 Denis Svechkarev
Denis Svechkarev Marat R. Sadykov
Marat R. Sadykov Lucas J. Houser
Lucas J. Houser Kenneth W. Bayles
Kenneth W. Bayles Aaron M. Mohs
Aaron M. Mohs- 1Department of Pharmaceutical Sciences, University of Nebraska Medical Center, Omaha, NE, United States
- 2Department of Pathology and Microbiology, University of Nebraska Medical Center, Omaha, NE, United States
- 3Fred and Pamela Buffett Cancer Center, University of Nebraska Medical Center, Omaha, NE, United States
- 4Department of Biochemistry and Molecular Biology, University of Nebraska Medical Center, Omaha, NE, United States
Fast and reliable identification of infectious disease agents is among the most important challenges for the healthcare system. The discrimination of individual components of mixed infections represents a particularly difficult task. In the current study we further expand the functionality of a ratiometric sensor array technology based on small-molecule environmentally-sensitive organic dyes, which can be successfully applied for the analysis of mixed bacterial samples. Using pattern recognition methods and data from pure bacterial species, we demonstrate that this approach can be used to quantify the composition of mixtures, as well as to predict their components with the accuracy of ~80% without the need to acquire additional reference data. The described approach significantly expands the functionality of sensor arrays and provides important insights into data processing for the analysis of other complex samples.
Introduction
Reliable and rapid identification of pathogenic microorganisms in clinical laboratories is of high importance for the safety and health of the society (Doggett et al., 2016). Currently used methods are mostly based on PCR and mass-spectroscopy techniques, are time-consuming, and equipment-demanding (Váradi et al., 2017). Some rapid detection approaches reported in recent years use antibodies or aptamers to provide selectivity and specificity (Kubicek-Sutherland et al., 2017; Leonard et al., 2018). Sensor arrays are cross-reactive and not intrinsically selective, but they are often based on stable small molecules and provide more flexibility (Geng et al., 2019; Li et al., 2019). Several such systems were reported for successful analysis of bacteria (Phillips et al., 2008; Han et al., 2017). Although pathogen-associated biomarker tests such as ELLecSA (Cartwright et al., 2016) are promising, they are based on engineered enzymes, lack specificity, and are not able to identify particular species of pathogenic bacteria (Sheldon, 2016). Moreover, reliable analysis of mixed bacterial infections in clinical samples still represents a significant challenge (Laitinen et al., 2002; Kommedal et al., 2008).
In our previous study (Svechkarev et al., 2018b), we showed that the dataset containing responses from eight pure bacterial cultures can provide information beyond traditional species classification. In addition, the sensor was able to predict the Gram status of unknown samples outside of the training dataset. In the present communication, we expand the functionality of our sensor array by demonstrating its ability to analyze and quantify individual components of mixed bacterial samples. Importantly, the described approach can be generally applied to any data obtained using a sensor array and could aid in extraction of additional information about the analyte without the need of additional measurements.
Materials and Methods
N-hydroxysuccinimide (NHS), 1-ethyl-3-(3-dimethylamino) propyl)carbodiimide (EDC), pyrenebutyric acid, 1,3-propyldiamine, 2-hydroxyacetophenone and 2-hydroxynaphthophenone were purchased from Sigma-Aldrich (St. Louis, MO). N,N-dimethylformamide (DMF), dimethyl sulfoxide (DMSO), sodium methylate, hydrogen peroxide (30%), N,N-dimethylaminobenzaldehyde, N,N-diphenylaminobenzaldehyde, and hydrochloric acid (Certified ACS Plus, 36–38%) were purchased from Fisher Scientific (Pittsburgh, PA). Ethanol was purchased from UNMC internal supply. Sodium hyaluronate (HA) was purchased from Lifecore Biomedical (Chaska, MN).
Synthesis of the Dyes
The fluorescent ratiometric dyes used as reporters in the sensor array were synthesized following a modified Algar-Flynn-Oyamada procedure, as described elsewhere (Klymchenko et al., 2003). In brief, a corresponding para-substituted benzaldehyde is first reacted with an equimolar quantity of 2-hydroxyacetophenone in DMF in the presence of sodium methylate. The resulting chalcone is then oxidized with an excess of hydrogen peroxide in ethanol in presence of sodium methoxide. Detailed synthetic procedure for each dye are described in the Supplementary Material.
Polymer Synthesis and Nanoparticle Loading
Amphiphilic hyaluronic acid (HA) polymers were synthesized as described in previous reports (Svechkarev et al., 2018a,b). Briefly, 40–45 mg HA (MW = 10–20 kDa) was dissolved in 1:1 ultrapure water and DMF along with 30 mg of NHS and 30 mg of EDC. After mixing for 30 min to activate the HA carboxylic acid groups, 10 weight percent of aminopropyl-pyrenebutanamide was added to the HA solution and allowed to react for 24 h. The reaction mixture was then removed and placed in 3,500 MWCO dialysis tubing and dialyzed against 1:1 water and ethanol for 4 exchanges over 24 h, then against pure water for 8 exchanges over 48 h to remove any impurities. Finally, the product was frozen and freeze-dried for later use. Stock solutions containing 60 mg of pyHA in 40 mL of ultrapure water, as well as 3 mg of each dye (in 10 mL DMSO) were prepared. Solutions of the polymer and dyes were mixed together (10 mL of the modified HA solution + 10 mL of the dye solution) to obtain 4 systems containing every dye mixed with the polymer. The final solutions were thoroughly mixed on a vortex mixer and loaded into the 3,500 MWCO dialysis bags. Samples were then dialyzed against ultrapure water with 8 exchanges over 48 h. After dialysis, the samples were purified using PD-10 columns, then frozen and freeze-dried for further storage at −20°C.
Bacterial Culture, Staining, and Spectroscopy
Eight different bacterial species from our lab collection were used in this study, including four Gram-positive (Staphylococcus aureus, Staphylococcus epidermidis, Bacillus subtilis, Enterococcus faecalis) and four Gram-negative (Escherichia coli, Acinetobacter baumannii, Klebsiella pneumoniae, Citrobacter freundii). Bacteria collected at the stationary phase of growth (15 h) were washed twice with PBS, resuspended in fresh PBS, and adjusted to OD600 = 4 for further use. Dye-loaded nanoparticles solutions were prepared with OD400 = 0.2. Pure bacterial samples were used as prepared. To obtain mixed samples, bacterial cultures with OD600 = 4 were mixed in corresponding proportions (v/v) before mixing with dye-loaded nanoparticles. Bacterial samples (either pure or mixed) and nanoparticles solutions were mixed 1:1, stirred on a vortex mixer, and incubated in dark for 15 min. All samples were subsequently centrifuged at 15,000 rpm for 1 min, washed once with PBS, and resuspended in the same volume of fresh PBS, keeping the original concentration. Samples of each bacterium or mixture with every dye were then plated on black 96-well plates (150 μL/well, 10 replicates per sample). Emission intensities of the samples at three channels (485, 515, and 575 nm) were recorded at λexcitation = 400 nm using Tecan Infinite 200 spectrofluorometric plate reader. Five independent measurements in each channel were averaged and used to calculate ratiometric responses for further analysis.
Data Analysis
Fluorescence intensities in three channels were converted into ratiometric signals, and data matrices were prepared that contained 8 unique signals for every data point. The linear discriminant analysis was performed using the XLSTAT software (Addinsoft, NY). Support vector machine analysis was performed using Orange software (Demšar et al., 2013).
Results and Discussion
Mixed Samples in the Linear Discriminant Space
The spectrum of a system whose components do not interact with each other constitutes a linear combination of the spectra of the mixture's components. The main hypothesis driving our approach is that this linear relationship will be preserved in the linear discriminant subspace. Indeed, such trends have been observed earlier for various linear progressions, like increasing concentrations of a single analyte (Tao and Auguste, 2016; Zhang et al., 2017) or binary mixtures with varying proportions of the components (Tao and Auguste, 2016; Zheng et al., 2019).
In this study, we used eight bacterial species to test our approach: four Gram-positive (S. aureus, S. epidermidis, B. subtilis, E. faecalis) and four Gram-negative (E. coli, A. baumannii, K. pneumoniae, C. freundii). A sensor array consisting of four environmentally-sensitive derivatives of 3-hydroxyflavone, described in detail in our previous work (Svechkarev et al., 2018b), was used to generate the fluorescent signals from bacterial samples. The reporter dyes have the same fluorescent core, but various substituents that drive their interactions with different components of the bacterial cell wall. The dyes change their fluorescent spectra in response to universal (polarity) and specific (hydrogen bonding) interactions, thus creating a unique “fingerprint” response pattern for every bacterial species analyzed.
In our proof-of-concept experiment, pure samples of E. coli, S. epidermidis, and their three different mixtures in various proportions, were investigated. The linear relationship between the spectral responses of the mixtures and those of individual components is evident from the fluorescence spectra (Figure 1A). The linear trend is preserved in the subspace of the first two linear discriminants (Figure 1B). Any departure from linearity may be due to the differences in interaction dynamics of the nanoparticles and/or encapsulated dyes with bacteria, which lead to the dyes being unequally distributed among the mixture's components. Further studies of the nanoparticle-bacteria interactions are underway to perform a detailed analysis of the factors that contribute to deviations from the linear trend.
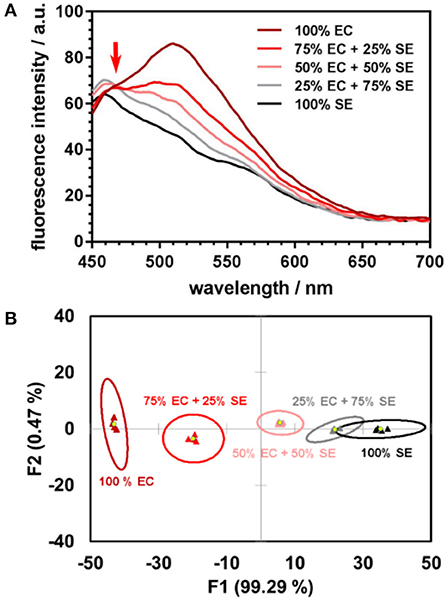
Figure 1. (A) Fluorescence spectra of DOAF-loaded nanoparticles upon incubation with E. coli (EC), S. epidermidis (SE), and their mixtures in different proportions each line is the average of four spectra. The isoemissive point at ~470 nm serves as evidence of the mixed samples spectra being linear combinations of the emission spectra of the pure components. (B) Canonical score plot from LDA analysis of response patterns of pure bacteria and their mixtures. Signals from the mixtures are positioned along the line connecting the centroids of the 95% confidence ellipses for the pure bacteria.
To investigate the behavior of complex samples upon interaction with the sensor, four pairs of bacterial cells were selected from the species indicated above: one Gram-positive pair, one Gram-negative pair, and two “mixed” pairs with one Gram-positive and one Gram-negative component (Figure 2). For each of the four pairs, two mixtures were prepared: a “standard” 50:50 (v/v) mixture with equal content of both components, and a “random” mixture with an arbitrary composition to test the sensor's quantification abilities. As described previously (Svechkarev et al., 2018b), the sensor array can distinguish the Gram status of the bacterial samples: signals from the Gram-positive bacteria are located in the negative part of the plot along the F1 axis, whereas those from Gram-negative bacteria are found on the positive side. Most of the signals from the mixed samples are located along the lines connecting the ellipse centroids of their respective components—however, some departures from linearity are observed for three of the eight studied mixtures. Locations of the signals on the plot are proportional to the composition of the mixtures: the larger is the content of a given component, the closer the mixture's signal is to the signal of that component.
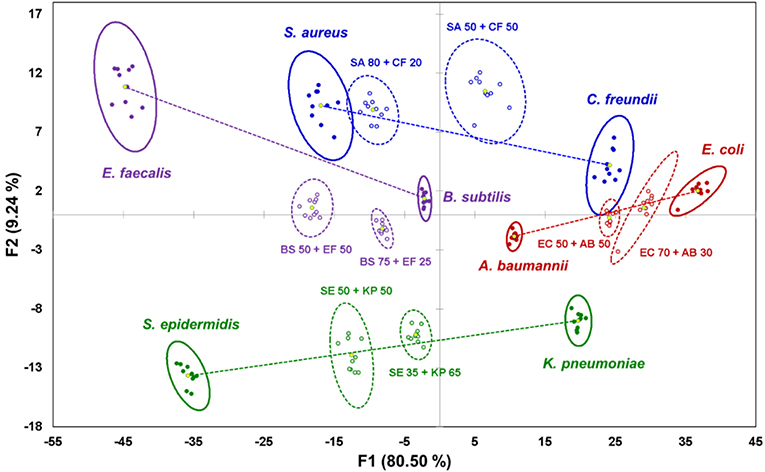
Figure 2. Canonical score plot of the results of LDA for pure bacterial samples and their binary mixtures. Signals from pure bacteria are represented by filled dots and solid ellipses; mixtures are represented by circles and dashed ellipses. Yellow dots are centroids of the 95% confidence ellipses. Lines connecting centroids of the mixture components serve as visual guide.
Classification of unknown samples is a common application of sensor arrays. These systems use a reference dataset, or “training dataset,” that combines the sensor's responses from known analytes, and creates a corresponding canonical score plot similar to one shown in Figure 2. A response from an unknown sample is then analyzed and compared to the responses from the training dataset (Rana et al., 2016). An important consideration is that unknown samples can only be correctly recognized if the signals they generate are already “known” to the sensing system—i.e., they are present among the samples of the training dataset. In this case, the sensor compares and classifies the unknown samples, whereas its prediction capabilities are limited.
Mixture Composition Quantification
The commonly used classification approach presents a limitation for mixed samples analysis: the system needs to be “trained” to recognize the mixtures by including their response patterns into the training dataset. This significantly increases both the effort needed to create the latter, and its size. Our solution to this problem is to use the linear trends observed for the mixture responses relative to their components. Whereas in traditional classification, the Mahalanobis distances are used to calculate the probability of an unknown sample to belong to a certain class from the training dataset, in our approach we use similar distances—i.e., those between the ellipse centroids—as a measure of the component proportions in binary mixtures.
Indeed, we show that the distances between the centroids are proportional to the mixture's composition (Figure 3A), and the content of both components can be estimated using the formulae:
The results of such quantification for all eight studied mixtures are presented in Table 1, columns 3–4. The quantification error in our method mostly varies in the range of 1–8%, with only two exceptions where the observed deviation from the linear trend is also the most significant.
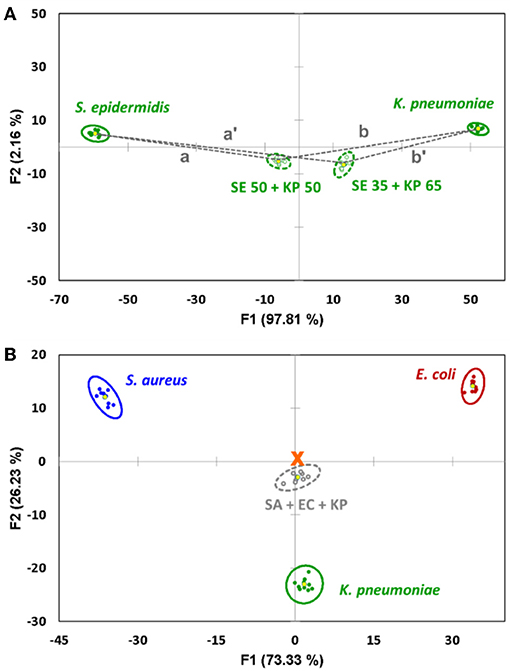
Figure 3. (A) Quantification of the binary mixture of bacteria after the components are identified. The content of S. epidermidis (SE) is proportional to the distance between the 95% confidence ellipse centroids of the mixture and K. pneumoniae (KP). (B) Canonical score plot of the sensor's response to an equal mixture of S. aureus (SA), E. coli (EC) and K. pneumoniae (KP) related to the signals of pure components. The signal of the mixture represents an almost perfect linear combination, being located very close to the center of the triangle (marked with an orange cross).
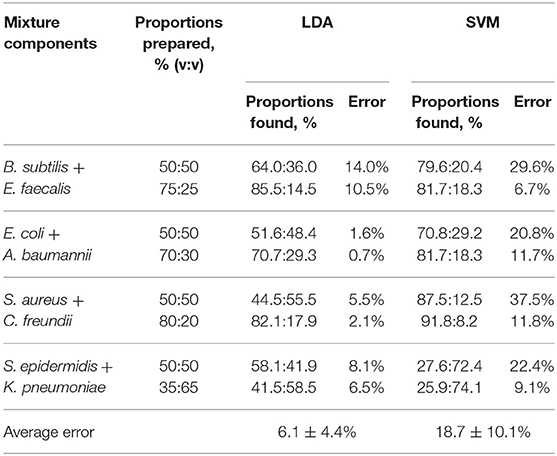
Table 1. Component quantification (see Supplementary Table 2 for detailed LDA quantification results).
A more advanced method of pattern analysis, support vector machines (SVM), is also routinely used for supervised classification (Askim et al., 2016; Tomberg et al., 2019). In the case of a mixture, its response can be compared to the training set comprising the signals of the components. This gives the probabilities for the mixture signal to be attributed to one of the components. However, the SVM method is not linear by its nature, and thus the linear relationship between the response of the mixture and its components may not be preserved. It is manifested, in particular, in significantly higher quantification errors (Table 1, columns 5–6), where the method shows a notable bias toward the most abundant component.
It is worth noting that the linear trends discussed above for the binary systems are observed for more complex samples as well. Thus, a proof-of-concept measurement with a triple-component mixture of S. aureus, E. coli, and K. pneumoniae in equal proportions (33.3% v/v each, Figure 3B) showed a near-perfect response, putting the signals from the mixture almost precisely in the center of the triangle formed by the signals from the three individual components. This strongly supports the ability of such sensor arrays to analyze complex multicomponent systems.
Prediction of Mixture Components
The described approach for the quantification of the components of mixed samples works when the components of an unknown mixture are identified, and they both belong to the training dataset. In addition, our study shows that the sensor array is capable of predicting the components of a mixed sample if they are not known in advance—i.e., without the need of expansion of the training dataset. In order to accomplish this task, a “one against the rest” analysis is used (Schoelkopf and Smola, 2002; Li et al., 2006; Svechkarev et al., 2018b). In this case, the training dataset consists of only two groups of signals: those of a component under question, and those of all other bacterial species combined together (the “other” class). We expect the system to be able to recognize a similarity in the response pattern of the mixture with both the component under question and the “other” bacteria, or only with the “other” class. The first case will mean a positive identification—the component is present in the mixture—and the signal from the mixture will be located somewhere between those of the identified component and the “other” bacteria (Figure 4A). The latter case means that both mixture components belong to the “other” bacteria class, and the component under question is not part of the mixture. It is usually visualized as a significant overlap of the ellipses for the mixture and “other” class signals (Figure 4B). The angle between the lines connecting the ellipse centroid of the “other” class response with the mixture and component under question can be an additional verification of the prediction accuracy: it is <90° in case of a positive attribution, and usually exceeds 90° in case of a negative result (Figure 4).
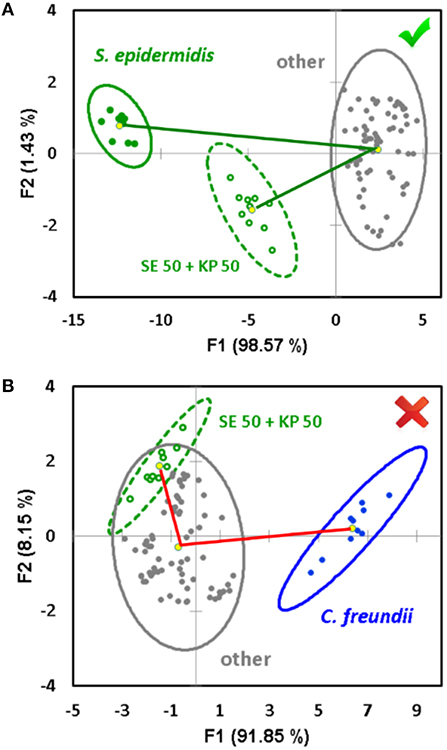
Figure 4. Example of a positive (A) and negative (B) decision regarding a potential component of an unknown mixture in the “one against the rest” analysis. The decision is made based on the overlap between the 95% confidence ellipses of the mixture and the complex of “other” bacteria, and the angle between the vectors connecting the ellipse centroid of the “other” aggregate group and the signal of the component under question, respectively.
The “one against the rest” analysis can also be performed using the SVM method instead of LDA. In this case, a probability for the mixture signal to be associated with either the component under question, or other bacteria, will be obtained. The probability data is presented in Supplementary Table 3, and the average results are reported in Table 2 (column 5). A probability of >75% is considered a positive result, <35% is a negative result, and any value in between is considered equivocal. A summary of the prediction accuracy based on correct hits is presented in Table 2, column 4. Overall, the results of both classification methods (LDA and SVM) are very similar, and the prediction accuracy generally exceeds 80%. This compares well with several other methods that demonstrated specificity in the range of 70–85% (Herreros et al., 2015; De Rosa et al., 2018).
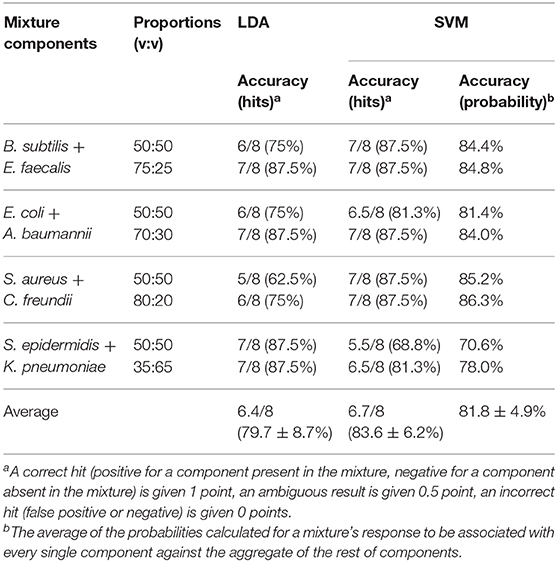
Table 2. Component prediction accuracy based on “one against the rest” analysis (see Supplementary Figures 2–9 for detailed LDA “one against the rest” classification).
The new approach to the processing of sensor array responses described in this report significantly expands the abilities of such sensors in both detection, prediction, and even quantification of complex samples, without the need for acquisition of new reference data and expansion of the training datasets. Further studies of the interaction dynamics of the reporter dyes and bacterial cell walls will allow for improved accuracy of this sensor array approach.
Data Availability Statement
The datasets generated for this study are included in the article/Supplementary Material, and can be obtained from the authors by request.
Author Contributions
DS conceptualized the project and prepared the original draft. DS and MS developed the methodology and performed the experiments. DS and LH prepared the sensor arrays and analyzed the data. KB and AM supervised the project. All authors participated in the review and editing of the manuscript.
Funding
This work was funded in part by the Nebraska Research Initiative to AM and research grants from the National Institutes of Health: R01 EB027662 to AM; P30 CA036727 (Fred & Pamela Buffett Cancer Center), 1S10RR17846, 1S10RR027940, P20 GM103480 (Nebraska Center for Nanomedicine), P01 AI83211 to KB, and R01 AI125589 to KB.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fchem.2019.00916/full#supplementary-material
References
Askim, J. R., Li, Z., LaGasse, M. K., Rankin, J. M., and Suslick, K. S. (2016). An optoelectronic nose for identification of explosives. Chem. Sci. 7, 199–206. doi: 10.1039/C5SC02632F
Cartwright, M., Rottman, M., Shapiro, N. I., Seiler, B., Lombardo, P., Gamini, N., et al. (2016). A Broad-Spectrum infection diagnostic that detects pathogen-associated molecular patterns (PAMPs) in whole blood. EBioMedicine 9, 217–227. doi: 10.1016/j.ebiom.2016.06.014
De Rosa, R., Grosso, S., Lorenzi, G., Bruschetta, G., and Camporese, A. (2018). Evaluation of the new Sysmex UF-5000 fluorescence flow cytometry analyser for ruling out bacterial urinary tract infection and for prediction of gram negative bacteria in urine cultures. Clin. Chim. Acta 484, 171–178. doi: 10.1016/j.cca.2018.05.047
Demšar, J., Curk, T., Erjavec, A., Gorup, C., Hočevar, T., Milutinovič, M., et al. (2013). Orange: data mining toolbox in Python. J. Mach. Learn. Res. 14, 2349–2353.
Doggett, N. A., Mukundan, H., Lefkowitz, E. J., Slezak, T. R., Chain, P. S., Morse, S., et al. (2016). Culture-independent diagnostics for health security. Heal. Secur. 14, 122–142. doi: 10.1089/hs.2015.0074
Geng, Y., Peveler, W. J., and Rotello, V. M. (2019). Array-based “Chemical Nose” Sensing in diagnostics and drug discovery. Angew. Chem. Int. Ed. 58, 5190–5200. doi: 10.1002/anie.201809607
Han, J., Cheng, H., Wang, B., Braun, M. S., Fan, X., Bender, M., et al. (2017). A Polymer/Peptide complex-based sensor array that discriminates bacteria in urine. Angew. Chem. Int. Ed. 56, 15246–15251. doi: 10.1002/anie.201706101
Herreros, M. L., Tagarro, A., García-Pose, A., Sánchez, A., Cañete, A., and Gili, P. (2015). Accuracy of a new clean-catch technique for diagnosis of urinary tract infection in infants younger than 90 days of age. Paediatr. Child Health 20, e30–e32. doi: 10.1093/pch/20.6.286
Klymchenko, A. S., Pivovarenko, V. G., and Demchenko, A. P. (2003). Elimination of the hydrogen bonding effect on the solvatochromism of 3-Hydroxyflavones. J. Phys. Chem. A 107, 4211–4216. doi: 10.1021/jp027315g
Kommedal, O., Karlsen, B., and Saebo, O. (2008). Analysis of mixed sequencing chromatograms and its application in direct 16S rRNA gene sequencing of polymicrobial samples. J. Clin. Microbiol. 46, 3766–3771. doi: 10.1128/JCM.00213-08
Kubicek-Sutherland, J., Vu, D., Mendez, H., Jakhar, S., and Mukundan, H. (2017). Detection of lipid and amphiphilic biomarkers for disease diagnostics. Biosensors 7:25. doi: 10.3390/bios7030025
Laitinen, R., Malinen, E., and Palva, A. (2002). PCR-ELISA: I: application to simultaneous analysis of mixed bacterial samples composed of intestinal species. Syst. Appl. Microbiol. 25, 241–248. doi: 10.1016/S0723-2020(04)70108-3
Leonard, H., Colodner, R., Halachmi, S., and Segal, E. (2018). Recent advances in the race to design a rapid diagnostic test for antimicrobial resistance. ACS Sensors 3, 2202–2217. doi: 10.1021/acssensors.8b00900
Li, T., Zhu, S., and Ogihara, M. (2006). Using discriminant analysis for multi-class classification: an experimental investigation. Knowl. Inf. Syst. 10, 453–472. doi: 10.1007/s10115-006-0013-y
Li, Z., Askim, J. R., and Suslick, K. S. (2019). The optoelectronic nose: colorimetric and fluorometric sensor arrays. Chem. Rev. 119, 231–292. doi: 10.1021/acs.chemrev.8b00226
Phillips, R. L., Miranda, O. R., You, C.-C., Rotello, V. M., and Bunz, U. H. F. (2008). Rapid and efficient identification of bacteria using gold-nanoparticle–Poly(para-phenyleneethynylene) constructs. Angew. Chem. Int. Ed. 47, 2590–2594. doi: 10.1002/anie.200703369
Rana, S., Elci, S. G., Mout, R., Singla, A. K., Yazdani, M., Bender, M., et al. (2016). Ratiometric array of conjugated polymers–fluorescent protein provides a robust mammalian cell sensor. J. Am. Chem. Soc. 138, 4522–4529. doi: 10.1021/jacs.6b00067
Sheldon, I. M. (2016). Detection of pathogens in blood for diagnosis of sepsis and beyond. EBioMedicine 9, 13–14. doi: 10.1016/j.ebiom.2016.06.030
Svechkarev, D., Kyrychenko, A., Payne, W. M., and Mohs, A. M. (2018a). Probing the self-assembly dynamics and internal structure of amphiphilic hyaluronic acid conjugates by fluorescence spectroscopy and molecular dynamics simulations. Soft Matter 14, 4762–4771. doi: 10.1039/C8SM00908B
Svechkarev, D., Sadykov, M. R., Bayles, K. W., and Mohs, A. M. (2018b). Ratiometric fluorescent sensor array as a versatile tool for bacterial pathogen identification and analysis. ACS Sensors 3, 700–708. doi: 10.1021/acssensors.8b00025
Tao, Y., and Auguste, D. T. (2016). Array-based identification of triple-negative breast cancer cells using fluorescent nanodot-graphene oxide complexes. Biosens. Bioelectron. 81, 431–437. doi: 10.1016/j.bios.2016.03.033
Tomberg, A., Johansson, M. J., and Norrby, P.-O. (2019). A predictive tool for electrophilic aromatic substitutions using machine learning. J. Org. Chem. 84, 4695–4703. doi: 10.1021/acs.joc.8b02270
Váradi, L., Luo, J. L., Hibbs, D. E., Perry, J. D., Anderson, R. J., Orenga, S., et al. (2017). Methods for the detection and identification of pathogenic bacteria: past, present, and future. Chem. Soc. Rev. 46, 4818–4832. doi: 10.1039/C6CS00693K
Zhang, L., Huang, X., Cao, Y., Xin, Y., and Ding, L. (2017). Fluorescent binary ensemble based on pyrene derivative and sodium dodecyl sulfate assemblies as a chemical tongue for discriminating metal ions and brand water. ACS Sensors 2, 1821–1830. doi: 10.1021/acssensors.7b00634
Keywords: multiparametric sensing, 3-hydroxyflavone, ESIPT, pathogenic bacteria, discriminant analysis, machine learning, pattern analysis
Citation: Svechkarev D, Sadykov MR, Houser LJ, Bayles KW and Mohs AM (2020) Fluorescent Sensor Arrays Can Predict and Quantify the Composition of Multicomponent Bacterial Samples. Front. Chem. 7:916. doi: 10.3389/fchem.2019.00916
Received: 15 November 2019; Accepted: 17 December 2019;
Published: 15 January 2020.
Edited by:
Jinsong Han, China Pharmaceutical University, ChinaReviewed by:
Benhua Wang, Central South University, ChinaXiaolong Sun, Xi'an Jiaotong University (XJTU), China
Copyright © 2020 Svechkarev, Sadykov, Houser, Bayles and Mohs. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Denis Svechkarev, ZGVuaXMuc3ZlY2hrYXJldkB1bm1jLmVkdQ==; Aaron M. Mohs, YWFyb24ubW9oc0B1bm1jLmVkdQ==