 Qiaoyu Tan
Qiaoyu Tan Ninghao Liu
Ninghao Liu Xia Hu
Xia Hu- Department of Computer Science and Engineering, Texas A&M University, College Station, TX, United States
Social network analysis is an important problem in data mining. A fundamental step for analyzing social networks is to encode network data into low-dimensional representations, i.e., network embeddings, so that the network topology structure and other attribute information can be effectively preserved. Network representation leaning facilitates further applications such as classification, link prediction, anomaly detection, and clustering. In addition, techniques based on deep neural networks have attracted great interests over the past a few years. In this survey, we conduct a comprehensive review of the current literature in network representation learning, utilizing neural network models. First, we introduce the basic models for learning node representations in homogeneous networks. We will also introduce some extensions of the base models, tackling more complex scenarios such as analyzing attributed networks, heterogeneous networks, and dynamic networks. We then introduce techniques for embedding subgraphs and also present the applications of network representation learning. Finally, we discuss some promising research directions for future work.
1. Introduction
Social networks, such as Facebook, Twitter, and LinkedIn, have greatly facilitated communication between web users around the world. The analysis of social networks helps summarizing the interests and opinions of users (nodes), discovering patterns from the interactions (links) between users, and mining the events that take place in online platforms. The information obtained by analyzing social networks could be especially valuable for many applications. Some typical examples include online advertisement targeting (Li et al., 2015), personalized recommendation (Song et al., 2006), viral marketing (Leskovec et al., 2007; Chen et al., 2010), social healthcare (Tang and Yang, 2012), social influence analysis (Peng et al., 2017), and academic network analysis (Dietz et al., 2007; Guo et al., 2014).
One central problem in social network analysis is how to extract useful features from non-Euclidean structured networks, to enable the deployment of downstream machine learning prediction models for specific analysis. For example, in the case of recommending new friends to a user in a social network, the key challenge might be how to embed network users into a low-dimensional space so that the closeness between users could be easily measured with distance metrics. To process structure information in networks, most previous efforts mainly rely on hand-crafted features, such as kernel functions (Vishwanathan et al., 2010), graph statistics (i.e., degrees or clustering coefficients) (Bhagat et al., 2011), or other carefully engineered features (Liben-Nowell and Kleinberg, 2007). However, such feature engineering processes could be very time-consuming and expensive, rendering it ineffective for many real-world applications. An alternative way to avoid this limitation, is to automatically learn feature representations that capture various information sources in networks (Bengio et al., 2013; Liao et al., 2018). The goal is to learn a transformation function that maps nodes, subgraphs, or even the whole network as vectors to a low-dimensional feature space, where the spatial relations between the vectors reflect the structures or contents in the original network. Given these feature vectors, subsequent machine learning models such as classification models, clustering models and outlier detection models could be directly used toward target applications.
Along with the substantial performance improvement gained by deep learning on image recognition, text mining, and natural language processing tasks (Bengio, 2009), developing network representation methods using neural network models have received increased attention in recent years. In this review, we provide a comprehensive overview of recent advancements in network representation learning, using neural network models. After introducing the notations and problem definitions, we first review the basic representation learning models for node embedding in homogeneous networks. Specifically, based on the type of representation generation modules, we divide the existing approaches into three categories: embedding look-up based, autoencoder based and graph convolution based. We then provide an overview of the approaches that learn representations for subgraphs in networks, which to some extent rely on the techniques of node representation learning. After that, we list some applications of network representation models. Finally, we discuss some promising research directions for future work.
2. Notations and Problem Definitions
In this section, we define some important terminologies that will be used in later sections, and then provide the formal definition of the network representation learning problem. In general, we use boldface uppercase letters (e.g., A) to denote matrices, boldface lowercase letters (e.g., a) to denote vectors, and lowercase letters (e.g., a) to denote scalars. The (i, j) entry, the i-th row and the j-th column of a matrix A is denoted as Aij, Ai*, and A*j, respectively.
Definition 1 (Network). Let be a network, where the i-th node (or vertex) is denoted as and denotes the edge between node vi and vj. X and Y are node attributes and labels, if available. Besides, we let A ∈ ℝN×N denote the associated adjacency matrix of . Aij is the weight of ei, j, where Aij > 0 indicates that the two nodes are connected, and otherwise Aij = 0. For undirected graphs, Aij = Aji.
In many scenarios, the nodes and edges in can also be associated with the type information. Let be a node-type mapping function and be an edge-type mapping function, where Tv and Te denote the set of node and edge types, respectively. Here, each node has one specific type, e.g., . Similarly, for each edge eij, .
Definition 2 (Homogeneous Network). A homogeneous network is a network in which |Tv| = |Te| = 1. All nodes and edges in G belong to one single type.
Definition 3 (Heterogeneous Network). A heterogeneous network is a network with |Tv| + |Te| > 2. There are at least two different types of nodes or edges in heterogeneous networks.
Given a network , the task of network representation learning is to train a mapping function f that maps certain components in , such as nodes or subgraphs, into a latent space. Let D be the dimension of the latent space and usually . In this work, we focus on the problem of node representation learning and subgraph representation learning.
Definition 4 (Node Representation Learning). Suppose z ∈ ℝD denotes the latent vector of node v, node representation learning aims to build a mapping function f so that z = f(v). It is expected that nodes with similar roles or characteristics, which are defined according to specific application domains, are mapped close to each other in the latent space.
Definition 5 (Subgraph Representation Learning). Let g denote a subgraph of . The nodes and edges in g are denoted as and , respectively, and we have and . The subgraph representation learning aims to learn a mapping function f so that z = f(g), where in this case z ∈ ℝD corresponds to the latent vector of g.
Figure 1 shows a toy example of network embedding. There are three subgraphs in this network distinguished with different colors: , , and . Given a network as input, the example below generates one representation for each node, as well as for each of the three subgraphs.
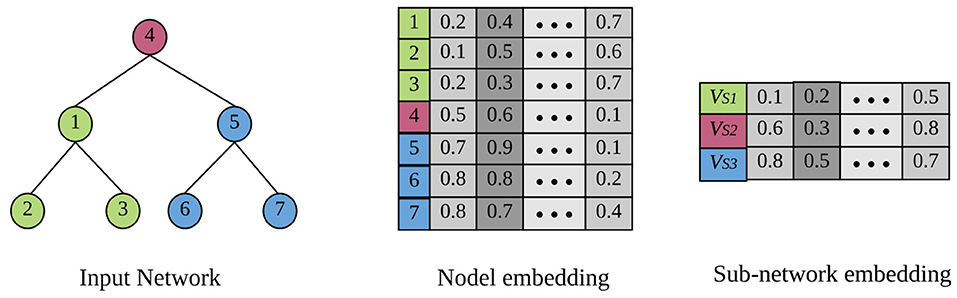
Figure 1. A toy example of node representation learning and subgraph representation learning (best viewed in color). There are three subgraphs in the input network denoted by different colors. The target of node embedding is to generate one representation for each individual node, while subgraph embedding is to learn one representation for an entire subgraph.
3. Neural Network Based Models
It has been demonstrated that neural networks have powerful capabilities in capturing complex patterns in data, and have achieved substantial success in the fields of computer vision, audio recognition, and natural language processing, etc. Recently, some efforts have been made to extend neural network models to learn representations from network data. Based on the type of base neural networks that are applied, we categorize them into three subgroups: look-up table based models, autoencoder based models, and GCN based models. In this section, we first give an overview of network representation learning from the perspective of encoding and decoding. We then discuss the details of some well-known network embedding models and how they fulfill the two steps. In this section, we only discuss representation learning for nodes. The models dealing with subgraphs will be introduced in later sections.
3.1. Framework Overview From the Encoder-Decoder Perspective
In order to elaborate the diversity of various neural network architectures, we argue that different techniques can be derived from the aspect of encoding and decoding schema, as well as their target network structure constrained for low dimensional feature space. Specifically, existing methods can be reduced to solving the following optimization problem:
where Φtar is the target relations that the embedding algorithm expects to preserve, and denotes the nodes involved in ϕ. is the encoding function that maps nodes into representation vectors, and ψdec is a decoding function that reconstructs the original network structure from the representation space. Ψ denotes the trainable parameters in encoders and decoders. By minimizing the loss function above, model parameters are trained so that the desired network structures Ψtar are preserved. As we will show in subsequent sections, from the overview framework aspect, the primary distinctions between various network representation methods rely on how they define the three components.
3.2. Models With Embedding Look-Up Tables
Instead of using multiple layers of nonlinear transformations, network representation learning could be achieved simply by using look-up tables which directly map a node index into its corresponding representation vector. Specifically, a look-up table could be implemented using a matrix, where each row corresponds to the representation of one node. The diversity of different models mainly lies in the definition of target relations in the network data that we hope to preserve. In the rest of this subsection, we will first introduce DeepWalk (Perozzi et al., 2014) to discuss the basic concepts and techniques in network embedding, and then extend the discussion to more complex and practical scenarios.
3.2.1. Skip-Gram Based Models
As a pioneering network representation model, DeepWalk treats nodes as words, samples random walks as sentences and utilizes the skip-gram model (Mikolov et al., 2013) to learn the representations of nodes as shown in Figure 2. In this case, the encoder ψenc is implemented as two embedding look-up tables Z ∈ ℝN×D and Zc ∈ ℝN×D, respectively for target embeddings and context embeddings. The network information ϕ ∈ Φtar that we try to preserve is defined as the node-context pairs observed in the random walks, where denotes the context nodes (or neighborhood) of vi. The objective is to maximize the probability of observing a node's neighborhood conditioned on embeddings:
where ei is a one-hot row vector of length N that picks the i-th row of Z. Let zi = eiZ and , the conditional probability above is formulated as
so that ψdec could be regarded as link reconstruction based on the normalized proximity between different nodes. In practice, the computation of the probability is expensive due to the summation over every node in the network, but hierarchical softmax or negative sampling can be applied to reduce time complexity.

Figure 2. Building blocks of models with embedding look-up tables. There are two key components of these works: sampling and modeling. The primary distinction between different methods under this line relies on how to define the two components.
There are also some approaches that are developed based on similar ideas. LINE (Tang et al., 2015) defines the first-order and second-order proximity for learning node embedding, where the latter can be seen as a special case of DeepWalk with context window length set as 1. Meanwhile, node2vec (Grover and Leskovec, 2016) applies different random walk strategies, which provides a trade-off between breadth-first search (BFS) and depth-first search (DFS) in networks search strategies. Planetoid (Yang et al., 2016) extends skip-gram models for semi-supervised learning, which predicts the class label of nodes along with the context in the input network data. In addition, it has been shown that there exists a close relationship between skip-gram models and matrix factorization algorithms (Levy and Goldberg, 2014; Qiu et al., 2018). Therefore, network embedding models that utilize matrix factorization techniques, such as LE (Belkin and Niyogi, 2002), Grarep (Cao et al., 2015), and HOPE (Ou et al., 2016), may also be implemented in the similar manner. Random sampling-based approaches have the capacity to allow a flexible and stochastic measure of node similarity, making them not only achieve higher performance in many applications, but also become more scalable toward large-scale datasets.
3.2.2. Attributed Network Embedding Models
Social networks are rich in side information, where nodes could be associated with various attributes that characterize their properties. Inspired by the idea of inductive matrix completion (Natarajan and Dhillon, 2014), TADW (Yang et al., 2015) extends the framework of DeepWalk by incorporating features of vertices into network representation learning. Besides sampling from plain networks, FeatWalk (Huang et al., 2019) proposes a novel feature-based random walk strategy to generate node sequences by considering node similarity on attributes. With the random walks based on both topological and attribute information, the skip-gram model is then applied to learn node representations.
3.2.3. Heterogeneous Network Embedding Models
Nodes in networks could be of different types, which poses the challenge of how to preserve relations among them. HERec (Shi et al., 2019) and metapath2vec++ (Dong et al., 2017) propose meta-path based random walk schema to discover the context across different types of nodes. The skip-gram architecture in metapath2vec++ is also modified, so that the normalization term in softmax only considers nodes of the same type. In a more complex scenario where we have both nodes and attributes of different types, HNE (Chang et al., 2015) combines feed-forward neural networks and embedding models toward a unified framework. Suppose za and zb denote the latent vectors of two different types of nodes, HNE defines two additional transformation matrices U and V to respectively map za and zb to the joint space. Let and , intra-type node similarity and inter-type node similarity are defined as
where we hope to preserve various types of similarities during training. As for obtaining za and zb, HNE applies different feed-forward neural networks to map raw input (e.g., images and texts) to latent spaces, thus enabling an end-to-end training framework. Specifically, the authors use a CNN to process images and a fully-connected neural network to process texts.
3.2.4. Dynamic Embedding Models
Real world social networks are not static and will evolve over time with addition/deletion of nodes and links. To deal with this challenge, DNE (Du L. et al., 2018) presents a decomposable objective to learn the representation of each node separately, where the impact of network changes on existing nodes is measurable and greatly affected nodes will be chosen for updates as the learning process proceeds. In addition, DANE (Li J. et al., 2017) leverages matrix perturbation theory to tackle online embedding updates.
3.3. Autoencoder Techniques
In this section, we discuss network representation models based on the autoencoder architecture (Hinton and Salakhutdinov, 2006; Bengio et al., 2013). As shown in Figure 3, an autoencoder consists of two neural network modules: encoder and decoder. The encoder ψenc maps the features of each node into a latent space, and the decoder ψdoc reconstructs the information about the network from the latent space. Usually the hidden representation layer has a smaller size than that of the input/output layer, forcing it to create a compressed representation that captures the non-linear structure of network. Formally, following Equation (1), the objective function of autoencoder is to minimize the reconstruction error between the input and the output decoded from low-dimensional representations.
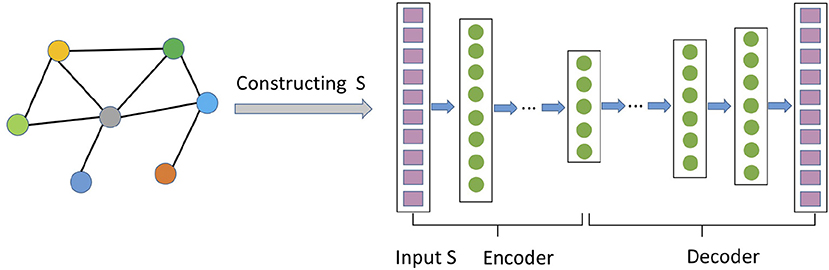
Figure 3. An example of autoencoder-based network representation algorithms. Rows of the proximity matrix are fed into the autoencoder to learn and generate embeddings at the hidden layer.
3.3.1. Deep Neural Graph Representation (DNGR)
DNGR (Cao et al., 2016) attempts to preserve a node's local neighborhood information using a stacked denoising autoencoder. Specifically, assume S is the PPMI matrix (Bullinaria and Levy, 2007) constructed from A, then DNGR minimizes the following loss:
where denotes the associated neighborhood information of vi. In this case, Φtar = {Si*}vi∈V and DNSR targets to reconstruct the PPMI matrix. zi is the embedding of node vi in the hidden layer.
3.3.2. Structural Deep Network Embedding (SDNE)
SDNE (Wang et al., 2016) is another autoencoder-based model for network representation learning. The objective function of SDNE is:
The first term is an autoencoder as in Equation (5), except that the reconstruction error is weighted, so that more emphasis is put on recovering non-zero entries in Si*. The second part is motivated by Laplacian Eigenmaps that imposes nearby nodes to have similar embeddings. Besides, SDNE differs from DNGR in the definition of S, where DNGR defines S as the PPMI matrix while SDNE sets S as the adjacency matrix.
It is worth noting that, unlike Equation (2) which uses one-hot indicator vector for embedding look-up, DNGR and SDNE transform each node's information to an embedding by training neural network modules. Such distinction allows autoencoder-based methods to directly model on a node's neighborhood structure and features, which is not straightforward for random walk approaches. Therefore, it is straightforward to incorporate richer information sources (e.g., node attributes) into representation learning, as will be introduced below. However, autoencoder-based methods may suffer from scalability issues as the input dimension is , which may result in significant time costs in real massive datasets.
3.3.3. Autoencoder-Based Attributed Network Embedding
The structure of autoencoders facilitates the incorporation of multiple information sources toward joint representation learning. Instead of only mapping nodes to the latent space, CAN (Meng et al., 2019) proposes to learn the representation of nodes and attributes in the same latent space by using variational autoencoders (VAEs) (Doersch, 2016), in order to capture the affinities between nodes and attributes. DANE (Gao and Huang, 2018) utilizes the correlation between topological and attribute information of nodes by building two autoencoders for each information source, and then encourages the two sets of latent representations to be consistent and complementary. Li H. et al. (2017) adopts another strategy, where topological feature vector and content information vector (learned by doc2vec Le and Mikolov, 2014) are directly concatenated and put into a VAE to capture the nonlinear relationship between them.
3.4. Graph Convolutional Approaches
Inspired by the significant performance improvement of convolutional neural networks (CNN) in image recognition, recent years have witnessed a surge in adapting convolutional modules to learn representations of network data. The intuition behind it is to generate node embedding by aggregating information from its local neighborhood as shown in Figure 4. Different from autoencoder-based approaches, the encoding function of graph convolutional approaches leverages a node's local neighborhood as well as attribute information. Some efforts (Bruna et al., 2013; Henaff et al., 2015; Defferrard et al., 2016; Hamilton W. et al., 2017) have been made to extend traditional convolutional networks for network data to generate network embedding in the past few years. The convolutional filters of these approaches are either spatial filters or spectral filters. Spatial filters operate directly on the adjacency matrix whereas spectral filters operate on the spectrum of graph Laplacian (Defferrard et al., 2016).
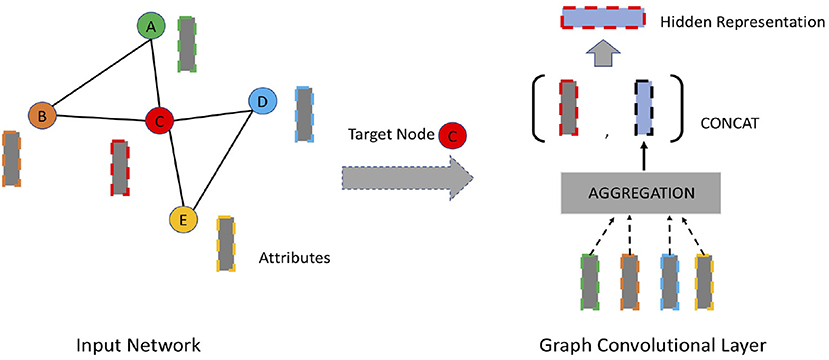
Figure 4. An overview of graph convolutional networks. The dashed rectangles denote node attributes. The representation of each individual node (e.g., node C) is aggregated from its immediate neighbors (e.g., node A, B, D, E), concatenated with the lower-layer representation of itself.
3.4.1. Graph Convolutional Networks (GCN)
GCN (Bronstein et al., 2017) is a well-known semi-supervised graph convolutional networks. It defines a convolutional operator on network, and iteratively aggregates embeddings of neighbors of a node and uses the aggregated embedding as well as its own embedding at previous iteration to generate the node's new representation. The layer-wise propagation rule of encoding function ψenc is defined as:
where Hk−1 denotes the learned embeddings in layer k − 1, and H0 = X. is the adjacency matrix with added self-connections. IG is the identity matrix, . Wk−1 is a layer-wise trainable weight matrix. σ(·) denotes an activation function such as ReLU. The loss function for supervised training is to evaluate the cross-entropy error over all labeled nodes:
where is the predictive matrix with F candidate labels. ψdec(·) can be viewed as a fully-connected network with the softmax activation function to map representations to predicted labels. Note that unlike autoencoders that explicitly treat each node's neighborhood as features or reconstruction goals as in Equations (5) or (6), GCN implicitly applies the local neighborhood links on each encoding layer as pathways to aggregate embeddings from neighbors, so that higher order network structures are utilized. Since Equation (8) is a supervised loss function, Φtar is not applicable here. However, the loss function can also be formulated in unsupervised manners, similar to the skip-gram model (Kipf and Welling, 2016; Hamilton W. et al., 2017). GCN may suffer from the scalability problem when the size of A is large. The corresponding training algorithms have been proposed to tackle this challenge (Ying et al., 2018a), where the network data is processed in small batches and we can sample a node's local neighbors instead of using all of them.
3.4.2. Inductive Training With GCN
So far many basic models we have reviewed mainly generate network representations in a transductive manner. GraphSAGE (Hamilton W. et al., 2017) emphasized the inductive capability of GCN. Inductive learning is essential for high-throughput machine learning systems, especially when operating on evolving networks that constantly encounter unseen nodes (Yang et al., 2016; Guo et al., 2018). The core representation update scheme of GraphSAGE is similar to that of traditional GCN, except that the operation on the whole network is replaced by sample-based representation aggregators:
where is the hidden representation of node vi in the k-th layer. CONCAT denotes concatenation operator and AGGREGATEk represents neighborhood aggregation function of the k-th layer (e.g., element-wise mean or max operator). denotes the neighbors of vi. Compared with Equation (7), GraphSAGE only needs to aggregate feature vectors from the partial set of neighbors, making it scalable for large-scale data. Given the attribute features and neighborhood relations of an unseen node, GraphSAGE can generate the embedding of this node by leveraging its local neighbors as well as attributes via forward propagation.
3.4.3. Graph Attention Mechanisms
Attention mechanisms have become the standard technique in many sequence-based tasks, in order to make models focus on the most relevant parts of the input in making decisions. We could also utilize attention mechanisms to aggregate the most important features from nodes' local neighbors. GAT (Velickovic et al., 2017) extends the framework of GCN by replacing the standard aggregation function with an attention layer to aggregate messages from most important neighbors. Thekumparampil et al. (2018) also proposes to remove all intermediate fully-connected layers in conventional GCN and to replace the propagation layers with attention layers. It thus allows the model to learn a dynamic and adaptive local summary of neighborhoods, greatly reduces the parameters, and also achieves more accurate predictions.
4. Subgraph Embedding
Besides learning representations for nodes, recent years have also witnessed an increasing branch of research efforts that try to learn representations for a set of nodes and edges as an integral. Thus, the goal is to represent a subgraph with a low-dimensional vector. Many traditional methods that operate on subgraphs rely on graph kernels (Haussler, 1999), which decompose a network into some atomic substructures such as graphlets, subtree patterns, and paths, and treat these substructures as features to obtain an embedding through further transformation. In this section, however, we focus on reviewing methods that seek to automatically learn embeddings of subgraphs using deep models. For those who are interested in graph kernels, we refer the readers to Vishwanathan et al. (2010).
According to the literature, most existing methods are built on the techniques used for node embedding, as introduced in section 3. However, in graph representation problems, the label information is associated with particular subgraphs instead of individual nodes or links. In this review, we divide the approaches of subgraph representation learning into two categories based on how they aggregate node-level embeddings in each subgraph. The detailed discussion for each category is as below.
4.1. Flat Aggregation
Assume denotes the set of nodes in a particular subgraph and represents the subgraph's embedding, could be obtained by aggregating the embeddings of all individual nodes in the subgraph:
where ψaggr denotes the aggregation function. Methods based on such flat aggregation usually define ψaggr that captures simple correlations among nodes. For example, Niepert et al. (2016) directly concatenates node embeddings together and utilize standard convolutional neural networks as an aggregation function to generate graph representation. Dai et al. (2016) employs a simple element-wise summation operation to define ψaggr, and learns graph embedding by summing all embeddings of individual nodes.
In addition, some methods apply recurrent neural networks (RNNs) for representing graphs. Some typical methods first sample a number of graph sequences from the input network, and then apply RNN-based autoencoders to generate an embedding for each graph sequence. The final graph representation is obtained by either averaging (Jin et al., 2018) or concatenating (Taheri et al., 2018) these graph sequence embeddings.
4.2. Hierarchical Aggregation
In contrast to flat aggregation, the motivation behind hierarchical aggregation is to preserve the hierarchical structure that might be presented in the subgraph by aggregating neighborhood information via a hierarchical way. Bruna et al. (2013) and Defferrard et al. (2016) attempt to utilize such a hierarchical structure of networks by combining convolutional neural networks with graph coarsening. The main idea behind them is to stack multiple graph coarsening and convolutional layers. In each layer, they first apply graph cluster algorithms to group nodes, and then merge node embeddings within each cluster using element-wise max-pooling. After clustering, they generate a new coarse network by stacking embeddings of clusters together, which is again fed into convolutional layers and the same process repeats. Clusters in each layer can be viewed as subgraphs, and cluster algorithms are used to learn the assignment matrix of subgraphs, so that the hierarchical structure of the network is also propagated through the layers. Although these methods work well in certain applications, they actually follow a two-stage fashion, where the stages of clustering and embedding may not reinforce each other.
To avoid this limitation, DiffPool (Ying et al., 2018b) proposes an end-to-end model that does not depend on a deterministic clustering subroutine. The layer-wise propagation rule is formulated as below:
where denotes node embeddings, is the cluster assignment matrix learned from the previous layer. The goal of the left equation is to generate the (k + 1)-th coarser network embedding M(k+1) by aggregating node embeddings according to cluster assignment C(k); while the right equation is to learn a new coarsened adjacency matrix from the previous adjacency matrix A(k), which stores the similarity between each pair of clusters. Here, instead of applying deterministic clustering algorithm to learn C(k), they adopt graph neural networks (GNNs) to learn it. Specifically, they use two separate GNNs on the input embedding matrix M(k) and coarsened adjacency matrix A(k) to generate assignment matrix C(k) and embedding matrix Z(k), respectively. Formally, , and . The two steps could reinforce each other to improve the performance. DiffPool may suffer from computational issues brought by the computation of soft clustering assignment, which is further addressed in Cangea et al. (2018).
5. Applications
The representations learned from networks can be easily applied to downstream machine learning models for further analysis on social networks. Some common applications include node classification, link prediction, anomaly detection, and clustering.
5.1. Node Classification
In social networks, people are often associated with semantic labels with respect to certain aspects about them, such as affiliations, interests, or beliefs. However, in real-world scenarios, people are usually partially or sparsely labeled, since labeling is expensive and time consuming. The goal of node classification is to predict labels of unlabeled nodes in networks by leveraging their connections with the labeled ones considering the network structure. According to Bhagat et al. (2011), existing methods can be classified into two categories, e.g., random walk based, and feature extraction-based methods. The former aims to propagate labels with random walks (Baluja et al., 2008), while the latter targets to extract features from a node's surrounding information and network statistics.
In general, the network representation approach follows the second principle. A number of existing network representation models, like Yang et al. (2015), Wang et al. (2016), and Liao et al. (2018), focus on extracting node features from the network using representation learning techniques, and then apply machine learning classifiers like support vector machine, naive Bayes classifiers, and logistic regression for prediction. In contrast to separating the steps of node embedding and node classification, some recent work (Dai et al., 2016; Hamilton W. et al., 2017; Monti et al., 2017) designs an end-to-end framework to combine the two tasks, so that the discriminative information inferred from labels can directly benefit the learning of network embedding.
5.2. Link Prediction
Social networks are not necessarily complete as some links might be missing. For example, friendship links between two users in a social network can be missing even if they actually know each other in real world. The goal of link prediction is to infer the existence of new interactions or emerging links between users in the future, based on the observed links and the network evolution mechanism (Liben-Nowell and Kleinberg, 2007; Al Hasan and Zaki, 2011; Lü and Zhou, 2011). In network embedding, an effective model is expected to preserve both network structure and inherent dynamics of the network in the low-dimensional space. In general, the majority of previous work focuses on predicting missing links between users under homogeneous network settings (Grover and Leskovec, 2016; Ou et al., 2016; Zhou et al., 2017), and some efforts also attempt to predict missing links in heterogeneous networks (Liu Z. et al., 2017, 2018). Although, beyond the scope of this survey, applying network embedding for building recommender systems (Ying et al., 2018a) may also be a direction that is worth exploring.
5.3. Anomaly Detection
Another challenging task in social network analysis is anomaly detection. Malicious activities in social networks, such as spamming, fraud, and phishing, can be interpreted as rare or unexpected behaviors that deviate from the majority of normal users. While numerous algorithms have been proposed for spotting anomalies and outliers in networks (Savage et al., 2014; Akoglu et al., 2015; Liu N. et al., 2017), anomaly detection methods, based on network embedding techniques, have recently received increased attention (Hu et al., 2016; Liang et al., 2018; Peng et al., 2018). The discrete and structural information in networks are merged and projected into the continuous latent space, which facilitates the application of various statistical or geometrical algorithms in measuring the degree of isolation or outlierness of network components. In addition, in contrast to detect malicious activities in a static way, Sricharan and Das (2014) and Yu et al. (2018) also attempted to study the problem in dynamic networks.
5.4. Node Clustering
In addition to the above applications, node clustering is another important network analysis problem. The target of node clustering is to partition a network into a set of clusters (or subgraphs), so that nodes in the same cluster are more similar to each other than those from other clusters. In social networks, such clusters are widely spread in terms of communities, such as groups of people that belong to similar affiliations or have similar interests. Most previous work focuses on clustering networks with various metrics of proximity or connection strength between nodes. For example, Shi and Malik (2000) and Ding et al. (2001) seek to maximize the number of connections within clusters while minimizing the connections between clusters. Recently, many efforts have resort to network representation techniques for node clustering. Some methods treat embedding and clustering as disjointed tasks, where they first embed nodes to low-dimensional vectors, and then apply traditional clustering algorithms to produce clusters (Tian et al., 2014; Cao et al., 2015; Wang et al., 2017). Other methods such as Tang et al. (2016) and Wei et al. (2017) consider the optimization problem of clustering and network embedding in a unified objective function and generate cluster-induced node embeddings.
6. Conclusion and Future Directions
In recent years there has been a surge in leveraging representation learning techniques for network analysis. In this review, we have provided an overview of the recent efforts on this topic. Specifically, we summarize existing techniques into three subgroups based on the type of the core learning modules: representation look-up tables, autoencoders, and graph convolutional networks. Although many techniques have been developed for a wide spectrum of social networks analysis problems in the past few years, we believe there still remains many promising directions that are worth further exploring.
6.1. Dynamic Networks
Social networks are inherently highly dynamic in real-life scenarios. The overall set of nodes, the underlying network structure, as well as attribute information, might evolve over time. As an example, these elements in real world social networks such as Facebook could correspond to users, connections, and personal profiles. This property makes existing static learning techniques fail in working properly. Although several methods have been proposed to tackle dynamic networks, they often rely on certain assumptions, such as assuming that the node set is fixed and only deals with dynamics caused by edge deletion and addition (Li J. et al., 2017). Furthermore, the changes in attribute information are rarely considered in existing works. Therefore, how to design effective and efficient network embedding techniques for truly dynamic networks remains an open question.
6.2. Hierarchical Network Structure
Most of the existing techniques mainly focus on designing advanced encoding or decoding functions trying to capture node pairwise relationships. Nevertheless, pairwise relations can only provide insights about local neighborhoods, and might not infer global hierarchical network structures, which is crucial for more complex networks (Benson et al., 2016). How to design effective network embedding methods that are capable of preserving hierarchical structures of networks is a promising direction for further work.
6.3. Heterogeneous Networks
Existing network embedding methods mainly deal with homogeneous networks. However, many relational systems in real-life scenarios can be abstracted as heterogeneous networks with multiple types of nodes or edges. In this case, it is hard to evaluate semantic proximity between different network elements in the low-dimensional space. While some work has investigated the use of metapaths (Dong et al., 2017; Huang and Mamoulis, 2017) to approximate semantic similarity for heterogeneous network embedding, many tasks on heterogeneous networks have not been fully evaluated. Learning embeddings for heterogeneous networks is still at the early stage, and more comprehensive techniques are required to fully capture the relations between different types of network elements, toward modeling more complex real systems.
6.4. Scalability
Although deep learning based network embedding methods have achieved substantial performances due to their great capacities, they still suffer from the problem of efficiency. This problem will become more severe when dealing with real-life massive datasets with billions of nodes and edges. Designing deep representation learning frameworks that are scalable for real network datasets is another driving factor to advance the research in this domain. Additionally, similar to using GPUs for traditional deep models built on grid structured data, developing computational paradigms for large-scale network processing could be an alternative way toward efficiency improvement (Bronstein et al., 2017).
6.5. Interpretability
Despite the superior performances achieved by deep models, one fundamental limitation of them is the lack of interpretability (Liu N. et al., 2018). Different dimensions in the embedding space usually have no specific meaning, thus it is difficult to comprehend the underlying factors that have been preserved in the latent space. Since the interpretability aspect of machine learning models is currently receiving increased attention (Du M. et al., 2018; Montavon et al., 2018), it might also be important to explore how to understand the representation learning outcome, how to develop interpretable network representation learning models, as well as how to utilize interpretation to improve the representation models. Answering these questions is helpful to learn more meaningful and task-specific embeddings toward various social network analysis problems.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work is, in part, supported by NSF (#IIS-1657196, #IIS-1750074 and #IIS-1718840).
References
Akoglu, L., Tong, H., and Koutra, D. (2015). Graph based anomaly detection and description: a survey. Data Min. Knowl. Discov. 29, 626–688. doi: 10.1007/s10618-014-0365-y
Al Hasan, M., and Zaki, M. J. (2011). “A survey of link prediction in social networks,” in Social Network Data Analytics, ed C. C. Aggarwal (Boston, MA: Springer), 243–275.
Baluja, S., Seth, R., Sivakumar, D., Jing, Y., Yagnik, J., Kumar, S., et al. (2008). “Video suggestion and discovery for youtube: taking random walks through the view graph,” in International Conference on World Wide Web (Beijing), 895–904.
Belkin, M., and Niyogi, P. (2002). “Laplacian eigenmaps and spectral techniques for embedding and clustering,” in Advances in Neural Information Processing Systems (Cambridge, MA), 585–591.
Bengio, Y. (2009). Learning deep architectures for AI. Found. Trends® in Mach. Learn. 2, 1–127. doi: 10.1561/2200000006
Bengio, Y., Courville, A., and Vincent, P. (2013). Representation learning: a review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1798–1828. doi: 10.1109/TPAMI.2013.50
Benson, A. R., Gleich, D. F., and Leskovec, J. (2016). Higher-order organization of complex networks. Science 353, 163–166. doi: 10.1126/science.aad9029
Bhagat, S., Cormode, G., and Muthukrishnan, S. (2011). “Node classification in social networks,” in Social Network Data Analytics, ed C. Aggarwal (Boston, MA: Springer), 115–148.
Bronstein, M. M., Bruna, J., LeCun, Y., Szlam, A., and Vandergheynst, P. (2017). Geometric deep learning: going beyond euclidean data. IEEE Signal Process. Mag. 34, 18–42. doi: 10.1109/MSP.2017.2693418
Bruna, J., Zaremba, W., Szlam, A., and LeCun, Y. (2013). “Spectral networks and locally connected networks on graphs,” in Proceedings of International Conference on Learning Representation (Banff, AB).
Bullinaria, J. A., and Levy, J. P. (2007). Extracting semantic representations from word co-occurrence statistics: a computational study. Behav. Res. Methods 39, 510–526. doi: 10.3758/BF03193020
Cangea, C., Veličković, P., Jovanović, N., Kipf, T., and Liò, P. (2018). “Towards sparse hierarchical graph classifiers,” in Workshop Proceedings of International Conference on Learning Representations (Scottsdale, AZ).
Cao, S., Lu, W., and Xu, Q. (2015). “Grarep: learning graph representations with global structural information,” in ACM International Conference on Information and Knowledge Management (New York, NY), 891–900.
Cao, S., Lu, W., and Xu, Q. (2016). “Deep neural networks for learning graph representations,” in AAAI Conference on Artificial Intelligence (Phoenix, AZ), 1145–1152.
Chang, S., Han, W., Tang, J., Qi, G.-J., Aggarwal, C. C., and Huang, T. S. (2015). “Heterogeneous network embedding via deep architectures,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Sydney, NSW), 119–128.
Chen, W., Wang, C., and Wang, Y. (2010). “Scalable influence maximization for prevalent viral marketing in large-scale social networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC), 1029–1038.
Dai, H., Dai, B., and Song, L. (2016). “Discriminative embeddings of latent variable models for structured data,” in International Conference on Machine Learning (New York, NY), 2702–2711.
Defferrard, M., Bresson, X., and Vandergheynst, P. (2016). “Convolutional neural networks on graphs with fast localized spectral filtering,” in Advances in Neural Information Processing Systems (Barcelona), 3844–3852.
Dietz, L., Bickel, S., and Scheffer, T. (2007). “Unsupervised prediction of citation influences,” in International Conference on Machine Learning (Corvallis, OR), 233–240.
Ding, C. H., He, X., Zha, H., Gu, M., and Simon, H. D. (2001). “A min-max cut algorithm for graph partitioning and data clustering,” in IEEE International Conference on Data Mining (San Jose, CA), 107–114.
Dong, Y., Chawla, N. V., and Swami, A. (2017). “metapath2vec: Scalable representation learning for heterogeneous networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS), 135–144.
Du, L., Wang, Y., Song, G., Lu, Z., and Wang, J. (2018). “Dynamic network embedding: An extended approach for skip-gram based network embedding,” in International Joint Conference on Artificial Intelligence (Stockholm), 2086–2092.
Du, M., Liu, N., and Hu, X. (2018). Techniques for interpretable machine learning. arXiv preprint arXiv:1808.00033.
Grover, A., and Leskovec, J. (2016). “node2vec: Scalable feature learning for networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, CA), 855–864.
Guo, J., Xu, L., and Chen, E. (2018). Spine: Structural identity preserved inductive network embedding. arXiv preprint arXiv:1802.03984.
Guo, Z., Zhang, Z. M., Zhu, S., Chi, Y., and Gong, Y. (2014). A two-level topic model towards knowledge discovery from citation networks. IEEE Trans. Knowl. Data Eng. 26, 780–794. doi: 10.1109/TKDE.2013.56
Hamilton, W., Ying, Z., and Leskovec, J. (2017). “Inductive representation learning on large graphs,” in Advances in Neural Information Processing Systems (Long Beach, CA), 1024–1034.
Haussler, D. (1999). Convolution Kernels on Discrete Structures. Technical Report, Department of Computer Science, University of California at Santa Cruz.
Henaff, M., Bruna, J., and LeCun, Y. (2015). Deep convolutional networks on graph-structured data. arXiv preprint arXiv:1506.05163.
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science 313, 504–507. doi: 10.1126/science.1127647
Hu, R., Aggarwal, C. C., Ma, S., and Huai, J. (2016). “An embedding approach to anomaly detection,” in IEEE International Conference on Data Engineering (Helsinki), 385–396.
Huang, X., Song, Q., Yang, F., and Hu, X. (2019). “Large-scale heterogeneous feature embedding,” in AAAI Conference on Artificial Intelligence (Honolulu, HI).
Huang, Z., and Mamoulis, N. (2017). Heterogeneous information network embedding for meta path based proximity. arXiv preprint arXiv:1701.05291. doi: 10.1145/1235
Jin, H., Song, Q., and Hu, X. (2018). “Discriminative graph autoencoder,” in 2018 IEEE International Conference on Big Knowledge (ICBK) (Singapore).
Kipf, T. N., and Welling, M. (2016). “Variational graph auto-encoders,” in Proceedings of NeurIPS Bayesian Deep Learning Workshop (Barcelona).
Le, Q., and Mikolov, T. (2014). “Distributed representations of sentences and documents,” in International Conference on Machine Learning (Beijing), 1188–1196.
Leskovec, J., Adamic, L. A., and Huberman, B. A. (2007). The dynamics of viral marketing. ACM Trans. Web 1:5. doi: 10.1145/1232722.1232727
Levy, O., and Goldberg, Y. (2014). “Neural word embedding as implicit matrix factorization,” in Advances in Neural Information Processing Systems (Montreal, QC), 2177–2185.
Li, H., Wang, H., Yang, Z., and Odagaki, M. (2017). “Variation autoencoder based network representation learning for classification,” in Proceedings of ACL 2017, Student Research Workshop (Vancouver, BC).
Li, J., Dani, H., Hu, X., Tang, J., Chang, Y., and Liu, H. (2017). “Attributed network embedding for learning in a dynamic environment,” in ACM Conference on Information and Knowledge Management (Singapore), 387–396.
Li, Y., Zhang, D., and Tan, K.-L. (2015). Real-time targeted influence maximization for online advertisements. Proc. VLDB Endowm. 8, 1070–1081. doi: 10.14778/2794367.2794376
Liang, J., Jacobs, P., Sun, J., and Parthasarathy, S. (2018). “Semi-supervised embedding in attributed networks with outliers,” in SIAM International Conference on Data Mining (San Diego, CA), 153–161.
Liao, L., He, X., Zhang, H., and Chua, T.-S. (2018). Attributed social network embedding. IEEE Trans. Knowl. Data Eng. 30, 2257–2270. doi: 10.1109/TKDE.2018.2819980
Liben-Nowell, D., and Kleinberg, J. (2007). The link-prediction problem for social networks. J. Am. Soc. Inform. Sci. Technol. 58, 1019–1031. doi: 10.1002/asi.20591
Liu, N., Huang, X., and Hu, X. (2017). “Accelerated local anomaly detection via resolving attributed networks,” in International Joint Conference on Artificial Intelligence (Melbourne, VIC), 2337–2343.
Liu, N., Huang, X., Li, J., and Hu, X. (2018). “On interpretation of network embedding via taxonomy induction,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (London).
Liu, Z., Zheng, V. W., Zhao, Z., Zhu, F., Chang, K. C.-C., Wu, M., et al. (2017). “Semantic proximity search on heterogeneous graph by proximity embedding,” in AAAI Conference on Artificial Intelligence (San Francisco, CA), 154–160.
Liu, Z., Zheng, V. W., Zhao, Z., Zhu, F., Chang, K. C.-C., Wu, M., et al. (2018). “Distance-aware dag embedding for proximity search on heterogeneous graphs,” in AAAI Conference on Artificial Intelligence (New Orleans, LA).
Lü, L., and Zhou, T. (2011). Link prediction in complex networks: a survey. Phys. A Stat. Mech. Appl. 390, 1150–1170. doi: 10.1016/j.physa.2010.11.027
Meng, Z., Liang, S., Bao, H., and Zhang, X. (2019). “Co-embedding attributed networks,” in ACM International Conference on Web Search and Data Mining (Melbourne, VIC).
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Montavon, G., Samek, W., and Müller, K.-R. (2018). Methods for interpreting and understanding deep neural networks. Digital Signal Process. 17, 1–15. doi: 10.1016/j.dsp.2017.10.011
Monti, F., Boscaini, D., Masci, J., Rodola, E., Svoboda, J., and Bronstein, M. M. (2017). “Geometric deep learning on graphs and manifolds using mixture model CNNs,” in The IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI).
Natarajan, N., and Dhillon, I. S. (2014). Inductive matrix completion for predicting gene–disease associations. Bioinformatics 30, i60–i68. doi: 10.1093/bioinformatics/btu269
Niepert, M., Ahmed, M., and Kutzkov, K. (2016). “Learning convolutional neural networks for graphs,” in International Conference on Machine Learning (New York, NY), 2014–2023.
Ou, M., Cui, P., Pei, J., Zhang, Z., and Zhu, W. (2016). “Asymmetric transitivity preserving graph embedding,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, CA), 1105–1114.
Peng, S., Wang, G., and Xie, D. (2017). Social influence analysis in social networking big data: Opportunities and challenges. IEEE Netw. 31, 11–17. doi: 10.1109/MNET.2016.1500104NM
Peng, Z., Luo, M., Li, J., Liu, H., and Zheng, Q. (2018). “Anomalous: a joint modeling approach for anomaly detection on attributed networks,” in International Joint Conference on Artificial Intelligence, 3513–3519.
Perozzi, B., Al-Rfou, R., and Skiena, S. (2014). “Deepwalk: Online learning of social representations,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (New York, NY), 701–710.
Qiu, J., Dong, Y., Ma, H., Li, J., Wang, K., and Tang, J. (2018). “Network embedding as matrix factorization: unifying deepwalk, LINE, PTE, and node2vec,” in ACM International Conference on Web Search and Data Mining (Los Angeles, CA), 459–467.
Savage, D., Zhang, X., Yu, X., Chou, P., and Wang, Q. (2014). Anomaly detection in online social networks. Soc. Netw. 39, 62–70. doi: 10.1016/j.socnet.2014.05.002
Shi, C., Hu, B., Zhao, W. X., and Philip, S. Y. (2019). Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 31, 357–370. doi: 10.1109/TKDE.2018.2833443
Shi, J., and Malik, J. (2000). Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 22, 888–905. doi: 10.1109/34.868688
Song, X., Tseng, B. L., Lin, C.-Y., and Sun, M.-T. (2006). “Personalized recommendation driven by information flow,” in International ACM SIGIR Conference on Research and Development in Information Retrieval (Seattle, WA), 509–516.
Sricharan, K., and Das, K. (2014). “Localizing anomalous changes in time-evolving graphs,” in ACM SIGMOD International Conference on Management of Data (Snowbird, UT), 1347–1358.
Taheri, A., Gimpel, K., and Berger-Wolf, T. (2018). Learning graph representations with recurrent neural network autoencoders. arXiv preprint arXiv:1805.07683.2018.
Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., and Mei, Q. (2015). “Line: Large-scale information network embedding,” in International Conference on World Wide Web (Florence), 1067–1077.
Tang, M., Nie, F., and Jain, R. (2016). “Capped LP-norm graph embedding for photo clustering,” in ACM Multimedia Conference (Amsterdam), 431–435.
Tang, X., and Yang, C. C. (2012). Ranking user influence in healthcare social media. ACM Trans. Intell. Syst. Technol. 3:73. doi: 10.1145/2337542.2337558
Thekumparampil, K. K., Wang, C., Oh, S., and Li, L.-J. (2018). Attention-based graph neural network for semi-supervised learning. arXiv preprint arXiv:1803.03735.
Tian, F., Gao, B., Cui, Q., Chen, E., and Liu, T.-Y. (2014). “Learning deep representations for graph clustering,” in AAAI Conference on Artificial Intelligence (Quebec City, QC), 1293–1299.
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y. (2017). “Graph attention networks,” in Proceedings of International Conference on Learning Representation (Vancouver, BC).
Vishwanathan, S. V. N., Schraudolph, N. N., Kondor, R., and Borgwardt, K. M. (2010). Graph kernels. J. Mach. Learn. Res. 11, 1201–1242.
Wang, D., Cui, P., and Zhu, W. (2016). “Structural deep network embedding,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco, Ca), 1225–1234.
Wang, X., Cui, P., Wang, J., Pei, J., Zhu, W., and Yang, S. (2017). “Community preserving network embedding,” in AAAI Conference on Artificial Intelligence (San Francisco, Ca), 203–209.
Wei, X., Xu, L., Cao, B., and Yu, P. S. (2017). “Cross view link prediction by learning noise-resilient representation consensus,” in International Conference on World Wide Web (Perth, WA), 1611–1619.
Yang, C., Liu, Z., Zhao, D., Sun, M., and Chang, E. Y. (2015). “Network representation learning with rich text information,” in International Joint Conference on Artificial Intelligence (Buenos Aires), 2111–2117.
Yang, Z., Cohen, W., and Salakhutdinov, R. (2016). “Revisiting semi-supervised learning with graph embeddings,” in International Conference on Machine Learning (New York, NY), 40–48.
Ying, R., He, R., Chen, K., Eksombatchai, P., Hamilton, W. L., and Leskovec, J. (2018a). “Graph convolutional neural networks for web-scale recommender systems,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (London), 974–2681.
Ying, R., You, J., Morris, C., Ren, X., Hamilton, W. L., and Leskovec, J. (2018b). Hierarchical graph representation learning withdifferentiable pooling. arXiv preprint arXiv:1806.08804.
Yu, W., Cheng, W., Aggarwal, C. C., Zhang, K., Chen, H., and Wang, W. (2018). “Netwalk: A flexible deep embedding approach for anomaly detection in dynamic networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (London), 2672–2681.
Keywords: deep learning, social networks, deep social network analysis, representation learning, network embedding
Citation: Tan Q, Liu N and Hu X (2019) Deep Representation Learning for Social Network Analysis. Front. Big Data 2:2. doi: 10.3389/fdata.2019.00002
Received: 03 December 2018; Accepted: 12 March 2019;
Published: 03 April 2019.
Edited by:
Yuxiao Dong, Microsoft Research, United StatesReviewed by:
Chuan-Ju Wang, Academia Sinica, TaiwanDonghui Hu, Hefei University of Technology, China
Copyright © 2019 Tan, Liu and Hu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xia Hu, xiahu@tamu.edu