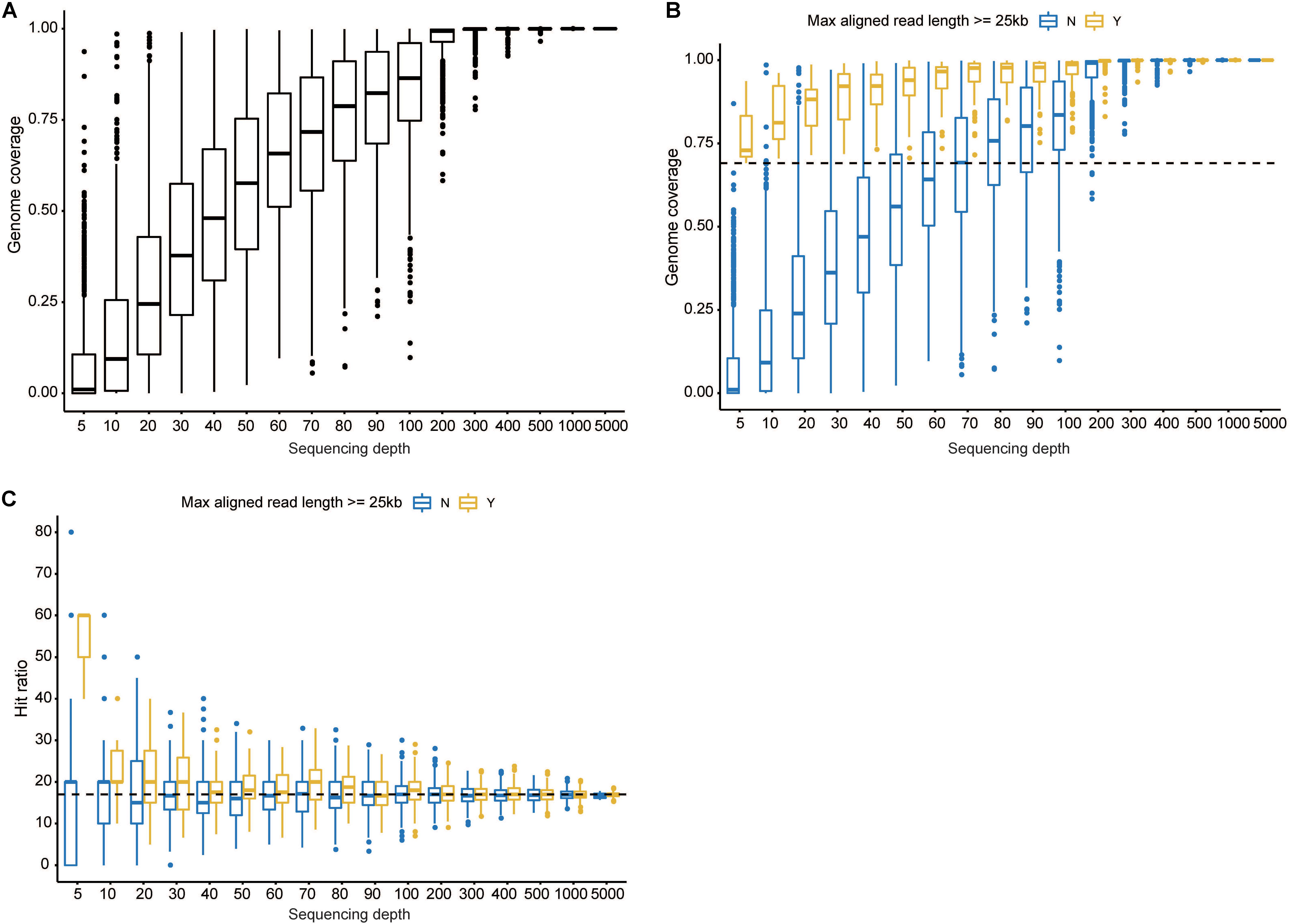
Figure 1. Investigation of the minimal read number to identify the current isolate. (A) The overall genome coverage distribution when 5–5,000 reads were randomly selected. The x axis denotes pseudosequencing depth, and the y axis, the corresponding genome coverages. (B) Genome coverage distribution decomposed by the maximal aligned read length. The dashed line corresponds to 69.10%. (C) Hit ratio distribution decomposed by the maximal aligned read length. The dashed line corresponds to 16.92%. “Y” represents read length being more than 25 kb, and “N” indicates less than 25 kb. Boxes represent the interquartile range (IQR) between the first and third quartiles (25th and 75th percentiles, respectively). Lines inside denote the median, and whiskers denote the most extreme values within 1.5 times IQR from the first and third quartiles. Outlier values are represented as points.
Illumina sequencing was further employed to de novo assemble the viral genome. After quality control, a total of 133,334 reads with a GC content of 44.04% were used for downstream assembly. One scaffold with a length of 35,369 bp was obtained. A total of 31 genomic discrepancies between MinION and Illumina sequencing were identified by both MEGA and dnadiff (Phillippy et al., 2008) programs (Table 1) and further validated and confirmed by PCR coupled with Sanger sequencing. Among these discrepancies, six ones were single-nucleotide polymorphisms (SNPs), and the rest belonged to insertion and deletions (indels). All the SNPs could be classified as base transitions. Notably, 19 of 25 indel loci in MinION data located next to homopolymeric regions composed of multiple adenines [poly(A)], thymines [poly(T)], guanines [poly(G)], or cytosines [poly(C)] (Supplementary Table S1). The dnadiff tool revealed that the pairwise nucleotide identity between the two draft sequences was 99.91%. Although sequencing errors still existed in the polished MinION genome, we are confident that the MinION output could achieve the goal of identifying pathogen at a comparable level. The corrected genome contained 35,369 bp with a GC content of 51.21%. The MinION read depth across the genome ranged from 44 X to 609 X, whereas the Illumina read depth ranged from 2 X to 125 X (Figure 2).
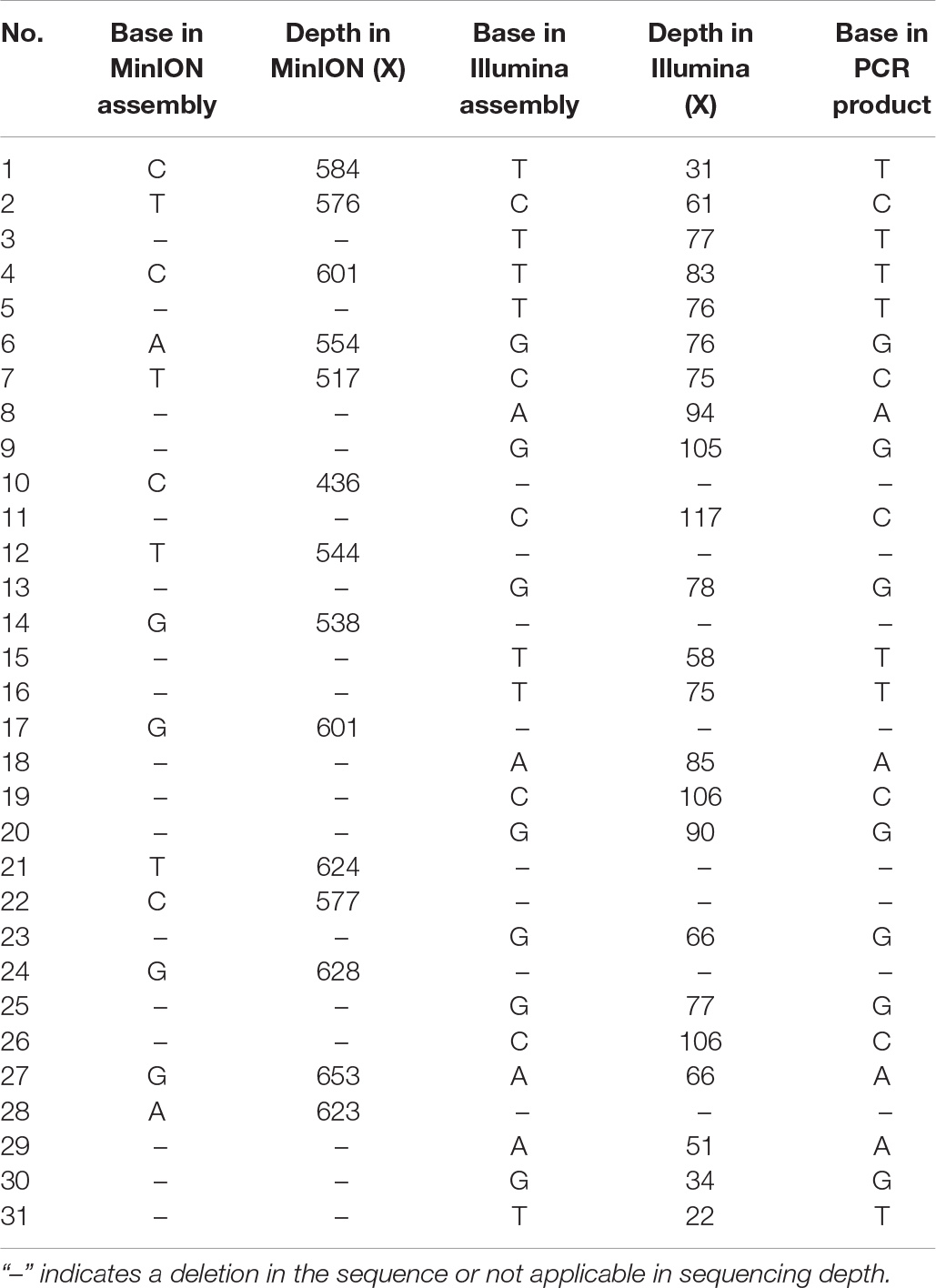
Table 1. Genomic discrepancies between MinION and Illumina sequencing.
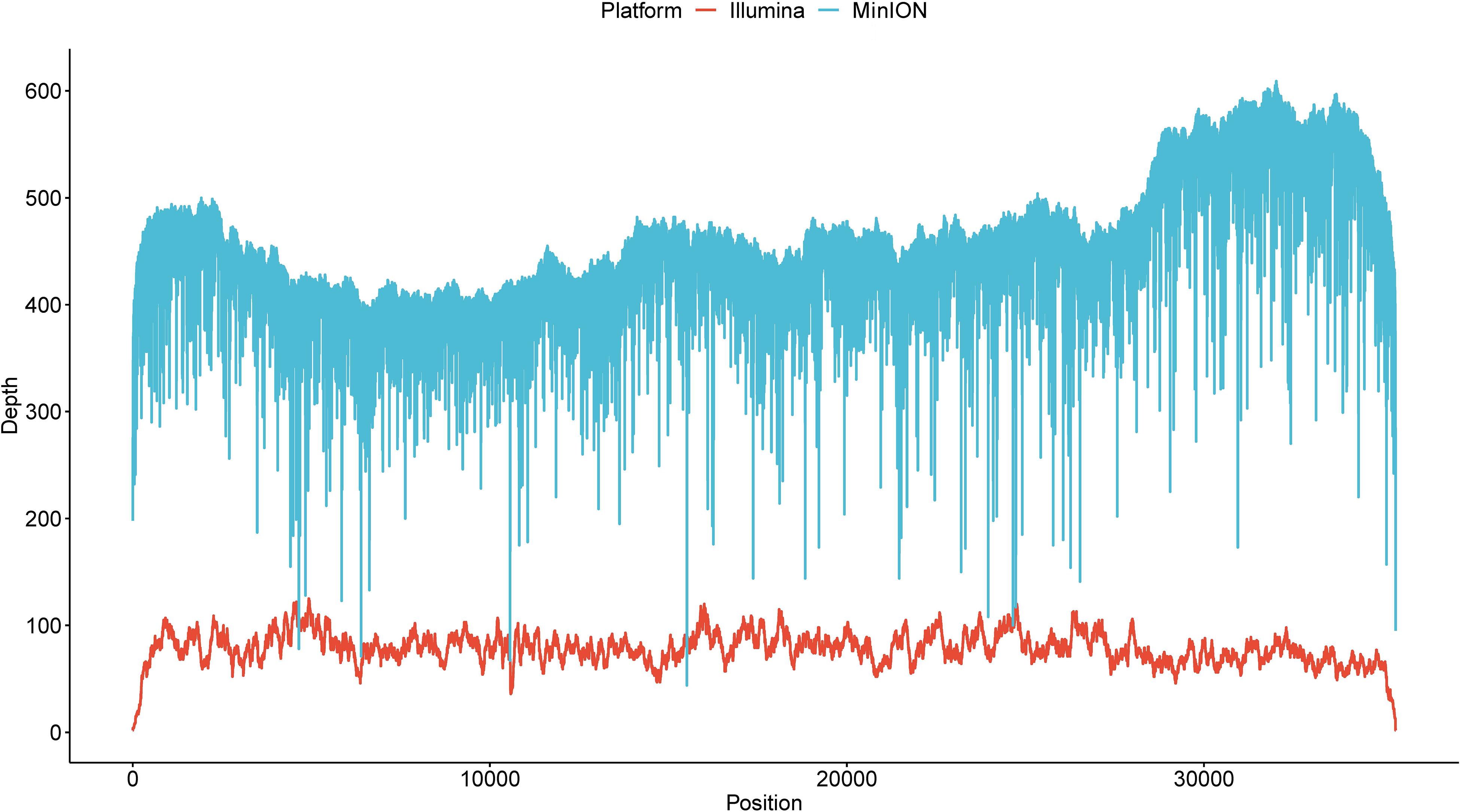
Figure 2. The read depth across the current genome by two sequencing platforms.
In order to conduct a genome type analysis of our HAdV21a genome, a tool named as CisSERS (Sharpe et al., 2016) that could perform in silico REA was used. REA using BamHI (Figure 3A) and KpnI (Figure 3B) identified our genome as a variant relative to the prototype and subtype 21b, the restriction band patterns of which were consistent with previous studies (Hage et al., 2014; Kajon et al., 2015). XhoI and PstI merely discriminated HAdV21 prototype from subtype 21a and 21b (Supplementary Figure S3).

Figure 3. Genomic characterization of the current isolate. (A,B) Genome type analysis using restriction enzyme BamHI (A) and KpnI (B). The numbers on the far left denote the molecular weight markers (bp). (C) Genomic annotation of the current isolate. Genes were displayed in gray, and CDSs discussed below in plum. “100 KDa protein” indicates the 100 kDa hexon-assembly associated protein.
A total of 13 genes were annotated from the genome sequence, all having ≥99.81% identities against the genes from reference genome KY307857.1 (Figure 3C). There were 48 coding sequences (CDSs) and 4 promoters located in these genes. The annotated hexon and fiber proteins that encode major neutralizing epitopes (Kajon et al., 2015) all had 100% identities with those of the reference KY307857.1.
Multiple alignment coupled with polymorphism analysis was further conducted. A G → T conversion occurred in the hypothetical protein (GenBank accession no. APT35313.1) encoded by the E2B gene, leading to a conversion of proline to threonine in the deduced amino acid sequence. When comparing the promoter region from position 10,562 to 10,597 in the current genome with other HAdV21s, we found two poly(T) regions that were highly varying in the number of T bases (the first poly(T) region: 13 Ts in current genome vs. 9–16 Ts in other references; the second poly(T) region: 4 Ts in current genome vs. 4–5 Ts in other references). A similar variation in poly(T) regions was also observed in the upstream region of CDS for a 52 kDa protein encoded in the L1 gene. One insertion of 6 bp and a 45 bp deletion were detected in the penton protein, and one 3 bp deletion and one 15 bp insertion were found in 100 kDa hexon assembly associated protein, which are shared features in subtype 21a (Hage et al., 2014) and 21b relative to the prototypes. Notably, some deletions and insertions occur in the intergeneric regions of CDSs; that is, an insertion of 6–12 bp (all As) between penton protein and protein VII precursor was detected in the present genome relative to all other references. Moreover, a deletion of 9 bp between protein VI precursor and hexon protein was found in comparisons of the current genome with the prototypes. Multiple polymorphisms were also discovered in the non-annotated 5′ region of the genome, such as a 1 bp deletion at position 242 and a conversion of C to T at position 252, the effects of which on viral life need further investigation.
Phylogenetic trees were constructed with hexon, fiber, and full genome sequences. Hexon- and fiber-based trees revealed that the current genome clustered with members from HAdV21a and 21b (Supplementary Figures S4, S5). In addition, the phylogenetic relationship between HAdV50 and HAdV21 was closer than with other subtypes. Phylogenetic trees via full-length genome sequences showed that the current sequence was placed within a clade composed of members from subtype 21a (Figure 4). The three subtypes, 21a, 21b, and 21p, were clearly separated. The prototype of HAdV50 was again observed to cluster with HAdV21.
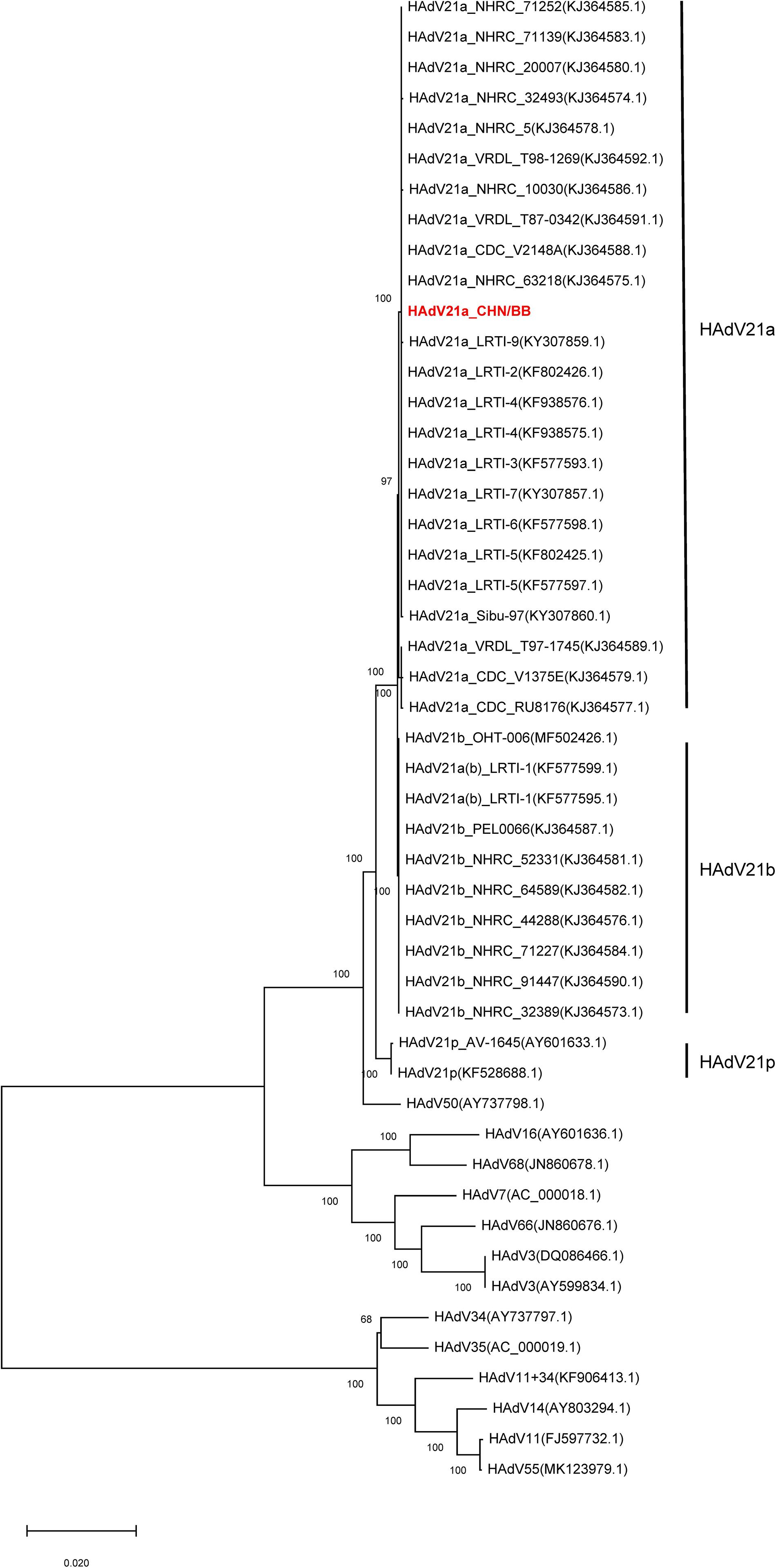
Figure 4. Phylogenetic tree constructed via whole-genome sequences. All available HAdV21 and other human mastadenovirus B genomes were used. The sequence displayed in red represents the current isolate.
We detected a recombinant event approximately starting from position 33,260 in the present HAdV21a genome that indicated a recombinant E4 gene originating from the HAdV3 prototype (Figure 5). BLASTN analysis revealed an identity of 99.54% between E4 genes from the current isolate and the HAdV3 prototype, which decreased to a range of 93.85–98.88% when it was aligned to E4 region from other non-HAdV3 members. A phylogenetic tree constructed based on the E4 gene sequences also revealed that all the strains in subtype 21a clustered with HAdV3 (Supplementary Figure S6). BLASTN identities of all available HAdV21a E4 genes against the HAdV3 E4 gene ranged from 99.42 to 99.57%, which were higher than those of HAdV21p against HAdV3 (98.64%). Thus, the recombinant E4 region in HAdV21a strains should be a common feature that has never been reported before.
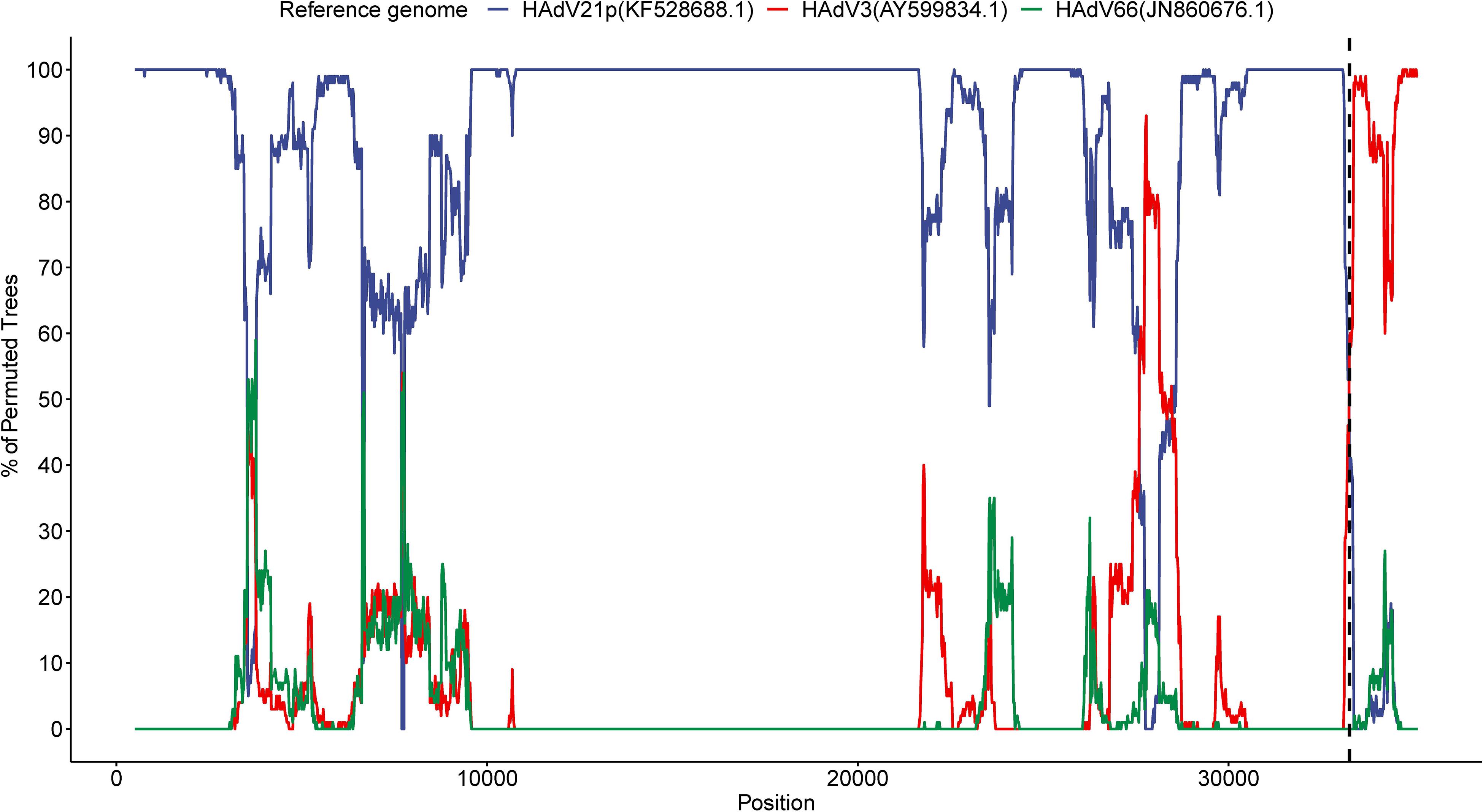
Figure 5. Bootscan analysis based on multiple alignment of the current isolate, HAdV3, HAdV21p, and HAdV66 genomes. The current genome was selected as the query sequence, whereas the rest were references. The dashed line represents the approximate position 33,260 in the present genome.
In this study, we report the first identification of HAdV21a in China via MinION and Illumina sequencers. This isolate contains 35,369 bp in the genome, encoding 13 genes and 48 CDSs. Genome type analysis in silico revealed that the present isolate could be distinguished from the prototype and subtype 21b. BLASTN and phylogenetic trees also confirmed this isolate belongs to subtype 21a. We further identified common features shared by HAdV21a members, such as insertions and deletions discovered in penton and 100 kDa hexon assembly associated proteins and a recombinant event in the E4 gene, when compared with other HAdVs.
Nanopore sequencing technology has an advantage of extremely long-read output (>2.3 Mb according to ONT website) over current NGS platforms. This characteristic has promoted rapid identification of pathogens in the field (McIntyre et al., 2016; Castro-Wallace et al., 2017; Johnson et al., 2017; Edwards et al., 2019), especially for bacteria and viruses. Human adenoviruses usually have 35–36 kb in their genomes, which could be captured and covered by ONT with a single read. There were 21 MinION reads longer than 30 kb, 20 of which could be identified as HAdV21a with a genome coverage ≥82.27%. These reads were produced in 54 min to ∼15.5 h after the start of sequencing, with eight (40%) generated in ≤2.5 h. This demonstrated the feasibility of nanopore technology in the rapid detection of HAdV, thus providing key information for disease control and treatment.
Oxford Nanopore Technologies is hindered by its high sequencing error rate (10–15%). We observed 31 discrepancies between MinION and Illumina sequencing. Although indels and substitutions are frequent in nanopore data, there might be other factors involved in these discrepancies, that is, the read correction, read assembly, and genome polishing methods (Loman et al., 2015; Koren et al., 2017; Xiao et al., 2017), in addition to potential sequencing errors, which needs further investigation. Base modifications have been reported in human, prokaryotes, and viruses (Gokhale and Horner, 2017; Xiao et al., 2018), some of which could be detected by ONT (Simpson et al., 2017; Liu et al., 2019). Thus, base modifications may also contribute to genomic discrepancies (Greig et al., 2019). Illumina platforms usually have very low sequencing errors, however, they are characterized by a relatively complex sample preparation procedure, a relatively long sequencing time, and high-performance computing equipment for downstream analyses, which therefore limits the field application of these platforms under non-laboratory conditions. Considering that the pairwise nucleotide identity between MinION and Illumina sequences was 99.91% in our study, we believe that MinION correctly identified the pathogen despite sequencing errors. With the release of a new version of flow cell, ONT sequencing errors should dramatically decrease in the future.
Because of the long-read output by MinION, a minimum of 500 reads covered ≥96.49% of the present genome. This implied that under resource-limited conditions we could attempt to terminate the sequencing run ahead of time. It was observed that a downsampling procedure with maximal aligned read length ≥25 kb could cover ≥69.10% of the genome. As most reads longer than 20 kb could be identified as part of the current genome, we deemed reads with a length of 25 kb were able to reach a genome coverage of 70.82% (25/35.3) regardless of sequencing errors.
We observed varying numbers of T bases in poly(T) regions upstream of the 52 kDa protein CDS in the current isolate when comparing to other references. Deletions and insertions occurred in the intergeneric regions of CDSs and non-annotated 5′ region of the genome, the effects of which require further investigation. Polymorphisms in penton and 100 kDa hexon assembly–associated proteins were discovered in all 21a and 21b relative to the prototypes, which have partially been reported in a previous study (Hage et al., 2014). We did not observe polymorphisms in the remaining proteins, indicating that high conservation exists in most proteins of HAdV21a.
Another common feature shared by HAdV21a members is the recombinant E4 gene originating from HAdV3. Products of the E4 gene could regulate cellular functions and participate in viral DNA replication and RNA processing (Weitzman, 2005). Both phylogenetic and homology analyses provided credible evidence for this recombinant event. When this recombinant gene occurred in HAdV21a remains to be elucidated. It has been noted that highly virulent HAdV21a could cause severe pneumonia, acute respiratory disease, and even death (Hage et al., 2014). However, in our study, the patient had only slight symptoms of respiratory tract infection and recovered in 1 week, implying differential susceptibility of populations and individuals. The difference in virulence might lie in polymorphisms discovered merely in the present isolate.
In China, epidemic HAdV subtypes usually contain HAdV1, 3, 4, 7, 11, 14, and 55 rather than HAdV21. Our study indicates that HAdV21a infection cannot be neglected, although it is rarely reported. The pathogen has caused severe pneumonia and acute respiratory distress syndrome in several regions, thus indicating the need to avoid severe cases in China. Epidemiological profiles of HAdV21 subtypes in China should also be investigated with state-of-the-art technologies.
All sequence data have been submitted to Sequence Read Archive of NCBI with an accession number PRJNA587860. The data are also available upon request. The genome sequence of present isolate has been deposited in NCBI GenBank with accession number MN686206.
The patient provided written informed consent upon enrollment. The study conformed to the ethical guidelines of the 1975 Declaration of Helsinki and was approved by the Institutional Review Board of the Center for Disease Control and Prevention of Eastern Theater Command.
CHW and JHZ conceived and designed the study. YH, HL, and QZ collected samples and patient information. YH, JJZ, and YL conducted the experiments. FY, YH, and CJW generated sequencing data. FY, PL, and TW analyzed and interpreted the data. FY and JJZ wrote the manuscript with contributions from all other authors. All authors reviewed and approved the final manuscript.
This work was supported by Major National Science and Technology Projects (Grant Nos. 2017ZX10303401, 2018ZX10713003, and AWS16J020) and the National Natural Science Foundation of China (Grant Nos. 31701158 and 81602325). The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2020.00285/full#supplementary-material
FIGURE S1 | Read depth across the MinION draft genome sequence.
FIGURE S2 | Genome coverage corresponding to each downsampling procedure.
FIGURE S3 | Genome type analysis using restriction enzyme XhoI (A) and PstI (B). The numbers on the far left denote the molecular weight marker (bp).
FIGURE S4 | Phylogenetic tree constructed via hexon gene sequences. The sequence displayed in red represents current isolate.
FIGURE S5 | Phylogenetic tree constructed via fiber gene sequences. The sequence displayed in red represents current isolate.
FIGURE S6 | Phylogenetic tree constructed via E4 gene sequences. The sequence displayed in red represents current isolate.
TABLE S1 | Homopolymer sequences upstream of indel loci.
Ameur, A., Kloosterman, W. P., and Hestand, M. S. (2019). Single-molecule sequencing: towards clinical applications. Trends Biotechnol. 37, 72–85. doi: 10.1016/j.tibtech.2018.07.013
Bankevich, A., Nurk, S., Antipov, D., Gurevich, A. A., Dvorkin, M., Kulikov, A. S., et al. (2012). SPAdes: a new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 19, 455–477. doi: 10.1089/cmb.2012.0021
Barnadas, C., Schmidt, D. J., Fischer, T. K., and Fonager, J. (2018). Molecular epidemiology of human adenovirus infections in Denmark, 2011–2016. J. Clin. Virol, 104, 16–22. doi: 10.1016/j.jcv.2018.04.012
Barrero, P. R., Valinotto, L. E., Tittarelli, E., and Mistchenko, A. S. (2012). Molecular typing of adenoviruses in pediatric respiratory infections in Buenos Aires, Argentina (1999–2010). J. Clin. Virol. 53, 145–150. doi: 10.1016/j.jcv.2011.11.001
Bautista-Gogel, J., Madsen, C. M., Lu, X., Sakthivel, S. K., Froh, I., Kamau, E., et al. (2019). Outbreak of respiratory illness associated with human adenovirus type 7 among persons attending officer candidates school, Quantico, Virginia, 2017. J. Infect. Dis. 221, 697–700. doi: 10.1093/infdis/jiz060
Castro-Wallace, S. L., Chiu, C. Y., John, K. K., Stahl, S. E., Rubins, K. H., McIntyre, A. B. R., et al. (2017). Nanopore DNA sequencing and genome assembly on the international space station. Sci Rep 7:18022. doi: 10.1038/s41598-017-18364-0
De Coster, W., D’Hert, S., Schultz, D. T., Cruts, M., and Van Broeckhoven, C. (2018). NanoPack: visualizing and processing long-read sequencing data. Bioinformatics 34, 2666–2669. doi: 10.1093/bioinformatics/bty149
Edwards, A., Debbonaire, A. R., Nicholls, S. M., Rassner, S. M., Sattler, B., Cook, J. M., et al. (2019). In-field metagenome and 16S rRNA gene amplicon nanopore sequencing robustly characterize glacier microbiota. bioRxiv [Preprint], doi: 10.1101/073965
Faria, N. R., Kraemer, M. U. G., Hill, S. C., Goes de Jesus, J., Aguiar, R. S., Iani, F. C. M., et al. (2018). Genomic and epidemiological monitoring of yellow fever virus transmission potential. Science 361, 894–899. doi: 10.1126/science.aat7115
Faria, N. R., Quick, J., Claro, I. M., Theze, J., de Jesus, J. G., Giovanetti, M., et al. (2017). Establishment and cryptic transmission of Zika virus in Brazil and the Americas. Nature 546, 406–410. doi: 10.1038/nature22401
Gokhale, N. S., and Horner, S. M. (2017). RNA modifications go viral. PLoS Pathog. 13:e1006188. doi: 10.1371/journal.ppat.1006188
Greig, D. R., Jenkins, C., Gharbia, S., and Dallman, T. J. (2019). Comparison of single-nucleotide variants identified by Illumina and Oxford Nanopore technologies in the context of a potential outbreak of Shiga toxin-producing Escherichia coli. Gigascience 8:giz104. doi: 10.1093/gigascience/giz104
Hage, E., Huzly, D., Ganzenmueller, T., Beck, R., Schulz, T. F., and Heim, A. (2014). A human adenovirus species B subtype 21a associated with severe pneumonia. J. Infect. 69, 490–499. doi: 10.1016/j.jinf.2014.06.015
Imai, K., Tamura, K., Tanigaki, T., Takizawa, M., Nakayama, E., Taniguchi, T., et al. (2018). Whole genome sequencing of influenza a and b viruses with the MinION sequencer in the clinical setting: a pilot study. Front. Microbiol. 9:2748. doi: 10.3389/fmicb.2018.02748
Ison, M. G. (2006). Adenovirus infections in transplant recipients. Clin. Infect. Dis. 43, 331–339. doi: 10.1086/505498
Johnson, S. S., Zaikova, E., Goerlitz, D. S., Bai, Y., and Tighe, S. W. (2017). Real-time DNA sequencing in the antarctic dry valleys using the oxford nanopore sequencer. J. Biomol. Tech. 28, 2–7. doi: 10.7171/jbt.17-2801-009
Kafetzopoulou, L. E., Pullan, S. T., Lemey, P., Suchard, M. A., Ehichioya, D. U., Pahlmann, M., et al. (2019). Metagenomic sequencing at the epicenter of the Nigeria 2018 Lassa fever outbreak. Science 363, 74–77. doi: 10.1126/science.aau9343
Kajon, A. E., Dickson, L. M., Metzgar, D., Houng, H. S., Lee, V., and Tan, B. H. (2010). Outbreak of febrile respiratory illness associated with adenovirus 11a infection in a Singapore military training cAMP. J. Clin. Microbiol. 48, 1438–1441. doi: 10.1128/JCM.01928-09
Kajon, A. E., Hang, J., Hawksworth, A., Metzgar, D., Hage, E., Hansen, C. J., et al. (2015). Molecular epidemiology of adenovirus type 21 respiratory strains isolated from us military trainees (1996–2014). J. Infect. Dis. 212, 871–880. doi: 10.1093/infdis/jiv141
Kandel, R., Srinivasan, A., D’Agata, E. M., Lu, X., Erdman, D., and Jhung, M. (2010). Outbreak of adenovirus type 4 infection in a long-term care facility for the elderly. Infect. Control Hosp. Epidemiol. 31, 755–757. doi: 10.1086/653612
Kim, D., Song, L., Breitwieser, F. P., and Salzberg, S. L. (2016). Centrifuge: rapid and sensitive classification of metagenomic sequences. Genome Res. 26, 1721–1729. doi: 10.1101/gr.210641.116
Koren, S., Walenz, B. P., Berlin, K., Miller, J. R., Bergman, N. H., and Phillippy, A. M. (2017). Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 27, 722–736. doi: 10.1101/gr.215087.116
Kumar, S., Stecher, G., Li, M., Knyaz, C., and Tamura, K. (2018). MEGA X: molecular evolutionary genetics analysis across computing platforms. Mol. Biol. Evol. 35, 1547–1549. doi: 10.1093/molbev/msy096
Lee, J., Choi, E. H., and Lee, H. J. (2010). Clinical severity of respiratory adenoviral infection by serotypes in Korean children over 17 consecutive years (1991–2007). J. Clin. Virol. 49, 115–120. doi: 10.1016/j.jcv.2010.07.007
Lenaerts, L., De Clercq, E., and Naesens, L. (2008). Clinical features and treatment of adenovirus infections. Rev. Med. Virol. 18, 357–374. doi: 10.1002/rmv.589
Lewis, P. F., Schmidt, M. A., Lu, X., Erdman, D. D., Campbell, M., Thomas, A., et al. (2009). A community-based outbreak of severe respiratory illness caused by human adenovirus serotype 14. J. Infect. Dis. 199, 1427–1434. doi: 10.1086/598521
Li, H. (2011). A statistical framework for SNP calling, mutation discovery, association mapping and population genetical parameter estimation from sequencing data. Bioinformatics 27, 2987–2993. doi: 10.1093/bioinformatics/btr509
Li, H. (2018). Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics 34, 3094–3100. doi: 10.1093/bioinformatics/bty191
Li, R., Zhu, H., Ruan, J., Qian, W., Fang, X., Shi, Z., et al. (2010). De novo assembly of human genomes with massively parallel short read sequencing. Genome Res. 20, 265–272. doi: 10.1101/gr.097261.109
Li, X., Kong, M., Su, X., Zou, M., Guo, L., Dong, X., et al. (2014). An outbreak of acute respiratory disease in China caused by human adenovirus type B55 in a physical training facility. Int. J. Infect. Dis. 28, 117–122. doi: 10.1016/j.ijid.2014.06.019
Lin, S. H., and Liao, Y. C. (2013). CISA: contig integrator for sequence assembly of bacterial genomes. PLoS One 8:e60843. doi: 10.1371/journal.pone.0060843
Lion, T. (2014). Adenovirus infections in immunocompetent and immunocompromised patients. Clin. Microbiol. Rev. 27, 441–462. doi: 10.1128/CMR.00116-13
Liu, Q., Fang, L., Yu, G. L., Wang, D. P., Xiao, C. L., and Wang, K. (2019). Detection of DNA base modifications by deep recurrent neural network on Oxford Nanopore sequencing data. Nat. Commun. 10:2449. doi: 10.1038/S41467-019-10168-2
Loman, N. J., Quick, J., and Simpson, J. T. (2015). A complete bacterial genome assembled de novo using only nanopore sequencing data. Nat. Methods 12, 733–735. doi: 10.1038/nmeth.3444
McIntyre, A. B. R., Rizzardi, L., Yu, A. M., Alexander, N., Rosen, G. L., Botkin, D. J., et al. (2016). Nanopore sequencing in microgravity. NPJ Micrograv. 2, 16035. doi: 10.1038/npjmgrav.2016.35
Pfortmueller, C. A., Barbani, M. T., Schefold, J. C., Hage, E., Heim, A., and Zimmerli, S. (2019). Severe acute respiratory distress syndrome (ARDS) induced by human adenovirus B21: report on 2 cases and literature review. J. Crit. Care 51, 99–104. doi: 10.1016/j.jcrc.2019.02.019
Phillippy, A. M., Schatz, M. C., and Pop, M. (2008). Genome assembly forensics: finding the elusive mis-assembly. Genome Biol. 9:R55. doi: 10.1186/gb-2008-9-3-r55
Philo, S. E., Anderson, B. D., Costa, S. F., Henshaw, N., Lewis, S. S., Reynolds, J. M., et al. (2018). Adenovirus type 21 outbreak among lung transplant patients at a large tertiary care hospital. Open Forum Infect. Dis. 5:ofy188. doi: 10.1093/ofid/ofy188
Prusinkiewicz, M. A., and Mymryk, J. S. (2019). metabolic reprogramming of the host cell by human adenovirus infection. Viruses 11:141. doi: 10.3390/v11020141
Quick, J., Grubaugh, N. D., Pullan, S. T., Claro, I. M., Smith, A. D., Gangavarapu, K., et al. (2017). Multiplex PCR method for MinION and Illumina sequencing of Zika and other virus genomes directly from clinical samples. Nat. Protoc. 12, 1261–1276. doi: 10.1038/nprot.2017.066
Quick, J., Loman, N. J., Duraffour, S., Simpson, J. T., Severi, E., Cowley, L., et al. (2016). Real-time, portable genome sequencing for Ebola surveillance. Nature 530, 228–232. doi: 10.1038/nature16996
Radke, J. R., and Cook, J. L. (2018). Human adenovirus infections: update and consideration of mechanisms of viral persistence. Curr. Opin. Infect. Dis. 31, 251–256. doi: 10.1097/QCO.0000000000000451
Rowe, W. P., Huebner, R. J., Gilmore, L. K., Parrott, R. H., and Ward, T. G. (1953). Isolation of a cytopathogenic agent from human adenoids undergoing spontaneous degeneration in tissue culture. Proc. Soc. Exp. Biol. Med. 84, 570–573. doi: 10.3181/00379727-84-20714
Sammons, J. S., Graf, E. H., Townsend, S., Hoegg, C. L., Smathers, S. A., Coffin, S. E., et al. (2019). Outbreak of adenovirus in a neonatal intensive care unit: critical importance of equipment cleaning during inpatient ophthalmologic examinations. Ophthalmology 126, 137–143. doi: 10.1016/j.ophtha.2018.07.008
Scott, M. K., Chommanard, C., Lu, X., Appelgate, D., Grenz, L., Schneider, E., et al. (2016). Human adenovirus associated with severe respiratory infection, Oregon, USA, 2013–2014. Emerg. Infect. Dis. 22, 1044–1051. doi: 10.3201/eid2206.151898
Sharpe, R. M., Koepke, T., Harper, A., Grimes, J., Galli, M., Satoh-Cruz, M., et al. (2016). CisSERS: customizable in silico sequence evaluation for restriction sites. PLoS One 11:e0152404. doi: 10.1371/journal.pone.0152404
Simpson, J. T., Workman, R. E., Zuzarte, P. C., David, M., Dursi, L. J., and Timp, W. (2017). Detecting DNA cytosine methylation using nanopore sequencing. Nat. Methods 14, 407. doi: 10.1038/nmeth.4184
van Dijk, E. L., Jaszczyszyn, Y., Naquin, D., and Thermes, C. (2018). The third revolution in sequencing technology. Trends Genet. 34, 666–681. doi: 10.1016/j.tig.2018.05.008
Wang, J., Ke, Y. H., Zhang, Y., Huang, K. Q., Wang, L., Shen, X. X., et al. (2017). Rapid and accurate sequencing of enterovirus genomes using MinION nanopore sequencer. Biomed. Environ. Sci. 30, 718–726. doi: 10.3967/bes2017.097
Weitzman, M. D. (2005). Functions of the adenovirus E4 proteins and their impact on viral vectors. Front. Biosci. 10:1106. doi: 10.2741/1604
Xiao, C. L., Chen, Y., Xie, S. Q., Chen, K. N., Wang, Y., Han, Y., et al. (2017). MECAT : fast mapping, error correction, and de novo assembly for single-molecule sequencing reads. Nat. Methods 14:1072. doi: 10.1038/Nmeth.4432
Xiao, C. L., Zhu, S., He, M. H., Chen, D., Zhang, Q., Chen, Y., et al. (2018). N-6-methyladenine DNA modification in the human genome. Mol. Cell 71:306. doi: 10.1016/j.molcel.2018.06.015
Xu, Y., Lewandowski, K., Lumley, S., Pullan, S., Vipond, R., Carroll, M., et al. (2018). Detection of viral pathogens with multiplex nanopore MinION sequencing: be careful with cross-talk. Front. Microbiol. 9:2225. doi: 10.3389/fmicb.2018.02225
Yao, L. H., Wang, C., Wei, T. L., Wang, H., Ma, F. L., and Zheng, L. S. (2019). Human adenovirus among hospitalized children with respiratory tract infections in Beijing China, 2017–2018. Virol. J. 16:78. doi: 10.1186/s12985-019-1185-x
Keywords: human adenovirus subtype 21a, adenovirus infection, pathogen detection, MinION sequencing, Illumina sequencing
Citation: Ye F, Han Y, Zhu J, Li P, Zhang Q, Lin Y, Wang T, Lv H, Wang C, Wang C and Zhang J (2020) First Identification of Human Adenovirus Subtype 21a in China With MinION and Illumina Sequencers. Front. Genet. 11:285. doi: 10.3389/fgene.2020.00285
Received: 27 November 2019; Accepted: 09 March 2020;
Published: 07 April 2020.
Edited by:
Chuan-Le Xiao, Sun Yat-sen University, ChinaCopyright © 2020 Ye, Han, Zhu, Li, Zhang, Lin, Wang, Lv, Wang, Wang and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chunhui Wang, dG9tbWk0MTRAMTM5LmNvbQ==; Jinhai Zhang, YWhvaUAxNjMuY29t
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.