 Ulysse Côté-Allard1*†
Ulysse Côté-Allard1*† Evan Campbell2*†
Evan Campbell2*† Angkoon Phinyomark2
Angkoon Phinyomark2 François Laviolette3Benoit Gosselin1‡
François Laviolette3Benoit Gosselin1‡ Erik Scheme2‡
Erik Scheme2‡- 1Department of Computer and Electrical Engineering, Université Laval, Quebec, QC, Canada
- 2Department of Electrical and Computer Engineering, Institute of Biomedical Engineering, University of New Brunswick, Fredericton, NB, Canada
- 3Department of Computer Science and Software Engineering, Université Laval, Quebec, QC, Canada
Existing research on myoelectric control systems primarily focuses on extracting discriminative characteristics of the electromyographic (EMG) signal by designing handcrafted features. Recently, however, deep learning techniques have been applied to the challenging task of EMG-based gesture recognition. The adoption of these techniques slowly shifts the focus from feature engineering to feature learning. Nevertheless, the black-box nature of deep learning makes it hard to understand the type of information learned by the network and how it relates to handcrafted features. Additionally, due to the high variability in EMG recordings between participants, deep features tend to generalize poorly across subjects using standard training methods. Consequently, this work introduces a new multi-domain learning algorithm, named ADANN (Adaptive Domain Adversarial Neural Network), which significantly enhances (p = 0.00004) inter-subject classification accuracy by an average of 19.40% compared to standard training. Using ADANN-generated features, this work provides the first topological data analysis of EMG-based gesture recognition for the characterization of the information encoded within a deep network, using handcrafted features as landmarks. This analysis reveals that handcrafted features and the learned features (in the earlier layers) both try to discriminate between all gestures, but do not encode the same information to do so. In the later layers, the learned features are inclined to instead adopt a one-vs.-all strategy for a given class. Furthermore, by using convolutional network visualization techniques, it is revealed that learned features actually tend to ignore the most activated channel during contraction, which is in stark contrast with the prevalence of handcrafted features designed to capture amplitude information. Overall, this work paves the way for hybrid feature sets by providing a clear guideline of complementary information encoded within learned and handcrafted features.
1. Introduction
Surface Electromyography (sEMG) is a technique employed in a vast array of applications from assistive technologies (Phinyomark et al., 2011c; Scheme and Englehart, 2011) to bio-mechanical analysis (Andersen et al., 2018), and more generally as a way to interface with computers and robots (Zhang et al., 2009; St-Onge et al., 2019). Traditionally, the sEMG-based gesture recognition literature primarily focuses on feature engineering as a way to increase the information density of the signal to improve gesture discrimination (Oskoei and Hu, 2007; Scheme and Englehart, 2011; Phinyomark et al., 2012a). In the last few years, however, researchers have started to leverage deep learning (Allard et al., 2016; Atzori et al., 2016; Phinyomark and Scheme, 2018a), shifting the paradigm from feature engineering to feature learning.
Deep learning is a multi-level representation learning method (i.e., methods that learn an embedding from an input to facilitate detection or classification), where each level generates a higher, more abstract representation of the input (LeCun et al., 2015). Conventionally, the output layer (i.e., classifier or regressor) only has direct access to the output of the highest representation level (LeCun et al., 2015; Alom et al., 2018). In contrast, several works have also fed the intermediary layers' output directly to the network's head (Sermanet et al., 2013; Long et al., 2015; Yang and Ramanan, 2015). Arguably, the most successful approach using this design philosophy is DenseNet (Huang et al., 2017), a type of convolutional network (ConvNet) where each layer receives the feature maps of all preceding layers as input. Features learned by ConvNets were also extracted to be employed in conjunction with (or replace) handcrafted features when training conventional machine learning algorithms (e.g., support vector machine, linear discriminant analysis, decision tree) (Poria et al., 2015; Nanni et al., 2017; Chen et al., 2019; Liu et al., 2019). Within the context of sEMG-based gesture recognition, deep learning was shown to be competitive with the current state of the art (Côté-Allard et al., 2019a) and when combined with handcrafted features, to outperform it (Chen et al., 2019). This last result seems to indicate that, for sEMG signals, deep-learned features provide useful information that may be complementary to those that have been engineered throughout the years. However, the black box nature of these deep networks means that understanding what type of information is encapsulated throughout the network, and how to leverage this information, is challenging.
The main contribution of this work is, therefore, to provide the first extensive analysis of the relationship between handcrafted and learned features within the context of sEMG-based gesture recognition. Understanding the feature space learned by the network could shed new insights on the type of information contained in sEMG signals. In turn, this improved understanding will allow the creation of better handcrafted features and facilitate the creation of new hybrid feature sets using this feature learning paradigm.
An important challenge arises when working with biosignals, as extensive variability exists between subjects (Guidetti et al., 1996; Batchvarov and Malik, 2002; Meltzer et al., 2007; Castellini et al., 2009; Halaki and Ginn, 2012). Especially within the context of sEMG-based gesture recognition (Castellini et al., 2009; Halaki and Ginn, 2012). Consequently, features learned using traditional deep learning training methods can be highly participant-specific, which would hinder the goal of this work of learning a general feature representation of sEMG signals. By defining each participant as a different domain, however, this issue can be framed as a Multi-Domain Learning problem (MDL) (Yang and Hospedales, 2014), with the added restriction that the network's weights should be participant-agnostic. Multiple popular and effective MDL algorithms have been proposed over the years (Nam and Han, 2016; Rebuffi et al., 2018). For example, Nam and Han (2016) proposed to use a shared network across multiples domains with one predictive head per domain. In Yang and Hospedales (2014), a single head was shared across two parallel networks with one of them receiving the example's representation as input, while the other receives a vector representation of the associated domain of the example. These algorithms however are ill-suited for this work's context as they: do not explicitly impose domain-agnostic weight learning (Yang and Hospedales, 2014), can scale poorly with the number of domains (i.e., participants) (Nam and Han, 2016), or are restricted to encode a single domain within their learned features (and use adaptor blocks to bridge the gap between domains) (Rebuffi et al., 2018). Unsupervised domain-adversarial training algorithms (Ajakan et al., 2014; Ganin et al., 2016; Tzeng et al., 2017; Shu et al., 2018) predict an unlabeled dataset by learning a representation on a labeled dataset that makes it hard to distinguish between examples from either distribution. However, these algorithms are often not designed to learn a unique representation across more than two domains simultaneously (Ajakan et al., 2014; Ganin et al., 2016; Tzeng et al., 2017; Shu et al., 2018), can be destructive to the source domain representation (through iterative process) (Shu et al., 2018), and by nature of the problem they are trying to solve, do not leverage the labels of the target domains. As such, this work presents a new multi-domain adversarial training algorithm, named ADANN (Adaptive Domain Adversarial Neural Network). ADANN trains a network across multiple domains simultaneously while explicitly penalizing any domain-variant representations to study learned features that generalize well across participants.
In this work, the sEMG information encapsulated within the general deep learning features learned by ADANN, is characterized using handcrafted features as landmarks in a topological network. This network is generated via the Mapper algorithm (Singh et al., 2007), with t-Stochastic Neighbor Embedding (t-SNE) (Maaten and Hinton, 2008), a non-linear dimensionality reduction visualization method, as the filter function. Mapper is a Topological Data Analysis (TDA) tool that excels at determining the shape of high dimensional data, by providing a faithful representation of it through a topological network. This TDA tool has been applied as a solution to numerous challenging applications across a wide array of domains; for example, uncovering the dynamic organization of brain activity during various tasks (Saggar et al., 2018) or identifying a subgroup of breast cancer with 100% survival rate and no metastasis (Nicolau et al., 2011). Mapper has also been applied to determine relationships between feature space for physiological signal pain recognition (Campbell et al., 2019b), and EMG-based gesture recognition (Phinyomark et al., 2017). However, to the best of the authors' knowledge, the use of TDA to interpret information harnessed within deep-learned features using handcrafted features as landmarks has yet to be explored.
In this paper, convNet visualization techniques are also leveraged as a way to highlight how the network makes class-discriminant decisions. Several works (Simonyan et al., 2013; Springenberg et al., 2014; Zeiler and Fergus, 2014; Gan et al., 2015) have proposed to visualize network's predictions by emphasizing which input-pixels have the most impact on the network's output, consequently, fostering a better understanding of what the network has learned. For example, Simonyan et al. (2013) used partial derivatives to compute pixel-relevance for the network output. Another example is Guided Backpropagation (Springenberg et al., 2014), which modifies the computation of the gradient to only include paths within the network that positively contribute to the prediction of a given class. When compared with saliency maps (Simonyan et al., 2013), Guided Backpropagation results in qualitative visualization improvements (Selvaraju et al., 2017). While these methods produce resolutions at a pixel level, the images produced with respect to different classes are nearly identical (Selvaraju et al., 2017). Other types of algorithms provide highly class-discriminative visualizations, but at a lower resolution (Selvaraju et al., 2016; Zhou et al., 2016) and sometimes require a specific ConvNet architecture (Zhou et al., 2016) to use. Within this work, Guided Gradient-weighted Class Activation Mapping (Guided Grad-CAM) (Selvaraju et al., 2017) is employed as it provides pixel-wise input resolution while being class-discriminative. Another advantage of this technique is that it can be implemented on any ConvNet-based architecture without requiring re-training. To the best of the authors' knowledge, this is the first time that deep learning visualization techniques are applied to EMG signals.
2. Materials and Methods
A flowchart of the material, methods and experiment is shown in Figure 1. This section is divided as follows: first, a description of the dataset and preprocessing used in this work is given in section 2.1. Then, the handcrafted features are presented in section 2.2. The ConvNet architecture and the new multi-domain adversarial training algorithm (ADANN) are presented in sections 2.3.1 and 2.3.2, respectively. A brief overview of Guided Grad-CAM is given in section 2.3.3, while sections 2.3.4 and 2.3.5 present single feature classification and handcrafted feature regression, respectively. Finally, the Mapper algorithm is detailed in section 2.4.
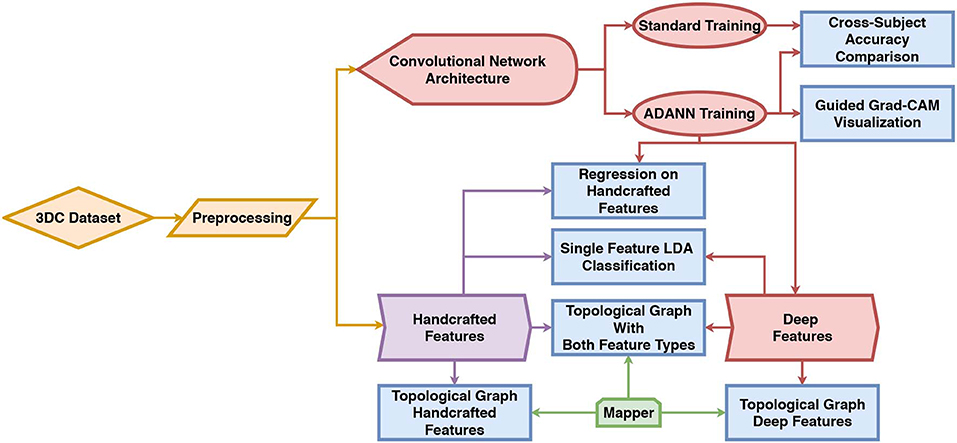
Figure 1. Diagram of the workflow of this work. The 3DC Dataset is first preprocessed before being used to train the network using standard training and the proposed ADANN training procedure. The handcrafted features are directly calculated from the preprocessed dataset, while the deep features are extracted from the ConvNet trained with ADANN. In the diagram, the blue rectangles represent experiments and the arrows show which methods/algorithms are required to perform them.
2.1. EMG Data
The dataset employed in this work is the 3DC Dataset (Côté-Allard et al., 2019b), featuring 22 able-bodied participants performing ten hand/wrist gestures + neutral (see Figure 2 for the list of gestures). This dataset was recorded with the 3DC Armband; a wireless, 10-channel, dry-electrode, 3D printed sEMG armband. The device samples data at 1,000 Hz per channel, allowing the feature extraction to take advantage of the full spectra of sEMG signals (Phinyomark and Scheme, 2018b). Informed consent was obtained from all participants, as approved by Laval University's Research Ethics Committee (Côté-Allard et al., 2019b).

Figure 2. The eleven hand/wrist gestures recorded in the 3DC Dataset (image re-used from Côté-Allard et al., 2019b).
The dataset was built as follows: Each participant was asked to perform and hold each gesture for a period of 5 s starting from the neutral position to produce a cycle. Three more cycles were recorded to serve as the training dataset. After a 5 min break, four new cycles were recorded to serve as the test dataset. Note that the validation set and hyperparameter selection are made from the training dataset.
As this work aims to understand the type of features learned by deep network in the context of myoelectric control systems, a critical factor to consider is the input latency. Smith et al. (2010) showed that the optimal guidance latency was between 150 and 250 ms. As such, the data from each participant was segmented into 151 ms frames with an overlap of 100 ms. The raw data was then band-pass filtered between 20 and 495 Hz using a fourth-order Butterworth filter.
2.2. Handcrafted Features
Handcrafted features are characteristics extracted from windows of the EMG signal using established mathematical equations. The purpose of these feature extraction methods is to enhance the information density of the signal so as to improve discrimination between motion classes (Oskoei and Hu, 2007; Phinyomark et al., 2012a). Across the myoelectric control literature, hundreds of handcrafted feature extraction methods have been presented (Oskoei and Hu, 2007; Phinyomark et al., 2012a, 2013). As such, implementing the exhaustive set of features that has been proposed is impractical. Instead, within this study a comprehensive subset of 79 of the most commonly used features is employed. With a comprehensive set of features, past literature has identified five functional groups that summarize all sources of information current handcrafted feature extraction techniques describe: signal amplitude and power (SAP), non-linear complexity (NLC), frequency information (FI), time-series modeling (TSM), and unique (UNI) (Phinyomark et al., 2017; Campbell et al., 2019a). The SAP functional group includes time-domain energy or power features (e.g., Root Mean Squared, Mean Absolute Value). The FI functional group generally refers to features extracted from the frequency domain, or features that describe spectral properties (e.g., Mean Frequency, Zero Crossings). The NLC functional group corresponds to features that describe entropy or similarity based information (e.g., Sample Entropy, Maximum Fractal Length). The TSM functional group represents features that attempt to reconstruct the data provided through stochastic or other algorithmic models (e.g., Autoregressive Coefficients, Cepstral Coefficients). Finally, the UNI functional group represents features that capture various other modalities of information, such as measures of signal quality or a combination of other functional groups (e.g., Signal to Motion Artifact Ratio, Time Domain Power Spectral Descriptors).
Table 1 presents the 56 handcrafted feature methods considered in this work. Note that some methods produce multiple features (e.g., Cepstral Coefficients, Histogram), resulting in a total of 79 features. The SAP, FI, NLC, TSM, and UNI feature groups are represented here by 25, 5, 6, 7, and 13 feature extraction methods, respectively. In the TDA of the deep learned features (see section 2.4), these handcrafted features serve as landmarks for well-understood properties of the EMG signal. In the regression model analysis (see section 2.3.5), the flow of information through the ConvNet is visualized by employing the handcrafted features methods as the target of the network.
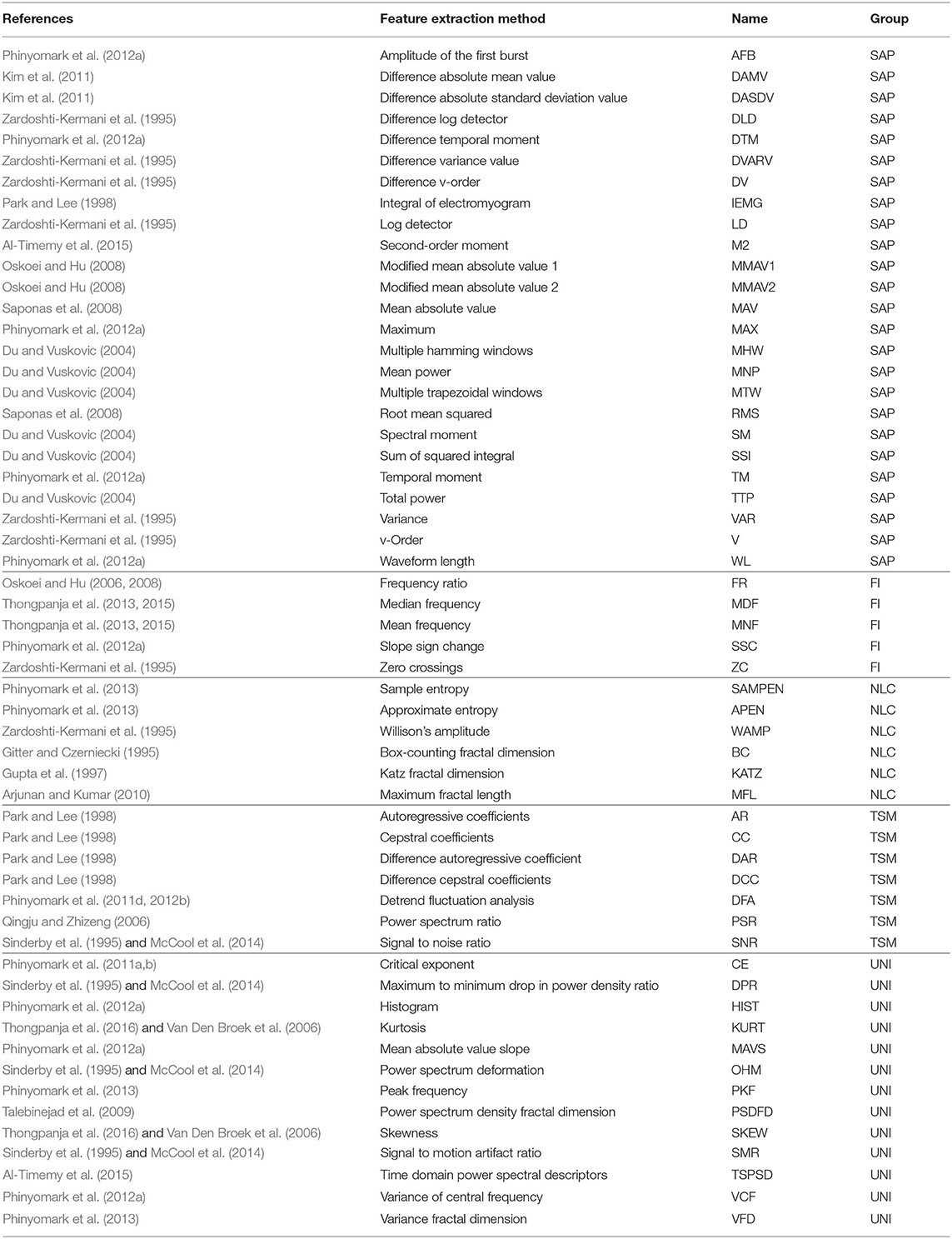
Table 1. Handcrafted features extracted for topological landmarks sorted by functional group.
2.3. Convolutional Network
The following subsections present the deep learning architecture, training methods and visualization techniques employed in this paper. The PyTorch (Paszke et al., 2017) implementation employed in this work is available at: https://github.com/UlysseCoteAllard/sEMG_handCraftedVsLearnedFeatures.
2.3.1. Architecture
Recent works on sEMG-based gesture recognition using deep learning have shown that ConvNets trained with the raw sEMG signal as input were able to achieve similar classification accuracy to the current state of the art (Zia ur Rehman et al., 2018; Côté-Allard et al., 2019a). Consequently, and to reduce bias, the preprocessed raw data (see section 2.1) is passed directly as an image of shape 10 × 151 (Channel × Sample) to the ConvNet.
The ConvNet's architecture, which is depicted in Figure 3, contains six blocks followed by a fully connected layer for gesture-classification. The network's topology was selected to obtain a deep network with a limited number of learnable parameters (to avoid overfitting) with simple layer connections to enable an easier, and thus more thorough analysis. All architecture choices and hyperparameter selection were performed using the training set of the 3DC Dataset or inspired by previous works (Côté-Allard et al., 2019a,b). Each block encapsulates a convolutional layer (LeCun et al., 2015), followed by batch normalization (BN) (Ioffe and Szegedy, 2015), leaky ReLU (slope = 0.1) (Xu et al., 2015) and dropout (Gal and Ghahramani, 2016) (with a drop rate set at 0.35 following Côté-Allard et al., 2019a). The number of blocks within the network was selected to obtain a sufficiently deep network to study how the type of learned features evolve with respect to their layer. The depth of the network was limited by the number of examples available for training and more complex layer connections [e.g., residual network (He et al., 2016), dense network (Huang et al., 2017)] were avoided to not ambiguate the analysis performed in this work. The number of feature maps (64) was kept uniform for each layer, allowing for easier comparisons of learned features across the convolutional layers. The filter size was 1 × 26 so that, similarly to the handcrafted features, the learned features are channel independent. Due to the selected filter size, the dimensions of feature maps at the final layer is 10 × 1.
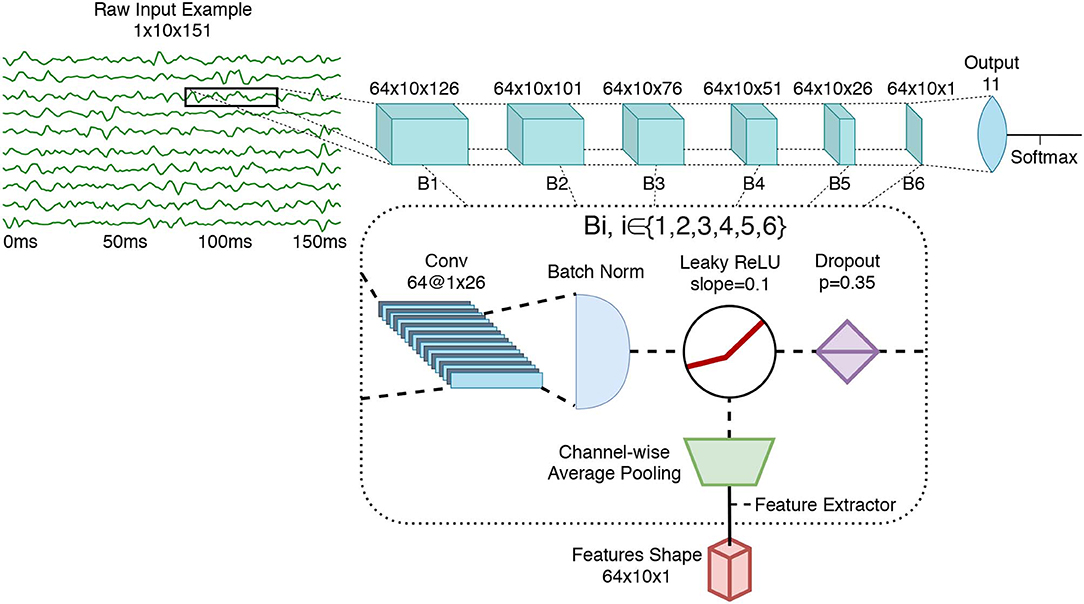
Figure 3. The ConvNet's architecture, employing 543,629 learnable parameters. In this figure, Bi refers to the ith feature extraction block (i∈{1,2,3,4,5,6}). Conv refers to Convolutional layer. As shown, the feature extraction is performed after the non-linearity (leaky ReLU).
Adam (Kingma and Ba, 2014) was employed to optimize the ConvNet with an initial learning rate of 0.0404709 and batch size of 512 (as used in Côté-Allard et al., 2019b). The training dataset was divided into training and validation sets using the first three cycles and last cycle, respectively. Employing this validation set, learning rate annealing was applied with a factor of five and a patience of fifteen with early stopping applied when two consecutive annealings occurred without achieving a better validation loss.
For the purpose of the TDA, features maps were extracted after the non-linearity using per feature-map channel-wise average pooling. That is, the number of feature maps remained the same, but the feature map's value per channel was averaged to a single scalar (as is common with handcrafted features).
2.3.2. Multi-Domain Adversarial Training
To better understand what type of features are commonly learned at each layer of the network, it is desirable that the model generalizes well across participants. This feature generality principle also motivates the design of the handcrafted features (presented in section 2.2), as it would be impractical to create new features for each new participant. Learning a general feature representation across participants, however, cannot be achieved by simply aggregating the training data of all participants and then training a classifier normally. As, even when precisely controlling for electrode placement, cross-subject accuracy using standard learning methods is poor (Castellini et al., 2009). This problem is compounded by the fact that important differences exist between subjects of the 3DC Dataset (i.e., position and rotation of the armband placed on the left or right arm).
Learning a participant-agnostic representation can be framed as a multi-domain learning problem (Nam and Han, 2016). In the context of sEMG-based gesture recognition, AdaBN, a domain adaptation algorithm presented in Li et al. (2016), was successfully employed as a way to learn a general representation across participants in Cote-Allard et al. (2017), Côté-Allard et al. (2019a). The hypothesis of AdaBN is that label-related information (i.e., hand gestures) will be contained within the network's weights, while the domain-related information (i.e., participants) are stored in their BN statistics. Training is thus performed by sharing the weights of the network across the subjects dataset while tracking the BN statistics independently for each participant.
To inhibit the shared network's weights from learning subject-specific representation, Domain-Adversarial Neural Networks (DANN) training (Ganin et al., 2016) is employed. DANN is designed to learn domain-invariant features across two domains from the point of view of the desired task. The approach used by DANN to achieve this objective consists of adding a second head (referred to as the domain classification head) to the network presented in section 2.3.1, which receives the output of block B6. The goal of this second head is to learn to discriminate between the domains. However, during backpropagation, the gradient computed from the domain loss is multiplied by a negative constant (set to -1 in this work) as it exits the domain classification head. This gradient reversal explicitly forces the feature distributions over the domains to be similar. Note that the backpropagation algorithm proceeds normally for the first head (gesture classification head). The loss function used for both heads is the cross-entropy loss. The two losses are combined as follows: , where and are the prediction and domain loss, respectively (see Figure 4), while λ is a scalar that weights the domain loss (set to 0.1 in this work).
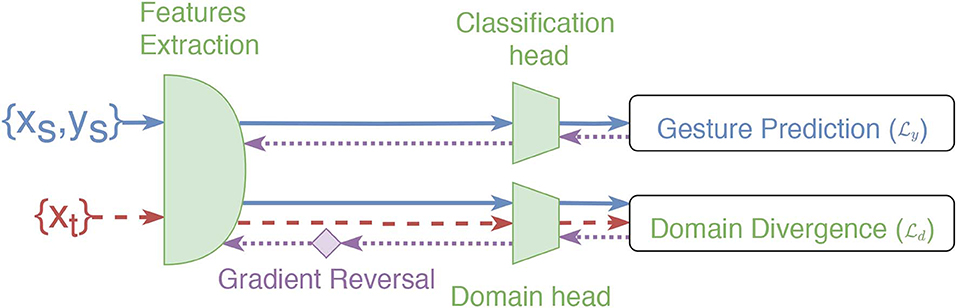
Figure 4. Overview of the training steps of ADANN (identical to DANN) for one labeled batch from the source ({xs, ys}, blue lines) and one unlabeled batch from the target ({xt}, red dashed lines). The purple dotted lines correspond to the backpropagated gradient. The gradient reversal operation is represented by the purple diamond.
Using this approach, each participant of the 3DC Dataset represents a different domain (n=22). A direct application of DANN would thus initialize the domain classification head with 22 output neurons. This, however, could create a pitfall where the network is able to differentiate between the domains perfectly while simply predict one of the 21 other domains to maximize . Instead, the domain classification head is initialized with only two output neurons. At each epoch, a batch is created that contains examples from a single participant (this batch is referred to as the source batch, and is assigned the domain label 0). A second batch, referred to as the target batch, is also created that contains examples from one of the other participants selected at random, and is assigned the domain label 1. As every participants data is used as the source batch at each epoch, this ensures that the network is forced to learn a domain-independent feature representation. ADANN's goal is thus to force the network to be unable to accurately associate a participant with their examples while achieving a highly discriminative gesture representation across all participants. During training, the BN statistics are tracked individually for each subject. Therefore, when learning from a source or target batch, the network uses the BN statistics associated with the corresponding participant. Note that, by construction, the participant associated with the source is necessarily different from the participant associated with the target. Consequently, the network is fed the source and target batch consecutively (i.e., not both batch simultaneously). Also note that the BN statistics are updated only in association with the source batch to ensure equal training updates across all participants. For a given iteration, once the source and target batch are constructed, the training step proceeds as described for DANN (see Figure 4).
To assess the performance of the proposed MDL algorithm, two identical ConvNet (as described in section 2.3.1) were created. One of the ConvNets was trained with ADANN, whereas the other used a standard training loop (i.e., aggregating the data from all participants), with both using the same hyperparameters. The networks trained with both methods were then tested on the test dataset with no participant-specific fine-tuning.
2.3.3. Learning Visualization
One of the main problems associated with deep learning is interpretability of how and why a model makes a prediction given a particular input. A first step in understanding a network prediction is through the visualization of the learned weights, feature maps and gradients resulting from a particular input. Consequently, several sophisticated visualization techniques have been developed, which are aimed at facilitating a better comprehension of the hierarchical learning that takes place within a network (Simonyan et al., 2013; Springenberg et al., 2014; Zhou et al., 2016). One popular such technique is Guided Grad-CAM, which combines high resolution pixel-space gradient visualization and class-discriminative visualization (Selvaraju et al., 2017). Guided Grad-CAM is thus employed to visualize how the ConvNet trained with ADANN makes its decisions, both on real examples from the 3DC Dataset and on an artificially generated signals.
Given an image that was used to compute a forward pass in the network and a label y, the output of Guided Grad-CAM is calculated from four distinct steps (note that steps two and three are computed independently from each other using the output of step one):
1. Set all the gradients of the output neurons to zero, except for the gradient of the neuron associated with the label y (which is set to one) and name the gradient of the neuron of interest yg.
2. Set all negative activations to zero. Then, perform backpropagation, but before propagating the gradient at each step, set all the negative gradients to zero again. Save the final gradients corresponding to the input image. This step corresponds to computing the guided backpropagation (Springenberg et al., 2014).
3. Let Fj, i be the activation of the ith feature map of the jth layer with feature maps of the network. Select a layer Fj of interest (in this work Fj correspond to the rectified convolutional layer of B6). Backpropagate the signal from the output layer to Fj, i (i.e., ). Then for each i compute the global average pooling of and name it wj, i. Finally, compute:
This third step corresponds to computing the Gradient-weighted Class Activation Mapping (Grad-CAM) (Selvaraju et al., 2016).
4. Finally, fuse the output of the two previous steps using point-wise multiplication to obtain the output of Guided Grad-CAM (Selvaraju et al., 2017).
2.3.4. Learned Feature Classification
Similarly to Chen et al. (2019), the learned features were extracted to train a Linear Discriminant Analysis (LDA) classifier to show the discriminative ability of the learned features. LDA was selected as it was shown to provide robust classification within the context of sEMG-based gesture recognition (Campbell et al., 2019c), does not require hyperparameter tuning, and creates linear boundaries within the input feature space. LDA was trained in a cross-subject framework on the training dataset and tested on the test dataset. For comparison purposes, LDA was also trained on the handcrafted features described in section 2.2. Note that the implementation was from scikit-learn (Pedregosa et al., 2011).
2.3.5. Regression Model
One method of highlighting the information content encoded throughout a network is to see how well-known handcrafted features can be predicted from the network's feature maps at different stages. This can be achieved using an added output neuron (regression head) at the feature extraction stage [i.e., after the non-linearity, but before the average pooling (before the green trapezoid of Figure 3)] of each block. The goal of this output is to map from the learned features to the handcrafted features of interest. As all the features considered in section 2.2 are calculated channel-wise, only the information from the first sEMG channel (arbitrarily selected) of the feature maps will be fed to the regression head.
The training procedure to implement this is as follows: first, pre-train the network using ADANN (presented in section 2.3.2). Second, freeze all the weights of the network, except for the weights associated with the regression head of the block of interest. The Mean Square Error (MSE) is then employed as the loss function with the target being the value of the handcrafted feature of interest from the first sEMG channel. Due to the stochastic nature of the algorithm, the training was performed 20 times for each participant and the results were given as the average MSE computed on the test dataset across of all participants. Note that the targets derived from multi-output feature extraction methods (e.g., Autoregressive Coefficients) corresponded to the first principal component returned by Principal Component Analysis (PCA) (where singular value decomposition was performed on the training and test set for the training and test phase, respectively).
2.4. Topological Data Analysis—Mapper
Conventional TDA methods, such as Isomap (Balasubramanian and Schwartz, 2002) produce a low dimensional embedding by retaining geodesic distances between neighboring points. However, they often have limited topological stability (Choi and Choi, 2007) and lack the ability to produce a simplicial complex (a ball-and-stick simplification of the shape of the dataset) with size smaller than the original dataset (Singh et al., 2007). The Mapper algorithm (Singh et al., 2007) is a TDA method that creates interpretable simplifications of high-dimensional data sets that remain true to the shape of the data set. Mapper can thus produce a stable representation of the topological shape of the dataset at a specified resolution, where the shape of the network has been simplified during a partial clustering stage. Further, the shape of the dataset is defined such that it is coordinate, deformation, and compression invariant. Consequently, this TDA algorithm can be employed to better understand how handcrafted and deep-learned features relate to one-another. In this work, Mapper is employed on three scenarios; (A), (B), and (C). In scenario (A), the algorithm only uses the handcrafted features as a way to validate the hyperparameters selected by cross-referencing the results with previous EMG works using Mapper (Phinyomark et al., 2017; Campbell et al., 2019a). For scenario (B), only the learned features are used to determine if features within the same block extract similar or dissimilar sources of information (i.e., the degree at which the features within the same block are dispersed across the topological network). Finally, in scenario (C), Mapper is applied to the combination of learned and handcrafted features to better understand their relationship and to provide new avenues of research for sEMG-based gesture recognition.
Sections 2.4.1–2.4.2, below, provide additional details about the approach, mathematical basis and implementation of Mapper in this work. Readers who are familiar with, or prefer to avoid these details, may jump directly to section 3.
2.4.1. Mapper Algorithm
The construction of the topological network created using the Mapper algorithm can be seen as a five stage pipeline:
1. prepare: organize the data set to produce a point cloud of features in high dimensional space.
2. lens: filter the high dimensional data into a lower dimensional representation using a lens.
3. resolution: divide the filtration into a set of regions.
4. partial clustering: for each region, cluster the contents in the original high dimensional space.
5. combine: combine the region isolated clusters into a single topological network using common points across regions (Geniesse et al., 2019).
2.4.2. Mathematical Definition of Mapper
A mathematical definition of the Mapper algorithm for feature extraction using a multi-channel recording device is as follows:
Let be a series of samples for each C channels, where and S is the length of a consecutive series of data. Define a set of N examples. Let also be a set of M feature-generating functions of the form . Given xn, c the c th element of xn ∈ X, the resulting feature is obtained by applying ϕm such that . Consequently, the vector is obtained such that .
The first step of the Mapper algorithm is to consider , the transformed data points from X. Then define ψ:ℝN × C → ℝZ, with 0 < Z ≪ N × C and consider the set . This dimensionality reduction (N × C → Z) is employed to reduce the computational cost of the rest of the Mapper algorithm and can be considered as a hyperparameter of the Mapper algorithm.
In the second step of the algorithm, define σ:ℝZ → ℝW, with 0 < W ≪ Z and consider the set . In the literature (Singh et al., 2007), the function σ is called filter function and W is the image or lens.
Third, let ℭ be the smallest hypercube of ℝW which covers W entirely. As X is a finite set, each dimension of ℭ is a finite interval. Let k ∈ ℕ*, be a hyperparameter that subdivides ℭ evenly into kW smaller hypercubes. Note that the side lengths of these smaller hypercubes are the length size of ℭ. Denotes V the set of all vertices of these smaller hypercubes. Next, fix D > H as another hyperparameter. For each , consider the hypercube of length D centered on . A visualization of step 3 is given in Figure 5.
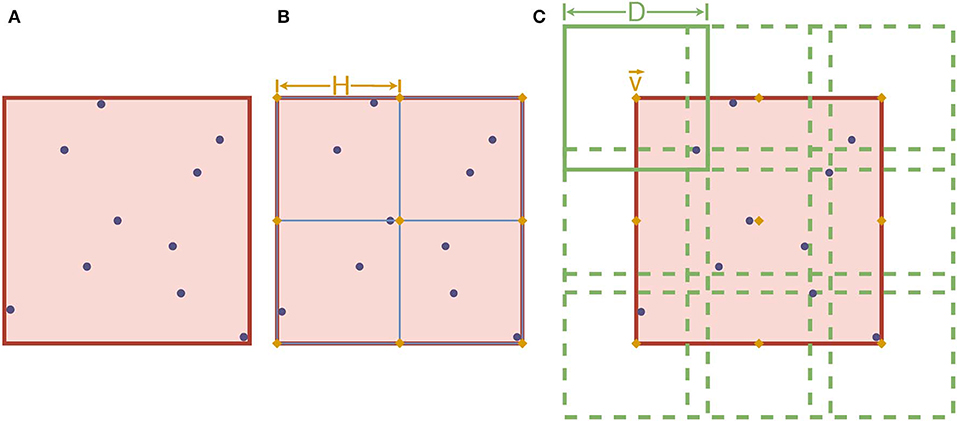
Figure 5. An example of step 3 of the Mapper algorithm with W = 2. The purple dots represent the elements of W. In (A), the red square corresponds to ℭ. In (B), ℭ is subdivided using k2 squares of length H (with k = 2 in this case). The orange diamonds, in both (B,C), represent the elements of V. Finally, the square of length D is shown on the upper left corner of (C), overlapping other squares centered on other elements of V (dotted lines).
Fourth, define , the set of all elements of Z that is projected in the hypercube . Let ξ be a clustering algorithm and be the resulting set of clusters. Define B as the set that consist of all so obtained clusters for all .
Fifth, compute the topological graph G using each element of B as a vertex and create an edge between vertices Gi and Gj (i, j ∈ {1, …, |B|}, i ≠ j) if Gi ∩ Gj ≠ ∅.
2.4.3. Mapper Implementation Within This Work
In this work, as described in section 2.1 the dataset was recorded using the 3DC Armband which offers 10 channel-recording (C = 10) and an example is comprised of 151 data-points (S = 151) for each channel. The number of considered features in scenarios (A), (B), and (C), are 79, 384, and 465, respectively. Note that multi-output feature extraction techniques (e.g., AR, HIST), consider each component of that vector as a separate feature. Each element of F is obtained by computing the result of a feature from section 2.2 (corresponding to ϕm() in the mathematical definition given previously) over each channel of each example of the Training Dataset. The dataset undergoes the first dimensionality reduction (Ψ()) using PCA (Wold et al., 1987), where the number of principal components used corresponds to 99% of the total variance. For scenarios (A), (B), and (C), 99% of the variance resulted in 44, 77, and 119 components, respectively, extracted from 971,860 channel-wise examples.
A second dimensionality reduction is then performed (σ()), referred to as the filter function, with the goal of representing meaningful characteristics of the relationship between features (Singh et al., 2007). Within this study, t-Stochastic Neighborhood Embedding (t-SNE) (Maaten and Hinton, 2008) is used to encapsulate important local structure between features. The two-dimensional (2D) t-SNE lens was constructed with a perplexity of 30, as this configuration resulted in the most stable visualization over many repetitions [tested on scenario (A)]. Using t-SNE as part of the Mapper algorithm instead of on its own leverages its ability to represent local structure while avoiding the use of a low-dimensional manifold to encapsulate global structure. Instead, the global structure is predominantly incorporated into the topological network produced by Mapper during the fifth stage.
The 2D lens was then segmented into a set of overlapped bins (the hypercubes centered on the elements of V), called the cover. A stable topological network was obtained when each dimension was divided into 5 regions, forming a grid of 25 cubes that were overlapped by 65%. The number of regions correspond to the topological network's resolution, while the overlap has an influence on the amount of connection formed between nodes (Singh et al., 2007).
Data points in each region are then clustered in isolation to provide insight into the local structure of the feature space (the elements of correspond to the data-point of a specific region). For each region, Ward's hierarchical clustering (ξ) was applied to construct a dendogram that grouped similar features together according to a reduction in cluster variance (Ward, 1963).
Finally, the dendograms produced using neighboring regions are combined to form the topological network (G) using the features that lie in the overlapped area to construct the edges between the nodes.
The implementation of the Mapper algorithm was facilitated by a combination of the Kepler Mapper (van Veen and Saul, 2019) and the DyNeuSR (Dynamical Neuroimaging Spatiotemporal Representations) (Geniesse et al., 2019) Python modules. An extended coverage of processing pipelines for time-series TDA is given in Phinyomark et al. (2018).
3. Results
3.1. Handcrafted Features
Figure 6 shows the topological network produced using only the handcrafted features. The Kullback-Leibler divergence of the t-SNE embedding of the handcrafted features plateaued at 0.50, indicating that the perplexity and number of iterations used was appropriate for the dataset. The topological network consisted of 125 nodes and 524 edges.
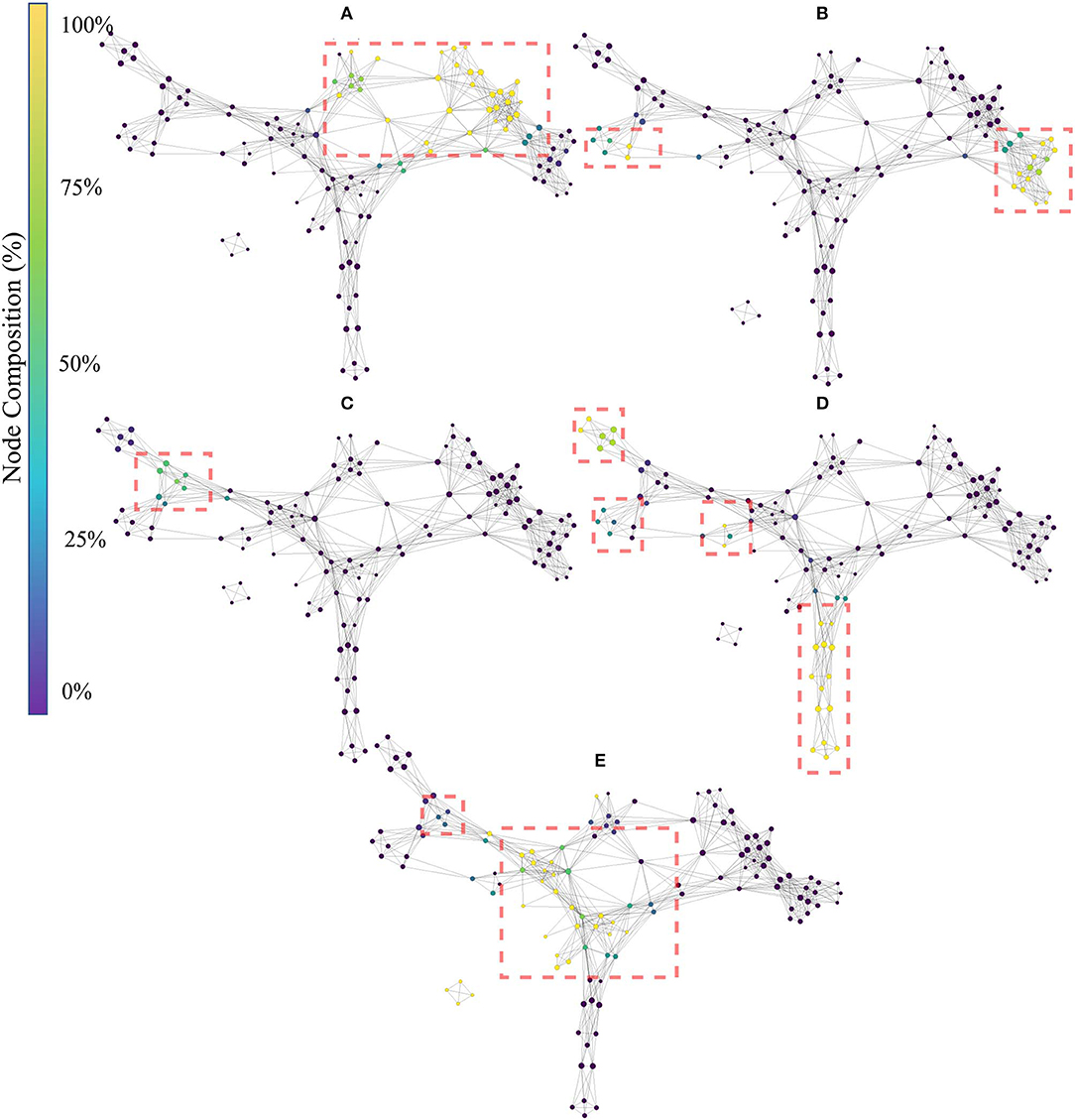
Figure 6. Topological network generated exclusively for the handcrafted features, where nodes are colored to indicate percent composition of: (A) signal amplitude and power features (SAP), (B) non-linear complexity (NLC), (C) frequency information features (FI), (D) time series modeling features (TSM), and (E) unique features (UNI). Dashed boxes highlight dense groupings of the specified functional group in each of the networks.
The color of the nodes within the network indicates the percentage of members that belong to the feature group of interest [(A):SAP, (B): NLC, (C): FI, (D): TSM, and (E): UNI]. The presence of an edge symbolizes common features present in the connected nodes, which can be used at a global scale to verify that functional groups (similar information) cluster together. Due to the topological nature of the graph, information similarity between nodes is measured using the number of edges that separate two nodes and not the length of the edges. Detailed interpretation of the TDA networks are given in the discussion.
3.2. Deep Features
The average cross-subject accuracy on the test set when using the proposed ADANN framework was 84.43±0.05%. Using a Wilcoxon signed-rank test (Wilcoxon, 1992) with n = 22, and considering each participant as a separate dataset, this was found to significantly outperform (p < 0.0001) the average accuracy of 65.03±0.08% obtained when training the ConvNet conventionally. Furthermore, based on Cohen's d, this difference in accuracy was considered to be huge (Sawilowsky, 2009). The accuracy obtained per participant for each training method is given in Figure 7A, and the confusion matrices calculated on the gestures are shown in Figure 7B.
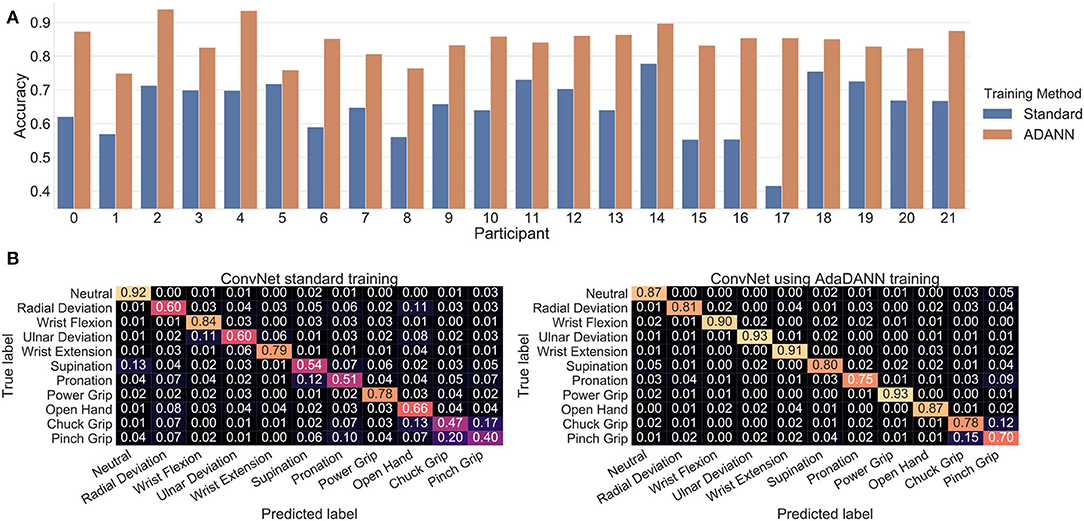
Figure 7. Classification results of deep learning architectures. (A) Per-participant test set accuracy comparison when training the network with and without ADANN, (B) Confusion matrices on the test set for cross-subject training with and without ADANN.
Figure 8A provides visualizations of the ConvNet trained with ADANN using Guided Grad-CAM for several examples from the 3DC Dataset, These visualizations highlight what the network considers “important” (i.e., which part of the signals had the most impact in predicting a given class) for the prediction of a particular gesture.
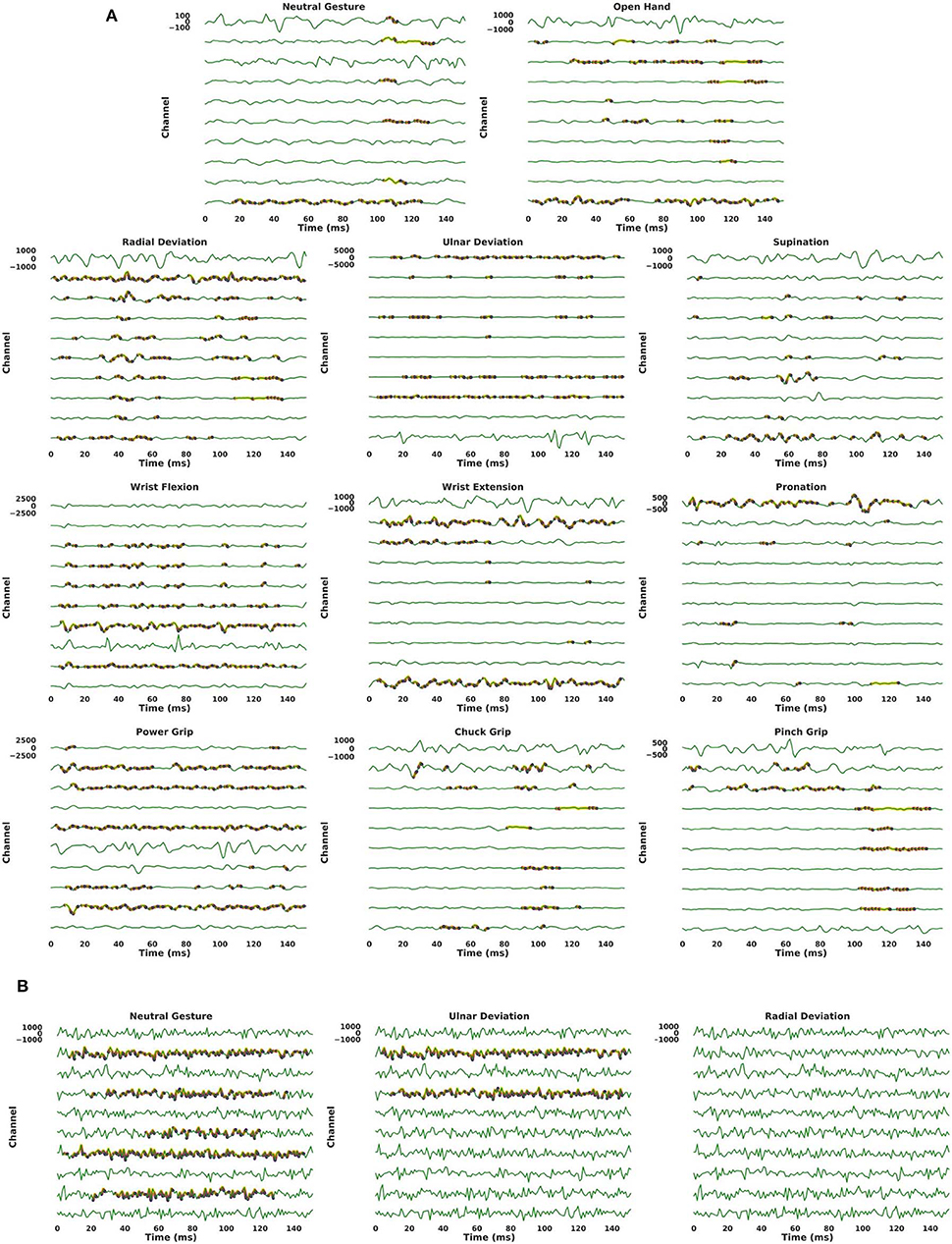
Figure 8. Output of Guided Grad-CAM when asked to highlight specific gestures in an example. For all graphs, the y-axis of each channel are scaled to the same range of value (indicated on the first channel of each graph). Warmer colors indicate a higher “importance” of a feature in the input space for the requested gesture. The coloring use a logarithmic scale. For visualization purposes, only features that are within three order of magnitudes to the most contributing feature are colored. (A) The examples shown are real examples and correspond to the same gestures that Guided Grad-CAM is asked to highlight. (B) A single example, generated using Gaussian noise of mean 0 and standard deviation 450, is shown three times. While the visualization algorithm does highlight features in the input space (when the requested gesture is not truly present in the input), the magnitude of these contributions is substantially smaller (half or less) than when the requested gesture is present in the input.
Instead of using Guided Grad-CAM to visualize how the network arrived at a decision for a known gesture, Figure 8B presents the results of the visualization algorithm when the network is told to find a gesture that is not present in the input. This is akin to using a picture of a cat as an input to the network and displaying the parts of the image that most resemble a giraffe. In Figure 8B, the input was randomly generated from a Gaussian distribution of mean 0 and standard deviation of 450 (chosen to have the same scale as the EMG signals of the 3DC Dataset). For six of the eleven gestures (Radial Deviation, Wrist Extension, Supination, Open Hand, Chuck Grip, and Pinch Grip) the network correctly identifies no relevant areas pertaining to these classes. While the network does highlight features in the input space associated with the other gestures, the magnitude of these contributions was substantially smaller (half or less) than when the requested gesture was actually present in the input signal.
The topological network produced using only the learned features is given in Figure 9. The color of the nodes within the network indicates the percentage of members that belong to the feature group of interests [(A): B1, (B): B2, (C): B3, (D): B4, (E): B5, and (F): B6]. Interpretation of the TDA network follows the rational stated in section 3.1. The Kullback-Leibler divergence of the t-SNE embedding of the handcrafted features plateaued at 0.37, again indicating that the perplexity and number of iterations used was appropriate for the dataset. The topological network consisted of 115 nodes and 672 edges.
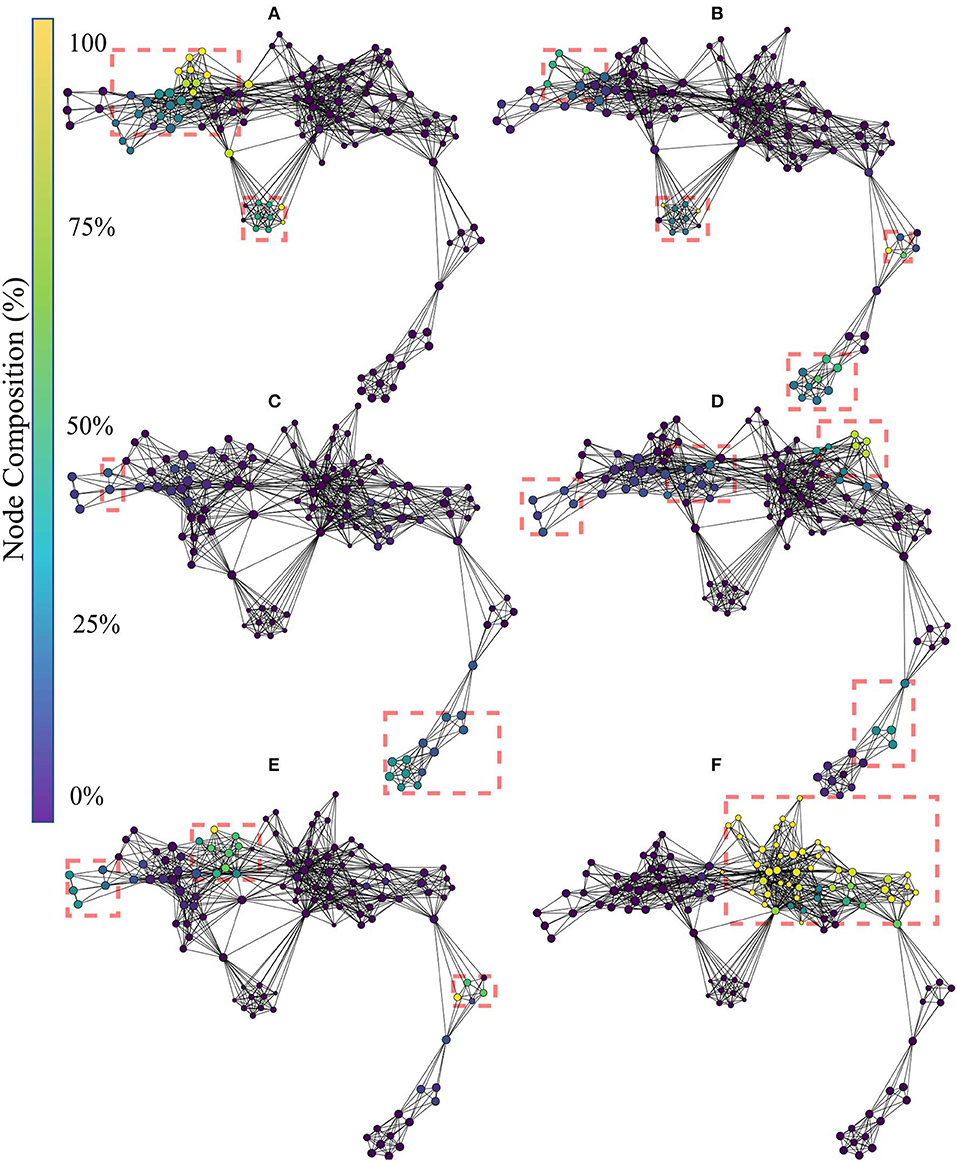
Figure 9. Topological network generated for exclusively the learned features, where nodes are colored to indicate percent composition of: (A) Block 1's features, (B) Block 2's features, (C) Block 3's features, (D) Block 4's features, (E) Block 5's features, and (F) Block 6's features. Dashed boxes highlight dense groupings of the specified block features in each of the networks.
3.3. Hybrid Features
The topological network produced using both handcrafted and learned features is shown in Figure 10. The Kullback-Leibler divergence of the t-SNE embedding of all features plateaued at 0.53, again indicating that the perplexity and number of iterations used was appropriate for the dataset. The topological network consisted of 115 nodes and 770 edges. From this network, only a subset of nodes were occupied by both handcrafted and learned features. Those nodes were indicated in Figure 10.
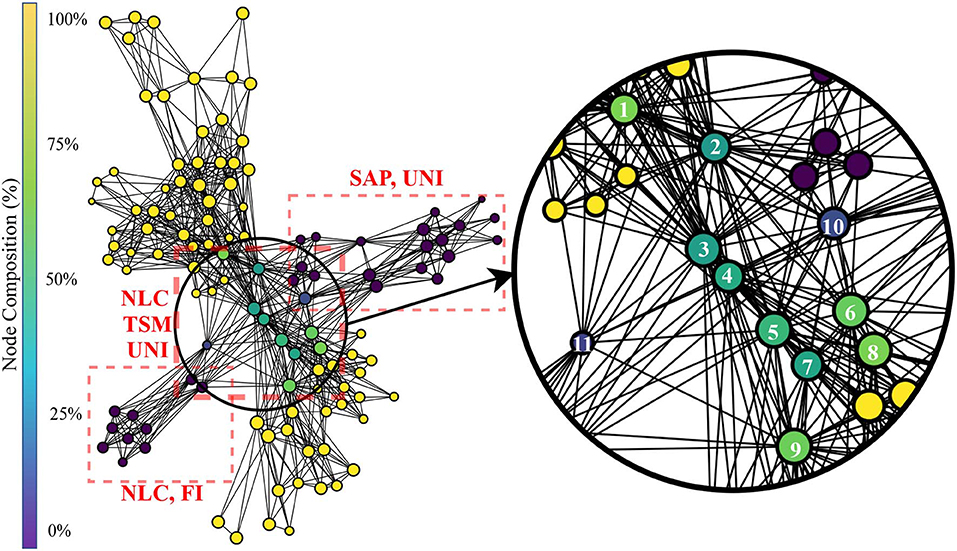
Figure 10. Topological network generated for all features, where nodes were colored to indicate percent composition of learned features. The dashed boxes highlight dense grouping of handcrafted features with their associated type.
The color of the nodes within the network indicates the percentage of members that belong to the feature group of interests (learned features). Information similarity was shown through a zoomed-in region of the network, where learned and handcrafted features clustered together. The feature members of the numbered nodes were listed in Table 2. Interpretation of the TDA network follows the rational stated in section 3.1.
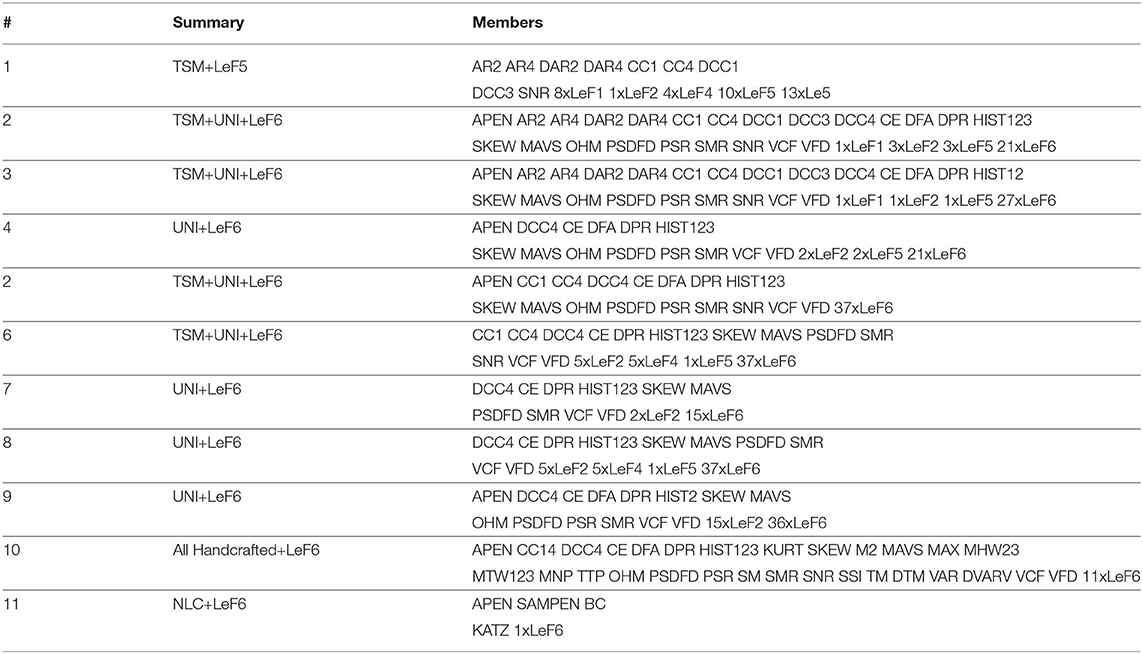
Table 2. Members of nodes labeled in Figure 6. LeFX refers to a Learned Feature from block X.
Table 3 shows the average accuracy (grouped by block for the learned features and by group for the handcrafted features) obtained when training an LDA on each feature and when using all features within a category (i.e., within a block or within a group of handcrafted feature). Note that for the learned features, PCA is applied to the feature map and the first component is employed to represent a given learned feature. Figure 11 shows examples of confusion matrices computed from the LDA classifications of singular features (both handcrafted and learned). Figure 11, also shows some confusion matrices obtained from the LDA's classification result when using all features within a category.
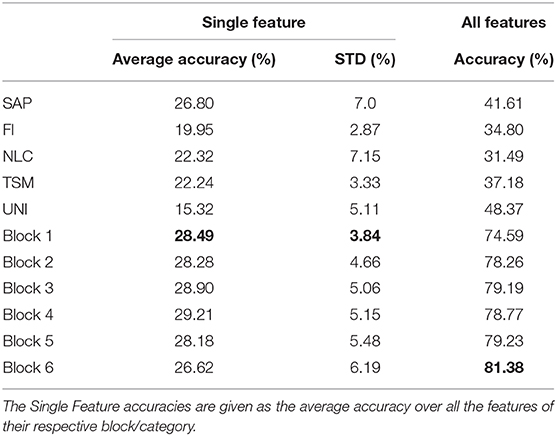
Table 3. Accuracy obtained on the test set using the handcrafted features and the learned features from their respective block.
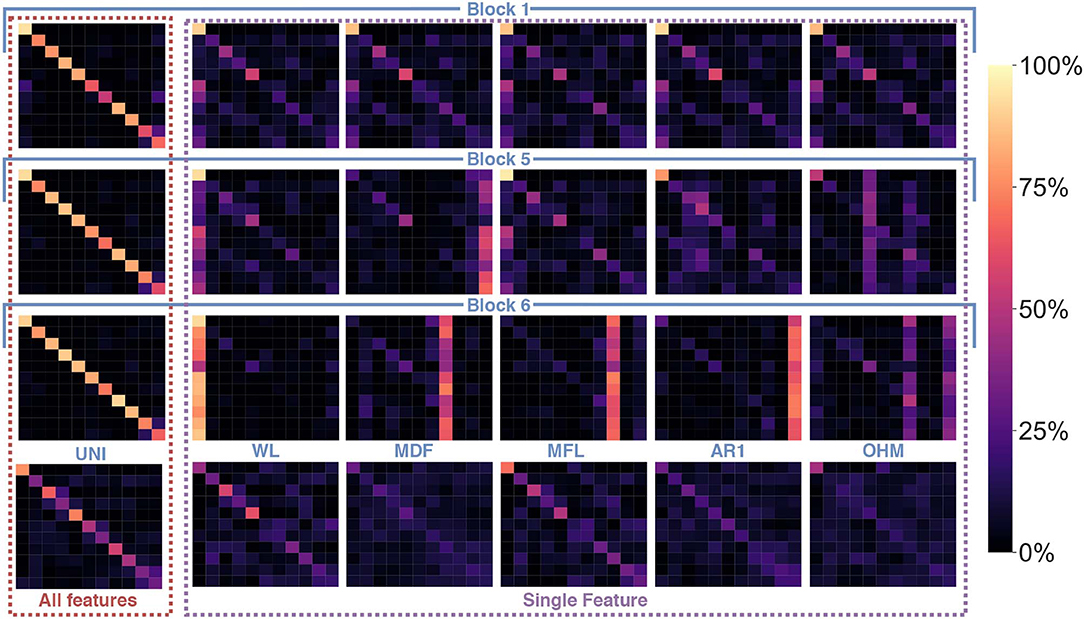
Figure 11. Confusion matrices using the handcrafted features and the learned features from the first, penultimate and last block as input and a LDA as the classifier. The first column, denoted as All features, shows the confusion matrices when using all 64 learned features of Block 1, 5, and 6, respectively (from top to bottom) and the set of UNI handcrafted features. The next five columns, denoted as Single Feature, show the confusions matrices for handcrafted feature examplars and from the same network's blocks but when training the LDA on a single feature. The subset of learned features was selected as representative of the typical confusion matrices found at each block. The examplars of the handcrafted features were selected from each handcrafted features' category (in order: SAP, FI, NLC, TSM, and UNI).
Figure 12 shows the average mean square error computed when regressing from the ConvNet's learned features (see section 2.3.5) to fifteen handcrafted features (three per Functional Group). Note that the mean squared error is obtained by computing the regression using only the output of the block of interest.
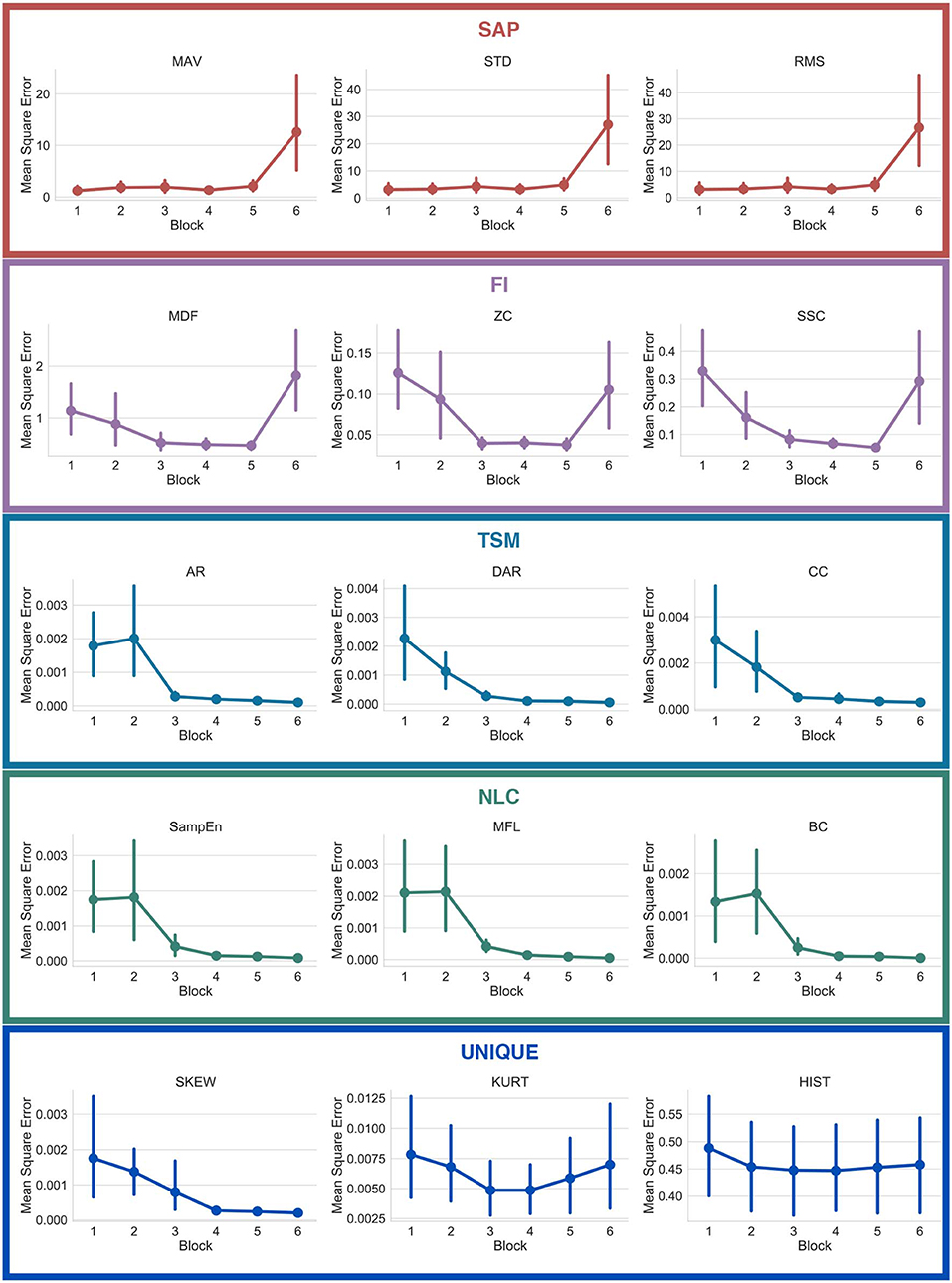
Figure 12. Mean squared error of the regressions from learned features to handcrafted features, with respect to the number of blocks employed for the regression. The features are grouped with their respective functional groups.
4. Discussion
4.1. Handcrafted Features
The result of the Mapper algorithm applied to handcrafted features (see Figure 6) showed that the handcrafted features agglomerated mostly with their respective groups, and that the topological graph is Y-shaped. This shows that the hyperparameters selected in this work are consistent with those found in previous EMG literature (Phinyomark et al., 2018; Campbell et al., 2019a).
4.2. ADANN and Deep Learning Visualization
Figure 7B shows that training the network with ADANN outperforms the standard training method in cross-subject classification. One advantage of ADANN in the context of this work is that the weights of the network have strong incentives to be subject-agnostic. As such, the learned features extracted from the network can be thought of as general features (and to a certain extent subject-independent) for the task of sEMG-based hand gesture recognition.
Applying Guided Grad-CAM, as in Figure 8, shows that the network mostly focuses on different channels for the detection of antagonist gestures. This suggests that the ConvNet was able to extract spatial features despite having access only to one dimensional convolutional kernels. Furthermore, it is notable that for all the examples given in Figure 8A, the most active channel was not the primary channel used for the gesture prediction. In fact, for the vast majority of gestures, the channel with the highest amplitude did not contribute in a meaningful way to the network's prediction. This observation held true while looking at several other examples from the 3DC Dataset. This might indicate that the common practice of placing the recording channel directly on the most prominent muscle for a given gesture within the context of gesture recognition may not be optimal. One could thus use the type of information provided by algorithms, such as Guided Grad-CAM as another way of performing channel selection (instead of simply using classification accuracy). The absence of importance on amplitude characteristics is in contrast to conventional practices of handcrafted feature engineering—where the feature set typically relies heavily on amplitude characteristics. This perhaps explains the growing interest in handcrafted feature extraction techniques that do not capture amplitude information, such as TDPSD, that have been demonstrated to outperform conventional amplitude-reliant features in terms of accuracy and robustness to confounding factors (Khushaba et al., 2016).
When applying Guided Grad-CAM on a noise input (one where the target gesture is not present, as seen in Figure 8B), the reported activation level is substantially lower, and in some cases non-existent. When the standard deviation of the Gaussian noise was increased by 33%, the network did not find any features resembling any gesture. This is most likely due to the fact that increasing the spread of the noise leads to a potentially greater gap in value between two adjacent data-points (reduced smoothness) fostering the condition for a more unrealistic signal. One could thus imagine training a generative adversarial network with the discriminative function based on the activation level calculated by Guided Grad-CAM, and modulating the difficulty by augmenting the signal's amplitude. This could facilitate training a network to not only be able to generate realistic, synthetic EMG signal, but also have the signal resemble actual gestures.
In contrast to the topological networks based on handcrafted features, those based on the learned features appear as a long flair with a loop. From Figure 9A, the learned features from block 1 are concentrated in the left segment of the flare, and the lower segment of the loop. From Figure 9B, the learned features from block 2 were located slightly more central to the network than the block 1 features. Additionally, a small subset of block 2 features appeared at the right segment of the flare, indicating a second distinct source of information was being harnessed. From Figures 9C–E, the features of block 3, 4, and 5 relocate their concentration of features to converge in the center of the network. Finally from Figure 9F, the concentration of all block 6 features lies in the center of the network. Thus, it can be seen that learned features from the same block tend to cluster together and remain close in the map to adjacent blocks in the network. The only exception to this is from the first block to the second, where substantially different features were generated by the latter. This suggests that the first layer may serve almost as a preprocessing layer which conditions the signal for the other layers.
4.3. Hybrid Features Visualization
The topological network generated from using both the handcrafted and learned features (see Figure 10) followed two orthogonal axes with the handcrafted features on one and the learned features on the other. The middle of the graph (where the two axis intercept) is where any nodes containing both handcrafted and learned features are found. The vast majority of these nodes are populated by features from block 6 and the NLC, TSM and UNI functional groupings. No nodes in the graph contained both handcrafted features and features from block 3, suggesting that block 3 extracted features not captured by current feature designs. Conversely, no learned features shared a node with features from the FI family, suggesting that these features may not have been extracted by the network.
While this topological network informs the type of information encoded within each individual feature, it is important to note that information can still be present but encoded in a more complex way within the weights of the deep network. This information flow can be visualized from the regression graphs of Figure 12. Features from the SAP family are more easily predicted within the early blocks whereas features from the TSM and NLC family require the latter blocks of the network to achieve the best predictions. Interestingly, while features from the FI family did not share any nodes learned features, one can see that the deep network is able to better extract this type of information within the intermediary blocks. This indicates (from Figures 10, 12) that, while frequency information is not explicitly used by the ConvNet, this type of information is nonetheless indirectly used to compute the features from the latter blocks. An example of a feature for which the ConvNet was unable to leverage its topology is the HIST (see Figure 12).
4.4. Understanding Deep Features Predictions
The topological network of Figure 10 showed that the type of information encoded within the lower blocks of the ConvNet tended to be highly dissimilar to what the handcrafted features encoded. Interestingly, however, Figure 11 shows that the role fulfilled by these features is similar. That is, both the handcrafted and learned features (from the lower blocks) try to encode general properties that can distinguish between all classes. The confusion matrices obtained from training an LDA on a single feature highlight this behavior (see Figure 11 for some examples) as both the handcrafted features and the learned features (before the last block) are able to distinguish between gestures relatively equally. In contrast, the features extracted from the last block (and to a lesser extent from the penultimate block) have been optimized to be a gesture detector instead of a feature detector. A clear visual of this behavior is illustrated in Figure 11, where the main line highlighted in the confusion matrices from block 6 was a single column (corresponding to the prediction of a single gesture), instead of the typical diagonal. In other words, during training, the neurons of the final block are encoded to have maximum activation when a particular class was provided in the input window and minimum activation when other classes were provided; effectively creating a one-vs.-all (OVA) classifier. This behavior is consistent with the feature visualization literature found in image classification and natural language processing, where semantic dictionaries or saliency maps have depicted neuron representations becoming more abstract at later layers (Simonyan et al., 2013; LeCun et al., 2015). This also explains why the features from the last block obtained the worst average accuracy when taken individually while achieving the highest accuracy as a group (see Table 3). That is, as each feature map of the last layer tries to detect a particular gesture, its activation for the other gestures should be minimal, making the distinction between the other gestures significantly harder. The final decision layer of the network can then be thought of as a weighted average of these OVA classifiers to maximize the performance of the learned feature maps. Note that in Table 3, the lower accuracies obtained from the handcrafted features as a group were expected as each feature within the same family provides similar type of information, even more so than the learned features of the network (as seen in Figures 6, 9, 10). Overall, the best performing handcrafted feature set as a group was the features from the UNI family despite the fact that they were the worst on average when alone. This is most likely due to the fact that by definitions, features within this family are more heterogeneous.
5. Conclusion
This paper presents the first in-depth analysis of features learned using deep learning for EMG-based hand gesture recognition. The type of information encoded within learned features and their relationship to handcrafted features were characterized employing a mixture of topological data analysis (Mapper), network interpretability visualization (Guided Grad-CAM), machine learning (feature classification prediction), and by visualizing the information flow using feature regression. As a secondary, but significant contribution, this work presented ADANN, a novel multi-domain training algorithm particularly suited for EMG-based gesture recognition shown to significantly outperform traditional training on cross-subject classification accuracy.
This manuscript paves the way for hybrid classifiers that contain both learned and handcrafted features. An ideal application for the findings of this work would rely on a mix of handcrafted features and learned features taken from all four extremities of the hybrid topological network, and at the center to provide complementary, and general features to the classifier. A network could then be trained to augment its sensitivity to similar classes. For example, to alleviate ambiguity between pinch grip and chuck grip, a learned feature that encodes the one-vs.-all information of pinch grip could be included into the original feature set or into an otherwise handcrafted only feature set. Alternatively, handcrafted feature extraction stages may be installed within the deep learning architecture by means of neuroevolution of augmenting topologies (Chen and Alahakoon, 2006), a genetic algorithm that optimizes the weights and connections of deep learning architectures.
The main limitation of this study was the use of a single architecture to generate the learned features. Though this architecture was chosen to be representative of current practices in myoelectric control and be extensible to other applications, the current work did study the impact of varying the number of blocks and the composition of these block on the different experiments. Additionally, although the set of handcrafted features was selected to be comprehensive over the sources of information available from the EMG signal, explicit time-frequency features, such as those based on spectrograms and wavelet were not included in the current work, as they were ill-adapted to the framework employed in this study. Furthermore, an analysis including a larger amount of gestures should also be conducted. Importantly, these results are presented for a single 1D electrode array, and may not be representative of larger 2D arrays, such as those used in high density EMG applications. Similarly, explicit spatio-temporal features, such as coherence between electrodes, were not explored, and the convolutional kernels were restricted to 1D (although as seen in Figure 8A the network was still able to learn spatial information to a certain extent). Omitting these type of complex features was a design choice as this work represents a first step in understanding and characterizing learned features within the context of EMG signal. As such, using this manuscript as a basis, future works should study the impact of diverse architectures on the type of learned features and will incorporate spatio-temporal features (both handcrafted and from 2D convolutional kernels). Additionally, formal feature set generation and hybrid classifiers should be investigated using the tools presented in this work.
Data Availability Statement
The datasets analyzed and the source code for this study can be found at the following link: https://github.com/UlysseCoteAllard/sEMG_handCraftedVsLearnedFeatures.
Ethics Statement
The studies involving human participants were reviewed and approved by Comités d'Éthique de la Recherche avec desêtres humains de l'Université Laval. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
UC-A, EC, AP, FL, BG, and ES: conceptualization. UC-A, EC, AP, FL, and ES: methodology. UC-A and EC: software and validation. UC-A, EC, AP, FL, and ES: formal analysis and investigation. FL, BG, and ES: resources. UC-A and EC: data curation and writing original draft preparation. UC-A, EC, AP, FL, BG, and ES: writing review and editing. UC-A and EC: visualization. FL, BG, and ES: supervision. UC-A, EC, AP, FL, BG, and ES: project administration. UC-A, AP, FL, BG, and ES: funding acquisition.
Funding
This research was funded by the Natural Sciences and Engineering Research Council of Canada (NSERC) [funding reference numbers 401220434, 376091307, 114090], the Institut de recherche Robert-Sauvé en santé et en sécurité du travail (IRSST), and the Canada Research Chair in Smart Biomedical Microsystems [funding reference number 950-232064]. Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG) [numéros de référence 401220434, 376091307, 114090].
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank Gabriel Dubé for his valuable input in relation to the Mapper algorithm.
References
Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., and Marchand, M. (2014). Domain-adversarial neural networks. arXiv [Preprint] arxiv:1412.4446.
Allard, U. C., Nougarou, F., Fall, C. L., Giguère, P., Gosselin, C., Laviolette, F., et al. (2016). “A convolutional neural network for robotic arm guidance using SEMG based frequency-features,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Seoul: IEEE), 2464–2470.
Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., et al. (2018). The history began from alexnet: a comprehensive survey on deep learning approaches. arXiv [Preprint] arxiv:1803.01164.
Al-Timemy, A. H., Khushaba, R. N., Bugmann, G., and Escudero, J. (2015). Improving the performance against force variation of EMG controlled multifunctional upper-limb prostheses for transradial amputees. IEEE Trans. Neural Syst. Rehabil. Eng. 24, 650–661. doi: 10.1109/TNSRE.2015.2445634
Andersen, V., Fimland, M. S., Mo, D.-A., Iversen, V. M., Vederhus, T., Hellebø, L. R. R., et al. (2018). Electromyographic comparison of barbell deadlift, hex bar deadlift, and hip thrust exercises: a cross-over study. J. Strength Condit. Res. 32, 587–593. doi: 10.1519/JSC.0000000000001826
Arjunan, S. P., and Kumar, D. K. (2010). Decoding subtle forearm flexions using fractal features of surface electromyogram from single and multiple sensors. J. Neuroeng. Rehabil. 7:53. doi: 10.1186/1743-0003-7-53
Atzori, M., Cognolato, M., and Müller, H. (2016). Deep learning with convolutional neural networks applied to electromyography data: a resource for the classification of movements for prosthetic hands. Front. Neurorobot. 10:9. doi: 10.3389/fnbot.2016.00009
Balasubramanian, M., and Schwartz, E. L. (2002). The isomap algorithm and topological stability. Science 295:7. doi: 10.1126/science.295.5552.7a
Batchvarov, V., and Malik, M. (2002). Individual patterns of QT/RR relationship. Cardiac Electrophysiol. Rev. 6, 282–288. doi: 10.1023/A:1016393328485
Côté-Allard, U., Fall, C. L., Drouin, A., Campeau-Lecours, A., Gosselin, C., Glette, K., et al. (2019a). Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 760–771. doi: 10.1109/TNSRE.2019.2896269
Côté-Allard, U., Gagnon-Turcotte, G., Laviolette, F., and Gosselin, B. (2019b). A low-cost, wireless, 3-D-printed custom armband for semg hand gesture recognition. Sensors 19:2811. doi: 10.3390/s19122811
Campbell, E., Phinyomark, A., Al-Timemy, A. H., Khushaba, R. N., Petri, G., and Scheme, E. (2019a). “Differences in EMG feature space between able-bodied and amputee subjects for myoelectric control,” in 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER) (San Fransisco, CA), 33–36.
Campbell, E., Phinyomark, A., and Scheme, E. (2019b). Feature extraction and selection for pain recognition using peripheral physiological signals. Front. Neurosci. 13:437. doi: 10.3389/fnins.2019.00437
Campbell, E. D., Phinyomark, A., and Scheme, E. (2019c). “Linear discriminant analysis with bayesian risk parameters for myoelectric control,” in 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP) (GlobalSIP 2019) (Ottawa, ON).
Castellini, C., Fiorilla, A. E., and Sandini, G. (2009). Multi-subject/daily-life activity EMG-based control of mechanical hands. J. Neuroeng. Rehabil. 6:41. doi: 10.1186/1743-0003-6-41
Chen, H., Zhang, Y., Li, G., Fang, Y., and Liu, H. (2019). Surface electromyography feature extraction via convolutional neural network. Int. J. Mach. Learn. Cybernet. 11, 185–196. doi: 10.1007/s13042-019-00966-x
Chen, L., and Alahakoon, D. (2006). “Neuroevolution of augmenting topologies with learning for data classification,” in 2006 International Conference on Information and Automation (Shandong), 367–371.
Choi, H., and Choi, S. (2007). Robust kernel isomap. Pattern Recogn. 40, 853–862. doi: 10.1016/j.patcog.2006.04.025
Cote-Allard, U., Fall, C. L., Campeau-Lecours, A., Gosselin, C., Laviolette, F., and Gosselin, B. (2017). “Transfer learning for semg hand gestures recognition using convolutional neural networks,” in 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (IEEE), 1663–1668.
Du, S., and Vuskovic, M. (2004). “Temporal vs. spectral approach to feature extraction from prehensile emg signals,” in Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration, 2004. IRI 2004 (Las Vegas, NV: IEEE), 344–350.
Gal, Y., and Ghahramani, Z. (2016). “Dropout as a bayesian approximation: representing model uncertainty in deep learning,” in International Conference on Machine Learning (New York, NY), 1050–1059.
Gan, C., Wang, N., Yang, Y., Yeung, D.-Y., and Hauptmann, A. G. (2015). “Devnet: a deep event network for multimedia event detection and evidence recounting,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Boston, MA), 2568–2577.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., et al. (2016). Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17, 2096–2030. arxiv:1505.07818.
Geniesse, C., Sporns, O., Petri, G., and Saggar, M. (2019). Generating dynamical neuroimaging spatiotemporal representations (dyneusr) using topological data analysis. Netw. Neurosci. 3, 763–778. doi: 10.1162/netn_a_00093
Gitter, J. A., and Czerniecki, M. J. (1995). Fractal analysis of the electromyographic interference pattern. J. Neurosci. Methods 58, 103–108. doi: 10.1016/0165-0270(94)00164-C
Guidetti, L., Rivellini, G., and Figura, F. (1996). EMG patterns during running: intra-and inter-individual variability. J. Electromyogr. Kinesiol. 6, 37–48. doi: 10.1016/1050-6411(95)00015-1
Gupta, V., Suryanarayanan, S., and Reddy, N. P. (1997). Fractal analysis of surface EMG signals from the biceps. Int. J. Med. Inform. 45, 185–192. doi: 10.1016/S1386-5056(97)00029-4
Halaki, M., and Ginn, K. (2012). “Normalization of EMG signals: to normalize or not to normalize and what to normalize to?” in Computational Intelligence in Electromyography Analysis–A Perspective on Current Applications and Future Challenges ed G. R. Naik (London: IntechOpen), 175–194.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV), 770–778.
Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 4700–4708.
Ioffe, S., and Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv [Preprint] arxiv:1502.03167.
Khushaba, R. N., Al-Timemy, A., Kodagoda, S., and Nazarpour, K. (2016). Combined influence of forearm orientation and muscular contraction on emg pattern recognition. Expert Syst. Appl. 61, 154–161. doi: 10.1016/j.eswa.2016.05.031
Kim, K. S., Choi, H. H., Moon, C. S., and Mun, C. W. (2011). Comparison of k-nearest neighbor, quadratic discriminant and linear discriminant analysis in classification of electromyogram signals based on the wrist-motion directions. Curr. Appl. Phys. 11, 740–745. doi: 10.1016/j.cap.2010.11.051
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arxiv [Preprint] arxiv:1412.6980.
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learning. Nature 521:436. doi: 10.1038/nature14539
Li, Y., Wang, N., Shi, J., Liu, J., and Hou, X. (2016). Revisiting batch normalization for practical domain adaptation. arxiv [Preprint] arxiv:1603.04779.
Liu, X., Zhang, R., Meng, Z., Hong, R., and Liu, G. (2019). On fusing the latent deep CNN feature for image classification. World Wide Web 22, 423–436. doi: 10.1007/s11280-018-0600-3
Long, J., Shelhamer, E., and Darrell, T. (2015). “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Boston, MA), 3431–3440.
Maaten, L. V. D., and Hinton, G. (2008). Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605.
McCool, P., Fraser, G. D., Chan, A. D., Petropoulakis, L., and Soraghan, J. J. (2014). Identification of contaminant type in surface electromyography (EMG) signals. IEEE Trans. Neural Syst. Rehabil. Eng. 22, 774–783. doi: 10.1109/TNSRE.2014.2299573
Meltzer, J. A., Negishi, M., Mayes, L. C., and Constable, R. T. (2007). Individual differences in EEG theta and alpha dynamics during working memory correlate with fMRI responses across subjects. Clin. Neurophysiol. 118, 2419–2436. doi: 10.1016/j.clinph.2007.07.023
Nam, H., and Han, B. (2016). “Learning multi-domain convolutional neural networks for visual tracking,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV), 4293–4302.
Nanni, L., Ghidoni, S., and Brahnam, S. (2017). Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recogn. 71, 158–172. doi: 10.1016/j.patcog.2017.05.025
Nicolau, M., Levine, A. J., and Carlsson, G. (2011). Topology based data analysis identifies a subgroup of breast cancers with a unique mutational profile and excellent survival. Proc. Natl. Acad. Sci. U.S.A. 108, 7265–7270. doi: 10.1073/pnas.1102826108
Oskoei, M. A., and Hu, H. (2006). “Ga-based feature subset selection for myoelectric classification,” in 2006 IEEE International Conference on Robotics and Biomimetics (Kunming: IEEE), 1465–1470.
Oskoei, M. A., and Hu, H. (2007). Myoelectric control systems–a survey. Biomed. Signal Process. Control 2, 275–294. doi: 10.1016/j.bspc.2007.07.009
Oskoei, M. A., and Hu, H. (2008). Support vector machine-based classification scheme for myoelectric control applied to upper limb. IEEE Trans. Biomed. Eng. 55, 1956–1965. doi: 10.1109/TBME.2008.919734
Park, S.-H., and Lee, S.-P. (1998). EMG pattern recognition based on artificial intelligence techniques. IEEE Trans. Rehabil. Eng. 6, 400–405. doi: 10.1109/86.736154
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., et al. (2017). “Automatic differentiation in pytorch,” in NIPS-W (Long Beach, CA).
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830.
Phinyomark, A., Ibanez-Marcelo, E., and Petri, G. (2018). Topological Data Analysis of Biomedical Big Data. 1st Edn., Volume 1 of 1, Chapter 11. Boca Raton: CRC Press, 209–233.
Phinyomark, A., Khushaba, R. N., Ibáñez-Marcelo, E., Patania, A., Scheme, E., and Petri, G. (2017). Navigating features: a topologically informed chart of electromyographic features space. J. R. Soc. Interface 14:20170734. doi: 10.1098/rsif.2017.0734
Phinyomark, A., Phothisonothai, M., Phukpattaranont, P., and Limsakul, C. (2011a). Critical exponent analysis applied to surface EMG signals for gesture recognition. Metrol. Meas. Syst. 18, 645–658. doi: 10.2478/v10178-011-0061-9
Phinyomark, A., Phothisonothai, M., Phukpattaranont, P., and Limsakul, C. (2011b). Evaluation of movement types and electrode positions for EMG pattern classification based on linear and non-linear features. Eur. J. Sci. Res 62, 24–34.
Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2011c). A review of control methods for electric power wheelchairs based on electromyography signals with special emphasis on pattern recognition. IETE Tech. Rev. 28, 316–326. doi: 10.4103/0256-4602.83552
Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2012a). Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 39, 7420–7431. doi: 10.1016/j.eswa.2012.01.102
Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2012b). Fractal analysis features for weak and single-channel upper-limb EMG signals. Expert Syst. Appl. 39, 11156–11163. doi: 10.1016/j.eswa.2012.03.039
Phinyomark, A., Phukpattaranont, P., Limsakul, C., and Phothisonothai, M. (2011d). Electromyography (EMG) signal classification based on detrended fluctuation analysis. Fluct. Noise Lett. 10, 281–301. doi: 10.1142/S0219477511000570
Phinyomark, A., Quaine, F., Charbonnier, S., Serviere, C., Tarpin-Bernard, F., and Laurillau, Y. (2013). EMG feature evaluation for improving myoelectric pattern recognition robustness. Expert Syst. Appl. 40, 4832–4840. doi: 10.1016/j.eswa.2013.02.023
Phinyomark, A., and Scheme, E. (2018a). Emg pattern recognition in the era of big data and deep learning. Big Data Cogn. Comput. (Seoul) 2:21. doi: 10.3390/bdcc2030021
Phinyomark, A., and Scheme, E. (2018b). “A feature extraction issue for myoelectric control based on wearable EMG sensors,” in 2018 IEEE Sensors Applications Symposium (SAS) (IEEE), 1–6.
Poria, S., Cambria, E., and Gelbukh, A. (2015). “Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (Lisbon), 2539–2544.
Qingju, Z., and Zhizeng, L. (2006). “Wavelet de-noising of electromyography,” in 2006 International Conference on Mechatronics and Automation (Luoyang: IEEE), 1553–1558.
Rebuffi, S.-A., Bilen, H., and Vedaldi, A. (2018). “Efficient parametrization of multi-domain deep neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Salt Lake City, UT), 8119–8127.
Saggar, M., Sporns, O., Gonzalez-Castillo, J., Bandettini, P., Carlsson, G., Glover, G., et al. (2018). Towards a new approach to reveal dynamical organization of the brain using topological data analysis. Nat. Commun. 9:1399. doi: 10.1038/s41467-018-03664-4
Saponas, T. S., Tan, D. S., Morris, D., and Balakrishnan, R. (2008). “Demonstrating the feasibility of using forearm electromyography for muscle-computer interfaces,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Florence: ACM), 515–524.
Sawilowsky, S. S. (2009). New effect size rules of thumb. J. Mod. Appl. Stat. Methods 8:26. doi: 10.22237/jmasm/1257035100
Scheme, E., and Englehart, K. (2011). Electromyogram pattern recognition for control of powered upper-limb prostheses: state of the art and challenges for clinical use. J. Rehabil. Res. Dev. 48, 643–659. doi: 10.1682/JRRD.2010.09.0177
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. (2017). “Grad-CAM: visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE International Conference on Computer Vision (Venice), 618–626.
Selvaraju, R. R., Das, A., Vedantam, R., Cogswell, M., Parikh, D., and Batra, D. (2016). Grad-CAM: why did you say that? arxiv [Preprint] arxiv:1611.07450.
Sermanet, P., Kavukcuoglu, K., Chintala, S., and LeCun, Y. (2013). “Pedestrian detection with unsupervised multi-stage feature learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 3626–3633.
Shu, R., Bui, H. H., Narui, H., and Ermon, S. (2018). A dirt-t approach to unsupervised domain adaptation. arXiv [Preprint] arxiv:1802.08735.
Simonyan, K., Vedaldi, A., and Zisserman, A. (2013). Deep inside convolutional networks: visualising image classification models and saliency maps. arXiv [Preprint] arxiv:1312.6034.
Sinderby, C., Lindstrom, L., and Grassino, A. (1995). Automatic assessment of electromyogram quality. J. Appl. Physiol. 79, 1803–1815. doi: 10.1152/jappl.1995.79.5.1803
Singh, G., Mémoli, F., and Carlsson, G. E. (2007). “Topological methods for the analysis of high dimensional data sets and 3D object recognition,” in SPBG (Prague), 91–100.
Smith, L. H., Hargrove, L. J., Lock, B. A., and Kuiken, T. A. (2010). Determining the optimal window length for pattern recognition-based myoelectric control: balancing the competing effects of classification error and controller delay. IEEE Trans. Neural Syst. Rehabil. Eng. 19, 186–192. doi: 10.1109/TNSRE.2010.2100828
Springenberg, J. T., Dosovitskiy, A., Brox, T., and Riedmiller, M. (2014). Striving for simplicity: the all convolutional net. arxiv [Preprint] arxiv:1412.6806.
St-Onge, D., Côté-Allard, U., Glette, K., Gosselin, B., and Beltrame, G. (2019). Engaging with robotic swarms: commands from expressive motion. ACM Trans. Hum. Robot Interact. 8:11. doi: 10.1145/3323213
Talebinejad, M., Chan, A. D., Miri, A., and Dansereau, R. M. (2009). Fractal analysis of surface electromyography signals: a novel power spectrum-based method. J. Electromyogr. Kinesiol. 19, 840–850. doi: 10.1016/j.jelekin.2008.05.004
Thongpanja, S., Phinyomark, A., Hu, H., Limsakul, C., and Phukpattaranont, P. (2015). The effects of the force of contraction and elbow joint angle on mean and median frequency analysis for muscle fatigue evaluation. ScienceAsia 41, 263–263. doi: 10.2306/scienceasia1513-1874.2015.41.263
Thongpanja, S., Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2013). Mean and median frequency of EMG signal to determine muscle force based on time-dependent power spectrum. Elektron. Elektrotech. 19, 51–56. doi: 10.5755/j01.eee.19.3.3697
Thongpanja, S., Phinyomark, A., Quaine, F., Laurillau, Y., Limsakul, C., and Phukpattaranont, P. (2016). Probability density functions of stationary surface EMG signals in noisy environments. IEEE Trans. Instr. Meas. 65, 1547–1557. doi: 10.1109/TIM.2016.2534378
Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). “Adversarial discriminative domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 7167–7176.
Van Den Broek, E. L., Schut, M. H., Westerink, J. H., van Herk, J., and Tuinenbreijer, K. (2006). “Computing emotion awareness through facial electromyography,” in European Conference on Computer Vision (Graz: Springer), 52–63.
Ward, J. H. J. (1963). Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 58, 236–244. doi: 10.1080/01621459.1963.10500845
Wilcoxon, F. (1992). “Individual comparisons by ranking methods,” in Breakthroughs in Statistics ed M. Davidian (Washington, DC: Springer), 196–202.
Wold, S., Esbensen, K., and Geladi, P. (1987). Principal component analysis. Chemometrics and intelligent laboratory systems, 2(1-3):37–52.
Xu, B., Wang, N., Chen, T., and Li, M. (2015). Empirical evaluation of rectified activations in convolutional network. arXiv [Preprint] arxiv:1505.00853.
Yang, S., and Ramanan, D. (2015). “Multi-scale recognition with DAG-CNNs,” in Proceedings of the IEEE International Conference on Computer Vision (Nice), 1215–1223.
Yang, Y., and Hospedales, T. M. (2014). A unified perspective on multi-domain and multi-task learning. arXiv [Preprint] arxiv:1412.7489.
Zardoshti-Kermani, M., Wheeler, B. C., Badie, K., and Hashemi, R. M. (1995). EMG feature evaluation for movement control of upper extremity prostheses. IEEE Trans. Rehabil. Eng. 3, 324–333. doi: 10.1109/86.481972
Zeiler, M. D., and Fergus, R. (2014). “Visualizing and understanding convolutional networks,” in European Conference on Computer Vision (Zurich: Springer), 818–833.
Zhang, X., Chen, X., Wang, W.-H., Yang, J.-H., Lantz, V., and Wang, K.-Q. (2009). “Hand gesture recognition and virtual game control based on 3D accelerometer and EMG sensors,” in Proceedings of the 14th International Conference on Intelligent User Interfaces (Sanibel Island, FL: ACM), 401–406.
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., and Torralba, A. (2016). “Learning deep features for discriminative localization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV), 2921–2929.
Keywords: EMG, deep learning, MAPPER, feature extraction, gesture recognition, CNN, ConvNet, Grad-CAM
Citation: Côté-Allard U, Campbell E, Phinyomark A, Laviolette F, Gosselin B and Scheme E (2020) Interpreting Deep Learning Features for Myoelectric Control: A Comparison With Handcrafted Features. Front. Bioeng. Biotechnol. 8:158. doi: 10.3389/fbioe.2020.00158
Received: 30 November 2019; Accepted: 17 February 2020;
Published: 03 March 2020.
Edited by:
Peter A. Federolf, University of Innsbruck, AustriaReviewed by:
Vitoantonio Bevilacqua, Politecnico di Bari, ItalyRachid Jennane, University of Orléans, France
Copyright © 2020 Côté-Allard, Campbell, Phinyomark, Laviolette, Gosselin and Scheme. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ulysse Côté-Allard, dWx5c3NlLmNvdGUtYWxsYXJkLjEmI3gwMDA0MDt1bGF2YWwuY2E=; Evan Campbell, ZXZhbi5jYW1wYmVsbDEmI3gwMDA0MDt1bmIuY2E=
†These authors share first authorship
‡These authors share senior authorship