 Bubacarr Bah1,2*
Bubacarr Bah1,2* Jared Tanner3
Jared Tanner3- 1The Research Centre, African Institute for Mathematical Sciences, Muizenberg, South Africa
- 2Department of Mathematical Sciences, University of Stellenbosch, Stellenbosch, South Africa
- 3Mathematics Institute, University of Oxford, Oxford, United Kingdom
We revisit the asymptotic analysis of probabilistic construction of adjacency matrices of expander graphs proposed in Bah and Tanner [1]. With better bounds we derived a new reduced sample complexity for d, the number of non-zeros per column of these matrices (or equivalently the left-degree of the underlying expander graph). Precisely ; as opposed to the standard , where N is the number of columns of the matrix (also the cardinality of set of left vertices of the expander graph) or the ambient dimension of the signals that can be sensed by such matrices. This gives insights into why using such sensing matrices with small d performed well in numerical compressed sensing experiments. Furthermore, we derive quantitative sampling theorems for our constructions which show our construction outperforming the existing state-of-the-art. We also used our results to compare performance of sparse recovery algorithms where these matrices are used for linear sketching.
1. Introduction
Sparse binary matrices, say A ∈ {0, 1}n×N, with n ≪ N are widely used in applications including graph sketching [2, 3], network tomography [4, 5], data streaming [6, 7], breaking privacy of databases via aggregate queries [8], compressed imaging of intensity patterns [9], and more generally combinatorial compressed sensing [10–15], linear sketching [7], and group testing [16, 17]. In all these areas we are interested in the case where n ≪ N, in which case A is used as an efficient encoder of sparse signals x ∈ ℝN with sparsity s ≪ n, where they are known to preserve ℓ1 distance of sparse vectors [18]. Conditions that guarantee that a given encoder, A, also referred to as a sensing matrix in compressed sensing, typically include the the nullspace, coherence, and the restricted isometry conditions, see [19] and references there in. The goal is for A to satisfy one or more of these conditions with the minimum possible n, the number of measurements. For uniform guarantees over all A, it has been established that n has to be Ω(s2), but that with high probability on the draw of random A, n can be for A with entries drawn from a sub-gaussian distribution, see [19] for a review of such results. Matrices with entries drawn from a Bernoulli distribution fall in the family of sub-gaussian but these are dense as opposed the the sparse binary matrices considered here. For computational advantages, such as faster application and smaller storage, it is advantageous to use sparse A in application [1, 14, 18].
Herein we consider the n achievable when A is an adjacency matrix of an expander graph [18], expander graph will be defined in the next section. Since the construction of such matrices can be construed as either a linear algebra problem or equivalently a graph theory one (in this manuscript we will focus more on the linear algebra discourse). There has been significant research on expander graphs in pure mathematics and theoretical computer science, see [20] and references therein. Both deterministic and probabilistic constructions of expander graphs have been suggested. The best known deterministic constructions achieve for some α > 0 [21]. On the other hand random constructions, first proven in Bassalygo and Pinsker [22], achieve the optimal , precisely , with , where d is the left degree of the expander graph but also the number of ones in each column of A, to be defined in the next section. However, to the best of our knowledge, it was [1] that proposed a probabilistic construction that is not only optimal but also more suitable to making quantitative statements where such matrices are applied.
This work follows the probabilistic construction proposed in Bah and Tanner[1] but with careful computation of the bounds, is able to achieve with . We retain the complexity of n but got a smaller complexity for d, which is novel. Related results with a similar d were derived in Indyk and Razenshteyn [23] and Bah et al.[24] but for structure sparse signals in the framework of model-based compressing sensing or sketching. In that framework, one has second order information about x beyond simple sparsity, which is first order information about x. It is thus expected and established that it is possible to get a small n and hence a smaller d. Arguably, such a small complexity for d justifies in hindsight fixing d to a small number in simulations with such A as in Bah and Tanner [1], Bah et al. [24], and Mendoza-Smith and Tanner [14], just to mention a few.
The results derived here are asymptotic, though finite dimensional bounds follow directly. We focus on for what ratios of the problem dimensions (s, n, N) does these results hold. There is almost a standard way of interrogating such a question, i.e., phase transitions, probably introduced to the compressed sensing literature by Donoho and Tanner [25]. In other words, we derive sampling theorems numerically depicted by phase transition plots about problem size spaces for which our construction holds. This is similar to what was done in Bah and Tanner [1] but for comparison purposes we include phase transition plots from probabilistic constructions by Buhrman et al. [26] and Berinde [27]. The plots show improvement over these earlier works. Furthermore, we show implications of our results for compressed sensing by using our results with the phase transition framework to compare the performance of selected combinatorial compressed sensing algorithms as is done in Bah and Tanner [1] and Mendoza-Smith and Tanner [14].
The manuscript is organized as follows. Section 1 gives the introduction; while section 2 sets the notation and defines some useful terms. The main results are stated in section 3 and the details of the construction is given in section 4. This is followed by a discussion in section 5 about our results, comparing them to existing results and using the results to compare the performance of some combinatorial compressed sensing algorithms. In section 6 we state the remaining proofs of theorems, lemmas, corollaries, and propositions used in this manuscript. After this section is the conclusion in section 7. We include an Appendix in Supplementary Materials, where we summarized key relevant materials from Bah and Tanner [1], and showed the derivation of some bounds used in the proofs.
2. Preliminaries
2.1. Notation
Scalars will be denoted by lowercase letters (e.g., k), vectors by lowercase boldface letters (e.g., x), sets by uppercase calligraphic letters (e.g., ) and matrices by uppercase boldface letters (e.g., A). The cardinality of a set is denoted by and [N]: = {1, …, N}. Given , its complement is denoted by and is the restriction of x ∈ ℝN to , i.e., if and 0 otherwise. For a matrix A, the restriction of A to the columns indexed by is denoted by . For a graph, denotes the set of neighbors of , that is the nodes that are connected to the nodes in , and eij = (xi, yj) represents an edge connecting node xi to node yj. The ℓp norm of a vector x ∈ ℝN is defined as .
2.2. Definitions
Below we give formal definitions that will be used in this manuscript.
Definition 2.1 (ℓp-norm restricted isometry property). A matrix A satisfies the ℓp-norm restricted isometry property (RIP-p) of order s and constant δs < 1 if it satisfies the following inequality.
The most popular case is RIP-2 and was first proposed in Cand‘es et al. [28]. Typically when RIP is mentioned without qualification, it means RIP2. In the discourse of this work though RIP-1 is the most relevant. The RIP says that A is a near-isometry and it is a sufficient condition to guarantee exact sparse recovery in the noiseless setting (i.e., y = Ax); or recovery up to some error bound, also referred to as optimality condition, in the noisy setting (i.e., y = Ax + e, where e is the bounded noise vector). we define optimality condition more precisely below.
Definition 2.2 (Optimality condition). Given y = Ax + e and for a reconstruction algorithm Δ, the optimal error guarantee is
where C1, C2 > 0 depend only on the RIP constant (RIC), i.e., δs, and not the problem size, 1 ≤ q ≤ p ≤ 2, and σs(x)q denote the error of the best s-term approximation in the ℓq-norm, that is
Equation (2) is also referred to as the ℓp/ℓq optimality condition (or error guarantee). Ideally, we would like ℓ2/ℓ2, but the best provable is ℓ2/ℓ1 [28], weaker than this is the ℓ1/ℓ1 [18], which is what is possible with the A considered in this work.
To aid translation between the terminology of graph theory and linear algebra we define the set of neighbors in both notation.
Definition 2.3 (Definition 1.4 in Bah and Tanner [1]). Consider a bipartite graph where is the set of edges and eij = (xi, yj) is the edge that connects vertex xi to vertex yj. For a given set of left vertices its set of neighbors is . In terms of the adjacency matrix, A, of the set of neighbors of for , denoted by As, is the set of rows with at least one non-zero.
Definition 2.4 (Expander graph). Let be a left-regular bipartite graph with N left vertexes, n right vertexes, a set of edges and left degree d. If, for any ϵ ∈ (0, 1/2) and any of size , we have that , then G is referred to as a (s, d, ϵ)-expander graph.
The ϵ is referred to as the expansion coefficient of the graph. A (s, d, ϵ)-expander graph, also called an unbalanced expander graph [18] or a lossless expander graph [29], is a highly connected bipartite graph. We denote the ensemble of n × N binary matrices with d ones per column by , or just to simplify notation. We also will denote the ensemble of n × N adjacency matrices of (s, d, ϵ)-expander graphs as 𝔼(N, n; s, d, ϵ) or simply 𝔼.
3. Results
Before stating the main results of the paper, we summarise here how we improve upon existing results in Bah and Tanner [1], which is generally true of standard random construction of such matrices. Essentially in the random constructions we want one minus the probability in (5) to go to zero as the problem size (s, n, N) → ∞. In Theorem 4.1 (which was Theorem 1.6 in Bah and Tanner [1]) for this to happen we require based on the bound (7). In this work we derived a tighter bound than (7), which is (12), that requires d to be smaller than the standard bound by a factor of log(s).
The main result of this work is formalized in Theorem 3.1, which is an asymptotic result, where the dimensions grow while their ratios remain bounded. This is also referred to as the proportional growth asymptotics [30, 31]. We point out that it has been observed in practice that applying these matrices (including the simulations we do in this manuscript), which necessitate having finite dimensions, produces results that agree with the theory. However, the theoretical analysis used in this work cannot be applied to the finite setting.
Theorem 3.1. Consider and let d, s, n, N ∈ ℕ, a random draw of an n×N matrix A from , i.e., for each column of A uniformly assign ones in d out of n positions, as (s, n, N) → ∞ while s/n ∈ (0, 1) and n/N ∈ (0, 1), with probability approaching 1 exponentially, the matrix A ∈ 𝔼 with
The proof of this theorem is found in section 6.1. It is worth emphasizing that the complexity of d is novel and it is the main contribution of this work.
Furthermore, in the proportional growth asymptotics, i.e., as (s, n, N) → ∞ while s/n → ρ and n/N → δ with ρ, δ ∈ (0, 1), for completeness, we derived a phase transition function (curve) in δρ-space below which Theorem 3.1 holds, but above which Theorem 3.1 fails to hold. This is formalized in the following lemma.
Lemma 3.1. Fix and let d, s, n, N ∈ ℕ, as (s, n, N) → ∞ while s/n → ρ ∈ (0, 1) and n/N → δ ∈ (0, 1) then for ρ < (1−γ)ρBT(δ; d, ϵ) and γ > 0, a random draw of A from implies A ∈ 𝔼 with probability approaching 1 exponentially.
The proof of this lemma is given in section 6.2. The phase transition function ρBT(δ; d, ϵ) turned out to be significantly higher that those derived from existing probabilistic constructions, hence our results are significant improvement over earlier works. This will be graphically demonstrated with some numerical simulations in section 5.
4. Construction
The standard probabilistic construction is for each column of A to uniformly assign ones in d out of n positions; while the standard approach to derive the probability bounds is to randomly selected s columns of A indexed by and compute the probability that |As| < (1 − ϵ)ds, then do a union bound over all sets of size s. Our work in Bah and Tanner [1] computed smaller bounds than previous works based on a dyadic splitting of and derived the following bound. We changed the notation and format of Theorem 1.6 in Bah and Tanner [1] slightly to be consistent with the notation and format in this manuscript.
Theorem 4.1 (Theorem 1.6, Bah and Tanner [1]). Consider d, s, n, N ∈ ℕ, fix with , let an n×N matrix A be drawn from , then
with a1: = d, and the functions defined as
where ψi is given by the following expression
and is the Shannon entropy in base e logarithms, and the index set .
a) If no restriction is imposed on as then the ai for i > 1 take on their expected value âi given by
b) If as is restricted to be less than âs, then the ai for i > 1 are the unique solutions to the following polynomial system
with a2i ≥ ai for each i.
In this work, based on the same approach as in Bah and Tanner [1], we derive new expressions for the pn(s, d) and Ψn(as, …, a1) in Theorem 4.1, i.e., (6) and (7) respectively, and provide a simpler bound for the improved expression of Ψn(as, …, a1).
Lemma 4.1. Theorem 4.1 holds with the functions
The proof of the lemma is given in section 6.3. Asymptotically, the argument of the exponential term in the bound of the probability in (5) of Theorem 4.1, i.e., Ψn(as, …, a1) in (12) is more important than the polynomial pn(s, d) in (11) since the exponential factor will dominate the polynomial factor. The significance of the lemma is that Ψn(as, …, a1) in (12) is smaller than Ψn(as, …, a1) in (7) since in (12) is asymptotically smaller than 3slog(5d) in (7), because the former is while the latter is , since we consider .
Recall that we are interested in computing Prob(|As| ≤ as) when as = (1 − ϵ)ds. This means having to solve the polynomial equation (10) to compute as small a bound of Ψn((1 − ϵ)ds, …, d) as possible. We derive an asymptotic solution to (10) for as = (1 − ϵ)ds and use that solution to get the following bounds.
Theorem 4.2. Consider d, s, n, N ∈ ℕ, fix with , for η > 0, β ≥ 1, and , let an n × N matrix A be drawn from , then
where
The proof of this theorem is also found in section 6.5. Since Theorem 4.2 holds for a fixed of size at most s, if we want this to hold for all of size at most s, we do a union bound over all of size at most s. This leads to the following probability bound.
Theorem 4.3. Consider d, s, n, N ∈ ℕ, and all with , for τ > 0, and , let an n × N matrix A be drawn from , then
where
Proof: Applying the union bound over all of size at most s to (13) leads to the following.
Then we used the upper bound of (143) to bound the combinatorial term in (19). After some algebraic manipulations, we separated the the polynomial term, given in (17), from the exponential terms whose exponent is
We upper bound ΨN(s, d, ϵ) in (18) by upper bounding with and the upper bound of Ψn(s, d, ϵ) in (15). The o(N) decays to zeros with N and its a result of dividing the polylogarithmic terms of s in (15), and τ = ηβ−1(β − 1) in (15). This concludes the proof.□
The next corollary easily follows from Theorem 4.3 and it is equivalent to Theorem 3.1. Its statement is that if the conditions therein holds, then the probability that the cardinality of the set of neighbors of any with is less than (1 − ϵ)ds goes to zero as dimensions of A grows. On the other hand, the probability that the cardinality of the set of neighbors of any with is greater than (1 − ϵ)ds goes to one as dimensions of A grows. Implying that A is the adjacency matrix of a (s, d, ϵ)-expander graph.
Corollary 4.1. Given d, s, n, N ∈ ℕ, and , for and , with cd, cn > 0. Let an n × N matrix A be drawn from , in the proportional growth asymptotics
Proof: It suffice to focus on the exponent of (16), more precisely on the bound of ΨN(s, d, ϵ) in (18), i.e.,
We can ignore the o(N) term as this goes to zero as N grows, and show that the remaining sum is negative. The remaining sum is
Hence, we can further focus on the sum in the square brackets, and find conditions on d that will make it negative. We require
Recall τ = ηβ−1(β−1) and β is a function of ϵ, with β(ϵ) ≈ 1+ϵ. Therefore, τ is a function of ϵ, and , hence there exists a cd > 0 for (25) to hold.
With regards to the complexity of n, we go back to the right hand side (RHS) of (24) and we substitute with Cd > 0 for d in the RHS of (24) to get the following.
Now we assume with Cn > 0 for n and substitute this in (26) to get the following.
Again since , hence there exists a cn > 0 for (28) to hold. The bound of n in (28) agrees with our earlier assumption, thus concluding the proof.□
5. Discussion
5.1. Comparison to Other Constructions
In addition to being the first probabilistic construction of adjacency matrices of expander graphs with such a small degree, quantitatively our results compares favorably to existing probabilistic constructions.We use the standard tool of phase transitions to compare our construction to the construction proposed in Berinde [27] and those proposed in Buhrmanet al. [26]. The phase transition curve ρBT(δ; d, ϵ) we derived in Lemma 3.1 is the ρ that solves the following equation.
where cn > 0 is as in (28). Equation (29) comes from taking the limit, in the proportional growth asymptotics, of the bound in (18), setting that to zero and simplifying. Similarly, for any with , Berinde [27] derived the following bound on the set of neigbors of , i.e., As.
We then express the bound in (30) as the product of a polynomial term and an exponential term as we did for the right hand side of (16). A bound of the exponent is carefully derived as in the derivations above. We set the limit, in the proportional growth asymptotics, of this bound to zero and simplify to get the following.
We refer to the ρ that solves (31) as the phase transition for the construction proposed by Berinde [27] and denote this ρ (the phase transition function) as ρBI(δ; d, ϵ). Another probabilistic construction was proposed by Burhman et al. [26]. In conforminty with the notation used in this manuscript their bound is equivalent to the following, also stated in a similar form by Indyk and Razenshteyn [23].
where ν > 0. We again express the bound in (32) as the product of a polynomial term and an exponential term. A bound of the exponent is carefully derived as in the derivations above. We set the limit, in the proportional growth asymptotics, of this bound to zero and simplify to get the following.
Similarly, we refer to the ρ that solves (33) as the phase transition for the construction proposed by Burhman et al. [26] and denote this ρ as ρBM(δ; d, ϵ). We compute numerical solutions to (29), (31), and (33) to derive the phase transitions, for the existence (probabilistic construction) of expanders, ρBT(δ; d, ϵ), ρBI(δ; d, ϵ), and ρBM(δ; d, ϵ) respectively. These are plotted in the left panel of Figure 1. It is clear that our construction has a much higher phase transition than the others, as expected from our previous results, see Figure 9 in Bah and Tanner [1]. Recall that the phase transition curves in these plots depict construction of adjacency matrices of (s, d, ϵ)-expanders with high probability for ratios of s, n, and N (since ρ: = s/n, and δ: = n/N) below the curve; and the failure to construct adjacency matrices of (s, d, ϵ)-expanders with high probability for ratios of s, n, and N above the curve. Essentially, the larger the area under the curve the better.
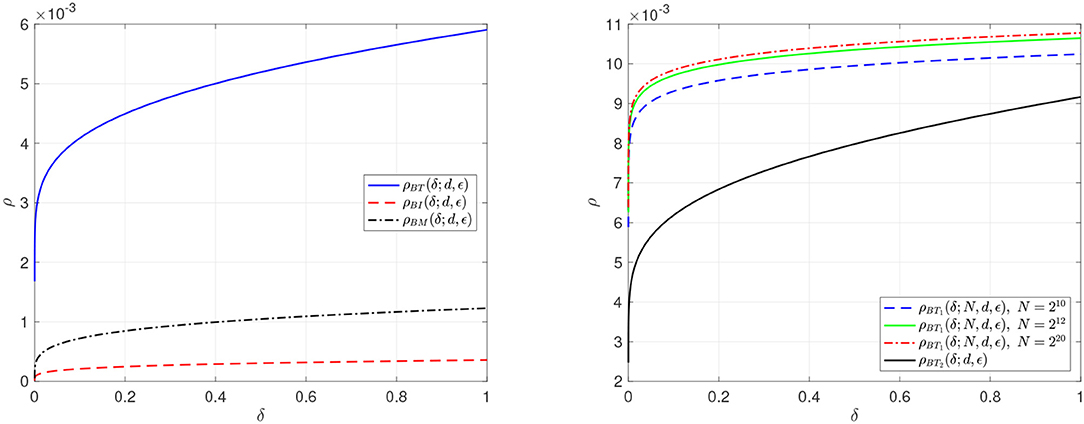
Figure 1. Plots of phase transitions for probabilistic construction of expanders, with fixed d = 25, ϵ = 1/6, and δ ∈ [10−6, 1] on a logarithmically spaced grid of 100 points. (Left) A comparison of ρBT(δ; d, ϵ), ρBI(δ; d, ϵ), and ρBM(δ; d, ϵ), where cn = 2. (Right) A comparison of ρBT(δ; d, ϵ) denoted as ρBT2(δ; d, ϵ) to our previous ρBT(δ; d, ϵ) denoted as ρBT1(δ; d, ϵ) in Bah and Tanner [1] with different values of N, (i.e., 210, 212, and 220) and cn = 2/3.
Remark 5.1. It is easy to see that ρBI(δ; d, ϵ) is a special case of ρBM(δ; d, ϵ) since the two phase transitions will coincide, or equivalently (31) and (33) will be the same, when ν = e−1. One could argue that Berinde's derivation in [27] suffers from over counting.
Given that this work is an improvement of our work in Bah and Tanner [1] in terms of simplicity in computing ρBT(δ; d, ϵ), for completeness we compare our new phase transition ρBT(δ; d, ϵ) denoted as ρBT2(δ; d, ϵ) to our previous ρBT(δ; d, ϵ) denoted as ρBT1(δ; d, ϵ) in the right panel of Figure 1. Each computation of ρBT1(δ; d, ϵ) requires the specification of N, which is not needed in the computation of ρBT2(δ; d, ϵ), hence the simplification. However, the simplification led to a lower phase transition as expected, which is confirmed by the plots in the right panel of Figure 1.
Remark 5.2. These simulations also inform us about the size of cn. See from the plots of ρBT(δ; d, ϵ) and ρBT2(δ; d, ϵ) that the smaller the value of cn the higher the phase transition but since ρBT2(δ; d, ϵ) has to be a lower bound of ρBT1(δ; d, ϵ), for values of cn much smaller than 2/3, the lower bound will fail to hold. This informed the choice of cn = 2 in the plot of ρBT(δ; d, ϵ) in the left panel of Figure 1.
5.2. Implications for Combinatorial Compressed Sensing
When the sensing matrices are restricted to the sparse binary matrices considered in this manuscript, compressed sensing is usually referred to as combinatorial compressed sensing a term introduced in Berinde et al. [18] and used extensively in Mendoza-Smith and Tanner [14] and Mendoza-Smith et al. [15]. In this setting, compressed sensing is more-or-less equivalent to linear sketching. The implications of our results on combinatorial compressed sensing are two-fold. One is on the ℓ1-norm RIP, we donate as RIP-1; while the second is in the comparison of performance of recovery algorithms for combinatorial compressed sensing.
5.2.1. RIP-1
As can be seen from (2), the recovery errors in compressed sensing depend on the RIC, i.e., δs. The following lemma deduced from Theorem 1 of Berinde et al.[18] shows that a scaled A drawn from 𝔼 have RIP with δs = 2ϵ.
Lemma 5.1. Consider and let A be drawn from 𝔼, then Φ = A/d satisfies the following RIP-1 condition
The interested reader is referred to the proof of Theorem 1 in Berinde et al. [18] for the proof of this lemma. Key to the holding of Lemma 5.1 is the existence of (s, d, ϵ)-expander graphs, hence one can draw corollaries from our results on this.
Corollary 5.1. Consider and let d, s, n, N ∈ ℕ. In the proportional growth asymptotics with a random draw of an n × N matrix A from , the matrix Φ: = A/d has RIP-1 with probability approaching 1 exponentially, if
Proof: Note that the upper bound of (34) holds trivially for any Φ = A/d where A has d ones per column, i.e., . But for the lower bound of (34) to hold for any Φ = A/d, we need A to be an (s, d, ϵ)-expander matrix, i.e., A ∈ 𝔼. Note that the event |As| ≥ (1 − ϵ)ds is equal to the event ||Ax||1 ≥ (1 − 2ϵ)d||x|1, which is equivalent to , for a fixed , with
. For A to be in 𝔼, we need expansion for all sets , with , i.e., A∈𝔼. The key thing to remember is that
The probability in (36) going to 1 exponentially in the proportional growth asymptotics, i.e., the existence of A∈𝔼 with parameters as given in (35), is what is stated in Theorem 3.1. Therefore, the rest of the proof follows from the proof of Theorem 3.1, hence concluding the proof of the corollary□.
Notably, Lemma 5.1 holds with Φ having much smaller number of non-zeros per column due to our construction. More over, we can derive sampling theorems for which Lemma 5.1 holds as thus.
Corollary 5.2. Fix and let d, s, n, N ∈ ℕ. In the proportional growth asymptotics, for any ρ < (1−γ)ρBT(δ; d, ϵ) and γ > 0, a random draw of A from implies Φ: = A/d has RIP-1 with probability approaching 1 exponentially.
Proof. The proof of this corollary follows from the proof of Corollary 5.1 above, and it is related to the proof of Lemma 3.1 as the proof of Corollary 5.1 is to the proof of Theorem 3.1. The details of the proof is thus skipped.□
5.2.2. Performance of Algorithms
We wish to compare the performance of selected combinatorial compressed sensing algorithms in terms of the possible problem sizes (s, n, N) that these algorithms can reconstruct sparse/compressible signals/vectors up to their respective error guarantees. The comparison is typically done in the framework of phase transitions, which depict a boundary curve where ratios of problems sizes above this curve are recovered with probability approaching 0 exponentially; while problems sizes below the curve are recovered with probability approaching 1 exponentially. The list of combinatorial compressed sensing algorithms includes Expander Matching Pursuit (EMP) [32], Sparse Matching Pursuit [33], Sequential Sparse Matching Pursuit (SSMP) [13], Left Degree Dependent Signal Recovery (LDDSR) [11], Expander Recovery (ER) [12], Expander Iterative Hard-Thresholding (EIHT) [19, Section 13.4], and Expander ℓ0-decoding (ELD) with both serial and parallel versions [14]. For reason similar to those used in Bah and Tanner [1] and Mendoza-Smith and Tanner [14], we selected out of this list four of the algorithms: (i) SSMP, (ii) ER, (ii) EIHT, (iv) ELD. Descriptions of these algorithms is skipped here but the interested reader is referred to the original papers or their summarized details in Bah and Tanner [1] and Mendoza-Smith and Tanner [14]. We were also curious as to how ℓ1-minimization's performance compares to these selected combinatorial compressed sensing algorithms, since ℓ1-minimization (ℓ1-min) can be used to solve the combinatorial problem solved by these algorithms, see [18, Theorem 3].
The phase transitions are based on conditions on the RIC of the sensing matrices used. Consequent to Lemma 5.1, this becomes conditions on the expansion coefficient (i.e., ϵ) of the underlying (s, d, ϵ)-expander graphs of the sparse sensing matrices used. Where this condition on ϵ is not explicitly given it is easily deducible from the recovery guarantees given for each algorithms. The conditions are summarized in the table below.
The theoretical values are what will be found in the reference given in the table; while the computational values are what we used in our numerical experiments to compute the phase transition curves of the algorithms. The value for e was set to be 10−15, to make the ϵk as large as possible under the given condition. With these values we computed the phase transitions in Figure 2.
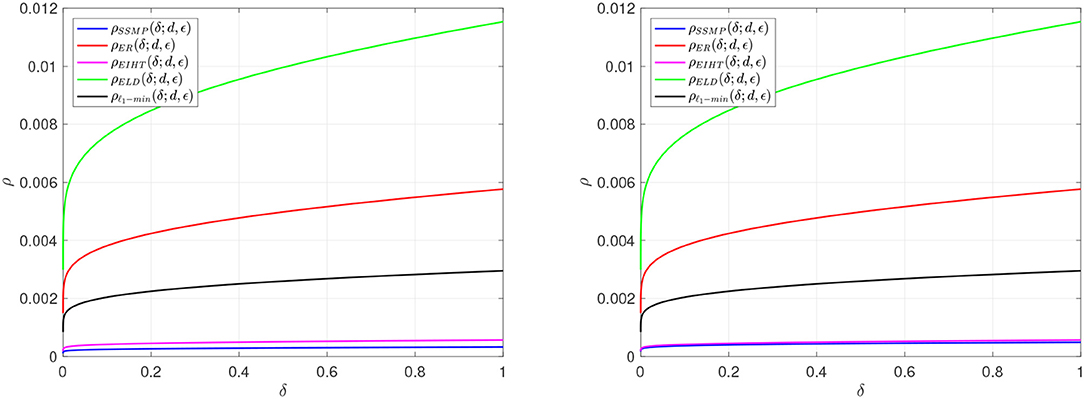
Figure 2. Phase transitions plots of algorithms with fixed d = 25, ϵ as in the fourth column of Table 1 with e = 10−15, cn = 2 and δ ∈ [10−6, 1] on a logarithmically spaced grid of 100 points. (Left) k = 3s for ρSSMP(δ; d, ϵ). (Right) k = ⌈(2+e)s⌉ for ρSSMP(δ; d, ϵ).

Table 1. Recovery conditions on ϵ.
The two figures are the same except for the different sparsity value used. The performance of the algorithms in this framework are thus ranked as follows: ELD, ER, ℓ1-min, EIHT, and SSMP.
Remark 5.3. We point out that there are many way to compare performance of algorithms, this is just one way. For instance, we can compare runtime complexities or actual computational runtimes as in Mendoza-Smith and Tanner [14]; phase transitions of different probabilities, here the probability of recovery is 1 but this could be set to something else, like 1/2 in the simulations in Mendoza-Smith and Tanner [14]; one could also compare number of iterations and iteration cost as was also done in Mendoza-Smith and Tanner [14]. We further point out that such comaprisons could be conducted with real-world data simulations, as was done in Mendoza-Smith and Tanner [14].
6. Proofs of Theorems, Lemmas, and Propositions
6.1. Theorem 3.1
The proof of the theorem follows trivially from Corollary 4.1. Based on (21) of Corollary 4.1 we deduce that A ∈ 𝔼 with probability approaching 1 exponentially with and , with cd, cn > 0, hence concluding the proof.□
6.2. Lemma 3.1
The phase transition curve ρBT(δ; d, ϵ) is based the bound of the exponent of (16), which is
In the propotional growth asymptotics (s, n, N) → ∞ while s/n → ρ ∈ (0, 1) and n/N → δ ∈ (0, 1). This implies that o(N) → 0 and (37) becomes
where cn > 0 is as in (28). If (38) is negative then as the problem size grows we have
Therefore, setting (38) to zero and solving for ρ gives us a critical ρ below which (38) is negative and positive above it. The critical ρ is the phase transition ρ, i.e., ρBT(δ; d, ϵ), where below ρBT(δ; d, ϵ) is parameterized by the γ in the lemma. This concludes the proof.□
6.3. Lemma 4.1
By the dyadic splitting proposed in Bah and Tanner [1], we let such that and therefore
In (41) we sum over all possible events, i.e., all possible sizes of ls. In line with the splitting technique, we simplify the probability to the product of the probabilities of the cardinalities of and and their intersection. Using the definition of Pn(·) in Lemma 8.2 (Appendix), thus leads to the following.
In a slight abuse of notation we write to denote applying the sum m times. We also drop the limits of the summation indices henceforth. Now we use Lemma 8.1 in Appendix to simplify (42) as follows.
Now we proceed with the splitting—note (43) stopped only at the first level. At the next level, the second, we will have q2 sets with Q2 columns and r2 sets with R2 columns which leads to the following expression.
We continue this splitting of each instance of Prob(·) for ⌈log2s⌉−1 levels until reaching sets with single columns where, by construction, the probability that the single column has d non-zeros is one. Note that at this point we drop the subscripts ji, as they are no longer needed. This process gives a complicated product of nested sums of Pn(·) which we express as
Using the expression for Pn(·) in (133) of Lemma 8.2 (Appendix) we bound (45) by bounding each Pn(·) as in (134) with a product of a polynomial, π(·), and an exponential with exponent ψn(·).
Using Lemma 8.4 in Appendix we maximize the ψn(·) and hence the exponentials in (46). We maximize each ψn(·) by choosing l(·) to be a(·). Then (46) will be upper bounded by the following.
We then factor the product of exponentials. This product becomes an exponential where exponent is the summation of the ψn(·), we will denote this exponent as . Then (47) simplifies to the following.
We denote the factor multiplying the exponential term by Π(ls, …, l2, d), therefore we have the following bound.
where is exactly Ψn(as, …, a2, d) given by (78) in [1, Proof of Theorem 1.6]. Consequently, we state the bound of and skip the proof, which is as thus.
where ψi is given by (8). The upper bound of Π(ls, …, l2, d) is given by the following proposition.
Proposition 6.1. Given ls ≤ as, l⌈s/2⌉ ≤ a⌈s/2⌉, ⋯ , l2 ≤ a2, we have
The proof of the proposition is found in section 6.4. Taking log of right hand side of (51) and then exponentiating the results yields
Combining (54) and (50) gives the following bound for (49)
It follows therefore that as in (11) and the exponent in (55) is n · Ψn(as, …, a1), which implies (12). This concludes the proof of the lemma.□
6.4. Proposition 6.1
By definition, from (48), we have
From (138) we see that π(·) is maximized when all the three arguments are the same and using Corollary 8.1 we take largest possible arguments that are equal in the range of the summation. Before we write out the resulting bound for Π(ls, …, l2, d), we simplify notation by denoting π(x, x, x) as π(x), and noting that Q⌈log2s⌉−1 = 2. Therefore, the bound becomes the following.
Properly aligning the π(·) with their relevant summations simplifies the right hand side (RHS) of (57) to the following.
From (138) we have π (y) defined as
We use the RHS of (59) to upper bound each term in (58), leading to the following bound.
For each Qi and Ri, i = 1, …, ⌈log2 s⌉−2, which means we have ⌈log2 s⌉ − 2 pairs plus one Q0, hence (60) simplifies to the following.
From (61) to (62) we upper each sum by taking the largest possible value of l(·), which is a(·), and multiplied it with the total number terms in the summation given by Lemma 8.1 in Appendix. We did upper bound the following two terms of (63).
Details of the derivation of the bounds (64) and (65) is in the Appendix. Using these bounds from (63) we have the following upper bound for Π(ls, …, l2, d).
From (66) to (67) we used the following upper bound.
The bound (67) coincides with (51), hence concluding the proof.□
6.5. Theorem 4.2
The following lemma is a key input in this proof.
Lemma 6.1. Let 0 < α ≤ 1, and εn > 0 such that εn → 0 as n → ∞. Then for as < âs,
where
The proof of the lemma is found in section 6.6. Recall from Theorem 4.1 that
where ψi is given by the following expression
We use Lemma 6.1 to upper bound ψi in (72) away from zero from above as n → 0. We formalize this bound in the following proposition.
Proposition 6.2. Let η > 0 and β > 1 as defined in Lemma 6.1. Then
The proof of Proposition 6.2 is found in section 6.7. Using the bound of ψi in Proposition 6.2, we upper Ψ(as, …, a1) as follows.
Then setting as = (1 − ϵ)ds and substituting in (75), the factor multiplying becomes
The last two terms of (79) become polynomial in s, d and ϵ, when exponentiated hence they are incorporated into pn(s, d, ϵ) in (14), which means
which is (14). The first two terms of (79) will grow faster than a polynomial in s, d and ϵ when exponentiated, hence they replace in (75), the factor multiplying . Therefore, (79) is modified as thus
The factor in (83) is lower bounded as follows, see proof in section 6.8.
Using this bound in (83) gives (15), thus concluding the proof.□
6.6. Lemma 6.1
Recall that we have a formula for the expected values of the ai as
which follow a relatively simple formulas, and then the coupled system of cubics as
for when the final as is constrained to be less than âs. To simplify the notation of the indexing in (86), observe that if i = 2j for a fixed j, then 2i = 2j+1 and 4i = 2j+2. Therefore, it suffice to use the index aj, aj+1, and aj+2 rather than ai, a2i, and a4i. Moving the second two terms in (86) to the right and dividing the quadratic multiples we get the relation
which is the same expression on the right and left, but with j increased by one on the left. This implies that the fraction is independent of j, so
for some constant c independent of j (though not necessarily of n). This is in fact the relation (85), if we set c to be equal to −1/n. One can then wonder what is the behavior of c if we fix the final as. Moreover, (88) is equivalent to
which inductively leads to
so that one has a relation of the lth stage in terms of the first stage. Note this does not require the as to be fixed, (90) is how one simply computes all al for l > 0 once one has a0 and c. The point is that c to match the as one has to select c appropriately. So the way we calculate c is by knowing a0 and as, then solving (90) for l = s. Unfortunately there is not an easy way to solve for c in (90) so we need to do some asymptotic approximation. Let's assume that al is close to âl. So we do an asymptotic expansion in terms of the difference from âl.
To simplify things a bit lets insert a0 = d (since a0 is a1 in our standard notation) and then we insert what we know for âl. For âl we have c = −n−1, see (85). We then have from (90) that
So if we write al = (1 − εn)âl and consider the case of εn → 0 as n → 0. The point of this is that instead of working with âl we can now work in terms of εn. Setting al = (1 − εn)âl gives
We now solve for c as a function of εn and d. As εn goes to zero we should have c converging to −n−1.
Let αn = 2l, for 0 < α ≤ 1 and c = −β(εn, d)/n, then, dropping the argument of β(·, ·), (92) becomes
Multiplying through by β/n and performing a change of variables of k = αn, (93) becomes
The left hand side of (94) simplifies to
The right hand side of (94) simplifies to
Matching powers of k in (95) and (96) for k0 and k−1 yields the following.
Both of which respectively simplify to the following.
Multiply (99) by β and subtract the two equations, (99) and (100), to get
This yields
To be consistent with what c ought to be as εn → 0, we choose
as required – concluding the proof.□
6.7. Proposition 6.2
We use Lemma 6.1 to express ψi in (72) as follows
Note that for regimes of small s/n considered
We need the following expressions for the Shannon entropy and it's first and second derivatives
But also due to the symmetry about z = 1/2. Similarly, is symmetric about z = 1/2; while is anti-symmetric, i.e., . Using the symmetry of we rewrite ψi in (105) as follows.
From (106), we deduce the following ordering
The last equality in (111) follows from that we assume 2βai ≤ n, where 1 < β < 2 but very close to 1. This is a valid constraint on the cardinality of the supports ai. To simplify notation, let , , and x3 = −cai, which implies that x1 ≤ x2 ≤ x3 ≤ 1/2. Therefore, from (110), we have
Observe that the expression in the square brackets on the right hand side of (116) is zero, which implies that
This is very easy to check by substituting the values of x1, x2, and x3. So instead of bound (115), we alternatively upper bound (114) as follows
where ξ21 ∈ (x1, x2), and ξ32 ∈ (x2, x3), which implies
Using relation (117), bound (118) simplifies to the following.
for ξ31 ∈ (x1, x3). Since ξ21 < ξ32, we rewrite bound (122) as follows.
where η = ξ32 − ξ21 > 0, and the last bound is due to the fact that x3 > ξ31.
Going back to our normal notation, we rewrite bound (124) as follows.
This concludes the proof.□
6.8. Inequality 84
The series bound (84) is derived as follows.
That is the required bounds, hence concluding the proof.□
7. Conclusion
We considered the construction of sparse matrices that are invaluable for dimensionality reduction with application in diverse fields. These sparse matrices are more efficient computationally compared to their dense counterparts also used for the purpose of dimensionality reduction. Our construction is probabilistic based on the dyadic splitting method we introduced in Bah and Tanner [1]. By better approximation of the bounds we achieve a novel result, which is a reduced complexity of the sparsity per column of these matrices. Precisely, a complexity that is a state-of-the-art divided by logs, where s is the intrinsic dimension of the problem.
Our approach is one of a few that gives quantitative sampling theorems for existence of such sparse matrices. Moreover, using the phase transition framework comparison, our construction is better than existing probabilistic constructions. We are also able to compare performance of combinatorial compressed sensing algorithms by comparing their phase transition curves. This is one perspective in algorithm comparison amongst a couple of others like runtime and iteration complexities.
Evidently, our results holds true for the construction of expander graphs, which is a graph theory problem and is of interest to communities in theoretical computer science and pure mathematics.
Author Contributions
JT contributed to conception of the idea. Both JT and BB worked on the derivation of the initial results, which was substantially improved by BB. BB wrote the first draft of the manuscript. JT did some revisions and gave feedback.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
BB acknowledges the support from the funding by the German Federal Ministry of Education and Research (BMBF) for the German Research Chair at AIMS South Africa, funding for which is administered by Alexander von Humboldt Foundation (AvH). JT acknowledges support from The Alan Turing Institute under the EPSRC grant EP/N510129/1.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2018.00039/full#supplementary-material
References
1. Bah B, Tanner J. Vanishingly sparse matrices and expander graphs, with application to compressed sensing. IEEE Trans Inform Theor. (2013) 59:7491–508. doi: 10.1109/TIT.2013.2274267
2. Ahn KJ, Guha S, McGregor A. Graph sketches: sparsification, spanners, and subgraphs. In: Proceedings of the 31st Symposium on Principles of Database Systems. Scottsdale, AZ: ACM (2012). p. 5–14.
3. Gilbert AC, Levchenko K. Compressing network graphs. In: Proceedings of the LinkKDD Workshop at the 10th ACM Conference on KDD. Seatle, WA (2004).
4. Vardi Y. Network tomography: estimating source-destination traffic intensities from link data. J Am Stat Assoc. (1996) 91:365–77.
5. Castro R, Coates M, Liang G, Nowak R, Yu B. Network tomography: recent developments. Stat Sci. (2004) 19:499–517. doi: 10.1214/088342304000000422
8. Dwork C, McSherry F, Talwar K. The price of privacy and the limits of LP decoding. In: Proceedings of the Thirty-ninth Annual ACM Symposium on Theory of Computing. San Diego, CA: ACM (2007). p. 85–94.
9. Donoho DL, Johnstone IM, Hoch JC, Stern AS. Maximum entropy and the nearly black object. J R Stat Soc Ser B (1992) 54:41–81.
10. Donoho DL. Compressed sensing. IEEE Trans Inform Theor. (2006) 52:1289–306. doi: 10.1109/TIT.2006.871582
11. Xu W, Hassibi B. Efficient compressive sensing with deterministic guarantees using expander graphs. In: Information Theory Workshop, 2007. ITW'07. Tahoe City, CA: IEEE (2007). p. 414–9.
12. Jafarpour S, Xu W, Hassibi B, Calderbank R. Efficient and robust compressed sensing using optimized expander graphs. IEEE Trans Inform Theor. (2009) 55:4299–308. doi: 10.1109/TIT.2009.2025528
13. Berinde R, Indyk P. Sequential sparse matching pursuit. In: 47th Annual Allerton Conference on Communication, Control, and Computing. IEEE (2009). p. 36–43.
14. Mendoza-Smith R, Tanner J. Expander ℓ0-decoding. Appl. Comput. Harmon. Anal. (2017) 45:642–67. doi: 10.1016/j.acha.2017.03.001
15. Mendoza-Smith R, Tanner J, Wechsung F. A robust parallel algorithm for combinatorial compressed sensing. arXiv [preprint] arXiv:170409012 (2017).
17. Gilbert AC, Iwen MA, Strauss MJ. Group testing and sparse signal recovery. In: Signals, Systems and Computers, 2008 42nd Asilomar Conference on. Pacific Grove, CA: IEEE (2008). p. 1059–63.
18. Berinde R, Gilbert AC, Indyk P, Karloff H, Strauss MJ. Combining geometry and combinatorics: A unified approach to sparse signal recovery. In: Communication, Control, and Computing, 2008 46th Annual Allerton Conference on. Urbana-Champaign, IL: IEEE (2008). p. 798–805.
19. Foucart S, Rauhut H. A Mathematical Introduction to Compressive Sensing. New York, NY: Springer (2013).
20. Hoory S, Linial N, Wigderson A. Expander graphs and their applications. Bull Am Math Soc. (2006) 43:439–562. doi: 10.1090/S0273-0979-06-01126-8
21. Guruswami V, Umans C, Vadhan S. Unbalanced expanders and randomness extractors from Parvaresh–Vardy codes. J ACM (2009) 56:20. doi: 10.1145/1538902.1538904
22. Bassalygo LA, Pinsker MS. Complexity of an optimum nonblocking switching network without reconnections. Problemy Peredachi Informatsii (1973) 9:84–87.
23. Indyk P, Razenshteyn I. On model-based RIP-1 matrices. In: International Colloquium on Automata, Languages, and Programming. Berlin; Heidelberg: Springer (2013). p. 564–75.
24. Bah B, Baldassarre L, Cevher V. Model-based sketching and recovery with expanders. In: SODA. SIAM (2014). p. 1529–43.
25. Donoho DL, Tanner J. Thresholds for the recovery of sparse solutions via l1 minimization. In: Information Sciences and Systems, 2006 40th Annual Conference on. IEEE (2006). p. 202–6.
26. Buhrman H, Miltersen PB, Radhakrishnan J, Venkatesh S. Are bitvectors optimal? SIAM J Comput. (2002) 31:1723–44. doi: 10.1137/S0097539702405292
27. Berinde R. Advances in Sparse Signal Recovery Methods. Massachusetts Institute of Technology (2009).
28. Candès EJ, Romberg J, Tao T. Stable signal recovery from incomplete and inaccurate measurements. Commun Pure Appl Math. (2006) 59:1207–23. doi: 10.1002/cpa.20124
29. Capalbo M, Reingold O, Vadhan S, Wigderson A. Randomness conductors and constant-degree lossless expanders. In: Proceedings of the Thirty-fourth Annual ACM Symposium on Theory of Computing. New York, NY: ACM (2002). p. 659–68.
30. Blanchard JD, Cartis C, Tanner J. Compressed sensing: how sharp is the restricted isometry property? SIAM Rev. (2011) 53:105–25. doi: 10.1137/090748160
31. Bah B, Tanner J. Improved bounds on restricted isometry constants for Gaussian matrices. SIAM J Matrix Anal Appl. (2010) 31:2882–98. doi: 10.1137/100788884
32. Indyk P, Ruzic M. Near-optimal sparse recovery in the ℓ1-norm. In: Foundations of Computer Science, 2008. FOCS'08. IEEE 49th Annual IEEE Symposium on. Philadelphia, PA: IEEE (2008). p. 199–207.
Keywords: compressed sensing (CS), expander graphs, probabilistic construction, sample complexity, sampling theorems, combinatorial compressed sensing, linear sketching, sparse recovery algorithms
Citation: Bah B and Tanner J (2018) On the Construction of Sparse Matrices From Expander Graphs. Front. Appl. Math. Stat. 4:39. doi: 10.3389/fams.2018.00039
Received: 27 June 2018; Accepted: 10 August 2018;
Published: 04 September 2018.
Edited by:
Haizhao Yang, National University of Singapore, SingaporeReviewed by:
Alex Jung, Aalto University, FinlandXiuyuan Cheng, Duke University, United States
Zhihui Zhu, Johns Hopkins University, United States
Copyright © 2018 Bah and Tanner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bubacarr Bah, YnViYWNhcnJAYWltcy5hYy56YQ==