 Peter Jung
Peter Jung Richard Kueng
Richard Kueng Dustin G. Mixon
Dustin G. Mixon- 1Communications and Information Theory Group, Technische Universität Berlin, Berlin, Germany
- 2Department of Computing and Mathematical Sciences, Institute for Quantum Information and Matter, California Institute of Technology, Pasadena, CA, United States
- 3Department of Mathematics, Ohio State University, Columbus, OH, United States
Compressed sensing is the art of effectively reconstructing structured n-dimensional vectors from substantially fewer measurements than naively anticipated. A plethora of analytical reconstruction guarantees support this credo. The strongest among them are based on deep results from large-dimensional probability theory and require a considerable amount of randomness in the measurement design. Here, we demonstrate that derandomization techniques allow for a considerable reduction in the randomness required for such proof strategies. More precisely, we establish uniform s-sparse reconstruction guarantees for Cs log(n) measurements that are chosen independently from strength-4 orthogonal arrays and maximal sets of mutually unbiased bases, respectively. These are highly structured families of vectors that imitate signed Bernoulli and standard Gaussian vectors in a (partially) derandomized fashion.
1. Introduction and Main Results
1.1. Motivation
Compressed sensing is the art of effectively reconstructing structured signals from substantially fewer measurements than would naively be required for standard techniques like least squares. Although not entirely novel, rigorous treatments of this observation [1, 2] spurred considerable scientific attention from 2006 on (see e.g., [3, 4]) and references therein. While deterministic results do exist, the strongest theoretic reconstruction guarantees still rely on randomness. Each measurement corresponds to the observed inner product of the unknown vector, with a vector chosen randomly from a fixed measurement ensemble. Broadly, these ensembles can be grouped into two families:
(i) Generic measurements such as independent Gaussian, or Bernoulli vectors. Such an abundance of randomness allows establishing very strong results by following comparatively simple and instructive proof techniques. The downside is that concrete implementations do require a lot of randomness. In fact, they might be too random to be useful for certain applications.
(ii) Structured measurements such as random rows of a Fourier, or Hadamard matrix. In contrast to generic measurements, these feature a lot of structure that is geared toward applications. Moreover, selecting random rows from a fixed matrix does require very little randomness. For example, log2(n) random bits are sufficient to select a row of the DFT uniformly at random. In contrast, generating an i.i.d. Bernoulli vector would consume n bits of randomness. Structure and comparatively little randomness have a downside, though. Theoretic convergence guarantees tend to be weaker than their generic counterparts. It should also not come as a surprise that the necessary proof techniques become considerably more involved.
Typically, results for type (i) precede the results for type (ii). Phase retrieval via PhaseLift is a concrete example for such a development. Generic convergence guarantees [5, 6] preceded (partially) de-randomized results [7, 8]. Compressed sensing is special in this regard. The two seminal works [1, 2] from 2006 provided both results almost simultaneously. This had an interesting consequence. Despite considerable effort, to date there still seems to be a gap between both proof techniques.
Here, we try to close this gap by applying a method that is very well established in theoretical computer science: partial derandomization. We start with a proof technique of type (i) and considerably reduce the amount of randomness required for it to work. While doing so, we keep careful track of the amount of randomness that is still necessary. Finally, we replace the original (generic) random measurements with pseudo-random ones that mimic them in a sufficiently accurate fashion. Our results highlight that this technique almost allows bridging the gap between existing proof techniques for generic and structured measurements: the results are still strong but require slightly more randomness than choosing vectors uniformly from a bounded orthogonal system, such as Fourier or Hadamard vectors.
There is also a didactic angle to this work: within the realm of signal processing, partial-derandomization techniques have been successfully applied to matrix reconstruction [8, 9] and phase retrieval via PhaseLift [7, 10, 11]. Although similar in spirit, the more involved nature of these problems may obscure the key ideas, intuition and tricks behind such an approach. However, the same techniques have not yet been applied to the original problem of compressed sensing. Here, we fill this gap and, in doing so, provide an introduction to partial derandomization techniques by example. To preserve this didactic angle, we try to keep the presentation as simple and self-contained as possible.
Finally, one may argue that compressed sensing has not fully lived up to the high expectations of the community yet (see e.g., Tropp [12]). Arguably, one of the most glaring problems for applications is the requirement of choosing individual measurements at random1. While we are not able to fully overcome this drawback here, the methods described in this work do limit the amount of randomness required to generate individual structured measurements. We believe that this may help to reduce the discrepancy between “what can be proved” and “what can be done” in a variety of concrete applications.
1.2. Preliminaries on Compressed Sensing
Compressed sensing aims at reconstructing s-sparse vectors x ∈ ℂn from m ≪ n linear measurements:
Since m ≪ n, the matrix A is singular and there are infinitely many solutions to this equation. A convex penalizing function is used to promote sparsity among these solutions. Typically, this penalizing function is the ℓ1-norm :
Strong mathematical proofs for correct recovery have been established. By and large, these statements require randomness in the sense that each row of A is an independent copy of a random vector a ∈ ℝn. Prominent examples include
(1) m = Cs log(n/s) standard complex Gaussian measurements: ,
(2) m = Cs log(n/s) signed Bernoulli (Rademacher) measurements: ,
(3) m = Cs log4(n) random rows of a DFT matrix: af ~ {f1, …, fn},
(4) for n = 2d: m = Cs log4(n) random rows of a Hadamard matrix: ah ~ {h1, …, hn}.
A rigorous treatment of all these cases can be found in Foucart and Rauhut [3]. Here, and throughout this work, C > 0 denotes an absolute constant whose exact value depends on the context but is always independent of the problem parameters n, s, and m. It is instructive to compare the amount of randomness that is required to generate one instance of the random vectors in question. A random signed Bernoulli vector requires n random bits (one for each coordinate), while a total of log2(n) random bits suffice to select a random row of a Hadamard matrix. A comparison between complex standard Gaussian vectors and random Fourier vectors indicates a similar discrepancy. In summary: highly structured random vectors, like af, ah require exponentially fewer random bits to generate than generic random vectors, like ag, asb. Importantly, this transition from generic measurements to highly structured ones comes at a price. The number of measurements required in cases (3) and (4) scales poly-logarithmically in n. More sophisticated approaches allow for converting this offset into a poly-logarithmic scaling in s rather than n [14, 15]. Another, arguably even higher price, is hidden in the proof techniques behind these results. They are considerably more involved.
The following two subsections are devoted to introducing formalisms that allow for partially de-randomizing signed Bernoulli vectors and complex standard Gaussian vectors, respectively.
1.3. Partially De-randomizing Signed Bernoulli Vectors
Throughout this work, we endow ℂn with the standard inner product . We denote the associated (Euclidean) norm by . Let be a signed Bernoulli vector with coefficients ϵi ~ {±1} chosen independently at random (Rademacher random variables). Then,
This feature is equivalent to isotropy of signed Bernoulli vectors:
for all z ∈ ℂn.
Independent sign entries are sufficient, but not necessary for this feature. Indeed, suppose that n = 2d is a power of two. Then, the rows of a Sylvester Hadamard matrix correspond to a particular subset of n sign vectors that are also proportional to an orthonormal basis. The orthonormal basis property ensures that a randomly selected Hadamard row is also isotropic. In turn, the coordinates ai ∈ {±1} of ah also obey (2), despite not being independent instances of random signs. This feature is called pairwise independence and naturally generalizes to k ≥ 2:
Definition 1. (k-wise independence.) Fix k ≥ 2 and let ϵi denote independent instances of a signed Bernoulli random variable. We call a random sign vector a ∈ {±1}n k-wise independent, if its components a1, …, an obey
for all k-tuples of indices 1 ≤ i1, …, ik ≤ n.
For k = 2, this defining property reduces to Equation (2) and is equivalent to demanding isotropy of the distribution. Random rows of Hadamard matrices form a concrete example for pairwise independence.
What is more, explicit constructions for k-wise independent vectors in ℝn are known for any k and n. In this work we focus on particular constructions that rely on generalizing the following instructive example. Fix n = 3 and consider the M = 4 rows of the following matrix:
The first two columns summarize all possible tuples (k = 2 combinations) of ±1. The coefficients of the third column correspond to their entry-wise product. Hence, the third column is completely characterized by the first two and therefore three components of a selected row are not mutually independent. Nonetheless, each subset of two coordinates does mimic independent behavior: all possible length-two combinations of ±1 occur exactly once in these two columns. This ensures that a randomly selected row obeys Equation (4) for k = 2 (pairwise independence). The concept of orthogonal arrays [16] generalizes this simple example.
Definition 2. (Orthogonal array) A (binary) orthogonal array of strength k with M rows and n columns is a M × n sign matrix such that every selection of k columns contains all elements of {±1}k an equal number of times.
The example from above is an 4 × 3 orthogonal array of strength 2. Strength-k orthogonal arrays are closely related to the concept of k-wise independence. The following implication is straightforward.
Lemma 1. Selecting a row of an M × n orthogonal array of strength k uniformly at random produces k-wise independent random vectors in n dimensions.
This correspondence identifies orthogonal arrays as general-purpose seeds for pseudo-random behavior. What is more, explicit constructions of orthogonal arrays are known for any k and any n. In contrast to the “full” array that lists all 2n possible elements of {±1}n as its rows, these constructions typically only require rows. This fundamental restriction is called Rao's bound and only scales polynomially in the dimension n. Choosing a random row from such an array only requires random bits and produces a random vector that is k-wise independent.
1.4. Partially Derandomizing Complex Standard Gaussian Vectors
Let us now discuss another general-purpose tool for (partial) de-randomization. Concentration of measure implies that n-dimensional standard complex Gaussian vectors concentrate sharply around the complex sphere of radius . Hence, they behave very similarly to vectors chosen uniformly from this sphere. For any k ∈ ℕ, such spherical random vectors obey
for all z ∈ ℂn.
Here, dw denotes the uniform measure on the complex unit sphere . This formula characterizes even moments of the uniform distribution2 on n−1. The concept of k-designs [17] uses this moment formula as a starting point for partial de-randomization. Roughly speaking, a k-design is a finite subset of -length vectors such that the uniform distribution over these vectors reproduces the uniform measure on up to k-th moments. More precisely:
Definition 3. A set of N vectors is called a (complex projective) k-design if, for any l ∈ [k] = {1, …, k}, a randomly selected element a(k) obeys
(Spherical) k-designs were originally developed as cubature formulas for the real-valued unit sphere [17]. The concept has since been extended to other sets. A generalization to the complex projective space ℂPn−1 gives rise to Definition 3. Complex projective k-designs are known to exist for any k and any dimension n (see e.g.,[18–20]). However, explicit constructions for k ≥ 3 are notoriously difficult to find. In contrast, several explicit families of 2-designs have been identified. Here, we will focus on one such family. Two orthonormal bases and of ℂn are called mutually unbiased if
A prominent example for such a basis pair is the standard basis and the Fourier, or Hadamard, basis, respectively. One can show that at most n + 1 different orthonormal bases may exist that have this property in a pairwise fashion [21, Theorem 3.5]. Such a set of n + 1 bases is called a maximal set of mutually unbiased bases (MMUB). For instance, in n = 2 the standard basis together with
forms a MMUB. Importantly, MMUBs are always (proportional to) 2-designs [22]. Explicit constructions exist for any prime power dimension n and one can ensure that the standard basis is always included. Here we point out one construction that is particularly simple if the dimension n ≥ 5 is prime [23]: The standard basis vectors together with all vectors whose entry-wise coefficients correspond to
form a MMUB. Here is a n-th root of unity. The parameter α ∈ [n] singles out one of the n different bases, while λ ∈ [n] labels the n corresponding basis vectors. Excluding the standard basis, this set of n2 vectors corresponds to all time-frequency shifts of a discrete Alltop sequence [24].
1.5. Main Results
In the following , like C, denotes an absolute constant whose precise value may depend on the context.
Theorem 1. (CS from orthogonal array measurements.) Suppose that a matrix A contains m ≥ Cs log(2n) rows that are chosen independently from strength-4 orthogonal array. Then, with probability at least , any s-sparse x ∈ ℂn can be recovered from y = Ax by solving the convex optimization problem (1).
Theorem 2. (CS from time-frequency shifted Alltop sequences.) Let n ≥ 5 be prime and suppose that A contains m ≥ Cs log(2n) rows that correspond to random time-frequency shifts of the n-dimensional Alltop sequence (6). Then, with probability at least , any s-sparse x ∈ ℝn can be recovered from y = Ax by solving (1).
This result readily generalizes to measurements that are sampled from a maximal set of mutually unbiased bases (excluding the standard basis). Time-frequency shifts of the Alltop sequence are one concrete construction that applies to prime dimensions only.
Note that the cardinality of all Alltop shifts is n2. Hence, 2log2(n) random bits suffice to select a random time-frequency shift. In turn, a total of
random bits are required for sampling a complete measurement matrix A. This number is exponentially smaller than the number of random bits required to generate a matrix with independent complex Gaussian entries. A similar comparison holds true for random signed Bernoulli matrices and columns sampled from a strength-4 orthogonal array.
Highly structured families of vectors – such as rows of a Fourier, or Hadamard matrix – require even less randomness to sample from: only log2(n) bits are required to select such a row uniformly at random. However, existing recovery guarantees are weaker than the main results presented here. They require an order of Cspolylog(s) log(n) random measurements to establish comparable results. Thus, the total number of random bits required for such a procedure scales like Cspolylog(s) log2(n). Equation (7) still establishes a logarithmic improvement in terms of sparsity.
The recovery guarantees in Theorem 1 and Theorem 2 can be readily extended to ensure stability with respect to noise corruption in the measurements and robustness with respect to violations of the model assumption of sparsity. We refer to section 3 for details.
We also emphasize that there are results in the literature that establish compressed sensing guarantees with comparable, or even less, randomness. Obviously, deterministic constructions are the extreme case in this regard. Early deterministic results suffer from a “quadratic bottleneck.” The number of measurements must scale quadratically in the sparsity: m ≃ s2. Although this obstacle was overcome, existing progress is still comparatively mild. Bourgain et al. [25], Mixon [26], Bandeira et al. [27] establish deterministic convergence guarantees for m ≃ s2−ϵ, where ϵ > 0 is a (very) small constant.
Closer in spirit to this work is Bandeira et al. [28]. There, the authors employ the Legendre symbol – which is well known for its pseudorandom behavior – to partially derandomize a signed Bernoulli matrix. In doing so, they establish uniform s-sparse recovery from m ≥ Cs log2(s) log(n) measurements that require an order of s log(s) log(n) random bits to generate. Compared to the main results presented here, this result gets by with less randomness, but requires more measurements. The proof technique is also very different.
To date, the strongest de-randomized reconstruction guarantees hail from a close connection between s-sparse recovery and Johnson-Lindenstrauss embeddings [29, 30]. These have a wide range of applications in modern data science. Kane and Nelson [31] established a very strong partial de-randomization for such embeddings. This result may be used to establish uniform s-sparse recovery for m = Cs log(n/s) measurements that require an order of s log(s log(n/s) log(n/s)) random bits. This result surpasses the main results presented here in both sampling rate and randomness required.
However, this strong result follows from “reducing” the problem of s-sparse recovery to a (seemingly) very different problem: find Johnson-Lindenstrauss embeddings. Such a reduction typically does not preserve problem-specific structure. In contrast, the approach presented here addresses the problem of sparse recovery directly and relies on tools from signal processing. In doing so, we maintain structural properties that are common in several applications of s-sparse recovery. Orthogonal array measurements, for instance, have ±1-entries. This is well-suited for the single pixel camera [32]. Alltop sequence constructions, on the other hand, have successfully been applied to stylized radar problems [33]. Both types of measurements also have the property that every entry has unit modulus. This is an important feature for communication applications like CDMA [34]. Having pointed out these high-level connections, we want to emphasize that careful, problem specific adaptations may be required to rigorously exploit them. The framework developed here may serve as a guideline on how to achieve this goal in concrete scenarios.
2. Proofs
2.1. Textbook-Worthy Proof for Real-Valued Compressed Sensing With Gaussian Measurements
This section is devoted to summarizing an elegant argument, originally by Rudelson and Vershynin [14], see also [35–37] for arguments that are similar in spirit. This argument only applies to s-sparse recovery of real-valued signals. We will generalize a similar idea to the complex case later on.
In this work we are concerned with uniform reconstruction guarantees: with high probability, a single realization of the measurement matrix A allows for reconstructing any s-sparse vector x by means of ℓ1-regularization (1). A necessary pre-requisite for uniform recovery is the demand that the kernel, or nullspace, of A must not contain any s-sparse vectors. This condition is captured by the nullspace property (NSP). Define,
where is the approximation error (measured in ℓ1-norm) one incurs when approximating x by s-sparse vectors.
A matrix A obeys the NSP of order s (s-NSP) if,
The set Ts is a subset of the unit sphere that contains all normalized s-sparse vectors. This justifies the informal definition of the NSP: no s-sparse vector is an element of the nullspace of A. Importantly, the NSP is not only necessary, but also sufficient for uniform recovery (see e.g., Foucart and Rauhut [3, Theorem 4.5]). Hence, universal recovery of s-sparse signals readily follows from establishing Rel. (9). The nullspace property and its relation to s-sparse recovery has long been somewhat folklore. We refer to Foucart and Rauhut [3, Notes on section 4] for a discussion of its origin.
The following powerful statement allows for exploiting generic randomness in order to establish nullspace properties. It is originally due to Gordon [38], but we utilize a more modern reformulation, see Foucart and Rauhut [3, Theorem 9.21].
Theorem 3. (Gordon's escape through a mesh.) Let A be a real-valued m × n standard Gaussian matrix3 and let E ⊆ n−1 ⊂ ℝn be a subset of the real-valued unit sphere. Define the Gaussian width where the expectation is over realizations of a standard Gaussian random vector. Then, for t ≥ 0 the bound
is true with probability at least 1 − e−t2/2.
This is a deep statement that connects random matrix theory to geometry: the Gaussian width is a rough measure of the size of the set E ⊆ n−1. Setting E = Ts allows us to conclude that a matrix A encompassing m independent Gaussian measurements is very likely to obey the s-NSP (9), provided that (m − 1) exceeds . In order to derive an upper bound on ℓ(Ts), we may use the following inclusion
see e.g., Kabanava and Rauhut [35, Lemma 3] and Rudelson and Vershynin [14, Lemma 4.5]. Here, denotes the set of all s-sparse vectors with unit length. In turn,
because the linear function z ↦ 〈ag, z〉 achieves its maximum value at the boundary Σs of the convex set conv (Σs). The right-hand side of (10) is the expected supremum of a Gaussian process indexed by z ∈ Σs. Dudley's inequality [39], see also [3, Theorem 8.23], states
where are covering numbers associated with the set Σs. They are defined as the smallest cardinality of an u-covering net with respect to the Euclidean distance. A volumetric counting argument yields and Dudley's inequality therefore implies
where c is an absolute constant. This readily yields the following assertion (choose for sufficiently small).
Theorem 4. (NSP for Gaussian measurements.) A number of m ≥ c2s log(en/s) independent real-valued Gaussian measurements obeys the (real-valued) s-NSP with probability at least .
This argument is exemplary for generic proof techniques: strong results from probability theory allow for establishing close-to-optimal recovery guarantees in a relatively succinct fashion.
2.2. Extending the Scope to Subgaussian Measurements
The extended arguments presented here are largely due to Dirksen, Lecue and Rauhut [36]. Again, we will focus on the real-valued case.
Gordon's escape through a mesh is only valid for Gaussian random matrices A. Novel methods are required to extend this proof technique beyond this idealized case. Comparatively recently, Mendelson provided such a generalization [40, 41].
Theorem 5. (Mendelson's small ball method, Tropp's formulation [37]). Suppose that A is a random m × n matrix whose rows correspond to m independent realizations of a random vector a ∈ ℝn. Fix a set E ⊆ ℝn, and define,
is the empirical average over m independent copies of a weighted by uniformly random signs ϵi ~ {±1}. Then, for any t, ξ > 0
with probability at least 1 − 2e−t2/2.
It is worthwhile to point out that for real-valued Gaussian vectors this result recovers Theorem 3 up to constants. Fix ξ > 0 of appropriate size. Then, E ⊆ n−1 ensures that ξ Q2ξ(ag, E) is constant. Moreover, Wm(ag, E) reduces to the usual Gaussian width ℓ(E).
Mendelson's small ball method can be used to establish the nullspace property for independent random measurements a ∈ ℝn that exhibit subgaussian behavior:
Signed Bernoulli vectors are a concrete example. Such random vectors are isotropic (3) and direct computation also reveals
because there are 3 possible pairings of four indices. Next, set . An application of the Paley-Zygmund inequality then allows for bounding the parameter Q2ξ(asb, Ts) in Mendelson's small ball method from below:
This lower bound is constant for any ξ ∈ (0, 1/2).
Next, note that Xz = 〈z, h〉 is a stochastic process that is indexed by z ∈ ℝn. This process is centered (Xz = 0) and Equation (11) implies that it is also subgaussian. Moreover, readily follows from isotropy (3). Unlike Gordon's escape through a mesh, Dudley's inequality does remain valid for such stochastic processes with subgaussian marginals. We can now repeat the width analysis from the previous section to obtain
Fixing ξ > 0 sufficiently small, setting and inserting these bounds into Equation (5) yields the following result.
Theorem 6. (NSP for signed Bernoulli measurements.) A matrix A encompassing m ≥ Cs log(en/s) random signed Bernoulli measurements obeys the (real-valued) s-NSP with probability at least .
A similar result remains valid for other classes of independent measurements with subgaussian marginals (11).
2.3. Generalization to Complex-Valued Signals and Partial De-Randomization
The nullspace property, as well as its connection to uniform s-sparse recovery readily generalizes to complex-valued s-sparse vectors (see e.g., Foucart and Rauhut [3], section 4). In turn, Mendelson's small ball method may also be generalized to the complex-valued case:
Theorem 7. (Mendelson's small ball method for complex vector spaces.) Suppose that the rows of A correspond to m independent copies of a random vector a ∈ ℂn. Fix a set E ⊆ ℂn and define
Then, for any t, ξ > 0
with probability at least 1 − 2e−t2/2.
Such a generalization was conjectured by Tropp [37], but we are not aware of any rigorous proof in the literature. We provide one in subsection 5.1 and believe that this generalization may be of independent interest. In particular, this extension allows for generalizing the arguments from the previous subsection to the complex-valued case.
Let us now turn to the main scope of this work: partial de-randomization. Effectively, Mendelson's small ball method reduces the task of establishing nullspace properties to bounding the two parameters and Wm(a, Ts) in an appropriate fashion. A lower bound on the former readily follows from the Paley-Zygmund inequality, provided that the following relations hold for any z ∈ ℂn:
Here, C4 > 0 is constant.
Indeed, inserting these bounds into the Paley-Zygmund inequality yields
In contrast, establishing an upper bound on Wm(a, Ts) via Dudley's inequality requires subgaussian marginals (11) (that must not depend on the ambient dimension). This implicitly imposes stringent constraints on all moments of a simultaneously. An additional assumption allows to considerably weaken these demands:
Here, e1, …, en denotes the standard basis of ℂn. Incoherence has long been identified as a key ingredient for developing s-sparse recovery guarantees. Here, we utilize it to establish an upper bound on Wm(A, Ts) that does not rely on subgaussian marginals.
Lemma 2. Let a ∈ ℂn be a random vector that is isotropic and incoherent. Let be the complex-valued generalization of the set defined in Equation (8) and assume m ≥ log(2n). Then,
This bound only requires an appropriate scaling of the first two moments (isotropy) but comes at a price. The bound scales logarithmically in n rather than n/s. We defer a proof of this statement to subsection 5.2 below. Inserting the bounds (13) and (15) into the assertion of Theorem 7 readily yields the main technical result of this work:
Theorem 8. Suppose that a ∈ ℂn is a random vector that obeys incoherence, isotropy and the 4th moment bound. Then, choosing
instances of a uniformly at random results in a measurement matrix A that obeys the complex-valued nullspace property of order s with probability at least .
In complete analogy to the real-valued case, the complex nullspace property ensures uniform recovery of s-sparse vectors x ∈ ℂn from y = Ax via solving the convex optimization problem (1).
2.4. Recovery Guarantee for Strength-4 Orthogonal Arrays
Suppose that is chosen uniformly from a strength-4 orthogonal array. By definition, each component ai of a has unit modulus. This ensures incoherence. Moreover, [aiaj] = [ϵiϵj] = δij, because 4-wise independence necessarily implies 2-wise independence. Isotropy then readily follows from (3). Finally, 4-wise independence suffices to establish the 4th moment bound. By assumption = [ϵiϵjϵkϵl] and we may thus infer
In summary: aoa meets all the requirements of Theorem 8. Theorem 1 then follows from the fact that the complex nullspace property ensures uniform recovery of all s-sparse signals simultaneously.
2.5. Recovery Guarantee for Mutually Unbiased Bases
Suppose that is chosen uniformly from a maximal set of n mutually unbiased bases (excluding the standard basis) whose elements are re-normalized to length . Random time-frequency shift of the Alltop sequence (6) are a concrete example for such a sampling procedure, provided that the dimension n ≥ 5 is prime.
The vector amub is chosen from a union of n bases that are all mutually unbiased with respect to the standard basis, see Equation (5). Together with normalization to length , this readily establishes incoherence: with probability one. Next, by assumption amub is chosen uniformly from a union of n re-scaled orthonormal bases. Let us denote each of them by , where 1 ≤ l ≤ n labels the different basis. Then,
which implies isotropy. Finally, a maximal set of (n + 1) mutually unbiased bases – including the standard basis which we denote by – forms a 2-design according to Definition 3. For any z ∈ ℂn this property ensures
which establishes the 4th moment bound. In summary, the random vector meets the requirements of Theorem 8. Theorem 2 then readily follows form the implications of the nullspace property for s-sparse recovery.
3. Extension to Noisy Measurements
The nullspace property may be generalized to address two imperfections in s-sparse recovery simultaneously: (i) the vector x ∈ ℂd may only be approximately sparse in the sense that it is well-approximated by an s-sparse vector, (ii) the measurements may be corrupted by additive noise: y = Ax + s with s ∈ ℂm.
To state this generalization, we need some additional notation. For z ∈ ℂn and s ∈ [n], let be the vector that only contains the s largest entries in modulus. All other entries are set to zero. Likewise, we write to denote the remainder. In particular, . An m × n matrix A obeys the robust nullspace property of order s with parameters ρ ∈ (0, 1) and τ > 0 if
see e.g., Foucart and Rauhut [3, Definition 4.21]. This extension of the nullspace property is closely related to stable s-sparse recovery via basis pursuit denoising:
Here, η > 0 denotes an upper bound on the strength of the noise corruption: ||s|| ℓ 2 ≤ η. [3, Theorem 4.22] draws the following precise connection: suppose that A obeys the robust nullspace property with parameters ρ and τ. Then, the solution z♯ ∈ ℂn to (16) is guaranteed to obey
where and D2 = (3 + ρ)τ/(1 − ρ). The first term on the r.h.s. vanishes if x is exactly s-sparse and remains small if x is well approximated by a s-sparse vector. The second term scales linearly in the noise bound η ≥ ||s||ℓ2 and vanishes in the absence of noise corruption.
In the previous section, we have established the classical nullspace property for measurements that are chosen independently from a vector distribution that is isotropic, incoherent and obeys a bound on the 4th moments. This argument may readily be extended to establish the robust nullspace property with relatively little extra effort. To this end, define the set
A moment of thought reveals that the matrix A obeys the robust nullspace property with parameters ρ, τ if
What is more, the following inclusion formula is also valid:
see Kabanava and Rauhut [35, Lemma 3] and Rudelson and Vershynin [14, Lemma 4.5]. This ensures that the bounds on the parameters in Mendelson's small ball method generalize in a rather straightforward fashion. Isotropy, incoherence and the 4th moment bound ensure
Now, suppose that A subsumes m ≥ Cρ−2s log(2n) independent copies of the random vector a ∈ ℂn. Then, Theorem 7 readily asserts that with probability at least
where c > 0 is another constant. Previously, we employed Mendelson's small ball method to merely assert that a similar infimum is not equal to zero. Equation (19) provides a strictly positive lower bound with comparable effort. Comparing this relation to Equation (18) highlights that this is enough to establish the robust nullspace property with parameters ρ and . In turn, a stable generalization of the main recovery guarantee follows from Equation (17).
Theorem 9. Fix ρ ∈ (0, 1) and s ∈ ℕ. Suppose that we sample m ≥ Cρ−2s log(n) independent copies of an isotropic, incoherent random vector a ∈ ℂn that also obeys the 4th moment bound. Then, with probability at least , the resulting measurement matrix A allows for stable, uniform recovery of (approximately) s-sparse vectors. More precisely, the solution z♯ to (16) is guaranteed to obey
where D1, D2 > 0 depend only on ρ.
4. Numerical Experiments
In this part we demonstrate the performance which can be achieved with our proposed derandomized constructions and we compare this to generic measurement matrices (Gaussian, signed Bernoulli). However, since the orthogonal array construction is more involved we first provide additional details relevant for numerical experiments.
Details on orthogonal arrays: An orthogonal array OA(λσk, n, σ, k) of strength k, with n factors and σ levels are an λσk × n array of σ different symbols such that in any k columns every ordered σk-tuple occurs in exactly λ rows. Arrays with λ = 1 are called simple. A comprehensive treatment can be found in the book [16]. Known arrays are listed in several libraries4. Often the symbol alphabet is not relevant, but we use the set ℤσ = {0, …, σ − 1} for concreteness. Such arrays can be represented as a matrix in . For σ = qp with q prime the simple orthogonal array OA(σk, n, σ, k) is linear if the qpt rows of the matrix form a vector space over Fq. The runs of an orthogonal array (the rows of the corresponding matrix) can also be interpreted as codewords of a code and vice versa. The array is linear if and only if the corresponding code is linear [16, Chapter 4]. This relationship allows to employ classical code constructions to construct orthogonal arrays.
In this work we propose to generate sampling matrices by selecting m ≤ M = λσk rows at random from an orthogonal array OA(λσ4, n, σ, 4) of strength k = 4 and with n factors. Intuitively, m log2(M) bits are then required to specify such a matrix A. For k = 4, a classical lower bound due to Rao [42] demands
Arrays that saturate this bound are called tight (or complete). In summary, an order of slog2(n) bits are required to sample a m × n matrix A with m ≥ Cs log(n) rows according to this procedure.
Strength-4 Constructions: For compressed sensing applications, we want arrays with a large number of factors n since this corresponds to the ambient dimension of the sparse vectors to recover. On the other hand the run size M should scale “moderately” to describe the random matrices only with few bits. Most constructions use an existing orthogonal array as a seed to construct larger arrays. Known binary arrays of strength 4 are for example the simple array OA(16, 5, 2, 4), or OA(80, 6, 2, 4). Pat [43] proposes an algorithm that uses a linear orthogonal array OA(N, n, σ, k) as a seed to construct a linear orthogonal array OA(N2, n2 + 2n, σ, k). This procedure may then be iterated.
Numerical results for orthogonal arrays: Figure 1 summarizes the empirical performance of basis pursuit (1) from independent orthogonal array measurements. We consider real-valued signals x and quantify the performance in terms of the normalized ℓ2-recovery error (NMSE) where z♯ is the solution of (1). To construct the orthogonal array, algorithm [43] is applied twice OA(16, 5, 2, 4) → OA(256, 35, 2, 4) → OA(65536, 1295, 2, 4). The 323 rows are uniformly samples from this array, i.e., the sampling matrix A has ±1 entries (instead of binary entries) and size 323 × 1295. But note that, in the case of non-negative sparse vectors, the corresponding binary 0/1-matrices may be used instead directly to recover with non-negative least-squares [44]. The sparsity of the unknown vector has been varied between 1…180. For each sparsity many experiments are performed to compute NMSE. In each run, the support of the unknown vector has been chosen uniformly at random and the values are independent instances of a standard Gaussian random variable. For comparison, we have also included the corresponding performances of a generic sampling matrix (signed Bernoulli) of the same size. Numerically, the partially derandomized orthogonal array construction achieves essentially the same performance as its generic counterpart.
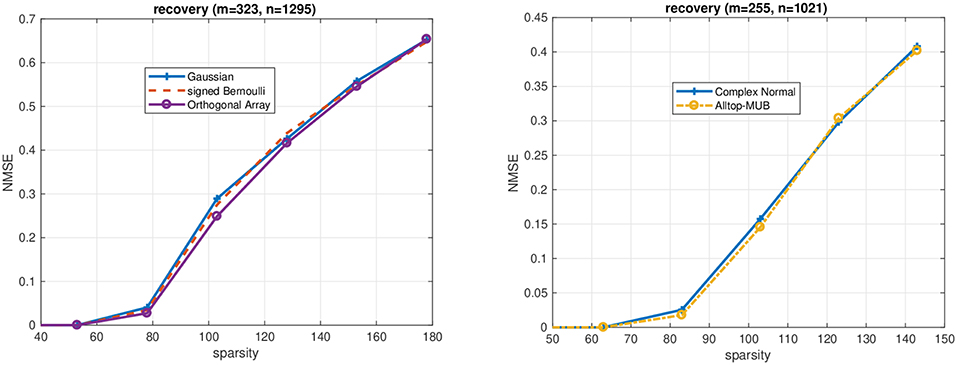
Figure 1. (Left) Performance of basis pursuit for m = 323 and n = 1295 (real-valued signals) from random orthogonal array measurements and their generic counterpart (signed Bernoulli). (Right) Performance of basis pursuit for m = 255 and n = 1021 (complex-valued signals) from random time-frequency shifted Alltop sequences and their generic counterpart (standard complex Gaussian vectors).
Numerical results for the Alltop design: Figure 1 shows the NMSE achieved for measurement matrices based on subsampling from an Alltop-design (6). The data is obtained in the same way as above, but the sparse vectors are generated as iid. complex-normal distributed on the support. For comparison the results for a (complex) standard Gaussian sampling matrix are included as well. Again, the performance of random Alltop-design measurements essentially matches its generic (Gaussian) counterpart.
5. Additional Proofs
5.1. Proof of Theorem 7
The proof is based on rather straightforward modifications of Tropp's proof for Mendelson's small ball method [37]. Let a ∈ ℂn be a complex-valued random vector. Suppose that are independent copies of a and let A be the m × n matrix whose i-th row is given by ai. The goal is to obtain a lower bound on where E ⊂ ℂn is an arbitrary set. First, note that ℓ1 and ℓ2 norms on ℝ2m are related via . For any z ∈ E this relation ensures
Next, fix ξ > 0 and introduce the indicator function {x ≥ ξ} which obeys x ≥ ξ{x ≥ ξ} for all x ≥ 0. Consequently,
Also, note that the expectation value of each summand obeys
according to the union bound. The last line follows from a simple observation. Let z = a + ib be a complex number. Then, necessarily implies either |a| ≥ ξ, or |b| ≥ ξ (or both). Next, define
and note that the estimate from above ensures
Adding and subtracting to Equation (21) and taking the infimum yields
Here we have applied Equation (22) to bound the contribution of the first term. Since Q2ξ(z) features both a real and imaginary part and we can split up the remaining supremum accordingly. The suprema over real and complex parts individually correspond to
and the vectors a1, …, am are independent copies of a single random vector a ∈ ℂn. The bounded difference inequality [45, section 6.1] asserts that both expressions concentrate around their expectation. More precisely, for any t > 0
Therefore, the union bound grants a transition from R(E, a) + I(E, a) to with probability at least 1 − 2e−t2/2. These expectation values can be further simplified. Define the soft indicator function
which admits the following bounds: {|s| ≥ 2ξ} ≤ ψξ(s) ≤ {|s| ≥ ξ} for all s ∈ ℝ. Moreover, ξψξ(s) is a contraction, i.e., a real-valued function with Lipschitz constant one that also obeys ξψξ(0) = 0. Rademacher symmetrization [3, Lemma 8.4] and the Rademacher comparison principle [46, Equation (4.20)] yield
where . A completely analogous bound holds true for I(E, a). Inserting both bounds into Equation (23) establishes
with probability at least 1 − 2e−t2/2. Setting establishes the claim.
5.2. Proof of Lemma 2
The inclusion Ts ⊂ 2conv(Σs) remains valid in the complex case. Moreover, every z ∈ conv(Σs) necessarily obeys
because the maximum value of a convex function is achieved at the boundary. Hoelder's inequality therefore implies
where . Moreover,
and we may bound both expressions on the r.h.s. independently. For the first term, fix θ > 0 and use Jensen's inequality (the logarithm is a concave function) to obtain
Monotonicity and non-negativity of the exponential function then imply
where we have also used that all ϵi's and ai's are independent. The remaining moment generating functions can be bounded individually. Fix 1 ≤ k ≤ n, σ ∈ {±1} and 1 ≤ i ≤ m and exploit the Rademacher randomness to infer
because σ2 = 1. Incoherence moreover ensures . This ensures that the remaining expectation value is upper-bounded by . Inserting these individual bounds into the original expression yields
for any . Choosing minimizes this upper bound and is feasible, by assumption. A completely analogous bound can be derived for the expected maximum absolute value of the imaginary part. Combining both yields
and inserting this bound into (24) ensures
Author Contributions
RK developed the technical aspects of the paper. PJ is responsible for the numerical aspects and the discussion of orthogonal arrays. Some of the main conceptual ideas are due to DM. These in particular include the idea of employing orthogonal arrays to partially derandomize signed Bernoulli matrices and the insight that a partial de-randomization of Gordon's escape through a mesh is essential for achieving the results. All authors contributed to the introduction and general presentation.
Funding
PJ is supported by the DFG grant JU 2795/3 and DAAD grant 57417688. RK was in part supported by Joel A. Tropp under the ONR Award No. N00014-17-12146 and also acknowledges funding provided by the Institute of Quantum Information and Matter, an NSF Physics Frontiers Center (NSF Grant PHY-1733907). DM was partially supported by AFOSR FA9550-18-1-0107, NSF DMS 1829955, and the Simons Institute of the Theory of Computing. We acknowledge support by the German Research Foundation and the Open Access Publication Fund of TU Berlin.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors want to thank David Gross for providing the original ideas that ultimately led to this publication.
Footnotes
1. ^Existing deterministic constructions (see e.g., Bandeira et al.[13]), do not (yet) yield comparable statements.
2. ^For comparison, a complex standard Gaussian vector obeys instead.
3. ^This is a m × n matrix where each entry is sampled independently from the standard normal distribution .
4. ^For example http://neilsloane.com/oadir/ or http://pietereendebak.nl/oapage/
References
1. Donoho DL. Compressed sensing. IEEE Trans Inform Theory. (2006) 52:1289–306. doi: 10.1109/TIT.2006.871582
2. Candes EJ, Romberg J, Tao T. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans Inform Theory. (2006) 52:489–509. doi: 10.1109/TIT.2005.862083
3. Foucart S, Rauhut H. A Mathematical Introduction to Compressive Sensing. Applied and Numerical Harmonic Analysis. New York, NY: Birkhäuser/Springer (2013). doi: 10.1007/978-0-8176-4948-7
4. Eldar YC, Kutyniok G. Compressed Sensing: Theory and Applications. Cambridge, UK: Cambridge University Press (2012).
5. Candès EJ, Strohmer T, Voroninski V. Phaselift: exact and stable signal recovery from magnitude measurements via convex programming. Commun Pure Appl Math. (2013) 66:1241–74. doi: 10.1002/cpa.21432
6. Candès E, Li X. Solving quadratic equations via PhaseLift when there are about as many equations as unknowns. Found Comput Math. (2013). p. 1–10. doi: 10.1007/s10208-013-9162-z
7. Gross D, Krahmer F, Kueng R. A partial derandomization of phaseLift using spherical designs. J Fourier Anal Appl. (2015) 21:229–66. doi: 10.1007/s00041-014-9361-2
8. Kueng R, Rauhut H, Terstiege U. Low rank matrix recovery from rank one measurements. Appl Comput Harmon Anal. (2017) 42:88–116. doi: 10.1016/j.acha.2015.07.007
9. Kabanava M, Kueng R, Rauhut H, Terstiege U. Stable low-rank matrix recovery via null space properties. Inform Inference. (2016) 5:405–41. doi: 10.1093/imaiai/iaw014
10. Kueng R, Gross D, Krahmer F. Spherical designs as a tool for derandomization: the case of PhaseLift. In: 2015 International Conference on Sampling Theory and Applications (Washington, DC: SampTA) (2015). p. 192–6. doi: 10.1109/SAMPTA.2015.7148878
11. Kueng R, Zhu H, Gross D. Low rank matrix recovery from Clifford orbits. arXiv [Preprint] (2016). arXiv:161008070.
12. Tropp JA. A mathematical introduction to compressive sensing [Book Review]. Bull Amer Math Soc. (2017) 54:151–65. doi: 10.1090/bull/1546
13. Bandeira AS, Fickus M, Mixon DG, Wong P. The road to deterministic matrices with the restricted isometry property. J Fourier Anal Appl. (2013) 19:1123–49. doi: 10.1007/s00041-013-9293-2
14. Rudelson M, Vershynin R. On sparse reconstruction from Fourier and Gaussian measurements. Commun Pure Appl Math. (2008) 61:1025–45. doi: 10.1002/cpa.20227
15. Cheraghchi M, Guruswami V, Velingker A. Restricted isometry of fourier matrices and list decodability of random linear codes. SIAM J Comput. (2013) 42:1888–914. doi: 10.1137/120896773
16. Hedayat AS, Sloane NJA, Stufken J. Orthogonal Arrays: Theory and Applications New York, NY: Springer-Verlag (1999). doi: 10.1007/978-1-4612-1478-6
17. Delsarte P, Goethals JM, Seidel JJ. Spherical codes and designs. Geometriae Dedicata. (1997) 6:363–88. doi: 10.1007/BF03187604
18. Bajnok B. Construction of spherical t-designs. Geom Dedicata. (1992) 43:167–79. doi: 10.1007/BF00147866
19. Korevaar J, Meyers JLH. Chebyshev-type quadrature on multidimensional domains. J Approx Theory. (1994) 79:144–64. doi: 10.1006/jath.1994.1119
20. Hayashi A, Hashimoto T, Horibe M. Reexamination of optimal quantum state estimation of pure states. Phys Rev A. (2005) 72:032325. doi: 10.1103/PhysRevA.72.032325
21. Bandyopadhyay S, Boykin PO, Roychowdhury V, Vatan F. A new proof for the existence of mutually unbiased bases. Algorithmica. (2002) 34:512–8. doi: 10.1007/s00453-002-0980-7
22. Klappenecker A, Rotteler M. Mutually unbiased bases are complex projective 2-designs. In: A. Klappenecker, M. Roetteler Editors. Proceedings International Symposium on Information Theory, 2005. (Adelaide, AU: ISIT) (2005). p. 1740–4. doi: 10.1109/ISIT.2005.1523643
23. Klappenecker A, Rötteler M. Constructions of Mutually Unbiased Bases. In: Mullen GL, Poli A, Stichtenoth H, editors. Finite Fields and Applications. Berlin; Heidelberg: Springer (2004). p. 137–44. doi: 10.1007/978-3-540-24633-6-10
24. Alltop W. Complex sequences with low periodic correlations. IEEE Trans Inform Theory. (1980) 26:350–4. doi: 10.1109/TIT.1980.1056185
25. Bourgain J, Dilworth S, Ford K, Konyagin S, Kutzarova D. Explicit constructions of RIP matrices and related problems. Duke Math J. (2011) 159:145–85. doi: 10.1215/00127094-1384809
26. Mixon DG. In: Boche H, Calderbank R, Kutyniok G, Vybíral J, editors. Explicit Matrices With the Restricted Isometry Property: Breaking the Square-Root Bottleneck. Cham: Springer International Publishing (2015). p. 389–417. doi: 10.1007/978-3-319-16042-9-13
27. Bandeira AS, Mixon DG, Moreira J. A conditional construction of restricted isometries. Int Math Res Notices. (2017) 2017:372–81. doi: 10.1093/imrn/rnv385
28. Bandeira AS, Fickus M, Mixon DG, Moreira J. Derandomizing restricted isometries via the legendre symbol. Constr Approx. (2016) 43:409–24. doi: 10.1007/s00365-015-9310-6
29. Baraniuk R, Davenport M, DeVore R, Wakin M. A simple proof of the restricted isometry property for random matrices. Constr Approx. (2008) 28:253–63. doi: 10.1007/s00365-007-9003-x
30. Krahmer F, Ward R. New and improved johnson-Lindenstrauss embeddings via the restricted isometry property. SIAM J Math Anal. (2011) 43:1269–81. doi: 10.1137/100810447
31. Kane DM, Nelson J. A derandomized sparse Johnson-Lindenstrauss transform. arXiv [Preprint] (2010). arXiv:10063585.
32. Duarte MF, Davenport MA, Takhar D, Laska JN, Sun T, Kelly KF, et al. Single-pixel imaging via compressive sampling. IEEE Signal Process Magaz. (2008) 25:83–91. doi: 10.1109/MSP.2007.914730
33. Herman MA, Strohmer T. High-resolution radar via compressed sensing. IEEE Trans Signal Process. (2009) 57:2275–84. doi: 10.1109/TSP.2009.2014277
34. Tropp JA, Dhillon IS, Heath RW, Strohmer T. CDMA signature sequences with low peak-to-average-power ratio via alternating projection. In: The Thrity-Seventh Asilomar Conference on Signals, Systems Computers. Pacific Grove, CA (2003). p. 475–9.
35. Kabanava M, Rauhut H. Analysis ℓ1-recovery with frames and gaussian measurements. Acta Appl Math. (2015) 140:173–95. doi: 10.1007/s10440-014-9984-y
36. Dirksen S, Lecue G, Rauhut H. On the gap between restricted isometry properties and sparse recovery conditions. IEEE Trans Inform Theory. (2016) 99:1.
37. Tropp JA. Convex Recovery of a Structured Signal from Independent Random Linear Measurements. In: Pfander EG, editor. Sampling Theory, a Renaissance: Compressive Sensing and Other Developments. Birkhäuser: Springer International Publishing (2015). p. 67–101. doi: 10.1007/978-3-319-19749-4-2
38. Gordon Y. On Milman's inequality and random subspaces which escape through a mesh in ℝn. In: Lindenstrauss J, Milman VD, editors. Geometric Aspects of Functional Analysis. Berlin; Heidelberg: Springer Berlin Heidelberg (1988). p. 84–106. doi: 10.1007/BFb0081737
39. Dudley R. Sizes of compact subsets of Hilbert space and continuity of Gaussian processes. J Funct Anal. (1967) 1:290–330. doi: 10.1016/0022-1236(67)90017-1
41. Koltchinskii V, Mendelson S. Bounding the smallest singular value of a random matrix without concentration. Int Math Res Notices. (2015) 2015:12991–3008. doi: 10.1093/imrn/rnv096
42. Rao CR. Factorial experiments derivable from combinatorial arrangements of arrays. J R Stat Soc. (1947) 9:128–39. doi: 10.2307/2983576
43. Pat A. On Construction of a Class of Orthogonal Arrays. Ph.D. Thesis, Department of Mathematics, Indian Institute of Technology, Kharagpur, India. (2012).
44. Kueng R, Jung P. Robust nonnegative sparse recovery and the nullspace property of 0/1 measurements. IEEE Trans Inform Theory. (2018) 64:689–703. doi: 10.1109/TIT.2017.2746620
45. Boucheron S, Lugosi G, Massart P. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford: Oxford University Press (2013). doi: 10.1093/acprof:oso/9780199535255.001.0001
Keywords: compressed sensing, k-wise independence, orthogonal arrays, spherical design, derandomization
Citation: Jung P, Kueng R and Mixon DG (2019) Derandomizing Compressed Sensing With Combinatorial Design. Front. Appl. Math. Stat. 5:26. doi: 10.3389/fams.2019.00026
Received: 23 September 2018; Accepted: 01 May 2019;
Published: 06 June 2019.
Edited by:
Jean-Luc Bouchot, Beijing Institute of Technology, ChinaReviewed by:
Nguyen Quang Tran, Aalto University, FinlandShao-Bo Lin, Wenzhou University, China
Martin Lotz, University of Warwick, United Kingdom
Copyright © 2019 Jung, Kueng and Mixon. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Peter Jung, cGV0ZXIuanVuZ0B0dS1iZXJsaW4uZGU=; Richard Kueng, cmt1ZW5nQGNhbHRlY2guZWR1